揭秘MCP:让AI模型拥有“超级工具箱”的魔法协议
标准化: 提供统一的AI工具接口标准安全性: 明确的权限控制和沙箱环境可组合性: 可以同时使用多个专业的MCP Server生态友好: 一次开发,多处使用MCP正在成为AI助手时代的“操作系统扩展协议”!就像浏览器通过扩展插件增强功能一样,AI助手通过MCP Server获得超能力。🦸。
开篇:AI的困境与MCP的诞生 🤔
想象一下这个场景:
-
你 🗣️ -> 🤖:“Hey ChatGPT,帮我看看项目代码里有多少个TODO注释?”
-
ChatGPT 🤖 -> ❓:“我很乐意帮忙,但我无法访问你的本地文件系统...”
我: 😫 (无奈地手动复制粘贴代码)
这就是传统AI助手的局限——它们生活在沙箱中,无法直接与你的工作环境(文件系统、数据库、API等)交互。
而 MCP (Model Context Protocol) 就是为了解决这个问题而生的!它是由OpenAI主导开发的一个开放协议,旨在为AI模型提供标准化的方式来访问外部工具、数据和资源。
简单来说,MCP就是AI模型的“USB标准接口”!🔌
| 对比项 | 没有MCP | 有MCP |
|---|---|---|
| 能力范围 | 局限于模型内部知识 | 可扩展至任何连接的工具 |
| 数据访问 | 无法访问实时/私有数据 | 可安全访问文件、数据库、API |
| 开发体验 | 每个应用各自为战 | 工具一次开发,多处使用 |
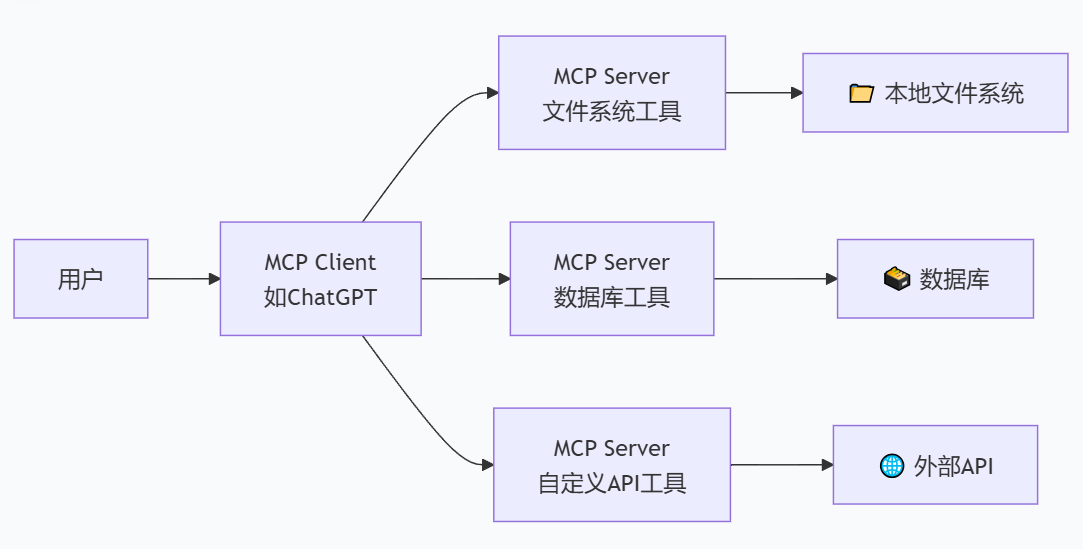
一、🧐 MCP是什么?三大核心概念
MCP的架构围绕三个核心概念构建:
1. 🗄️ Servers (服务器)
提供工具和数据的“供应商”。比如:
-
一个提供文件读写工具的Server
-
一个提供数据库查询工具的Server
-
一个提供公司内部API访问的Server
2. 🔌 Clients (客户端)
使用这些工具的“消费者”。比如:
-
OpenAI的ChatGPT桌面端
-
Claude AI桌面应用
-
任何支持MCP的AI应用
3. 📋 Resources (资源) & 🛠️ Tools (工具)
-
Resources: 静态数据源(如文件、数据库表)
-
Tools: 可执行的操作(如执行命令、调用API)
二、🚀 手把手教你写一个MCP Server
接下来,我们创建一个实用的MCP Server:一个能够搜索和阅读本地Markdown文件的工具!这将极大增强AI助手处理你文档的能力。
第0步:环境准备
首先安装必要的库:
pip install fastmcp python-dotenv第1步:创建MCP Server代码
创建一个文件 fast_markdown_server.py:
# fast_markdown_server.py
from fastmcp import FastMCP, Resource, Tool
import glob
import os
import re
from pathlib import Path
from typing import List, Optional
import json
# 初始化 FastMCP Server - 一句话搞定!
mcp = FastMCP("markdown-express", description="闪电般快速的Markdown工具服务器")
# 定义资源:Markdown文件列表
@mcp.resource("file://{name}")
def markdown_files(name: str) -> Optional[Resource]:
"""获取指定的Markdown文件资源"""
filepath = find_markdown_file(name)
if filepath and os.path.exists(filepath):
return Resource(
uri=f"file://{filepath}",
name=os.path.basename(filepath),
description=f"Markdown文件: {filepath}",
mimeType="text/markdown"
)
return None
def find_markdown_file(name: str) -> Optional[str]:
"""查找Markdown文件"""
if not name.endswith('.md'):
name += '.md'
# 先在当前目录找
if os.path.exists(name):
return name
# 递归查找
for filepath in glob.glob("**/*.md", recursive=True):
if filepath.endswith(name) or os.path.basename(filepath) == name:
return filepath
return None
# 定义工具:搜索Markdown内容
@mcp.tool()
def search_markdown(keyword: str, max_results: int = 5) -> str:
"""在所有Markdown文件中搜索关键词
Args:
keyword: 要搜索的关键词
max_results: 最大返回结果数量
"""
if not keyword:
return "请输入要搜索的关键词"
results = []
md_files = glob.glob("**/*.md", recursive=True)
for filepath in md_files:
try:
content = Path(filepath).read_text(encoding='utf-8')
if keyword.lower() in content.lower():
lines = content.split('\n')
matching_lines = [
f"第{i+1}行: {line.strip()}"
for i, line in enumerate(lines)
if keyword.lower() in line.lower()
][:3] # 每个文件最多显示3行
if matching_lines:
results.append(f"📁 文件: {filepath}")
results.extend(matching_lines)
results.append("---")
if len(results) >= max_results * 10: # 粗略限制
break
except Exception as e:
results.append(f"❌ 读取文件 {filepath} 时出错: {str(e)}")
if not results:
return f"没有在Markdown文件中找到包含 '{keyword}' 的内容"
return "\n".join(results)
# 定义工具:读取Markdown文件
@mcp.tool()
def read_markdown(filepath: str) -> str:
"""读取指定Markdown文件的内容
Args:
filepath: 文件路径(支持相对路径和文件名)
"""
actual_path = find_markdown_file(filepath)
if not actual_path:
available_files = glob.glob("**/*.md", recursive=True)
return f"❌ 找不到文件: {filepath}\n📂 可用文件:\n" + "\n".join(f" • {f}" for f in available_files)
try:
content = Path(actual_path).read_text(encoding='utf-8')
return f"📄 文件: {actual_path}\n\n{content}"
except Exception as e:
return f"❌ 读取文件时出错: {str(e)}"
# 定义工具:创建新的Markdown文件
@mcp.tool()
def create_markdown(filename: str, content: str = "", title: str = "") -> str:
"""创建新的Markdown文件
Args:
filename: 文件名(不需要.md后缀)
content: 文件内容
title: 文件标题(会自动添加为一级标题)
"""
if not filename.endswith('.md'):
filename += '.md'
try:
if title:
full_content = f"# {title}\n\n{content}"
else:
full_content = content
Path(filename).write_text(full_content, encoding='utf-8')
return f"✅ 成功创建文件: {filename}\n📝 内容长度: {len(full_content)} 字符"
except Exception as e:
return f"❌ 创建文件失败: {str(e)}"
# 定义工具:统计Markdown信息
@mcp.tool()
def analyze_markdown(filepath: str) -> str:
"""分析Markdown文件的统计信息
Args:
filepath: 要分析的文件路径
"""
actual_path = find_markdown_file(filepath)
if not actual_path:
return f"❌ 找不到文件: {filepath}"
try:
content = Path(actual_path).read_text(encoding='utf-8')
# 统计信息
lines = content.split('\n')
words = len(content.split())
characters = len(content)
# 统计标题
headings = {
'#': len(re.findall(r'^#\s', content, re.MULTILINE)),
'##': len(re.findall(r'^##\s', content, re.MULTILINE)),
'###': len(re.findall(r'^###\s', content, re.MULTILINE)),
}
# 统计代码块
code_blocks = len(re.findall(r'```.*?```', content, re.DOTALL))
return f"""📊 文件分析: {actual_path}
📈 基本统计:
• 行数: {len(lines)}
• 单词数: {words}
• 字符数: {characters}
📑 标题结构:
• 一级标题: {headings['#']}
• 二级标题: {headings['##']}
• 三级标题: {headings['###']}
💻 代码块: {code_blocks} 个
📋 预览 (前3行):
{chr(10).join(f' | {line}' for line in lines[:3])}
"""
except Exception as e:
return f"❌ 分析文件失败: {str(e)}"
# 定义工具:查找TODO项
@mcp.tool()
def find_todos(keyword: str = "TODO") -> str:
"""在所有Markdown文件中查找TODO项
Args:
keyword: 要查找的关键词(如 TODO, FIXME, NOTE等)
"""
results = []
md_files = glob.glob("**/*.md", recursive=True)
for filepath in md_files:
try:
content = Path(filepath).read_text(encoding='utf-8')
lines = content.split('\n')
todo_lines = [
f"第{i+1}行: {line.strip()}"
for i, line in enumerate(lines)
if keyword.upper() in line.upper()
]
if todo_lines:
results.append(f"📁 {filepath}:")
results.extend(todo_lines)
results.append("---")
except Exception as e:
results.append(f"❌ 读取文件 {filepath} 时出错: {str(e)}")
if not results:
return f"没有找到包含 '{keyword}' 的项"
return "\n".join(results)
# 启动服务器 - 就这么简单!
if __name__ == "__main__":
mcp.run(transport="stdio")第2步:创建测试文件
创建一些测试用的 Markdown 文件:
project_plan.md
# 项目计划
## 第一阶段
- [x] 项目初始化
- [ ] 用户认证系统 TODO: 需要设计API
- [ ] 数据库设计
## 第二阶段
- [ ] 前端界面开发
- [ ] 后端API开发 NOTE: 考虑使用FastAPI
## 注意事项
FIXME: 需要处理时区问题meeting_notes.md
# 周会记录
## 2024-05-20
### 讨论内容
1. 项目进度汇报
2. 技术方案讨论
3. 下一步计划
### 待办事项
- TODO: 安排代码评审
- TODO: 更新文档第3步:运行服务
python fast_markdown_server.py第4步:测试脚本
创建一个测试文件 test_fast_server.py:
# test_fast_server.py
import asyncio
from fastmcp import FastMCPClient
async def test_fast_server():
# 连接到我们的FastMCP Server
async with FastMCPClient.create_stdio_client(
["python", "fast_markdown_server.py"]
) as client:
# 列出所有工具
tools = await client.list_tools()
print("🛠️ 可用工具:", [tool.name for tool in tools.tools])
# 测试搜索功能
print("\n🔍 测试搜索:")
result = await client.call_tool("search_markdown", {"keyword": "TODO"})
print(result.content[0].text[:200] + "...")
# 测试读取功能
print("\n📖 测试读取:")
result = await client.call_tool("read_markdown", {"filepath": "project_plan"})
print(result.content[0].text[:150] + "...")
# 测试分析功能
print("\n📊 测试分析:")
result = await client.call_tool("analyze_markdown", {"filepath": "meeting_notes"})
print(result.content[0].text)
if __name__ == "__main__":
asyncio.run(test_fast_server())运行测试:
python test_fast_server.py三、🎯 配置 ChatGPT 使用 FastMCP Server
编辑 ChatGPT 的配置文件 (~/.config/OpenAI/config.json):
{
"mcpServers": {
"markdown-express": {
"command": "python",
"args": ["/absolute/path/to/your/fast_markdown_server.py"],
"env": {}
}
}
}现在你可以在 ChatGPT 中这样使用:
-
"搜索我所有Markdown文件中的TODO项"
-
"读取project_plan.md并帮我分析项目进度"
-
"创建一个名为ideas.md的新文件,标题为'项目创意'"
-
"分析meeting_notes.md的文档结构"
四、💡 总结:为什么MCP如此重要?
-
标准化: 提供统一的AI工具接口标准
-
安全性: 明确的权限控制和沙箱环境
-
可组合性: 可以同时使用多个专业的MCP Server
-
生态友好: 一次开发,多处使用
MCP正在成为AI助手时代的“操作系统扩展协议”!就像浏览器通过扩展插件增强功能一样,AI助手通过MCP Server获得超能力。🦸
互动环节:💬
Q1: MCP和LangChain有什么区别?
A1: LangChain是一个开发框架,帮你构建AI应用。MCP是一个协议标准,让AI应用能够安全地访问外部工具。它们可以一起使用!
Q2: 除了文件操作,MCP还能做什么?
A2: 几乎所有事情!数据库访问、API调用、系统管理、实时数据查询...只要你能用Python写出来的功能,都可以包装成MCP Server。
Q3: 如何学习更多关于MCP的知识?
A3: 访问官方文档:https://modelcontextprotocol.io,那里有详细的指南和更多示例。
未来已来,AI助手不再是被困在笼中的鸟,而是拥有了打开世界大门的钥匙!而你,刚刚学会了如何打造这样的钥匙。🔑
祝你编程愉快!下次再见! 👋

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 29
29 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)