李飞飞《Agent AI综述》
实现“物理世界的通用智能”,即在开放、动态环境中完成多样化任务(如烹饪、清洁、工业协作)。:基于预训练模型(如RT-2、VoxPoser)实现对未见过物体或场景的适应。:依赖深度学习模型(如CNN、Transformer)提取环境结构与语义。直接与环境进行物理接触(如机械臂操作物体、自动驾驶算法识别障碍物)。构建环境的几何模型(3D点云)和语义模型(物体类别、空间关系)。结合视觉与触觉数据,提升对
李飞飞团队在《具身智能体综述:迈向物理世界的通用智能》(Embodied Agents: Toward General Intelligence in the Physical World)中系统性地阐述了具身智能体(Embodied Agent)的理论框架、技术挑战及未来方向,为该领域提供了全面的学术指引。以下是核心要点:
1. 核心概念:具身智能体的定义与目标
定义:具身智能体是“在物理世界中通过感知、行动与环境交互的智能系统”,其核心特征包括:
- 物理交互:直接与环境进行物理接触(如机械臂操作物体、自动驾驶算法识别障碍物)。
- 多模态感知:融合视觉、触觉、听觉等多源信息。
- 动态决策:实时适应环境变化,执行复杂任务。
- 目标:实现“物理世界的通用智能”,即在开放、动态环境中完成多样化任务(如烹饪、清洁、工业协作)。
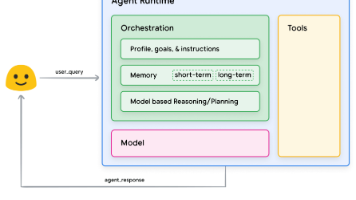
2. 技术框架:从感知到行动的闭环系统
2.1 感知层:多模态信息处理
- 视觉感知:依赖深度学习模型(如CNN、Transformer)提取环境结构与语义。
- 触觉反馈:通过触觉传感器(如GelSight)获取物体材质、形状等物理属性。
- 跨模态融合:结合视觉与触觉数据,提升对物体状态(如软硬、滑动)的准确判断。
2.2 理解层:环境建模与任务规划
- 场景建模:构建环境的几何模型(3D点云)和语义模型(物体类别、空间关系)。
- 任务分解:将自然语言指令(如“帮我泡杯咖啡”)转化为子任务序列(取杯子→接水→放咖啡粉)。
- 物理推理:预测物体运动轨迹与环境变化(如预测水杯倾斜后液体流动方向)。
2.3 执行层:实时控制与适应
- 运动规划:生成机械臂或移动机器人的安全、高效运动轨迹。
- 反馈控制:通过传感器数据实时调整动作(如抓取时根据物体滑动调整力度)。
- 零样本泛化:基于预训练模型(如RT-2、VoxPoser)实现对未见过物体或场景的适应。
3. 关键技术挑战
- 感知-动作的时序一致性:如何处理传感器噪声与环境延迟,确保动作的准确性。
- 多任务泛化能力:在有限训练数据下,如何实现对新任务、新环境的快速适应。
- 物理交互的安全性:避免对环境或人类造成伤害(如碰撞检测、力控制)。
- 数据与算力需求:大规模真实环境数据采集与高效推理算法的矛盾。
4. 应用与落地场景
- 服务机器人:家庭助手(如打扫卫生、照护老人)、餐饮服务。
- 工业自动化:智能工厂中的柔性生产线、质量检测。
- 自动驾驶:复杂交通场景中的决策与控制(如避障、路径规划)。
- 人机协作:通过自然语言指令实现人与机器的无缝配合。
5. 未来研究方向
- 多模态预训练模型:开发能同时处理视觉、触觉、语言等数据的通用模型。
- 物理世界仿真:构建高保真模拟环境,加速算法训练与验证(如Log2world)。
- 人机交互接口:自然语言、手势等更直观的控制方式。
- 伦理与安全:制定具身智能体的行为准则,避免滥用风险。
总结
李飞飞团队的具身智能体研究强调“从数据到决策的端到端闭环”,通过融合感知、理解与行动能力,推动机器从“被动观察者”转变为“主动参与者”。该框架不仅为机器人技术提供新思路,也为自动驾驶、智能制造等领域带来潜在突破。随着多模态大模型与物理世界建模技术的进步,具身智能体有望成为连接数字世界与物理世界的桥梁。


有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 12
12 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)