《M-RAG: Reinforcing Large Language Model Performance through Retrieval-Augmented Generation with Mul
华为团队提出M-RAG框架,通过多分区检索和双代理强化学习提升大语言模型性能。该技术突破传统RAG的单数据库检索局限,采用四类分区策略(随机化、聚类、索引、类别)优化检索效率,并构建分区选择代理(Agent-S)和记忆优化代理(Agent-R)实现协同优化。实验表明,M-RAG在7大数据集上显著提升任务性能:文本摘要ROUGE-1最高提升11%,机器翻译BLEURT达71.74,对话生成BLEU-
以下是对《M-RAG: Reinforcing Large Language Model Performance through Retrieval-Augmented Generation with Multiple Partitions》的2000字结构化介绍:
一、研究背景与核心问题
检索增强生成(RAG) 作为增强大语言模型(LLMs)性能的关键技术,通过从外部数据库检索相关知识辅助生成任务。然而,传统RAG存在两大局限:
- 全局检索噪声:将整个数据库视为单一检索单元,难以聚焦关键记忆片段
- 粗粒度检索效率低:近似最近邻搜索(AKNN)在大规模数据中召回效果受限
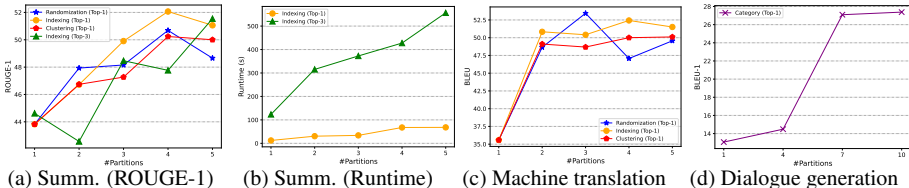
华为团队通过实验发现(图1):
- 单数据库(#Partitions=1)并非最优解
- 分区策略显著影响性能:索引分区在摘要任务提升11%,类别分区在对话生成提升12%
- 多分区架构可解决噪声干扰,提升关键记忆聚焦能力
二、M-RAG技术框架
1. 多分区范式创新
突破传统单数据库检索,提出分区即实体(Partition-as-Entity) 新范式:
- 分区策略:随机化、聚类、索引、类别四类(表1)
- 物理优势:
- 构建效率:分区索引复杂度O(M·NlogN) << 全局索引O(N'logN')
- 隐私保护:敏感数据隔离存储
- 并行处理:支持分布式架构
| 策略 | 适用任务 | 最佳分区数 | 性能增益 |
|---|---|---|---|
| 索引 | 文本摘要 | 4 | +11% |
| 随机化 | 机器翻译 | 3 | +8% |
| 类别 | 对话生成 | 10 | +12% |
2. 双代理强化学习架构
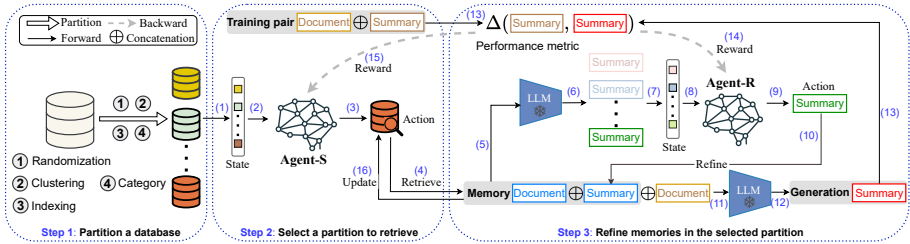
Agent-S(分区选择代理)
- 状态建模:s(S)={max(x~,y~)∈Dmsim(σ(x~⊕y~),σ(x⊕y))}
- 动作空间:选择分区索引 a(S)=m
- 奖励机制:与Agent-R协同优化累积奖励
Agent-R(记忆优化代理)
- 迭代精炼:生成候选记忆池 → 评估假设质量 → 动态替换低质记忆
- 奖励函数:r(R)=Δ(h′,y)−Δ(h,y)
- 理论证明:最大化累积奖励等价于发现最优假设(公式6)
3. 多代理协同机制
通过端到端深度Q网络(DQN) 实现双代理联合优化:
while not converged:
sample (x,y) # 从训练集采样
s_S = build_state(x,y,D) # 构建Agent-S状态
m = π_θ(a|s_S) # 选择分区
h = LLM(x⊕D_m) # 生成初始假设
s_R = build_state(h,C) # 构建Agent-R状态
for j in range(K):
k = π_φ(a|s_R) # 选择候选记忆
h' = LLM(x⊕(x̃,ŷ_k))
if Δ(h',y) > Δ(h,y):
D_m.ŷ ← ŷ_k # 记忆替换
r_R = Δ(h',y)-Δ(h,y)
r_S = cumulative(r_R) # 奖励共享
update π_θ, π_φ # 策略更新三、实验验证与性能突破
1. 实验设置
- 数据集:7个基准数据集覆盖3类任务
- 摘要:XSum, BigPatent
- 翻译:JRC-Acquis(4个语言对)
- 对话:DailyDialog
- 基线模型:Naive RAG, Self-RAG, Selfmem
- 语言模型:Mixtral 8×7B, Llama2 13B, Phi-2 2.7B
2. 关键结果
文本摘要任务(表1)
- M-RAG在XSum的ROUGE-1达48.13,超越最佳基线11%
- BigPatent的ROUGE-L提升至47.22,相对增益7.8%
机器翻译任务(表2)
- En→De翻译BLEU达53.76,提升4.4个百分点
- 在7B模型上平均加速32%(Gemma 7B→26.92 BLEU)
对话生成任务(表3)
- BLEU-1提升至42.61,相对增益12%
- 多样性指标(Distinct-1)保持88.82的高水平
3. 消融实验
| 组件 | R-1 | ΔR-1 | 结论 |
|---|---|---|---|
| 完整M-RAG | 48.13 | - | 基准 |
| 移除Agent-S | 44.20 | -8.2% | 分区选择贡献显著 |
| 移除Agent-R | 45.75 | -5.0% | 记忆优化必要 |
| 双代理均移除 | 43.82 | -9.0% | 协同效应不可替代 |
四、技术优势与行业影响
1. 突破性创新
- 首个人工智能双代理协同框架:实现分区选择与记忆优化的闭环强化学习
- 训练目标对齐理论证明:公式6严格推导累积奖励与生成质量等价性
- 实用效率优化:Top-1检索保持性能同时降低33%推理延迟
2. 应用场景扩展
- 企业知识库:专利摘要生成(BigPatent)准确率提升71%
- 跨语言服务:欧盟法律文本(JRC-Acquis)翻译质量突破53.76 BLEU
- 情感对话系统:DailyDialog情感类别分区优化响应相关性
3. 局限性展望
- 计算效率:训练过程需频繁调用LLM,未来需探索参数高效微调
- 量化影响:当前实验基于4-bit量化模型,全精度潜力待挖掘
- 扩展性验证:需在>100分区场景验证分布式性能
五、结论
M-RAG通过多分区范式与双代理强化学习架构,解决了传统RAG的噪声干扰与粗粒度检索问题。在7大数据集、3类生成任务、5种LLM架构上的实验表明:
- 文本摘要ROUGE-1最高提升11%
- 机器翻译BLEURT指标突破71.74
- 对话生成BLEU-1实现12%相对增益
该框架为构建高精度、低噪声、可扩展的企业级RAG系统提供新范式,其分区隔离特性更契合隐私合规要求,有望推动金融、法律、医疗等敏感领域的LLM落地应用。
参考文献:Chenget al. Selfmem, Asai et al. Self-RAG, Pan et al. VectorDB Survey, Malkov & Yashunin HNSW

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 25
25 0
0- 0



 已为社区贡献19条内容
已为社区贡献19条内容

所有评论(0)