RAG-1-RAG简介和读取文本
Document 类是 LangChain 中的核心组件,它定义了文档对象的基本结构,主要包含两个关键属性:page_content:存储文档的实际内容metadata:存储文档的元数据,如来源、创建时间等这个简单而强大的数据结构在整个 RAG 流程中扮演着关键角色,是文档加载器、分割器、向量数据库和检索器之间传递数据的标准格式。LangChain 提供了丰富的文档加载器,支持从多种数据源加载文档
RAG入门
RAG概念
RAG(Retrieval Augmented Generation)顾名思义,通过检索外部数据,增强大模型的生成效果。RAG即检索增强生成,为LLM提供了从某些数据源检索到的信息,并基于此修正生成的答案。RAG基本上是Search + LLM 提示,可以通过大模型回答查询,并将搜索算法所找到的信息作为大模型的上下文。查询和检索到的上下文都会被注入到发送到 LLM 的提示语中。
LLM的局限性
将大模型应用于实际业务场景时会发现,通用的基础大模型基本无法满足我们的实际业务需
求,主要有以下几方面原因:
● LLM的知识不是实时的,不具备知识更新
● LLM可能不知道你私有的领域/业务知识
● LLM有时会在回答中生成看似合理但实际上是错误的信息
为什么会用到RAG?
1、提高准确性: 通过检索相关的信息,RAG可以提高生成文本的准确性。
2、减少训练成本:与需要大量数据来训练的大型生成模型相比,RAG可以通过检索机制来减少所
需的训练数据量,从而降低训练成本。
3、适应性强:RAG模型可以适应新的或不断变化的数据。由于它们能够检索最新的信息,因此在
新数据和事件出现时,它们能够快速适应并生成相关的文本
RAG vs Fine-tuning
RAG(检索增强生成)是把内部的文档数据先进行embedding,借助检索先获得大致的知识范围
答案,再结合prompt给到LLM,让LLM生成最终的答案
Fine-tuning(微调)是用一定量的数据集对LLM进行局部参数的调整,以期望LLM更加理解我
们的业务逻辑,有更好的zero-shot能力。
RAG系统工作流程图解
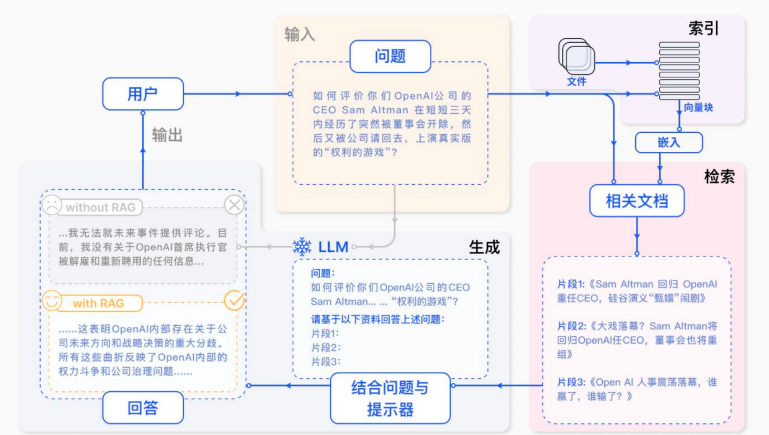
RAG具体实现流程:
-
文件加载:从多源读取原始文档
-
文本处理:
-
格式标准化
-
内容分割
-
-
向量转换:将文本片段转化为向量并存储
-
智能检索:
-
用户查询向量化
-
匹配最相关的top k文本片段
-
-
问答生成:
-
将检索结果作为上下文
-
结合问题生成prompt
-
提交大语言模型获取答案
-
RAG系统文档处理要点:
-
文档加载:支持多格式源文件读取
-
预处理:完成格式转换和内容分割
-
向量化:建立可检索的向量数据库
-
检索增强:基于语义匹配获取相关知识
-
答案生成:利用大模型能力产出最终回答
文件加载
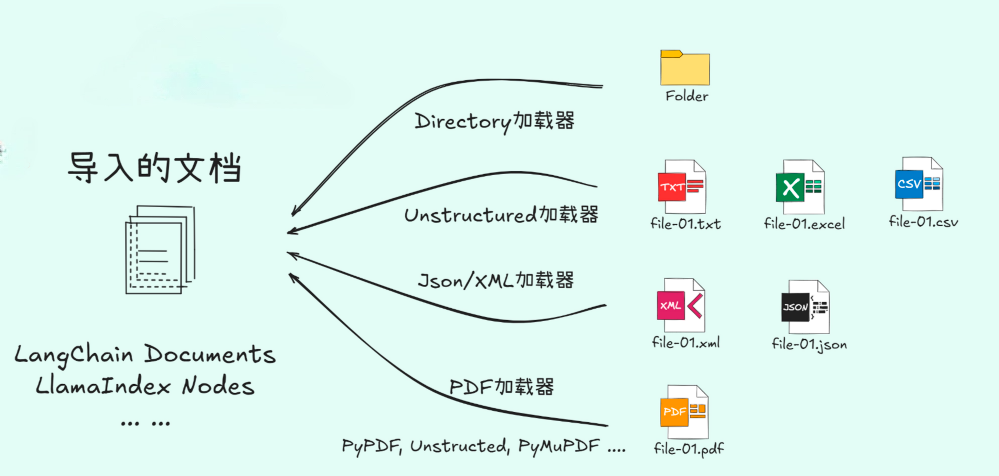
Document 组件
Document 类简介
Document 类是 LangChain 中的核心组件,它定义了文档对象的基本结构,主要包含两个关键属性:
-
page_content:存储文档的实际内容
-
metadata:存储文档的元数据,如来源、创建时间等
这个简单而强大的数据结构在整个 RAG 流程中扮演着关键角色,是文档加载器、分割器、向量数据库和检索器之间传递数据的标准格式。
Document 组件的作用
-
统一数据格式:无论原始数据来自何种源(PDF、网页、数据库等),最终都会被转换为统一的 Document 格式
-
元数据管理:通过 metadata 字段保存文档的额外信息,便于后续检索和溯源
-
状态传递:在各个处理组件之间传递数据时保持数据的一致性
LangChain 文档加载器详解
文档加载器概述
LangChain 提供了丰富的文档加载器,支持从多种数据源加载文档:
-
文本文件
-
Markdown 文档
-
Office 文档(Word、Excel、PowerPoint)
-
PDF 文件
-
网页内容
-
数据库记录等
文本加载
案例:
from langchain_unstructured import UnstructuredLoader
text_file_path = "../deepseek百度百科.txt"
loader = UnstructuredLoader(text_file_path)
documents = loader.load()
print('加载的文档数量:', len(documents))
print('第一个文档内容:', documents[0].page_content)
print('第一个文档元数据:', documents[0].metadata)加载目录:
from langchain_community.document_loaders import DirectoryLoader
loader = DirectoryLoader(
"../data",
glob="**/*.txt", # 匹配所有子目录中的txt文件
loader_cls=UnstructuredLoader,
show_progress=True # 显示加载进度
)
documents = loader.load()
print(len(documents))markdown加载
from langchain_community.document_loaders import UnstructuredMarkdownLoader
markdown_path = "../data/简介.md"
loader = UnstructuredMarkdownLoader(
markdown_path
)
data = loader.load()
print(data[0].page_content[:250])
loader = UnstructuredMarkdownLoader(markdown_path, mode="elements")
data = loader.load()
print(f"Number of documents: {len(data)}\n")
for document in data:
print(f"{document}\n")网页加载
from langchain_unstructured import UnstructuredLoader
page_url = "https://baike.baidu.com/item/%E4%BA%BA%E5%B7%A5%E6%99%BA%E8%83%BD/9180"
loader = UnstructuredLoader(web_url = page_url)
docs = loader.load()
for doc in docs[:5]:
print(f'{doc.metadata}: {doc.page_content}')
ppt加载
from unstructured.partition.ppt import partition_ppt
ppt_elements = partition_ppt(filename="人工智能培训.pptx")
print("ppt 内容:")
for element in ppt_elements:
print(element.text)
from langchain_core.documents import Document
#转换为Documents数据结构
documents = [Document(page_content=element.text, metadata={"source": "人工智能培训.pptx"}) for element in ppt_elements]
print(documents)图片加载
from langchain_community.document_loaders import UnstructuredImageLoader
image_path = "美女.jpg"
loader = UnstructuredImageLoader(image_path)
data = loader.load()
print(data)pdf加载
from unstructured.partition.pdf import partition_pdf
# 全局设置
# 解析 PDF 结构,提取文本和表格
file_path = "page-1-5.pdf" # 修改为你的文件路径
IMAGE_OUT_DIR="images"
elements = partition_pdf(
file_path,
strategy="hi_res", # 使用高精度策略
infer_table_structure=True, # 推断表格结构
extract_images_in_pdf=True, #提取图片
# max_characters=4000, # 每个文本块最大字符数
# new_after_n_chars=3800, # 达到3800字符后分新块
# combine_text_under_n_chars=2000, # 合并小于2000字符的文本块
# chunking_strategy = "by_title", # 按标题分块
extract_image_block_output_dir=IMAGE_OUT_DIR, #图片提取路径
) # 解析PDF文档
# 创建一个元素ID到元素的映射
element_map = {element.id: element for element in elements if hasattr(element, 'id')}
for element in elements:
print("\n数据类型:",element.category)
print("元数据:", vars(element.metadata)) # 使用vars()显示所有元数据属性
print("内容:")
print(element.text) # 打印表格文本内容
# 获取并打印父节点信息
parent_id = getattr(element.metadata, 'parent_id', None)
if parent_id and parent_id in element_map:
parent_element = element_map[parent_id]
print("\n父节点信息:")
print(f"类型: {parent_element.category}")
print(f"内容: {parent_element.text}")
if hasattr(parent_element, 'metadata'):
print(f"父节点元数据: {vars(parent_element.metadata)}") # 同样使用vars()显示所有元数据
else:
print(f"未找到父节点 (ID: {parent_id})")
print("-" * 50)

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 20
20 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)