3 、从一个demo开始学习HuggingFace
本文介绍了使用HuggingFace Transformers进行中文文本分类的实战流程。首先加载ChnSentiCorp数据集并进行预处理,使用AutoTokenizer进行文本编码。然后构建基于预训练模型(hfl/rbt3)的分类器,配置训练参数(batch_size、学习率等)和评估指标(准确率、F1值)。最后通过Trainer类完成模型训练、评估和预测。整个过程展示了HuggingFace
代码来源B站up主:你可是处女座啊(如有侵权联系立删)
视频:【手把手带你实战HuggingFace Transformers-入门篇】基础知识与环境安装_哔哩哔哩_bilibili
本篇学习顺序和视频有所不同哦(建议先看视频学习一下Model及其之前的部分)。
任务:实现文本分类
数据集:来自huggingface的ChnSentiCorp_htl_all.csv
1、数据集导入、划分、预处理
我们直接使用HuggingFace提供的数据集,可直接使用代码导入(需要提前下载):
dataset = load_dataset("csv", data_files="./ChnSentiCorp_htl_all.csv", split="train")
dataset = dataset.filter(lambda x: x["review"] is not None)参数解释:
“csv”:从csv文件中导入数据
data_files="./ChnSentiCorp_htl_all.csv":从指定路径导入数据集。
split = "train":
指定加载的数据集拆分(split)。对于单文件 CSV,默认只有一个拆分,通常命名为 "train"(即使文件中没有显式定义拆分)。
若 CSV 文件包含多个拆分(如通过文件名区分 train.csv 和 test.csv),可通过 split 选择特定拆分,或不指定 split 以 DatasetDict 形式返回所有拆分。
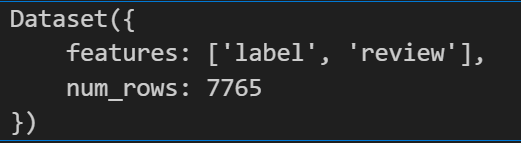
上面是dataset的类型。
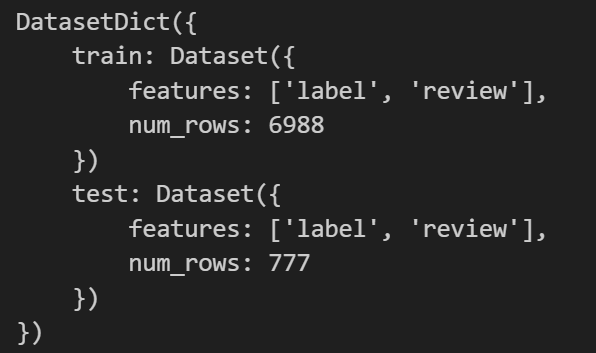
datasets = dataset.train_test_split(test_size=0.1)测试比例为10%。
由于目前的数据集是中文的形式,我们需要将其转变为计算机能识别的编码。
tokenizer = AutoTokenizer.from_pretrained("hfl/rbt3")
def process_function(examples):
tokenized_examples = tokenizer(examples["review"], max_length=128, truncation=True)
tokenized_examples["labels"] = examples["label"]
return tokenized_examples
tokenized_datasets = datasets.map(process_function, batched=True, remove_columns=datasets["train"].column_names)Tokenizer分词算法是NLP大模型最基础的组件,基于Tokenizer可以将文本转换成独立的token列表,进而转换成输入的向量成为计算机可以理解的输入形式。
这里直接使用from_pretrained函数调用预训练好的分词器。
函数process_function(examples)会对传入的examples的内容进行处理:
tokenized_examples = tokenizer(examples["review"], max_length=128, truncation=True)处理examples中的review的内容,并且设置最大长度为128。
因此,examples["review"]会得到
input_ids:文本分词后的数字编码,长度 ≤ 128。
attention_mask:与 input_ids 一一对应,标记有效 Token 的掩码,长度 ≤ 128。
token_type_ids(若模型需要):同样长度 ≤ 128(RBT3 等基于 BERT 的模型会生成该字段)。
然后将原始的examples["label"]部分加上去,最终得到:
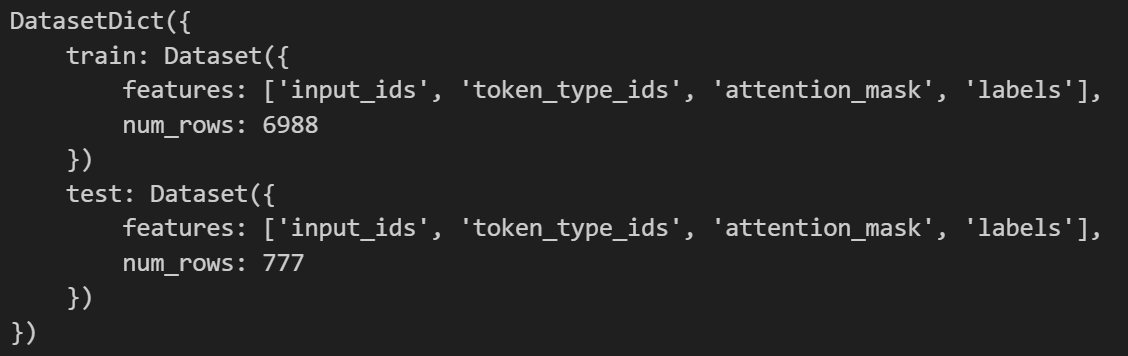
如果没有remove_columns=datasets["train"].column_names这个参数会得到:
(即移除datasets原始的中文字段)
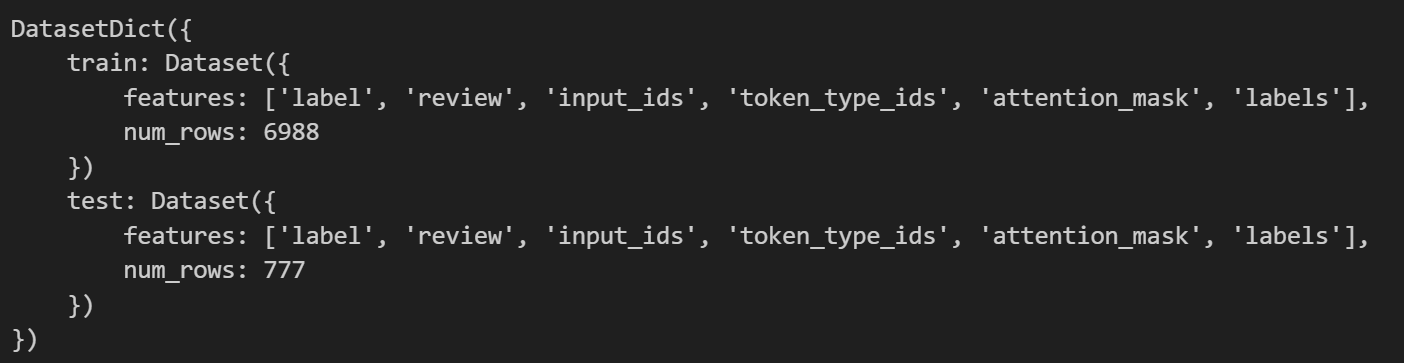
发现这里面还有原先数据集中的汉字的部分“label”“review”,这个是要注意的。
2、模型的创建、训练
model = AutoModelForSequenceClassification.from_pretrained("hfl/rbt3")同样加载预训练的模型。
(1)创建TrainingArguments
train_args = TrainingArguments(output_dir="./checkpoints", # 输出文件夹
per_device_train_batch_size=64, # 训练时的batch_size
per_device_eval_batch_size=128, # 验证时的batch_size
logging_steps=10, # log 打印的频率
evaluation_strategy="epoch", # 评估策略
save_strategy="epoch", # 保存策略
save_total_limit=3, # 最大保存数
learning_rate=2e-5, # 学习率
weight_decay=0.01, # weight_decay
metric_for_best_model="f1", # 设定评估指标
load_best_model_at_end=True) # 训练完成后加载最优模型这里定义了训练的参数。可自己根据需要增删部分。
(2)创建评估函数(用于将模型的输出变为我们能看懂的指标如准确率)
import evaluate
acc_metric = evaluate.load("accuracy")
f1_metric = evaluate.load("f1")
def eval_metric(eval_predict):
predictions, labels = eval_predict
predictions = predictions.argmax(axis=-1)
acc = acc_metric.compute(predictions=predictions, references=labels)
f1 = f1_metric.compute(predictions=predictions, references=labels)
acc.update(f1)
return acc使用evaluate库中的函数定义了两个指标:
"accuracy", "f1"eval_metric(eval_predict)函数传入的参数是由加下来的Trainer自动生成的EvalPrediction 类,包含两个核心属性:predictions(通常是 logits,即未归一化的预测概率)和label_ids。
然后通过argmax(axis=-1)函数将概率转变为分类的结果,本次的二分类中就是0和1。
再利用compute函数计算对印的指标数据,并使用update函数合并结果生成类似于:
{"accuracy": 0.85, "f1": 0.82}最终返回。
(3)创建Trainer
from transformers import DataCollatorWithPadding
trainer = Trainer(model=model,
args=train_args,
train_dataset=tokenized_datasets["train"],
eval_dataset=tokenized_datasets["test"],
data_collator=DataCollatorWithPadding(tokenizer=tokenizer),
compute_metrics=eval_metric)其中train_dataset用于训练;eval_dataset用于测试评估,监控训练效果和选择最优模型;data_collator=DataCollatorWithPadding(tokenizer=tokenizer)会根据批次中最长样本的长度自动填充短样本;compute_metrics指定评估指标计算函数,定义如何从模型预测结果中计算评估指标。
trainer.train()
trainer.evaluate(tokenized_datasets["test"])
trainer.predict(tokenized_datasets["test"])train:训练,由于再TrainingArguments 中设置了保存的参数,会保存最优的模型。每训练完 1 个 epoch(全量样本),Trainer 会先在验证集上评估模型性能,再根据评估结果决定是否保存模型。metric_for_best_model="f1":明确以 “F1 分数” 作为判断 “最优模型” 的标准(与 eval_metric 函数返回的 f1 指标对应)
evalua:遍历测试集,计算模型对每个样本的预测结果,然后调用 compute_metrics 函数生成指标,但不保存每个样本的具体预测结果(只保留统计值)。
test:遍历测试集,计算并保存每个样本的预测结果(logits 或 predictions),同时计算整体指标(调用 compute_metrics)。
至此,HuggingFace基本的操作结束!

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 27
27 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)