LMDeploy 部署
使用结合W4A16量化与kv cache量化的internlm2_5-1_8b-chat模型封装本地API并与大模型进行一次对话,作业截图需包括显存占用情况与大模型回复,参考4.1 API开发,请注意2.2.3节与4.1节应使用作业版本命令。使用Function call功能让大模型完成一次简单的"加"与"乘"函数调用,作业截图需包括大模型回复的工具调用情况,参考4.2 Function call
文章目录
基础任务
任务一 量化
使用结合W4A16量化与kv cache量化的internlm2_5-1_8b-chat模型封装本地API并与大模型进行一次对话,作业截图需包括显存占用情况与大模型回复,参考4.1 API开发,请注意2.2.3节与4.1节应使用作业版本命令。
1. 非量化时显存占用情况(50% A100)

未量化的模型参数 14GB
kv cache 20.8GB = (40-14) * 0.8 GB
其他运行占用 0.6 GB 左右
总共 35.4 GB
2. 设置 kv cache 比例后显存占用情况
执行以下语句
conda activate lmdeploy
lmdeploy chat /root/models/internlm2_5-7b-chat --cache-max-entry-count 0.4

未量化的模型参数 14GB
kv cache 10.4GB = (40-14) * 0.4 GB
其他运行占用 0.78 GB 左右
总共 25.1 GB
3. 设置在线 kv cache 量化
执行以下语句
lmdeploy serve api_server \
/root/models/internlm2_5-7b-chat \
--model-format hf \
--quant-policy 4 \
--cache-max-entry-count 0.4\
--server-name 0.0.0.0 \
--server-port 23333 \
--tp 1
显存占用情况跟上面相似,但此时可以存储更多的元数据
4. W4A16 模型量化和部署
W4A16的量化配置意味着:
- 权重被量化为4位整数。
- 激活保持为16位浮点数。
执行以下命令,使用1.8B模型进行尝试
lmdeploy lite auto_awq \
/root/models/internlm2_5-1_8b-chat \
--calib-dataset 'ptb' \
--calib-samples 128 \
--calib-seqlen 2048 \
--w-bits 4 \
--w-group-size 128 \
--batch-size 1 \
--search-scale False \
--work-dir /root/models/internlm2_5-1_8b-chat-w4a16-4bit
4.1 量化前后模型大小对比
量化模型大小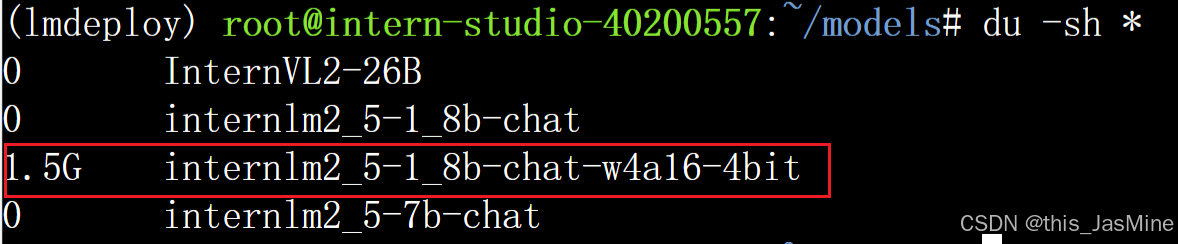
原模型大小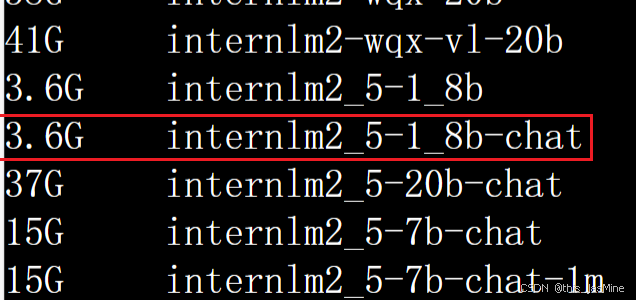
4.2 量化后模型运行显存占用情况
1.8B 的 模型
5. W4A16 + KV cache + KV cache量化
执行以下指令(使用量化后的 1.8B 模型)
lmdeploy serve api_server \
/root/models/internlm2_5-1_8b-chat-w4a16-4bit/ \
--model-format awq \
--quant-policy 4 \
--cache-max-entry-count 0.4\
--server-name 0.0.0.0 \
--server-port 23333 \
--tp 1
得到结果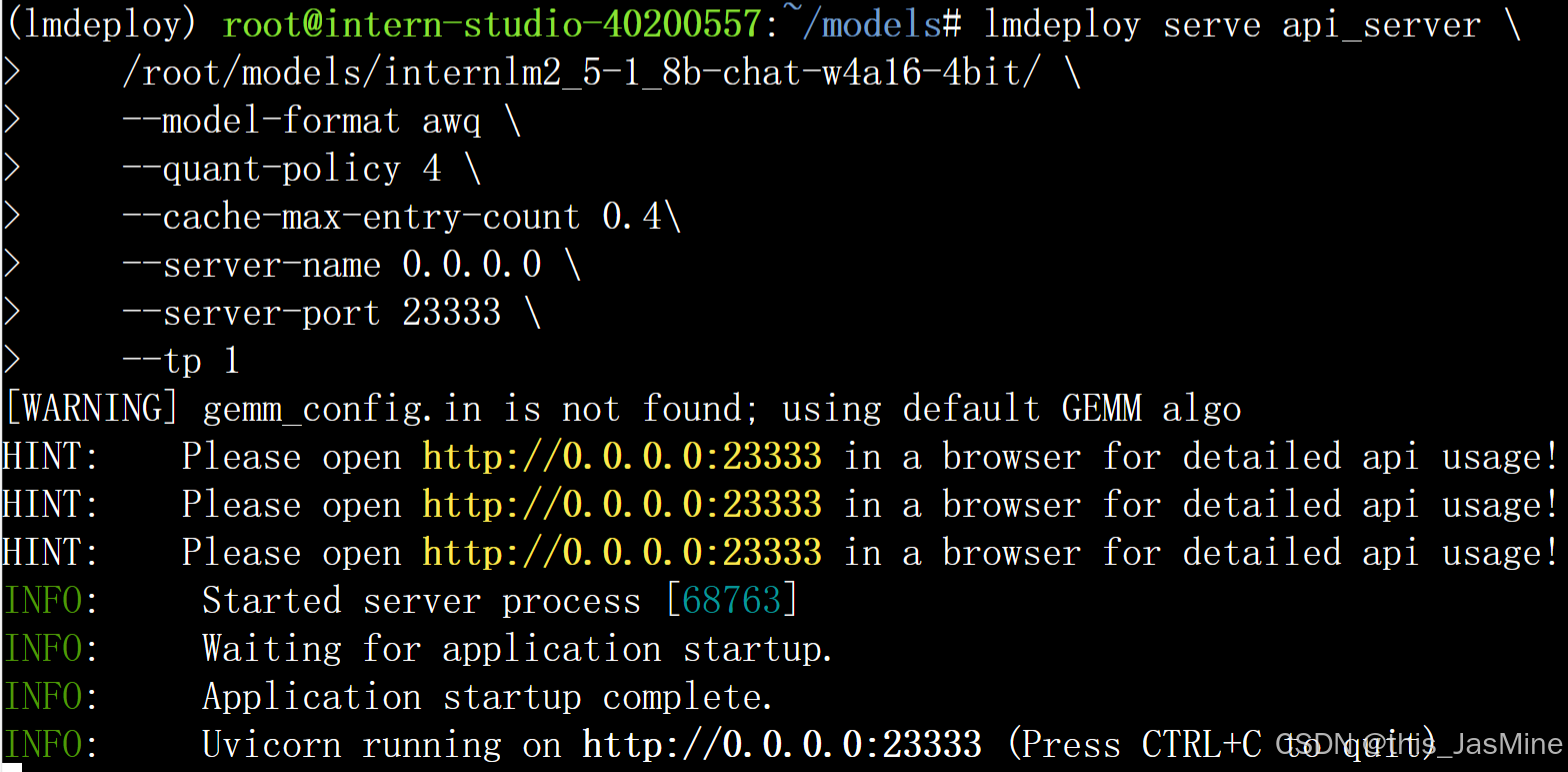
此时的显存占用
启动 API 服务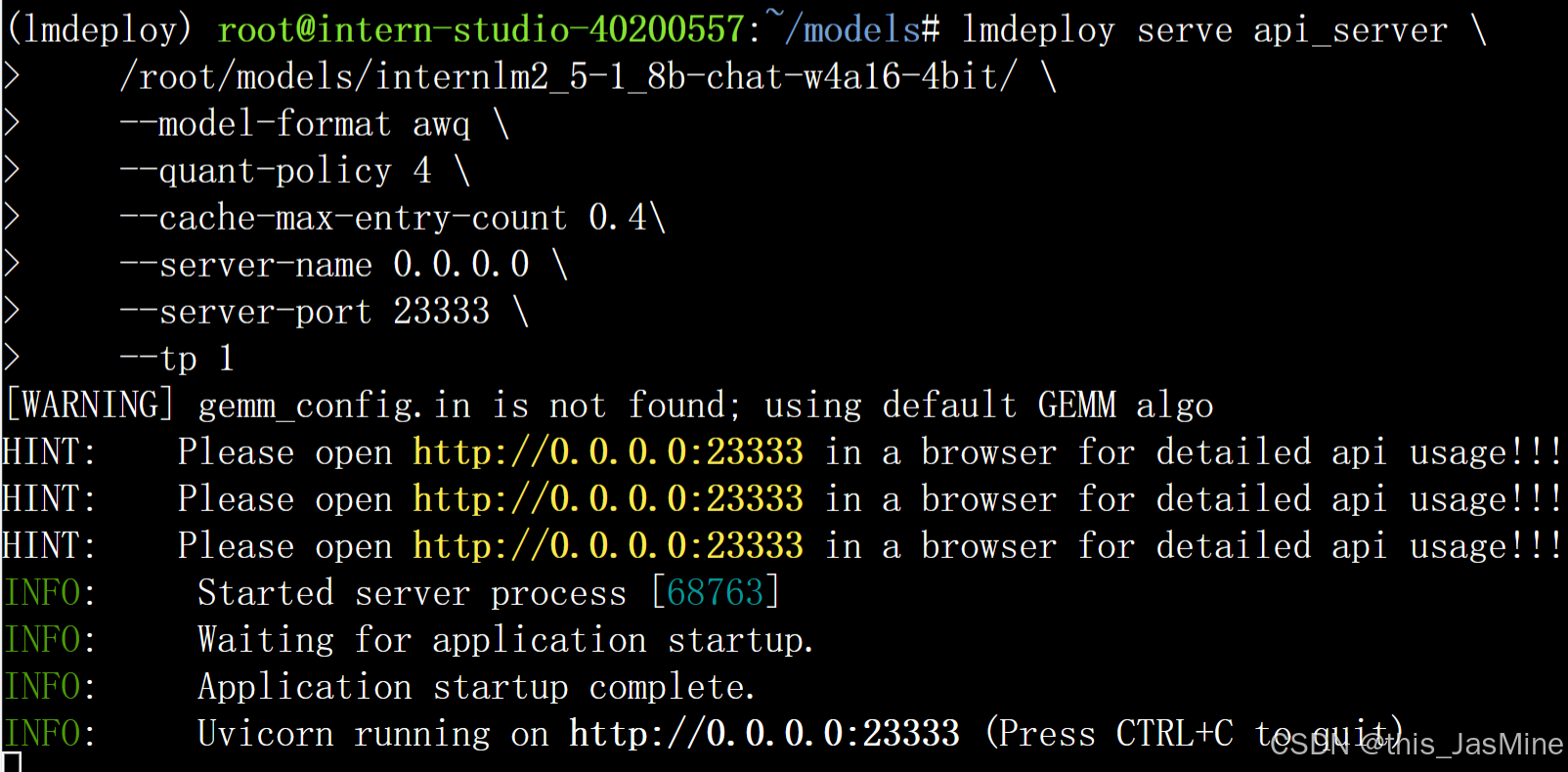
使用命令行调用API对话
任务二 Function call
使用Function call功能让大模型完成一次简单的"加"与"乘"函数调用,作业截图需包括大模型回复的工具调用情况,参考4.2 Function call(选做
一个奇怪的报错: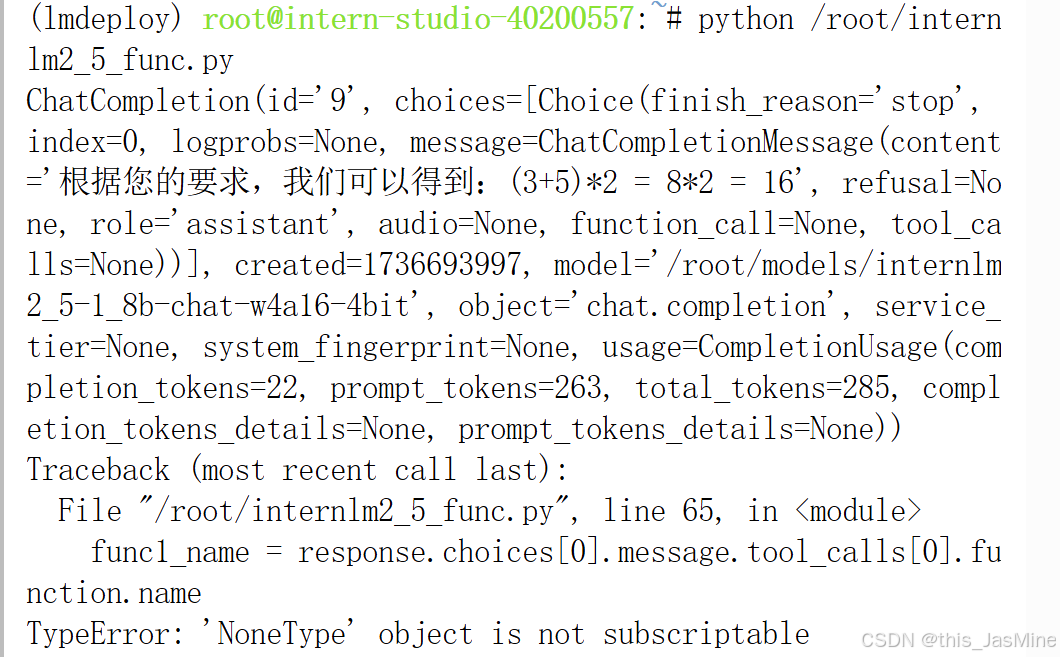


有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 13
13 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)