小白都能看懂的Transformer!!
Transformer是2017年提出的革命性神经网络架构,基于自注意力机制彻底改变了自然语言处理领域。其核心创新在于完全摒弃RNN结构,通过并行计算和直接捕捉任意位置依赖关系,解决了RNN存在的两大痛点。Transformer由编码器和解码器组成,核心组件包括输入嵌入、位置编码、自注意力机制、多头注意力、前馈网络等。其中自注意力机制能动态计算序列中所有词之间的关系,而多头注意力则从不同子空间学习
提到现代自然语言处理(NLP),就绕不开 Transformer:它是一种基于自注意力机制的深度神经网络,由 Vaswani 团队在 2017 年通过论文《Attention Is All You Need》首次提出。最初为机器翻译等 Seq2Seq 任务设计的它,不仅颠覆了 NLP 领域的技术格局,更成为 GPT、BERT 等所有主流大型语言模型的 “技术基石”。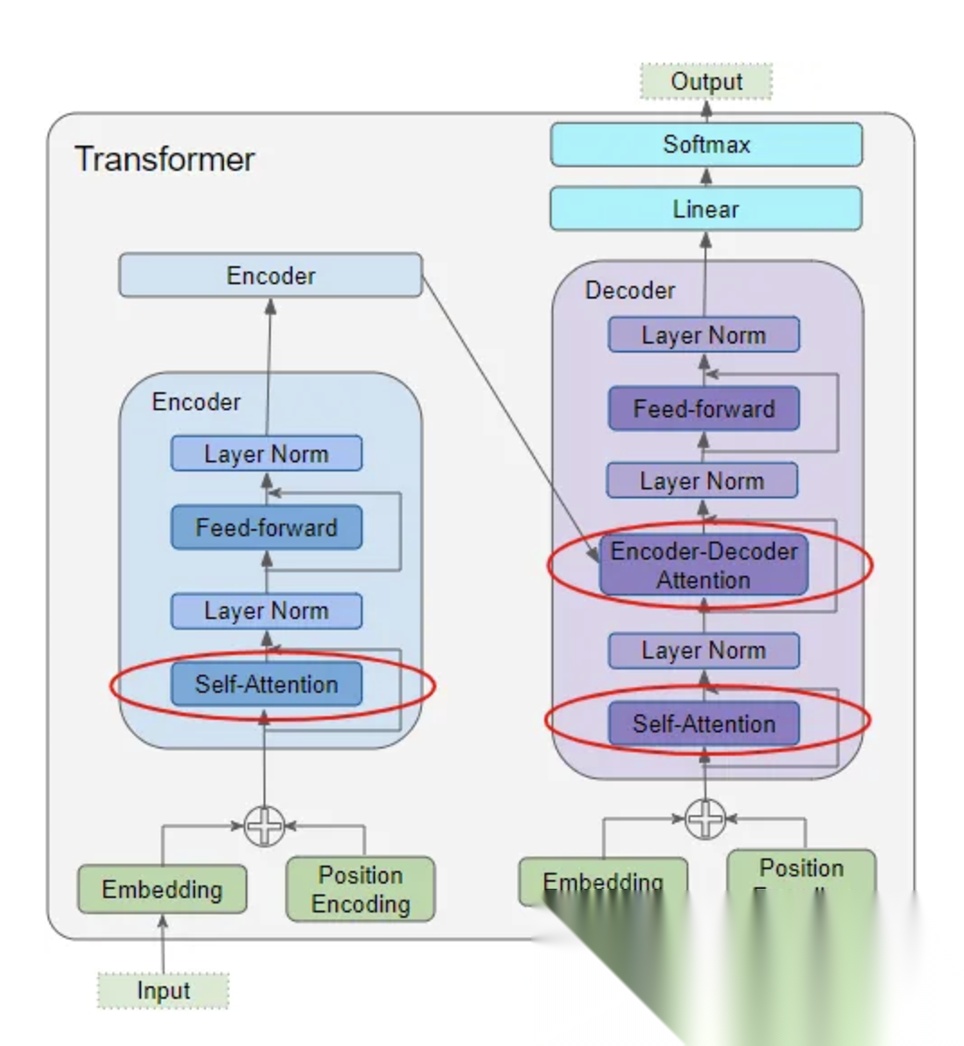
Transformer 简介
在 Transformer 出现之前,处理序列数据(如自然语言)的主流模型是循环神经网络(RNN)及其变体(如 LSTM、GRU)。这些模型通过顺序处理数据来捕捉上下文信息。
然而,顺序处理会导致两个主要问题
- 无法并行计算:每个时间步的计算都依赖于前一个时间步的隐藏状态,这使得模型训练速度慢。
- 长距离依赖问题:当序列很长时,早期的信息在多次传递后会逐渐丢失,模型难以捕捉到长距离的词语关系。
Transformer 最核心的创新在于它完全摒弃了传统的循环神经网络(RNN) 的循环结构,它完全基于自注意力机制来处理序列。这种设计使得模型可以并行计算整个序列(提高了效率),并且能够直接捕捉序列中任意两个位置的依赖关系(更好地捕捉序列中的长距离依赖关系),从而完美解决了 RNN 的上述两大痛点,成为了自然语言处理(NLP)领域的里程碑式算法。
Transformer 架构
一个典型的 Transformer 模型通常由编码器(Encoder)和解码器(Decoder)两部分组成,它们各自由多个相同的层堆叠而成。
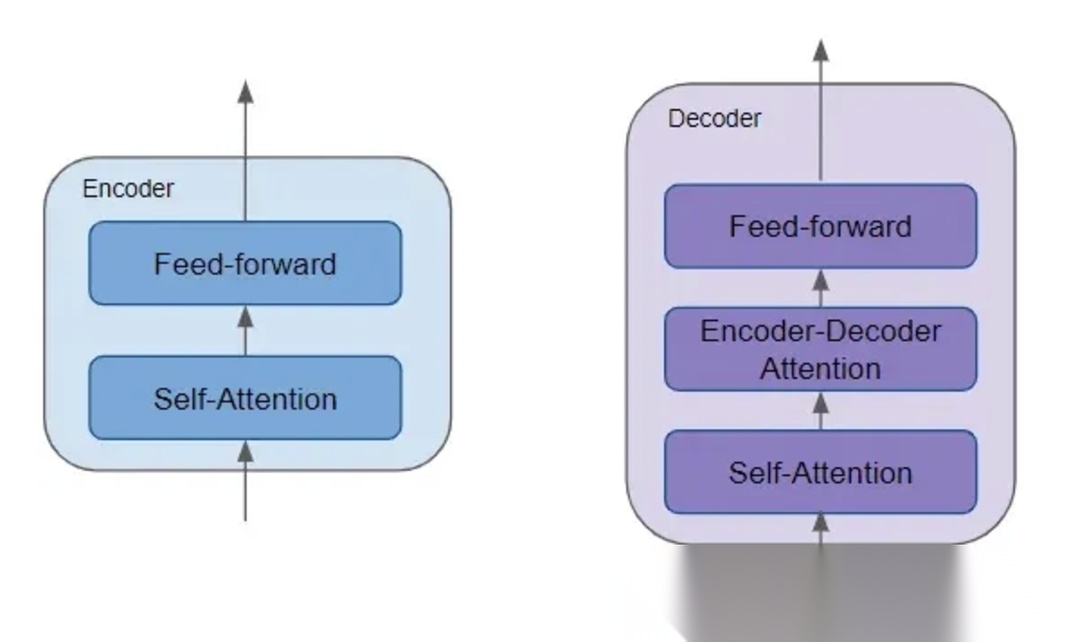
编码器(Encoder)
编码器负责将输入序列(如一个英文句子)中的每个词,转换成一个包含丰富上下文信息的向量表示。每个编码器层都包含两个子层:
- 多头自注意力机制:捕捉输入序列内部词与词之间的依赖关系。
- 前馈神经网络:对自注意力机制的输出进行非线性变换。
每个子层之后都跟着一个残差连接和层归一化,以帮助梯度更好地反向传播。
解码器(Decoder)
解码器负责将编码器生成的上下文向量和已生成的输出序列(如部分中文翻译)作为输入,逐步生成完整的输出序列。
每个解码器层包含三个子层
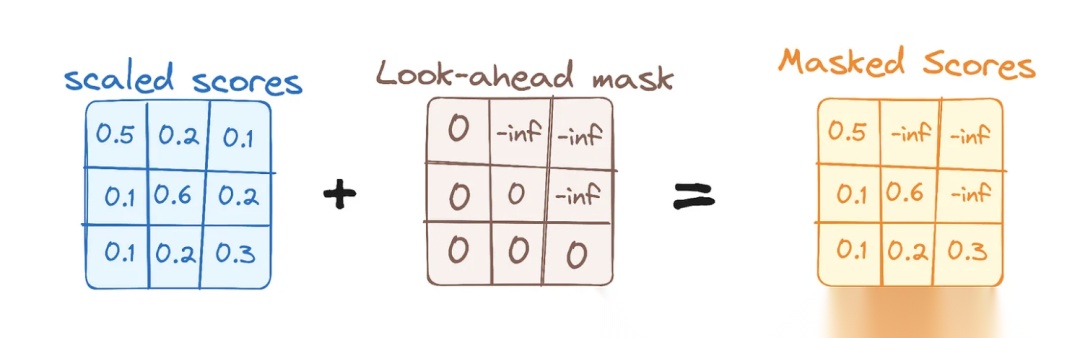
- 带掩码的多头自注意力(Masked Multi-Head Attention):在训练时,解码器需要生成下一个词。为了防止模型“偷看”到未来的词,在计算自注意力时,对未来的位置进行掩码(masking),将其注意力分数设置为一个极小的负数,使其在 Softmax 后变为 0。
- 编码器-解码器注意力(Encoder-Decoder Attention):这一层使得解码器在生成每个词时,能够关注到整个输入序列(编码器的输出),从而更好地理解上下文。
- 前馈神经网络:与编码器中的前馈网络类似。
同样,每个子层之后也跟着残差连接和层归一化。
核心组件
1.输入嵌入
由于计算机无法直接理解文字,我们需要将每个词语或标记(token)转换成一个固定维度的向量,这个过程就是嵌入(Embedding)。
输入嵌入是将将离散的词语转换成连续的、稠密的向量表示。这些向量捕捉了词语的语义信息,例如,“国王”和“女王”的嵌入向量会比“国王”和“苹果”的向量更接近。
计算公式为
其中
- 是输入序列
- 是输入序列的嵌入表示
2.位置编码
由于 Transformer 模型不包含任何循环或卷积结构,模型本身无法感知词语在句子中的位置信息。
为了解决这个问题,Transformer 在输入词向量中加入了位置编码,通过在词向量中注入关于词在序列中位置的特定信息,使得模型能够理解词的顺序。
位置编码通常使用正弦和余弦函数来计算,其数学公式如下
其中
- 是序列中某个元素的位置
- i 是位置编码向量中的维度索引
- d 是嵌入向量的维度
然后将位置编码和输入嵌入相加形成最终的输入表示。
3.自注意力机制
自注意力机制是 Transformer 最核心的组件。它的基本思想是,在对序列中的某个词进行编码时,不仅要考虑它自身的词向量,还要考虑序列中所有其他词对它的影响。
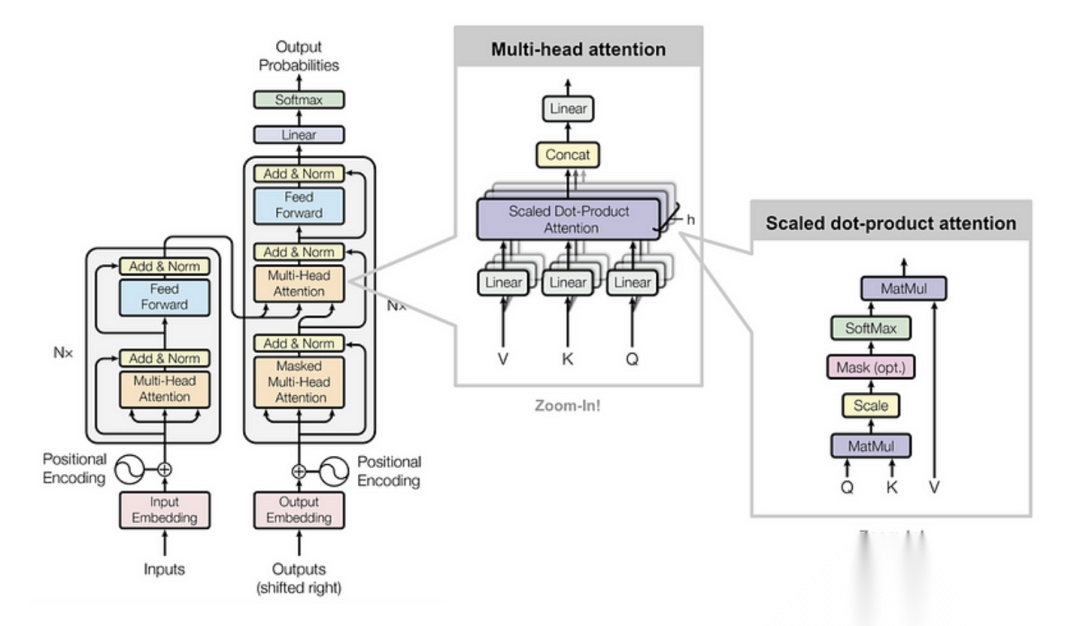
其计算过程如下
计算步骤为
-
生成查询、键和值矩阵
首先,输入 X 经过三个不同的线性变换得到 Q、K 和 V 矩阵
-
计算注意力得分
将 矩阵与 矩阵的转置相乘,得到一个注意力分数矩阵。这个分数衡量了每个词与其他所有词之间的关联度。
-
缩放
为了避免点积结果过大导致梯度消失问题,我们将注意力得分除以
-
归一化
对缩放后的注意力得分应用 Softmax 函数,得到注意力权重,它们表示每个值向量对最终输出的贡献程度。
-
加权求和
将注意力权重与对应的值向量 相乘,然后求和,得到最终的注意力输出。
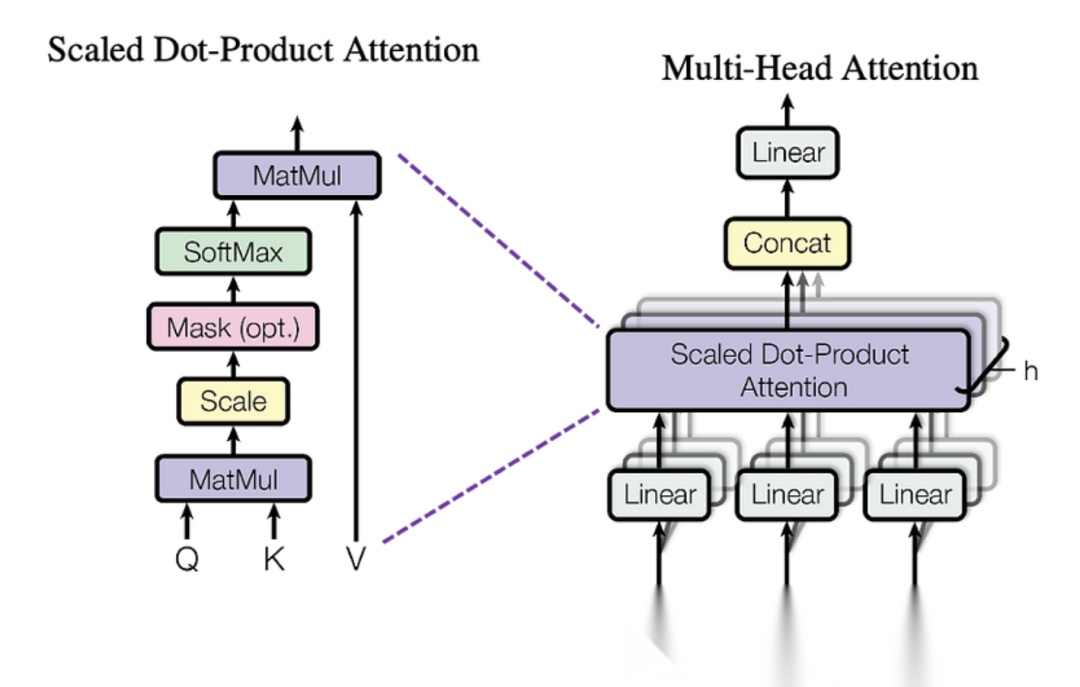
4.多头注意力机制
为了让模型能够从不同的表示子空间中学习信息,Transformer 引入了多头注意力机制。
具体实现为
-
设多头数为 h,每个头有自己的线性变换矩阵
-
对输入执行 h 次独立的自注意力机制
-
将所有头的输出拼接
-
线性变换
对拼接后的结果进行最终的线性变换,得到最终的输出
其中, 是线性变换矩阵
5.前馈网络
在自注意力层之后,每个位置的输出都会经过一个前馈网络。
前馈网络对每个位置的向量独立进行处理,其目的是增加模型的非线性,并进一步对注意力层的输出进行复杂的特征转换。
前馈网络通常由两层全连接网络和一个 ReLU 激活函数组成。
公式如下
- x 是输入向量
- 是权重矩阵。
- 是偏置向量。
6.残差连接与层归一化
为了解决深度网络训练中的梯度消失问题,并加快训练速度,Transformer 引入了残差连接和层归一化。
残差连接
在每个子层(自注意力层和前馈网络)的输出与输入之间添加一个“快捷连接”(shortcut connection)。这使得信息可以在网络中更顺畅地流动。
其公式为
- x 是输入向量
- 是自注意力或前馈网络的输出
层归一化
在残差连接之后,对每个样本的特征维度进行归一化。
公式为
- 是输入的均值和方差。
- 是可学习的缩放和偏移参数。
7.掩蔽多头自注意力机制
在编码器中,自注意力机制可以毫无限制地关注序列中的所有词语,因为编码器需要理解整个输入序列的上下文。
然而,在解码器中,我们的任务是生成一个序列。在生成第 t 个词语时,模型应该只能看到前面已经生成的 1,…,t−1 个词语,而不能偷看到第 t+1 个或更后面的词语。这就好比你在写一句话时,不能事先知道你接下来要写什么词语。
掩蔽多头自注意力机制就是为了实现这个目的而设计的。它的核心思想是在自注意力计算过程中,阻止模型关注未来的词语。
具体来说,在计算注意力分数时引入了掩蔽矩阵 ,对所有未来位置设置极小值(通常是负无穷,在经过 后会变为0,因此未来位置的注意力权重也变成了0,这确保了在加权求和时,模型不会考虑未来词语的 V 向量)。
数学公式为
其中,M 为遮掩矩阵
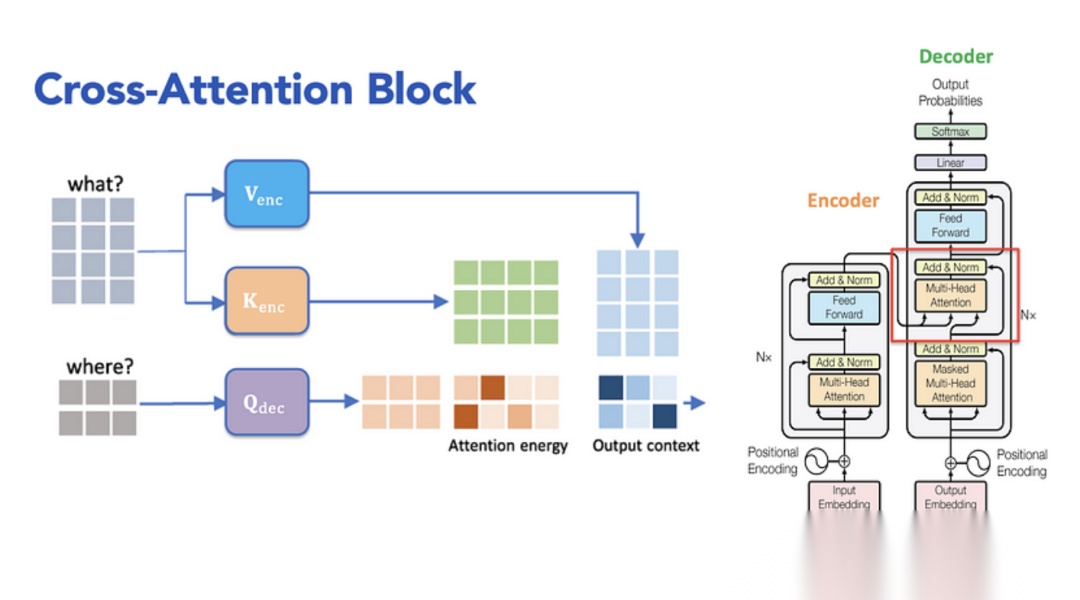
8.编码器-解码器多头注意力
编码器-解码器多头注意力是解码器中另一个关键组件,用于将解码器中的查询向量 (Query) 与编码器输出的键 (Key) 和值 (Value) 向量交互,从而动态提取输入序列的相关信息。
通过这种方式,解码器可以根据编码器提供的上下文信息,有选择性地关注源序列中最重要的部分,从而生成更准确的目标序列。这使得翻译模型能够更好地理解源语言的含义。
读者福利大放送:如果你对大模型感兴趣,想更加深入的学习大模型**,那么这份精心整理的大模型学习资料,绝对能帮你少走弯路、快速入门**
如果你是零基础小白,别担心——大模型入门真的没那么难,你完全可以学得会!
👉 不用你懂任何算法和数学知识,公式推导、复杂原理这些都不用操心;
👉 也不挑电脑配置,普通家用电脑完全能 hold 住,不用额外花钱升级设备;
👉 更不用你提前学 Python 之类的编程语言,零基础照样能上手。
你要做的特别简单:跟着我的讲解走,照着教程里的步骤一步步操作就行。
包括:大模型学习线路汇总、学习阶段,大模型实战案例,大模型学习视频,人工智能、机器学习、大模型书籍PDF。带你从零基础系统性的学好大模型!
现在这份资料免费分享给大家,有需要的小伙伴,直接VX扫描下方二维码就能领取啦😝↓↓↓
为什么要学习大模型?
数据显示,2023 年我国大模型相关人才缺口已突破百万,这一数字直接暴露了人才培养体系的严重滞后与供给不足。而随着人工智能技术的飞速迭代,产业对专业人才的需求将呈爆发式增长,据预测,到 2025 年这一缺口将急剧扩大至 400 万!!
大模型学习路线汇总
整体的学习路线分成L1到L4四个阶段,一步步带你从入门到进阶,从理论到实战,跟着学习路线一步步打卡,小白也能轻松学会!
大模型实战项目&配套源码
光学理论可不够,这套学习资料还包含了丰富的实战案例,让你在实战中检验成果巩固所学知识
大模型学习必看书籍PDF
我精选了一系列大模型技术的书籍和学习文档(电子版),它们由领域内的顶尖专家撰写,内容全面、深入、详尽,为你学习大模型提供坚实的理论基础。
大模型超全面试题汇总
在面试过程中可能遇到的问题,我都给大家汇总好了,能让你们在面试中游刃有余
这些资料真的有用吗?
这份资料由我和鲁为民博士(北京清华大学学士和美国加州理工学院博士)共同整理,现任上海殷泊信息科技CEO,其创立的MoPaaS云平台获Forrester全球’强劲表现者’认证,服务航天科工、国家电网等1000+企业,以第一作者在IEEE Transactions发表论文50+篇,获NASA JPL火星探测系统强化学习专利等35项中美专利。本套AI大模型课程由清华大学-加州理工双料博士、吴文俊人工智能奖得主鲁为民教授领衔研发。
资料内容涵盖了从入门到进阶的各类视频教程和实战项目,无论你是小白还是有些技术基础的技术人员,这份资料都绝对能帮助你提升薪资待遇,转行大模型岗位。
👉获取方式:
😝有需要的小伙伴,可以保存图片到VX扫描下方二维码免费领取【保证100%免费】
相信我,这套大模型系统教程将会是全网最齐全 最适合零基础的!!

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 39
39 0
0- 0



 已为社区贡献135条内容
已为社区贡献135条内容

所有评论(0)