大模型 DPO 微调 -- “漫画真人化”评价实践
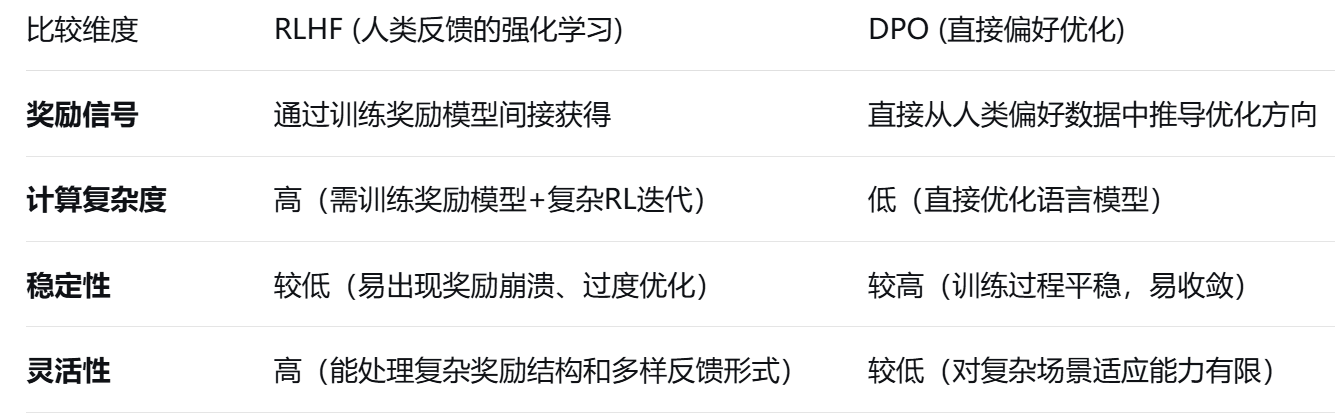
本文介绍了两种优化大语言模型(LLM)输出的方法:RLHF(人类反馈强化学习)和DPO(直接偏好优化)。RLHF通过人类评估和强化学习调整模型输出,而DPO则直接利用偏好数据优化模型。文章以"漫画真人化";话题为例,展示了DPO微调实践:通过构建支持/反对回答数据集(10%支持率),对Breeze-7B模型进行微调,使输出明显偏向反对立场。结果显示,微调后模型负面表述增多,立场更加鲜明,验证了DP
DPO 微调示例:根据人类偏好优化 LLM 大语言模型 | Github
09. DPO 微调:根据偏好引导 LLM 的输出 | Kaggle
RLHF 和 DPO:推动语言模型与人类期望对齐
基于预训练模型的微调,让大模型的输出符合人类的期望和价值观。
1. RLHF(人类反馈强化学习)
RLHF 是一种基于强化学习(RL),融入人类反馈机制的方法。在传统强化学习中,智能体通过与环境交互,依据环境给出的奖励或惩罚信号来调整自身行为策略,以最大化长期累积奖励。而 RLHF 则将人类引入这一循环,把人类对模型输出的评价作为重要反馈。目的使得对话表现更加自然、流畅,且符合人类的交流习惯和价值观,提升用户与模型交互的体验。
具体而言,首先由人类评估者对模型针对特定输入生成的多个输出进行评分或者排序,从而生成偏好数据。(例如,在训练一个对话模型时,对于问题 “周末可以做什么有趣的活动?”,模型可能给出 “可以去公园散步,享受自然”“周末在家打游戏也不错” 等不同回答,评估者需要从中选择更优的答案并标注。)
基于这些数据,训练一个奖励模型。奖励模型的任务是学习预测人类偏好,即判断模型的哪个输出更受青睐。
最后,利用强化学习算法,例如近端策略优化(PPO)算法,以奖励模型给出的预测奖励为导向,对语言模型进行微调,促使其在生成输出时能够最大化奖励,也就是更符合人类期望。
2. DPO(直接偏好优化)
DPO 是一种新兴的训练方法,它旨在直接优化语言模型以匹配人类偏好。与 RLHF 不同,DPO 跳过了奖励模型的训练环节。其核心思想是将人类偏好数据直接转化为一个优化目标,通过最大化模型生成人类偏好输出的概率,同时最小化生成不受欢迎输出的概率,来调整模型参数。
具体来说,DPO 利用人类对模型输出的偏好数据构建一个特殊的损失函数,然后直接在语言模型上进行梯度更新,使模型朝着生成人类偏好输出的方向优化。
3. 微调之间的区别
相比微调唐诗,使用问题和答案驱动(一个问题 -> 一个标准答案)的微调方式。
难度:1. 数据标注成本很高 2. 有些问题没有严格的标准答案。
而 DPO 使用人类对文本的偏好对:即人类认为 一组文本回复中哪个更好。
目标:学习到答案的相对偏好,让模型输出的答案更符合偏好的方向。模型不需要完全生成一个“标准答案”,而是需要倾向于生成更符合偏好或更优的回答。
0. 实践目标
成对“支持/反对” 回答的数据集,通过DPO微调
使得大模型对“漫画真人化”相关话题的回答 更偏向于“反对”
1. 数据集的部分展示
https://github.com/Baiiiiiiiiii/GenAI_hw6_dataset.git
with open("./GenAI_hw6_dataset/labelled_data.json", 'r') as jsonfile:
full_data = json.load(jsonfile)
with open("./GenAI_hw6_dataset/test_prompt.json", 'r') as jsonfile:
test_data = json.load(jsonfile)训练集每个问题都给出了两个回答:
更偏向支持的回答 support 更偏向反对的回答 oppose 便于后续DPO时设置回答偏向。
([{'id': 1,
'prompt': '日本動漫真人化是否有損原作形象?',
'support': '真人化能夠呈現更真實的角色形象,提升原作魅力。',
'oppose': '真人化可能無法完美呈現動畫中的獨特風格,損害原作形象。'},
{'id': 2,
'prompt': '真人化是否能夠擴大動漫在全球的影響力?',
'support': '真人化能夠讓更多非動漫迷接觸作品,擴大影響力。',
'oppose': '真人化可能失去動漫的獨特風格,限制影響力擴大。'},
{'id': 3,
'prompt': '真人化是否能夠吸引新觀眾?',
'support': '真人化能夠吸引不熟悉動漫的觀眾,擴大受眾。',
'oppose': '真人化可能讓原本的動漫迷感到失望,無法吸引新觀眾。'},
{'id': 4,
'prompt': '真人化是否能夠保留原作故事情節的精髓?',
'support': '真人化有機會更深入挖掘原作故事,保留精髓。',
'oppose': '真人化可能因為改編而失去原作故事的深度與精髓。'},
{'id': 5,
'prompt': '真人化是否能夠提升動漫產業的商業價值?',
'support': '真人化能夠開拓更多商業機會,提升產業價值。',
'oppose': '真人化可能讓觀眾對原作失去興趣,影響產業價值。'}],
[{'id': 1, 'prompt': '真人化是否能改善日本漫畫的全球可及性?'},
{'id': 2, 'prompt': '真人化如何影響年輕一代對日本漫畫的看法?'},
{'id': 3, 'prompt': '真人化是否能提升原作漫畫的文學價值?'},
{'id': 4, 'prompt': '真人化是否有助於保護和保存日本漫畫的傳統?'},
{'id': 5, 'prompt': '真人化是否有助於提升日本漫畫行業的經濟效益?'},
{'id': 6, 'prompt': '真人化如何影響日本漫畫原作者的創作動力?'},
{'id': 7, 'prompt': '真人化是否對漫畫原作的忠實粉絲公平?'},
{'id': 8, 'prompt': '真人化是否能夠促進日本漫畫的創新和多樣性?'},
{'id': 9, 'prompt': '真人化是否有助於擴大動漫文化的市場份額?'},
{'id': 10, 'prompt': '真人化是否有助於提高日本漫畫在全球的競爭力?'}])2. 微调前的大模型输出
构建模型和量化配置
model = AutoModelForCausalLM.from_pretrained(
'MediaTek-Research/Breeze-7B-Instruct-v0_1',
device_map='auto',
trust_remote_code=True,
quantization_config=BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_compute_dtype=torch.bfloat16,
bnb_4bit_use_double_quant=True,
bnb_4bit_quant_type='nf4'
)
)加载分词器
tokenizer = AutoTokenizer.from_pretrained('MediaTek-Research/Breeze-7B-Instruct-v0_1')
tokenizer.padding_side = "right" # 在序列右侧进行填充
tokenizer.pad_token = tokenizer.eos_token # 使用结束符作为填充符将文字问题转换为prompt
def data_formulate(data):
# 1. 构建对话消息序列
messages = [
{"role": "system", "content": '回覆請少於20字'}, # 系统指令:限制回复长度
{"role": "user", "content": data['prompt']}, # 用户输入:从数据中提取提示词
]
# 2. 应用聊天模板格式化
prompt = tokenizer.apply_chat_template(
messages,
tokenize=False, # 不进行分词(返回字符串而非token ID)
add_generation_prompt=True # 添加生成提示符,指示模型开始生成回复
)
return prompt遍历问题 输出结果;存储原结果便于后续比较
# 初始化存储列表
original_model_response = []
for data in tqdm(test_data):
# 1. 获取数据ID并打印问题
id = data['id']
print(f"Question {id}:\n{data['prompt']}")
# 2. 数据预处理和分词
inputs = tokenizer(data_formulate(data), return_tensors="pt").to('cuda')
# data_formulate(data): 调用函数 转化为prompt
# return_tensors="pt": 返回PyTorch张量
# .to('cuda'): 将数据移动到GPU
# 3. 配置生成参数
generation_config = GenerationConfig(
do_sample=False, # 禁用随机采样(使用贪婪解码)
max_new_tokens=200, # 限制生成最大token数
pad_token_id=tokenizer.pad_token_id # 设置填充token ID
)
# 4. 模型生成响应
output = model.generate(**inputs, generation_config=generation_config)
# **inputs: 解包input_ids, attention_mask等参数
# 5. 后处理解码输出
output_text = tokenizer.batch_decode(output, skip_special_tokens=True)[0].split('[/INST] ')[1]
# tokenizer.batch_decode: 将token ID转换回文本
# skip_special_tokens=True: 跳过特殊token(如<pad>, <eos>)
# .split('[/INST] ')[1]: 提取模型生成部分(移除提示词)
# 6. 存储结果并打印
original_model_response.append(output_text)
print(f"Response from original model:\n{output_text}\n")可以看出回答都是优缺点都包含,对这个话题部分支持部分反对。
Question 1:
真人化是否能改善日本漫畫的全球可及性?
Response from original model:
真人化可能會提高日本漫畫的全球可及性,因真人版電影或劇集可以吸引更多非漫畫讀者的注意,並提供不同的體驗。然而,這取決於真人化作品的品質、行銷策略和市場接受度。
Question 2:
真人化如何影響年輕一代對日本漫畫的看法?
Response from original model:
真人化可能會影響年輕一代對日本漫畫的看法,使他們更容易接受和理解故事和角色,並吸引更多人關注和支持日本漫畫文化。然而,個人喜好和文化差異可能導致不同的影響。
Question 3:
真人化是否能提升原作漫畫的文學價值?
Response from original model:
真人化可能會提升原作漫畫的知名度和影響力,但文學價值本身可能因個人喜好和文化差異而異。真人化可能帶來更多觀眾,但文學價值取決於原作的故事、人物和主題,而非真人化形式。3. 训练数据集
训练epoch + 训练数据量 + 对于 support的偏向比例(这里设置为0.1 代表比较偏向反对)
比如选50个训练数据 0.1支持率,就挑选出 5个支持数据 + 45个反对数据
num_epoch = 1 # 训练轮数
# 用于训练的数据量
data_size = 50
training_data = full_data[:data_size]
# 偏好支持真人化训练数据量
support_ratio = 0.1 # 偏好支持真人化的比例
support_data_size = int(data_size * support_ratio)训练集四列 分别为 prompt问题;立场是否支持;倾向的回复;不倾向的回复
# 1. 准备提示词列表
prompt_list = [data_formulate(data) for data in training_data]
# 将每个训练数据格式化为模型输入提示词
# 2. 准备偏好响应列表(chosen)
chosen_list = [data['support'] for data in training_data[:support_data_size]] + \
[data['oppose'] for data in training_data[support_data_size:]]
# 前support_data_size条数据取'support'作为偏好响应
# 剩余数据取'oppose'作为偏好响应
# 3. 准备非偏好响应列表(rejected)
rejected_list = [data['oppose'] for data in training_data[:support_data_size]] + \
[data['support'] for data in training_data[support_data_size:]]
# 与前面对应:前support_data_size条取'oppose'作为非偏好响应
# 剩余数据取'support'作为非偏好响应
# 4. 记录立场标签
position_list = ['support' for _ in range(support_data_size)] + \
['oppose' for _ in range(data_size - support_data_size)]
# 标记每条数据的原始立场
# 5. 创建训练数据集
train_dataset = Dataset.from_dict({
'prompt': prompt_list,
'position': position_list,
'chosen': chosen_list,
'rejected': rejected_list
})4. DPO训练
训练器参数: 基础模型 + 训练数据集 + 分词器(前三之前给出) + DPO训练参数配置 + PEFT微调配置
1. 训练参数配置 (DPOConfig)
training_args = DPOConfig(
output_dir='./', # 输出目录
per_device_train_batch_size=1, # 每个设备的训练批量大小(很小,通常因内存限制)
num_train_epochs=num_epoch, # 训练轮数
gradient_accumulation_steps=8, # 梯度累积步数(模拟更大批量)
gradient_checkpointing=False, # 是否使用梯度检查点(节省内存但变慢)
learning_rate=2e-4, # 学习率(相对较高的学习率)
optim="paged_adamw_8bit", # 使用分页的8位AdamW优化器(节省内存)
logging_steps=1, # 每步都记录日志
warmup_ratio=0.1, # 学习率预热比例(前10%训练步预热)
beta=0.1, # DPO损失函数的β参数(控制KL散度约束强度)
report_to='none', # 不向任何平台报告结果
# 显式声明以避免警告
max_length=512, # 序列最大长度
max_prompt_length=128, # 提示词最大长度
remove_unused_columns=False, # 保留所有列(DPO需要特定列)
)2. PEFT--Lora配置 (LoraConfig)
peft_config = LoraConfig(
lora_alpha=16, # LoRA的alpha参数(缩放因子)
lora_dropout=0.1, # LoRA层的dropout率
r=64, # 秩(rank),低秩分解的维度
bias="none", # 不训练偏置参数
task_type="CAUSAL_LM", # 任务类型:因果语言模型
)3. DPO训练器 (DPOTrainer)训练
dpo_trainer = DPOTrainer(
model, # 要训练的基础模型
args=training_args, # 训练参数配置
train_dataset=train_dataset, # 训练数据集(包含prompt、chosen、rejected)
processing_class=tokenizer, # 分词器
peft_config=peft_config, # PEFT配置
)
dpo_trainer.train()5. 微调后的模型输出与比较
下列循环输出结果的 1-4步骤 和之前第二部分微调前模型输出对应的代码完全相同
for data in tqdm(test_data, desc="Generating responses"):
# 获取当前数据的ID
id = data['id']
# 1. 数据预处理:将对话数据格式化为模型输入
inputs = tokenizer(data_formulate(data), return_tensors="pt").to('cuda')
# 2. 使用自动混合精度进行推理(节省内存,加速计算)
with torch.amp.autocast(device_type='cuda', dtype=torch.bfloat16):
# 配置生成参数
generation_config = GenerationConfig(
do_sample=False, # 使用贪婪解码(确定性输出)
max_new_tokens=200, # 限制生成的最大token数量
pad_token_id=tokenizer.pad_token_id # 设置填充token ID
)
# 3. 模型生成响应
output = model.generate(**inputs, generation_config=generation_config)
# 4. 后处理解码:将token ID转换为文本
tuned_output = tokenizer.batch_decode(
output,
skip_special_tokens=True # 跳过特殊token(如<pad>, <eos>)
)[0].split('[/INST] ')[1] # 提取模型生成部分(移除提示词)
# 5. 获取原始模型的响应结果(用于对比)
ref_output = original_model_response[id - 1]
# 6. 打印对比结果
print(f"\nQuestion {id}:\n{data['prompt']}") # 打印问题
print(f"Response from original model:\n{ref_output}") # 打印原始模型响应
print(f"Response from trained model:\n{tuned_output}") # 打印微调后模型响应比较原始输出和 对于偏向不支持微调后的结果
问题7:真人化是否对漫画原作的忠实粉丝公平?
原始模型:真人化可能会影响忠实的漫画原作粉丝,因真人版可能有不同的故事改编、角色设定或表现方式,但个人喜好不同,仍有可能欣赏。
微调后:真人化可能对忠实漫画原作的粉丝不公平,因真人版可能删减或更改故事、人物设定,或因演员、导演等因素影响作品品质。
# 去掉仍有可能欣赏
问题8:真人化是否能够促进日本漫画的创新和多样性?
原始模型:真人化可能促进日本漫画的创新和多样性,因真人版电影或剧集可以吸引新观众群,并提供不同的故事表现方式。然而,过度的真人化或商业化可能限制创意和多元性。平衡点须考虑。
微调后:真人化可能会限制日本漫画的创新和多样性,因其可能导致创作者倾向于追求熟悉的故事和角色,而忽略创新和多元化。
# 去掉了可能促进微调后的模型明显偏向反对立场,主要表现:
-
负面表述增多:频繁使用"可能损害"、"限制"、"不公平"等负面词汇
-
谨慎语气强化:多用"可能...但可能..."的保留句式,强调潜在风险
-
立场转变明显:
-
原始模型:相对中立,平衡分析利弊
-
微调后:强调负面影响,即使承认好处也会立即补充风险
-

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐



 30
30 0
0- 0



 已为社区贡献9条内容
已为社区贡献9条内容

所有评论(0)