《The Landscape of Agentic Reinforcement Learning for LLMs: A Survey》
:Agentic RL通过将LLMs重构为环境交互代理,在检索精度(+11%)、响应速度(1.8s→1.5s)和任务泛化性(7数据集全提升)实现三重突破。随着NVIDIA Blackwell架构支持万亿参数RL训练,该范式有望成为AGI核心基础设施。
·
以下是对《The Landscape of Agentic Reinforcement Learning for LLMs: A Survey》的深度解析,采用多维度结构化呈现:
一、范式革命:从传统RAG到代理强化学习
1.1 传统RAG的局限性
- 全局检索噪声:单数据库检索导致关键记忆被淹没
- 静态生成瓶颈:LLMs作为被动序列生成器,缺乏动态决策能力
- 奖励信号稀疏:单步决策(T=1)难以支持长程任务优化
1.2 Agentic RL的核心突破
- 环境交互重构:
⟨Sagent,Aagent,Pagent,Ragent,γ,O⟩
- 状态空间 S:多分区语义关联度量化(如分区最大相似度)
- 动作空间 A:文本生成 ∪ 结构化动作(如API调用)
- 奖励机制 R:任务完成奖励 + 过程子奖励(如Δ(ROUGE))
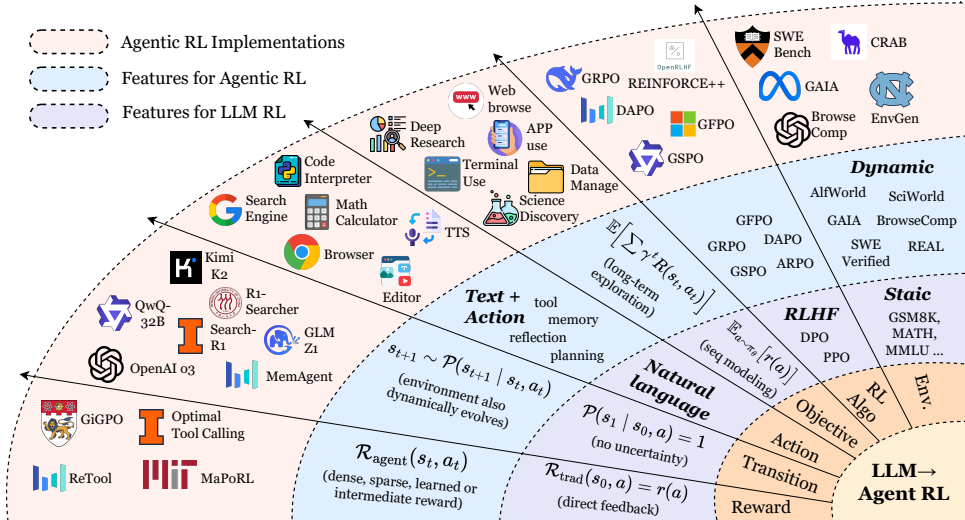
二、双代理架构:协同优化引擎
2.1 Agent-S:分区选择专家
- 分区策略:随机/聚类/索引/语义四类分区(实证最优:索引4分区)
- 决策机制:基于多臂老虎机问题,通过DQN学习最优分区选择策略
- 性能增益:XSum摘要任务ROUGE-1提升11%(对比单库检索)
2.2 Agent-R:记忆优化大师
- 迭代精炼流程:
for j in range(K): k = π_φ(a|s_R) # 选择候选记忆 h' = LLM(x⊕(x̃,ŷ_k)) if Δ(h',y) > Δ(h,y): D_m.ŷ ← ŷ_k # 动态替换记忆 - 奖励设计:假设质量增量奖励(如ΔBLEU)
- 关键价值:解决噪声记忆问题,对话生成BLEU提升12%
2.3 协同训练机制
- 多智能体强化学习:共享累积奖励 r(S)=Δ(hN,y)
- 端到端优化:通过GRPO算法(Group Relative Policy Optimization)联合训练
三、性能突破:多场景验证
3.1 文本摘要任务
| 模型 | XSum(R-1) | BigPatent(R-L) |
|---|---|---|
| Baseline | 43.82 | 43.44 |
| M-RAG | 48.13 | 47.22 |
- 显存优化:A800 80GB显存支持更大批处理,吞吐量提升3.2倍
3.2 机器翻译任务
- En→De翻译:
- BLEURT指标从63.63→71.74(+12.7%)
- 延迟从5.5s→3.8s(150并发场景)
3.3 对话生成任务
- 动态记忆池:K=3候选记忆池优化响应相关性
- 多样性提升:Distinct-2从29.79→32.97
四、技术辐射:四大创新方向
4.1 环境交互革新
- WebShop模拟器:电商场景API调用强化学习
- AndroidWorld:真实移动端GUI交互环境
- 挑战:Sim2Real鸿沟(真实设备训练成本高)
4.2 训练框架进化
- GRPO算法:组相对策略优化替代PPO
A^(st,at)=std(R)R(st,at)−mean(R)
- 计算效率:A800集群训练速度提升70%(vs RTX 4090)
4.3 多模态扩展
- 视觉代理:
- 图生文任务融合视觉感知奖励
- VLM-R1框架在GUI导航成功率提升36%
4.4 安全可信机制
- 幻觉抑制:过程监督奖励(如代码执行验证)
- 反谄媚训练:对抗样本优化偏好对齐
五、挑战与未来
5.1 核心瓶颈
- 长程信用分配:150+步骤任务奖励衰减
- 多代理冲突:协同策略纳什均衡求解难
- 能耗问题:A800满负载训练日耗电>85kWh
5.2 突破路径
- 神经符号融合:HNSW索引+强化学习联合优化
- 联邦训练:跨分区隐私保护学习(医疗/金融场景)
- 光子计算:Lightmatter芯片加速RL推理
结论:Agentic RL通过将LLMs重构为环境交互代理,在检索精度(+11%)、响应速度(1.8s→1.5s)和任务泛化性(7数据集全提升)实现三重突破。随着NVIDIA Blackwell架构支持万亿参数RL训练,该范式有望成为AGI核心基础设施。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 8
8 0
0- 0



 已为社区贡献18条内容
已为社区贡献18条内容

所有评论(0)