数据一致性、AI样本可追溯性与数据治理
在AI系统中,数据不仅仅要“可用”,更要“可靠、可控、可追踪”。因此,建立一套具备数据一致性保障机制、AI样本追溯机制与完整数据治理流程的系统架构,是AI架构师的必修课。在大规模分布式AI数据系统中,数据的一致性不仅仅是“数据库层级”的事务控制,更应覆盖采集、加工、标注、训练各阶段。为了保证数据不被滥用、泄漏或越权访问,AI数据平台必须引入治理机制,图2-为常用的多层权限与数据分级控制图。通过这种
·
据一致性、AI样本可追溯性与数据治理
在AI系统中,数据不仅仅要“可用”,更要“可靠、可控、可追踪”。一旦数据出现错位、标注错误或样本混乱,轻则模型性能下降,重则导致业务决策偏误。因此,建立一套具备数据一致性保障机制、AI样本追溯机制与完整数据治理流程的系统架构,是AI架构师的必修课。
1. 数据一致性保障
在大规模分布式AI数据系统中,数据的一致性不仅仅是“数据库层级”的事务控制,更应覆盖采集、加工、标注、训练各阶段。如图2-所示。
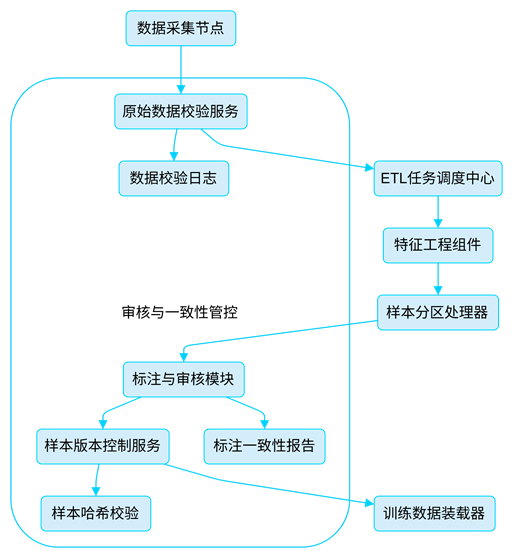
图2- 数据一致性保障流程
- 数据采集节点:负责从各业务系统抓取日志、音频、图像等原始数据;
- 原始数据校验服务:进行首轮字段校验,如格式规范、字段缺失、主键唯一性;
- ETL任务调度中心:负责定时批处理、任务依赖、失败回滚等调度逻辑;
- 特征工程组件:完成缺失值处理、特征提取、字段派生等操作;
- 样本分区处理器:将样本按模型需求划分多个逻辑训练子集;
- 标注与审核模块:负责人工/机器混合标注、审核状态管理;
- 样本版本控制服务:为每一次样本导入生成独立版本标识;
- 训练数据装载器:将指定版本样本导入模型平台;
校验输出节点:
- 数据校验日志:记录校验失败字段与采集源;
- 标注一致性报告:记录同一样本不同标注员标签差异;
- 样本哈希校验:用于判断样本是否被意外修改或重复入库。
2. AI样本可追溯性
为了实现对任意一个训练样本的“源头→流转→使用”全过程可查询,系统需引入样本ID版本化、流转日志存储与模型使用登记机制。如图2-所示。
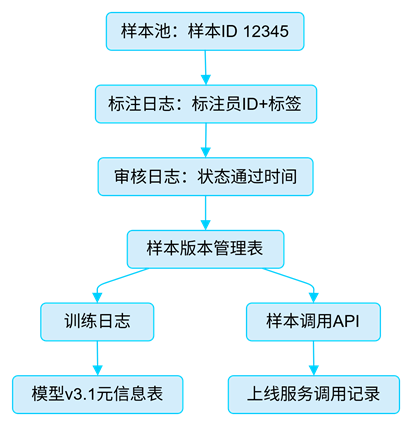
图2- AI样本可追溯性结构图
- 每个样本(如ID 12345)在样本池中存储基本字段;
- 标注员操作通过标注日志记录:包括标注员ID、使用模板、耗时等;
- 审核通过后,系统记录审核人员与状态变更时间;
- 审核通过样本进入样本版本管理表,标记“v20240524-17h任务批次”;
- 在训练日志中,记录该版本样本被模型v3.1训练所使用;
- 如果模型上线,对应服务将样本ID加入调用记录链,支持追溯线上误判场景;
- 所有环节可通过“样本调用API”对接外部查询系统,实现平台级统一样本查询。
这一机制可实现在错误预测或模型偏差出现时,精准定位训练样本来源、操作历史与调用轨迹,是高可靠AI系统的重要保障。
3. 数据治理策略与权限管控流程
为了保证数据不被滥用、泄漏或越权访问,AI数据平台必须引入治理机制,图2-为常用的多层权限与数据分级控制图。
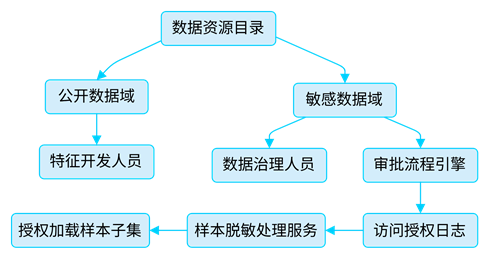
图2- 数据治理策略与权限管控流程图
- 数据资源目录:平台将全部数据进行资产化登记;
- 公开数据域:如不含PII的用户行为日志,可开放给特征工程人员;
- 敏感数据域:如包含通话内容、身份证字段,需走权限审批;
- 审批流程引擎:控制是否允许某工程师访问敏感样本;
- 访问授权日志:记录审批人、时间、有效期、使用项目;
- 样本脱敏处理服务:将敏感字段替换为Token或Null;
- 授权加载样本子集:标记脱敏样本可用于本次实验,但不可外传。
通过这种治理机制,可以实现在多人协作、跨团队开发过程中,样本使用合规可控,防止数据违规、误用和滥用。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 3
3 0
0- 0



 已为社区贡献15条内容
已为社区贡献15条内容

所有评论(0)