深度解剖vLLM:高吞吐LLM推理引擎的7大核心技术
vLLM作为分布式大模型推理引擎,通过分页注意力、连续批处理等核心技术优化性能。其架构包含KV缓存管理器、调度器和执行器,支持预处理、调度、模型执行和采样全流程。关键技术包括分页注意力机制、前缀缓存共享和推测解码,并采用预填充与解码节点分离的架构。系统支持多GPU并行和分布式扩展,通过动态负载均衡提升吞吐量。性能测试关注TTFT、ITL等指标,实现高并发AI服务支持。vLLM的创新设计使其在LLM
·
本文较长,建议点赞收藏,以免遗失。更多AI大模型应用开发学习视频及资料,尽在 聚客AI学院。
作为分布式大模型推理引擎,vLLM通过分页注意力、连续批处理等核心技术实现高吞吐与低延迟。今天我将深度解析其架构设计。如果对你有所帮助,记得告诉身边有需要的朋友。

一、核心引擎架构
1.1 基础组件
- KV缓存管理器:采用分页注意力机制(PagedAttention),将KV缓存划分为固定大小块(默认16 tokens/块),通过内存池动态分配:
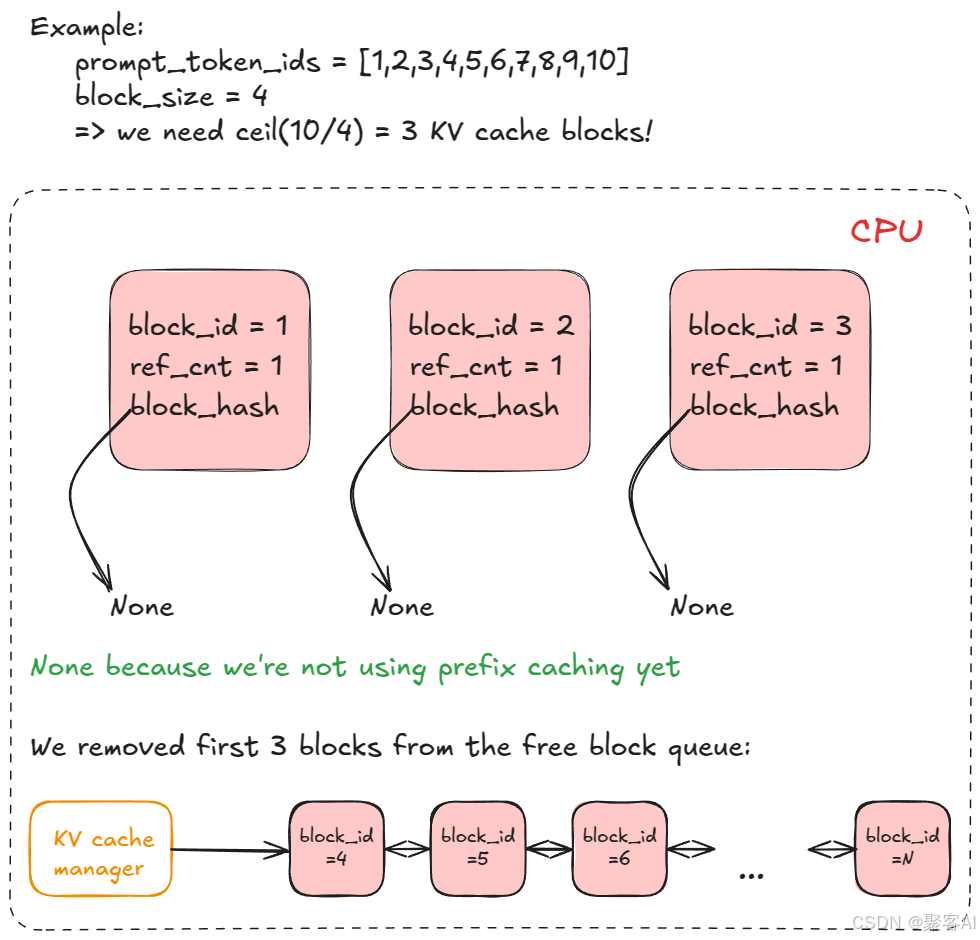
- 调度器:支持FCFS/优先级调度,维护等待队列与运行队列,混合处理预填充与解码请求
- 执行器:驱动模型前向传播,支持即时执行与CUDA图优化
1.2 推理流程
1)请求预处理:分词后生成EngineCoreRequest
2)调度阶段:
- 解码请求优先分配KV块
- 预填充请求按令牌预算分块处理
3)模型执行:
- 扁平化批次输入,分页注意力确保序列隔离
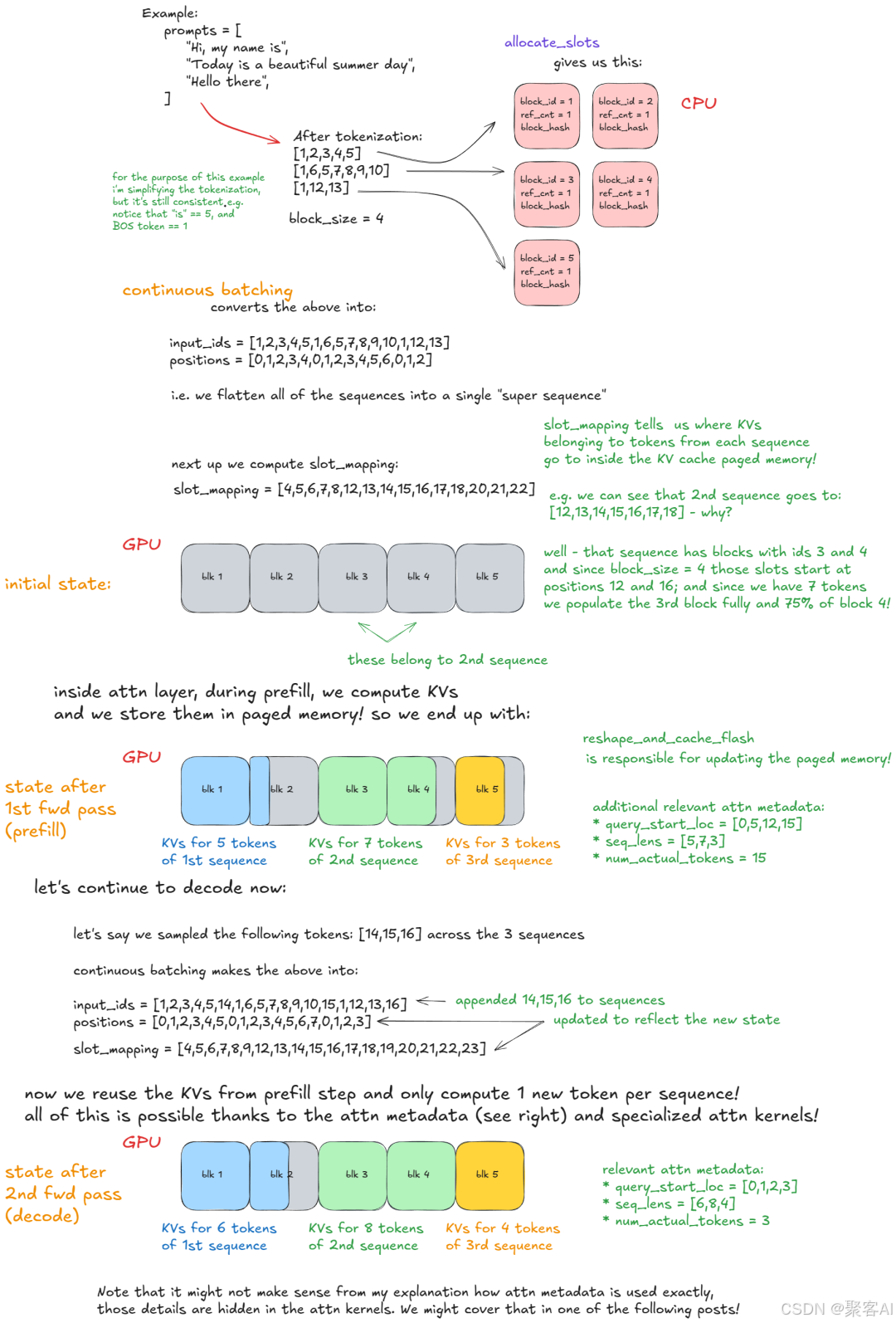
4)采样与后处理:根据采样参数生成token,检测停止条件
二、关键技术优化
2.1 分页注意力(PagedAttention)
- 块大小公式:
2 * block_size * num_kv_heads * head_size * dtype_bytes - 内存零碎片:释放块回归资源池实现高效复用
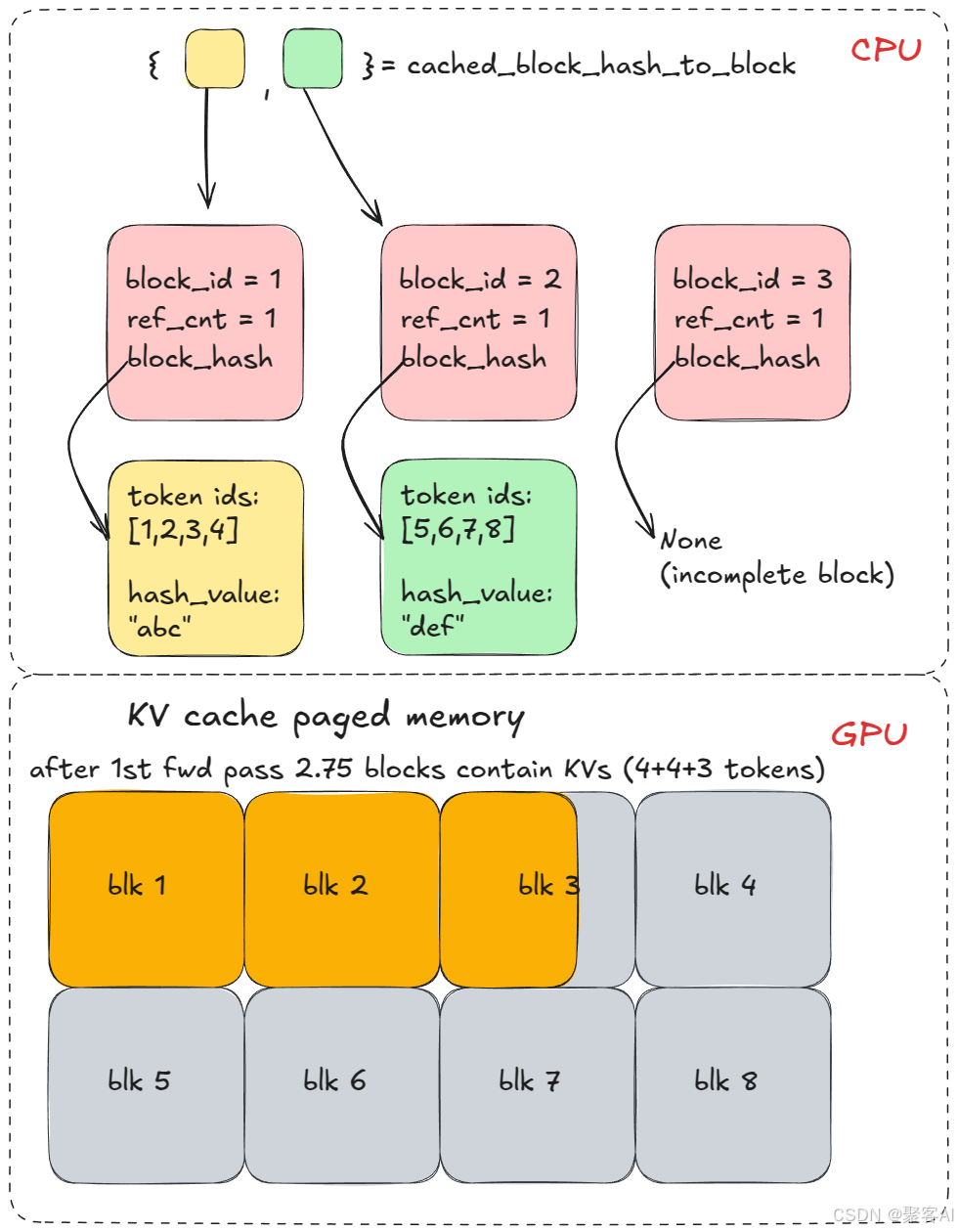
2.2 前缀缓存
- 共享前缀哈希化存储:对16-token完整块计算SHA-256哈希
- 复用机制:后续请求匹配哈希直接调用缓存块
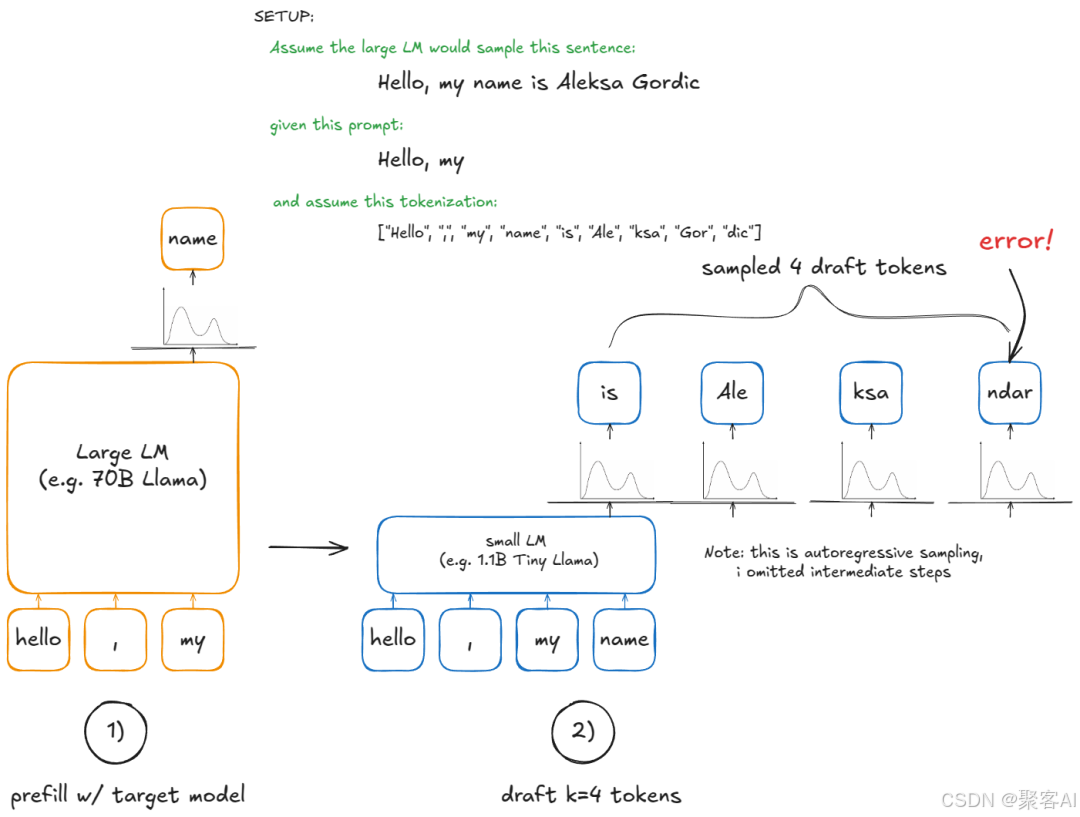
2.3 推测解码
流程:
- 草稿模型(N-gram/EAGLE/Medusa)生成k候选token
- 大模型并行验证k+1个位置概率
- 按接受规则输出有效token
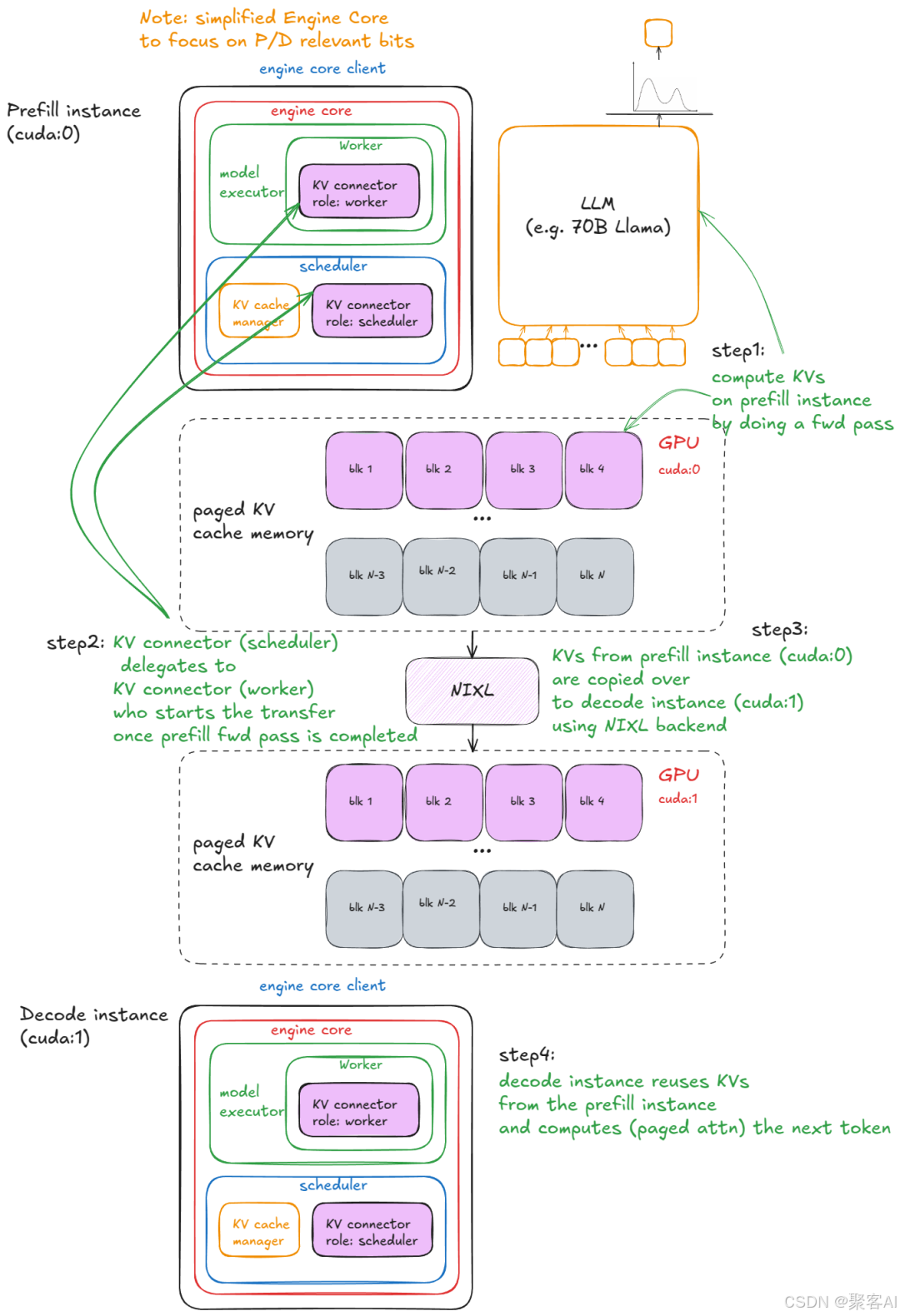
2.4 解耦式P/D架构
- 预填充节点:处理长提示计算,输出KV至缓存服务
- 解码节点:专注token生成,读取共享KV缓存
- 连接器协调:跨节点KV传输实现计算隔离
三、分布式扩展
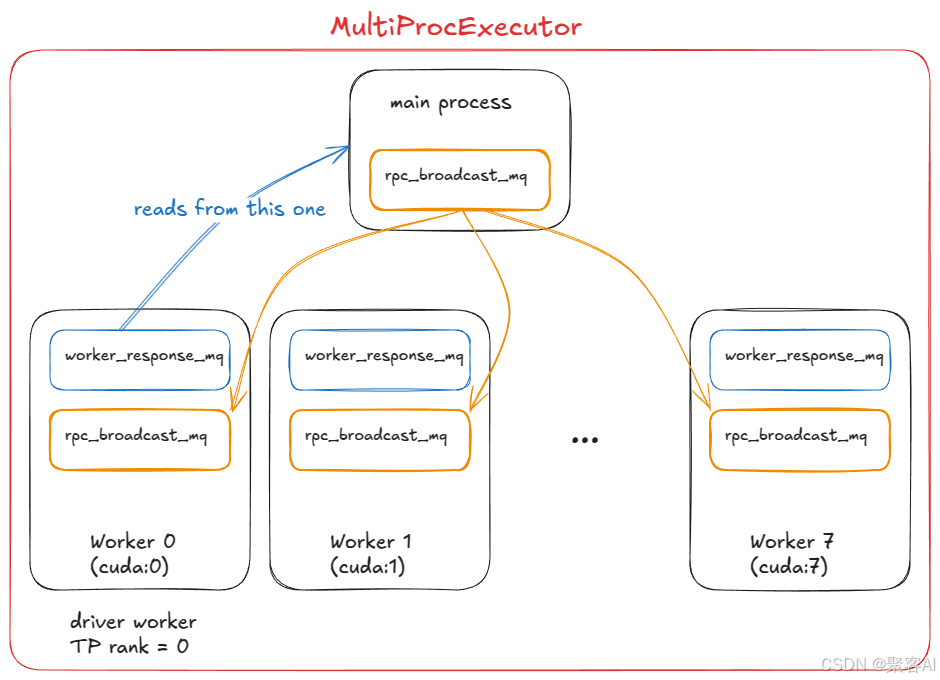
3.1 多GPU执行(MultiProcExecutor)
- 张量并行:模型层分片至同节点多GPU
- 流水线并行:跨节点分层处理长序列
- 工作进程通过ZMQ实现RPC通信:
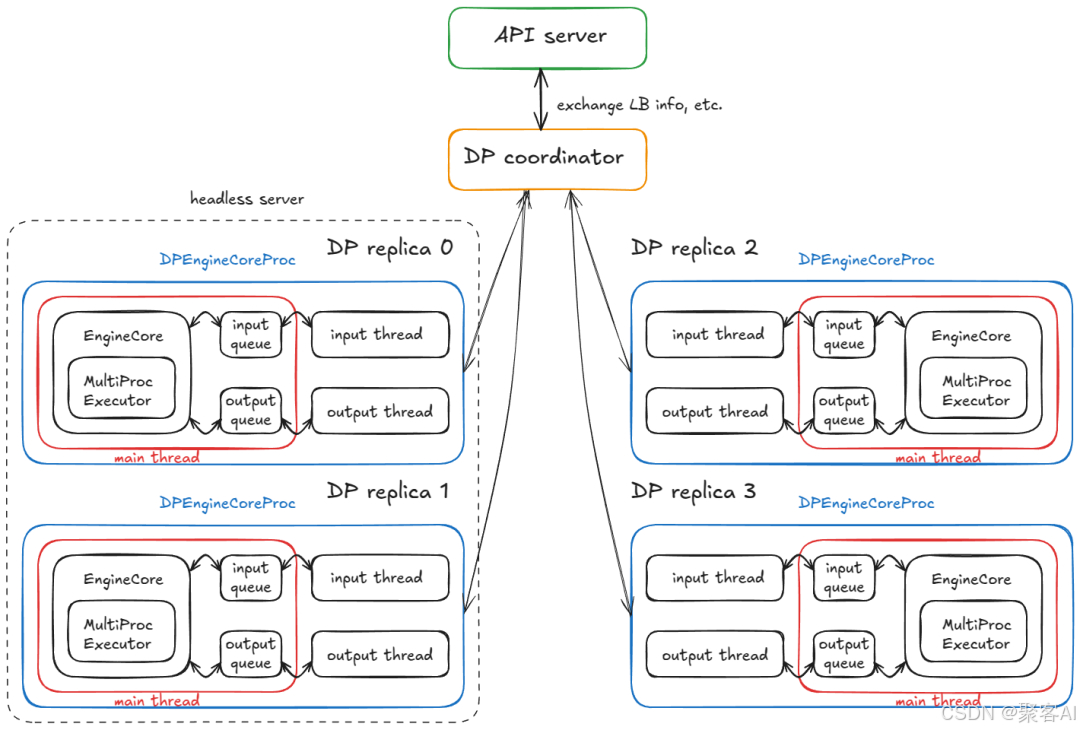
3.2 服务层架构
无头引擎节点:运行DPEngineCoreProc处理计算
API服务节点:
AsyncLLM封装引擎接口- FastAPI提供REST端点
- DP协调器动态负载均衡
请求生命周期:
四、性能优化与基准测试
4.1 关键指标
| 指标 | 定义 |
|---|---|
| TTFT | 首token生成延迟 |
| ITL | token间延迟 |
| TPOT | 单token平均处理时间 |
| Goodput | 满足SLO的吞吐量 |
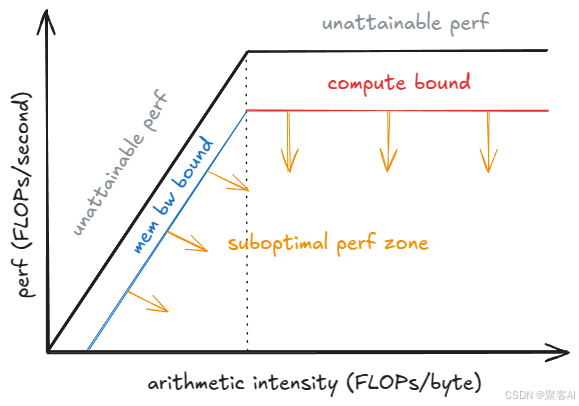
4.2 性能权衡模型
批大小影响:
- 小批量:ITL↓,吞吐量↓
- 大批量:ITL↑,吞吐量↑(至饱和点)
4.3 调优工具
vllm bench latency:测量端到端延迟vllm bench throughput:压力测试峰值吞吐- 自动SLO优化:动态调整参数满足延迟约束
最后总结一下
vLLM通过创新内存管理、分布式调度与算法优化,在LLM推理场景实现数量级性能提升。其模块化设计支持从单GPU到多节点集群的灵活部署,为高并发AI服务提供基础架构支撑。当然,主流的LLM推理框架除了vLLM,还有其它几大框架,具体的选择根据实际项目需求来定,几大框架的优势对比及选型,我这里也做了一个技术文档,实力宠粉。粉丝朋友自行领取:《大型语言模型(LLM)推理框架的全面分析与选型指南(2025年版)》
好了,今天的分享就到这里,点个小红心,我们下期见。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 12
12 0
0- 0



 已为社区贡献27条内容
已为社区贡献27条内容

所有评论(0)