数据库分库分表与模型训练样本分区
于是,分库分表技术展示出极其重要的地位,而对于AI模型训练而言,如何构建高效、可分布、可切割的样本分区系统,也是创建矩阵程序、行为分类和个性化推荐的基础之一。同时,对于不频繁变动的详细信息,将其分离到UserDetail表中,可以减小主要操作表的数据量,提高整体数据库的性能。着电商系统的发展,单个商品表中的数据量可能会迅速膨胀,造成查询和维护上的困难。架构师需推动“样本结构标准化”工作,将样本、标
数据库分库分表与模型训练样本分区
在AI架构中,数据库是一切智能能力的基石。无论是用户习惯分析,购买行为排序,还是AIGC结果的评分与选择,都依赖于大量的历史行为、环境元数据和多模态数据的综合分析。然而,随着用户体量的增长和交互处理的高并发质变,传统的单一数据库性能已经无法承载巨量数据的缓存、精筛、进程和分析需求。于是,分库分表技术展示出极其重要的地位,而对于AI模型训练而言,如何构建高效、可分布、可切割的样本分区系统,也是创建矩阵程序、行为分类和个性化推荐的基础之一。
1. 数据库分库分表策略
分库分表策略是实现数据库水平扩展的关键技术之一,它帮助系统管理庞大的数据,同时保证高效的数据访问。
在电商系统中,商品数据通常包括商品的基本信息、价格、库存、评价等,对这些信息的高效访问直接关系到用户体验和系统性能。
(1)分库策略。
电商系统中的商品种类繁多,为了提高数据管理的效率和查询速度,可以对商品信息按照不同的维度(如品类、品牌)进行分库操作。这有助于将数据进行物理隔离,降低单个数据库的负载,提高系统的整体性能。
- 按品类分库:将不同品类的商品存储在不同的数据库中。例如,将电子产品、服饰、家居用品分别存放在3个独立的数据库中,以便针对不同品类的商品实施特定的优化策略。
- 按品牌分库:对于品牌集中度较高的商品,可以考虑按品牌进行分库。这有助于品牌专场营销时快速查询某个品牌下的所有商品,同时便于管理和分析数据。
例如,将商品信息按品类分库,如图2-所示。
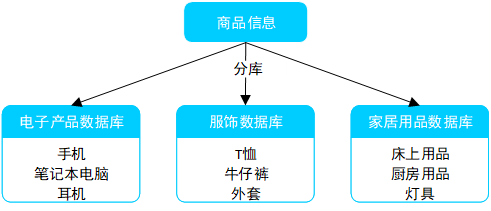
图2- 将商品信息按品类分库
(2)分表策略。
随着电商系统的发展,单个商品表中的数据量可能会迅速膨胀,造成查询和维护上的困难。通过分表策略,可以将大表拆分成多个小表,有助于分散单表的数据量压力,提高查询和写入性能。
- 垂直分表:将一个表按照业务功能或数据使用频率进行列的拆分,每个表都存储部分列。例如,将商品表分为商品基础信息表和商品详细信息表,分别存储基础信息(例如商品名称、价格、类别等)和详细信息(例如商品描述、评价等)。
- 水平分表:将表中的行按某个规则分散到多个表中,每个表都存储一部分行。例如,将商品表按商品上架时间分表(如按上架月份分表存储商品数据)、按商品ID范围分表等。
例如,根据商品ID范围将电子产品数据库中的手机表水平分为多个表,如图2-所示。
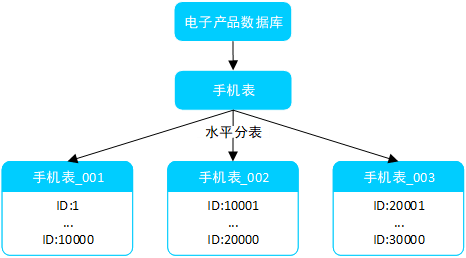
图2- 对手机表按商品ID进行水平分表
再比如,用户信息表可能包含的字段:用户ID、姓名、电子邮箱、电话号码、地址、生日、注册日期、最后登录时间等。随着时间的推移,这个表的数据量会变得非常大,查询和更新操作可能会变得缓慢。为了优化性能,可以采用垂直分表策略,将用户信息表拆分为用户基础信息表和用户详细信息表,如图2-所示。
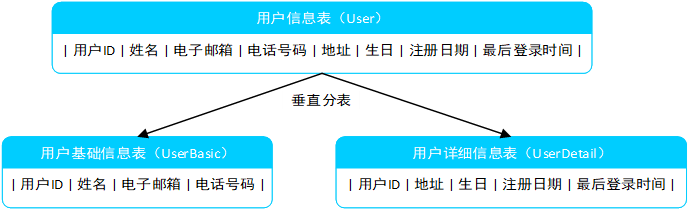
图2- 对用户信息表进行垂直分表
通过这种方式,当需要查询用户的基础信息时,只需要查询UserBasic表,而不必每次都去加载包含大量非必需数据的原始表。这不仅提高了查询效率,也简化了数据管理。同时,对于不频繁变动的详细信息,将其分离到UserDetail表中,可以减小主要操作表的数据量,提高整体数据库的性能。
此外,这种分表方式需要维护表间的关联,如通过用户ID关联UserBasic表和UserDetail表。这可能会带来关联查询的需求,设计时需要考虑如何高效地实现这些关联操作。
2. 模型训练样本分区
所谓“样本分区”,是指在数据湖或样本仓中,依据业务逻辑或模型需求,将全量样本划分为若干可独立加载、组合与调度的数据子集。样本分区不仅是数据整理方式,更是加速训练、提升模型效果与支持多任务调度的关键能力。
一个合理的样本分区策略应满足以下特性。
- 可控性:分区方式应基于清晰的业务或模型维度(如用户地域、数据生成时间、用户类型等);
- 均衡性:各分区数据量应尽可能均衡,防止训练资源倾斜;
- 可组合性:应支持多个分区组合训练,如训练某区域用户模型、测试新用户策略等;
- 可调度性:便于AI训练平台批量加载、并行处理与快速调试。
(1)样本分区的常见方式
根据不同的业务与模型场景,样本分区通常采用以下几种方法。
- 按时间分区:最常见方式,用于支持按日、周、月训练或回归实验;
- 按人群标签分区:如高活跃用户、新用户、付费用户等,支持用户画像驱动的模型定向训练;
- 按模型目标分区:如点击模型、转化模型、兴趣预测模型,每类模型使用不同特征结构的数据分区;
- 按样本来源系统分区:如Web端、App端、IoT端,不同来源产生的样本结构不同,需分别建模;
- 按实验批次分区:配合A/B测试体系,记录各实验组样本,以便离线复现与模型对比。
(2)样本分区的底层存储设计
样本分区的物理载体通常构建于如下存储系统之上。
- 数据湖(如HDFS、OSS):适用于大规模分布式存储,支持原始数据、多版本样本的存储;
- 特征仓(如Hive、ClickHouse、Doris):支持列式存储与高并发读取,适合结构化训练样本;
- 样本缓存层(如HBase、Redis、Kafka):用于在线学习与快速样本访问;
- 向量存储系统(如Milvus):管理嵌入样本、向量召回结构,服务于语义类模型。
提示:
设计时需注意,每类存储系统应基于样本使用场景进行选择。例如,深度模型训练阶段需要批量读取大量特征数据,建议以分区表结构加载;而在线模型增量学习则需支持实时样本追加、快速查询。
(3)特征切分策略与样本配套结构
为了使训练数据具备更好的模块性与复用性,样本往往需要和“特征工程产物”配套存储与同步。常见的做法如下。
- 样本-特征双轨分区:即样本分区和特征仓分区保持一致,例如样本 train_2025_05_20 对应特征表 feature_user_2025_05_20;
- 静态特征与动态特征解耦:将用户画像类特征(如性别、注册天数)独立存放为快照文件,每天更新;而行为类特征(如点击次数、停留时长)则按小时或分钟粒度更新;
- 分批导出与多版本缓存:支持不同模型请求不同分区的特征文件,如基础模型使用全量特征,高阶模型使用时间窗口特征。
为了保证样本调度的精准性,特征与样本的绑定必须在ETL阶段实现,例如在样本生成时直接附带特征索引或哈希键,后续训练过程可通过Join方式加载。
3. 架构师在分库分表与样本分区设计中的职责定位
AI架构师在设计数据分库、分表与样本分区体系时,既要理解业务增长与技术边界之间的张力,又要协调数据工程与模型工程之间的耦合点。其关键职责包括但不限于以下几点:
(1)系统容量规划与横向扩展路线设计
架构师应根据系统每日新增数据量、用户增长趋势、访问并发预测,规划数据库分片上限、分表扩展策略与分区粒度。例如:商品库设计支持100亿商品,初期每月按商品类型分表,后期可按商家再分库。
(2)样本仓建设规范制定
架构师需制定全公司统一的样本仓存储规范,包括分区命名规则、数据精度要求、缺失值处理机制、样本版本控制策略等。例如:
所有样本应包含“partition_id、sample_version、feature_source”字段;
每次模型训练日志需记录样本分区及时间戳,支持模型回滚验证。
(3)特征与样本的解耦与接口设计
架构师需推动“样本结构标准化”工作,将样本、标签与特征数据物理解耦,逻辑绑定,形成跨平台、跨任务复用的数据接口体系,便于服务化调用与平台化托管。
(4)架构治理与数据血缘追踪
架构师应推动样本调度链路的血缘追踪能力建设,确保每一批样本的数据来源、ETL逻辑、使用记录可查询、可验证。例如,通过元数据管理平台建立样本 → 特征 → 数据表 → 源日志的完整路径索引。
(5)建立端到端的自动化训练通路
架构设计最终应服务于效率提升与AI工程化能力落地。架构师需与数据团队协作,建设“从日志采集 → 样本分区 → 特征同步 → 模型训练 → 验证回流”的完整闭环,并通过CI/CD系统将其标准化与自动化,从而支撑快速迭代与多模型上线。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 17
17 0
0- 0



 已为社区贡献15条内容
已为社区贡献15条内容

所有评论(0)