AI 智能体与 Coze 工作流实践:手把手搭建新旧文档对比工具,高效定位内容差异
本文介绍如何利用Coze平台搭建自动化文档对比工作流,通过AI技术实现新旧版本文件的智能差异分析。工作流采用"文件读取-AI分析-结果输出"三步骤设计,支持doc、pdf等多种格式。详细讲解节点配置方法,包括文件上传参数设置、内容提取插件使用、大模型提示词优化等关键环节。测试案例显示,AI能精准识别新增、删除、修改、重排四类差异,并以清晰表格呈现结果。文章还提供模型选择、格式兼
在日常工作中,我们经常需要对比新旧文档的修改痕迹——比如核对报告的更新内容、确认合同条款的调整、检查文案的优化细节。但手动逐行对比不仅耗时,还容易遗漏排版调整或隐藏的文字修改。今天就为大家分享如何用Coze搭建一条自动化的“新旧文档内容对比工作流”,只需上传文件,就能快速输出清晰的差异对照表,适用于doc、pdf、txt等多种格式,小白也能轻松上手。
一、工作流核心逻辑:3步实现自动化对比
整个工作流的设计思路非常简洁,核心是“文件读取→AI分析对比→结果输出”的闭环,无需复杂代码,全靠节点拖拽和参数配置即可完成。具体逻辑如下:
- 输入触发
上传旧文档(需对比的原始版本)和新文档(修改后的版本),作为工作流的启动条件;
- 内容提取
通过Coze官方“文件读取”插件,分别解析两个文档的文本内容,转化为AI可识别的字符串格式;
- 智能对比
调用大模型对提取的内容进行逐段分析,定位“新增、删除、修改、重排”四类差异,并按固定表格格式整理结果;
- 结果输出
将AI生成的对比表直接返回给用户,包含原文、修改后内容及修改类型,一目了然。
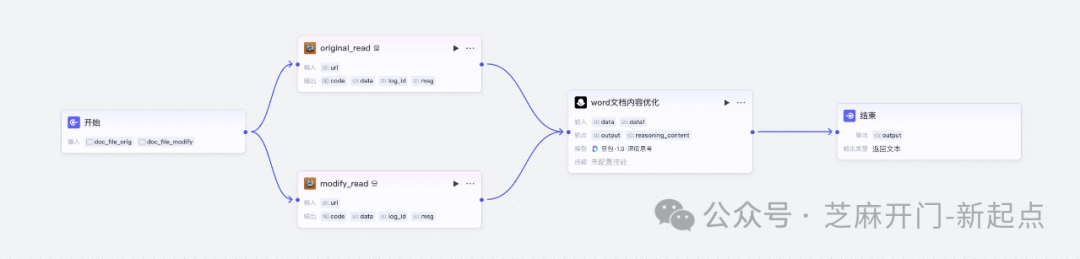
二、详细搭建步骤:从0到1配置节点
步骤1:创建“开始”节点,设置文件上传参数
“开始”节点是工作流的入口,主要作用是接收用户上传的新旧文档,配置时需注意文件格式和大小限制:
-
参数1:旧文档(doc_file_orig)
-
变量类型:
File(文件); -
描述:填写“需对比的原始文档”,方便后续区分;
-
限制:支持html、xml、doc、docx、txt、pdf、csv、xlsx格式,单个文件不超过500MB;
-
操作:勾选“必填”,确保用户不会遗漏上传。
-
-
参数2:新文档(doc_file_modify)
-
配置与旧文档完全一致,仅描述改为“修改后的文档”,避免混淆。
-
配置完成后,用户启动工作流时,只需点击“上传”按钮分别添加两个文档即可。
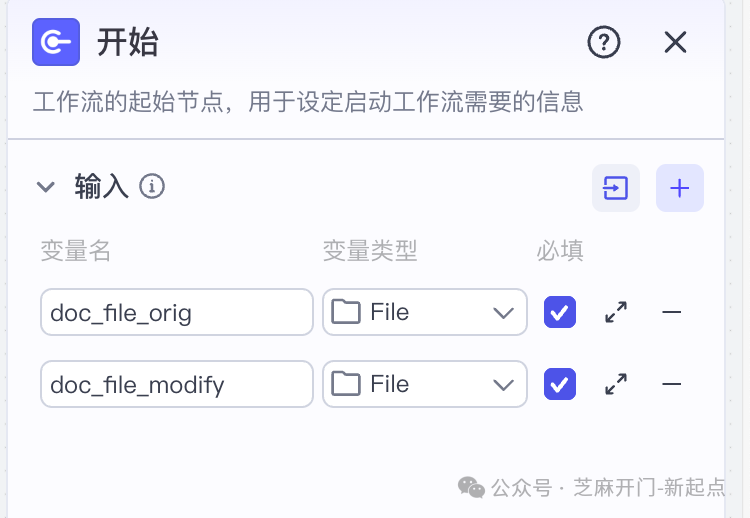
步骤2:添加“文件读取”节点,提取文档内容
这一步需要两个相同的“文件读取”节点(Coze官方插件),分别用于解析旧文档和新文档的内容,确保AI能获取到纯文本信息:
(1)旧文档读取节点(命名为“original_read”)
- 输入参数关联
将“url”参数绑定到“开始”节点的“doc_file_orig”(即用户上传的旧文档);
- 输出结果
插件会自动返回3个参数,核心是
data(文档的纯文本内容),另外两个code(状态码,0表示成功)和log_id(日志ID)可忽略,后续仅需用到data; - 注意事项
若文档含图片或复杂格式(如表格),插件会优先提取可识别的文本,图片中的文字暂不支持解析(需后续手动核对)。
(2)新文档读取节点(命名为“modify_read”)
- 配置与旧文档读取节点完全一致
仅将“url”参数绑定到“开始”节点的“doc_file_modify”(新文档),最终同样获取
data(新文档的纯文本内容)。
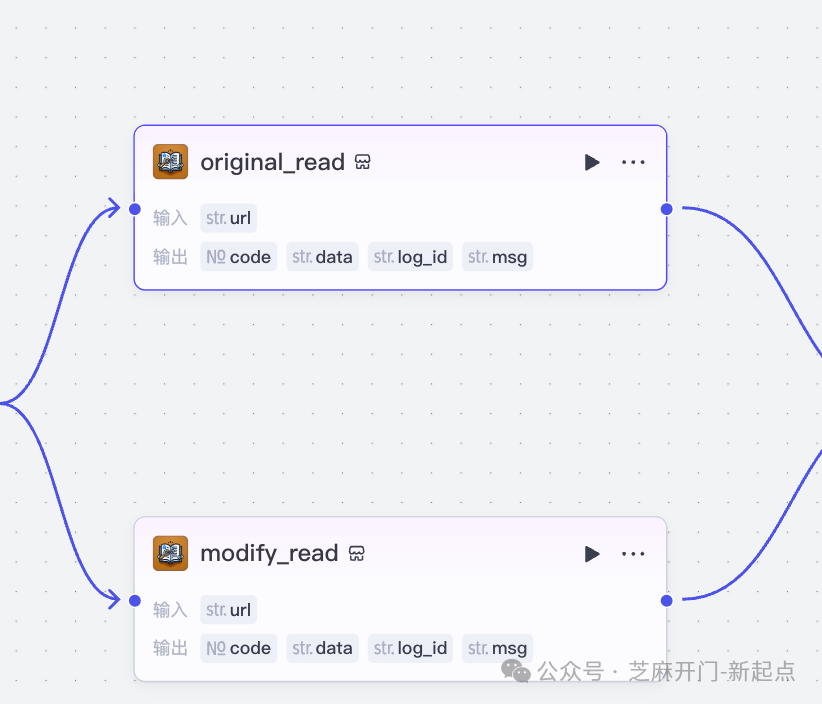
步骤3:配置“大模型”节点,实现AI对比分析
这是整个工作流的核心,需要通过提示词引导大模型精准定位差异并规范输出格式,推荐使用豆包·1.6·深度思考·多模态模型(支持256K大上下文,能处理长文档):
(1)模型参数配置
- 输入变量关联
-
变量1:
data,绑定“original_read”节点的data(旧文档内容); -
变量2:
data1,绑定“modify_read”节点的data(新文档内容);
-
- 输出格式
选择“文本”,确保结果以清晰的表格呈现,而非JSON代码。
(2)关键提示词设计(决定对比精度的核心)
提示词需要明确AI的角色、任务和输出格式,避免AI偏离需求或输出混乱。参考如下系统提示词:
# 角色
你是有10年文档审核经验的对比专家,擅长精准定位新旧文档的文字差异与排版调整。
## 技能
### 技能1:内容对比与分类
1. 逐段对比旧文档内容{{data}}和新文档内容{{data1}},找出所有不同之处(包括文字增减、表述调整、段落换行变化);
2. 将差异按“修改类型”分类:
- 新增:新文档比旧文档多的文字或段落;
- 删除:新文档比旧文档少的文字或段落;
- 修改:文字表述调整(如“很好”改为“非常好”);
- 重排:段落结构或换行调整(如某句话从第一段移到第二段,或新增换行分隔);
3. 按表格格式输出结果,表格列名为“条款编号”“原文”“修改后内容”“修改类型”,“条款编号”按差异出现的顺序编号(1、2、3...)。
## 限制
1. 仅对比{{data}}和{{data1}}的内容,不添加任何额外解读(如“建议保留原文”);
2. 若无差异,直接输出“未发现新旧文档内容差异”;
3. 表格需简洁,避免合并单元格或复杂格式。
(3)用户提示词
无需额外添加复杂内容,仅需将两个文档内容传递给AI即可:旧文档内容:{{data}} 新文档内容:{{data1}}
步骤4:添加“结束”节点,输出对比结果
“结束”节点的作用是将大模型生成的对比表返回给用户,配置非常简单:
- 输出变量关联
将“回答内容”绑定到“大模型”节点的
output(AI生成的对比结果); - 输出类型
选择“返回文本”,支持流式输出(长文档对比时,结果会逐步加载,无需等待全部生成)。
三、试运行验证:用实际案例看效果
为了测试工作流的实用性,我们用一份“那些花儿”歌词作为案例,对比旧文档(含冗余表述)和新文档(优化后版本),看看AI的对比结果是否精准:
(1)测试文档背景
-
旧文档:
那片笑声让我想起我的那些树儿
在我生命每个角落静静为我开着
我曾以为我会永远守在她身旁
今天我们已经离去在人海茫茫
她们都老了吧 她们在哪里呀
我们就这样 各自奔天涯
啦啦啦啦啦啦啦 想她
啦啦啦啦啦啦啦 她还在开吗
啦啦啦啦啦啦啦 去呀
她们已经被风吹走 散落在天涯
有些故事还没讲完那就算了吧
那些心情在岁月中已经难辨真假
如今这里荒草丛生 没有了鲜花
好在曾经拥有你们的春秋和冬夏
她们都还年轻吧 她们在哪里呀
我们就这样 各自海角
啦啦啦啦啦啦啦 想她
啦啦啦啦啦啦啦 她还在开吗
啦啦啦啦啦啦啦 去呀
她们已经被风吹走 散落在海角
啦啦啦啦啦啦啦 也罢
啦啦啦啦啦啦啦 (语气词)
啦啦啦啦啦啦啦 知道
人们就像被风吹走 插在了天涯
她们都老了吧 她们还在开吗
我们就这样 各自奔天涯新文档:
那片笑声让我想起我的那些花儿
在我生命每个角落静静为我开着
我曾以为我会永远守在她身旁
今天我们已经离去在人海茫茫
她们都老了吧 她们在哪里呀
我们就这样 各自奔天涯
啦啦啦啦啦啦啦 想她
啦啦啦啦啦啦啦 她还在开吗
啦啦啦啦啦啦啦 去呀
她们已经被风吹走 散落在天涯
有些故事还没讲完那就算了吧
那些心情在岁月中已经难辨真假
如今这里荒草丛生 没有了鲜花
好在曾经拥有你们的春秋和冬夏
她们都老了吧 她们在哪里呀
我们就这样 各自奔天涯
啦啦啦啦啦啦啦 想她
啦啦啦啦啦啦啦 她还在开吗
啦啦啦啦啦啦啦 去呀
她们已经被风吹走 散落在天涯
啦啦啦啦啦啦啦 也罢
啦啦啦啦啦啦啦 (语气词)
啦啦啦啦啦啦啦 知道
人们就像被风吹走 插在了天涯
她们都老了吧 她们还在开吗
我们就这样 各自奔天涯(2)AI生成的对比表(部分)
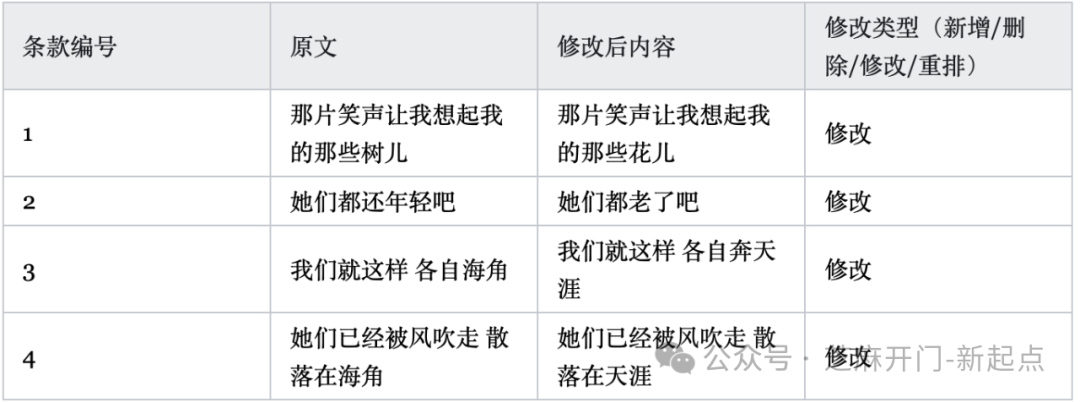
(3)结果分析
AI准确识别了“新增/删除/修改/重排"几类差异,表格格式清晰,无需人工二次整理。若文档更长(如1000字以上),只要不超过模型的上下文限制,对比精度依然稳定。
四、避坑指南:这些细节决定工作流是否好用
- 模型选择
避免用小上下文模型(如豆包·1.0),否则长文档内容会被截断,导致对比不完整;若文档超过20000字,建议拆分文档后分多次对比;
- 格式兼容性
复杂格式文档(如含公式的PDF、加密文档)需先转为可编辑的doc或txt格式,否则“文件读取”插件可能提取失败;
- 差异漏检处理
若AI漏检了细微差异(如标点符号修改),可在提示词中补充“需检查标点符号、空格、大小写的差异”,提升精度;
- 结果验证
AI对比后,建议人工核对关键段落(如合同条款、数据指标),避免因格式解析误差导致的误判。
五、拓展场景:不止于文档对比
这条工作流不仅能对比普通文档,还能灵活调整用于更多场景:
- 代码对比
将“文件读取”节点改为“代码读取”插件,提示词中添加“识别代码语法差异(如变量名修改、函数新增)”,可用于程序员核对代码版本;
- 报告更新核对
针对月度/季度报告,用工作流快速定位数据修改(如“销售额100万”改为“120万”),避免人工逐行找数据;
- 教案优化记录
老师可对比新旧教案的修改,生成“优化日志”,方便后续复盘教学思路调整。
通过以上步骤,一条实用的“新旧文档对比工作流”就搭建完成了。相比手动对比,它能节省80%的时间,且差异分类更清晰,尤其适合经常处理文档更新的职场人。如果觉得搭建麻烦,也可以基于这个思路,在Coze社区搜索类似工作流进行二次修改,快速适配自己的需求。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 10
10 0
0- 0



 已为社区贡献10条内容
已为社区贡献10条内容

所有评论(0)