大模型工作流程详解
大模型处理文本的核心流程分为三个阶段:1)输入处理,将文本分词、嵌入为向量并添加位置编码;2)模型计算,通过多层Transformer结构进行上下文理解和推理;3)输出生成,将概率分布转换为文本并循环生成完整内容。整个过程实现了"文本→数字→计算→数字→文本"的转换,结合符号处理和神经网络计算,使模型能够理解和生成人类语言。
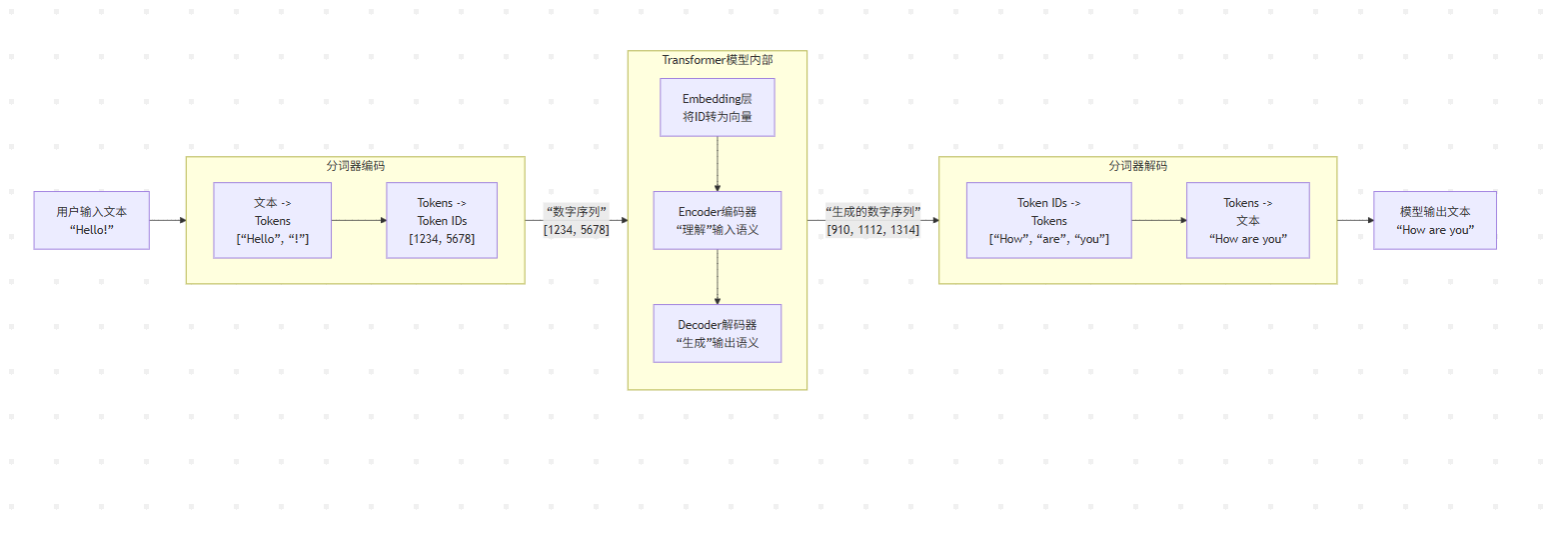
这个过程可以清晰地分为三个核心阶段:① 输入处理 -> ② 模型计算 -> ③ 输出生成。
整个流程的核心在于,文本(人类语言)必须被转换为数字(模型语言)才能被处理,最终再转换回文本。
第一阶段:输入处理(从文本到模型能懂的数字)
这一步的目标是将人类输入的原始文本,转化为模型能够理解的数值表示。它就像是一个翻译官,把一句话翻译成计算机能处理的“密码”。
- 分词 (Tokenization)
• 任务:将输入的句子或段落拆分成模型词汇表中存在的更小的单元(Tokens)。这些单元可能是词、子词或符号。
• 例子:输入:“你好!” -> 分词后:[“你”, “好”, “!”]。
• 输出:一个Token列表。每个Token都会被映射到词汇表中的一个整数ID。例如:[101, 202, 999]。
- 嵌入 (Embedding)
• 任务:将每个Token的整数ID转换成一个高维的、稠密的浮点数向量(称为“嵌入向量”或“词向量”)。
• 为什么:计算机无法直接理解数字ID的含义。这些向量被设计为:语义相近的词,其向量在空间中的距离也更近。模型通过这种方式“理解”词语的意义。
• 输出:一个向量矩阵。例如,ID 101 (“你”) 可能被转换为向量 [0.12, 0.84, -0.23, …, 0.45] (维度可能是4096维)。
- 位置编码 (Positional Encoding)
• 问题:Transformer的自注意力机制本身没有顺序概念。打乱单词顺序,它计算出的结果是一样的。但语言顺序至关重要。
• 解决方案:为每个词在序列中的位置生成一个独一无二的向量,然后加到其词嵌入向量上。
• 效果:让模型明确知道每个词的位置和顺序信息。
至此,输入的文本已经变成了一个既包含语义信息,又包含位置信息的数值矩阵,可以被送入模型的核心部分进行计算。
第二阶段:模型计算(Transformer的核心推理)
这是大模型的“大脑”,负责进行复杂的数学运算和推理。其核心是Transformer的解码器结构(如GPT系列)或编码器-解码器结构(如T5)。
- 层层处理 (Nx Transformer Blocks)
• 模型由数十个甚至上百个相同的Transformer层堆叠而成。
• 每一层都主要包含两个子层:
◦ 自注意力机制 (Self-Attention):让序列中的每一个词都能与序列中的所有其他词(包括自己)进行交互和加权汇总。这使得模型能够真正地理解上下文。例如,在处理句子中的“它”这个词时,模型会自动将注意力集中到其指代的前文“苹果”上。
◦ 前馈神经网络 (Feed-Forward Network):对自注意力的输出进行进一步的非线性变换和加工,增强模型的表达能力。
• 残差连接 (Add) 和 层归一化 (Norm):环绕在每个子层周围,确保深层网络能够稳定训练,防止梯度消失。
- 生成隐藏状态 (Hidden States)
• 经过所有层的处理后,最后一个Transformer层为每个输入Token输出一个最终的隐藏状态向量。
• 这个向量是模型对“在这个上下文中,这个位置应该是什么”的终极理解。
第三阶段:输出生成(从数字回到文本)
模型计算出的隐藏状态依然是数字向量,我们需要将其变回人类可以读懂的文本。这个过程是逐步且自回归的。
-
投影到词汇表 (Projection to Vocabulary)
• 将最后一个Token对应的隐藏状态向量(代表模型对“下一个词”的思考结果)通过一个线性层(Linear Layer) 映射到一个非常大的向量,其维度与词汇表大小相同。这个向量称为 logits。 -
转换为概率分布 (Softmax)
• 将 logits 输入 Softmax 函数,将其转换为一个概率分布。这个分布中的每个值代表词汇表中每个词作为“下一个词”出现的概率。
• 例如,P(“Hello”) = 0.8, P(“Hi”) = 0.15, P(“Howdy”) = 0.05 …
- 采样 (Sampling)
• 模型不会总是简单地选择概率最高的词(贪婪搜索),那样会生成枯燥且可预测的文本。
• 而是会根据一种采样策略从概率分布中选取下一个词。常用策略包括:
◦ 温度采样 (Temperature):调整分布的平滑程度。温度越高,选择越随机、越有创意;温度越低,选择越确定、越保守。
◦ 核采样 (Top-p Sampling):从概率累积达到p的最小候选集合中随机选择。
• 这一步为AI生成文本带来了随机性和创造性。
- 解码与循环 (Decoding & Loop)
• 将采样得到的词(的ID)追加到输入序列的末尾。
• 整个流程(从分词到采样)重复进行,模型基于之前生成的所有词来预测下一个词,直到生成一个标志结束的特殊Token(如 )或达到最大长度限制。
- 最终分词解码 (Final Tokenization Decode)
• 将生成的所有Token IDs序列,送回最开始使用的同一个分词器。
• 分词器执行反向操作(解码),将这些IDs转换回字符串并拼接起来,形成最终的、人类可读的输出文本。
总结
整个流程是一个精妙的 “文本 -> 数字 -> 计算 -> 数字 -> 文本” 的循环。
- 输入处理:将文本符号转化为数值向量。
- 模型计算:在向量空间中进行复杂的数学变换和推理,理解上下文并预测下一个词的概率分布。
- 输出生成:根据概率分布抽样,将选中的数字ID循环反馈给模型,最终全部转换回文本符号。
这个过程完美地结合了符号主义(分词)和连接主义(向量计算与神经网络),使得大模型能够理解和生成人类语言。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 8
8 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)