多模态信息抽取:CLIP模型,看完这篇文章我又又又悟了!
CLIP(Contrastive Language-Image Pre-training)是由OpenAI开发的多模态预训练模型,能够将图像和文本映射到同一嵌入空间,通过对比学习实现图文匹配。该模型包含文本编码器和图像编码器,采用对比损失函数优化,使匹配的图文对向量相近,不匹配的相距较远。CLIP突破了传统固定类别标签的限制,仅需图像-文本对即可训练,无需人工标注类别。其应用广泛,包括图像分类、图
经典图像分类器
在训练模型检测图像是猫还是狗时,一种常见的方法是向模型提供猫和狗的图像,然后根据误差逐步调整模型,直到学会区分两者。
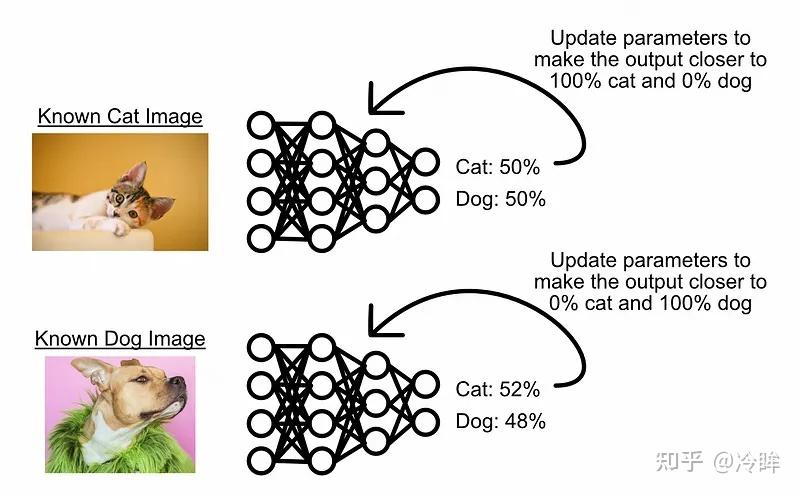
这些模型仅在其训练的范围内表现良好。
2021开年,顶着地表最强语言模型GPT-3的光环,OpenAI在自然语言处理领域一路高歌猛进,推出两个跨越文本与图像次元的模型:DALL·E和CLIP。
CLIP是一个预训练模型,就像BERT、GPT、ViT等预训练模型一样。首先使用大量无标签数据训练这些模型,然后训练好的模型就能实现,输入一段文本(或者一张图像),输出文本(图像)的向量表示。
CLIP和BERT,GPT,ViT的区别在于,CLIP是多模态的,包含图像处理以及文本处理两个方面的内容,而BERT,GPT是单模态的,VIT是单模态图像的。


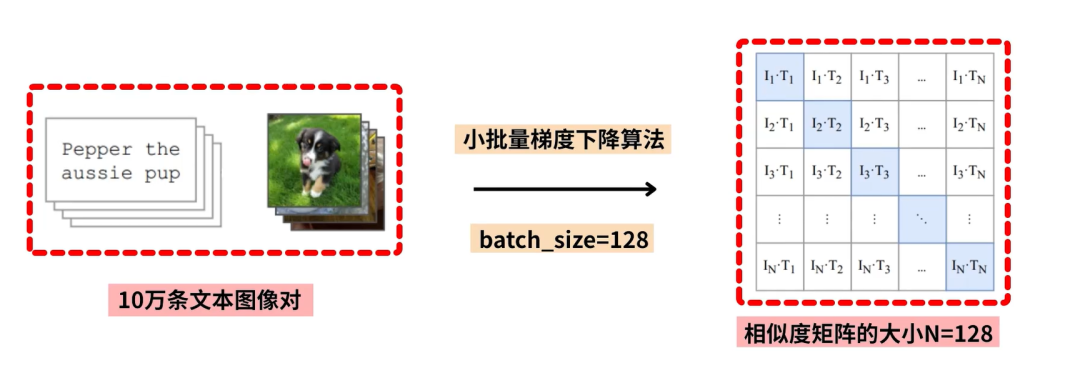
因此OpenAI 到网上爬了4亿个图像-文本对,构建了数据集WIT(WebImageText)。WIT数据集中的文本都是图像相关的sentence,而不是single-word,因此提供了足够的自然语言数据(光文本的存储就需要100个T)。
CLIP模型架构图详解
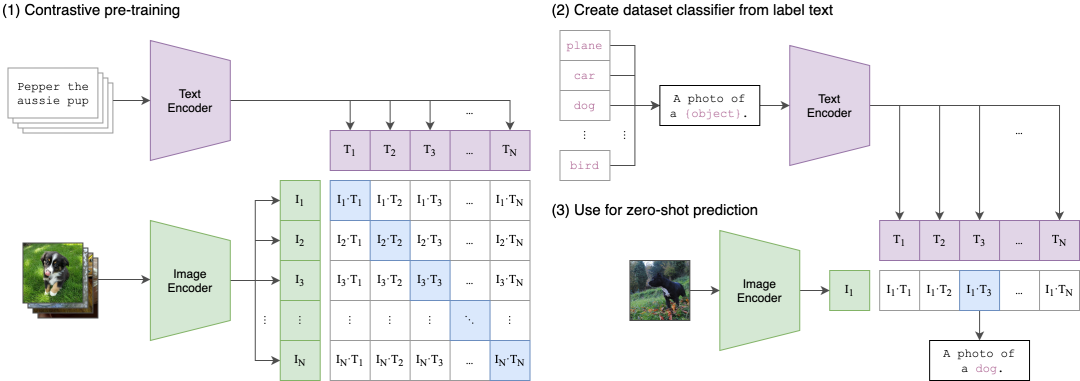
CLIP全称是Contrastive Language-Image Pre-training,根据字面意思,就是对比-图像预训练模型,只需要提供图像类别的文本描述,就能进行图像的分类。
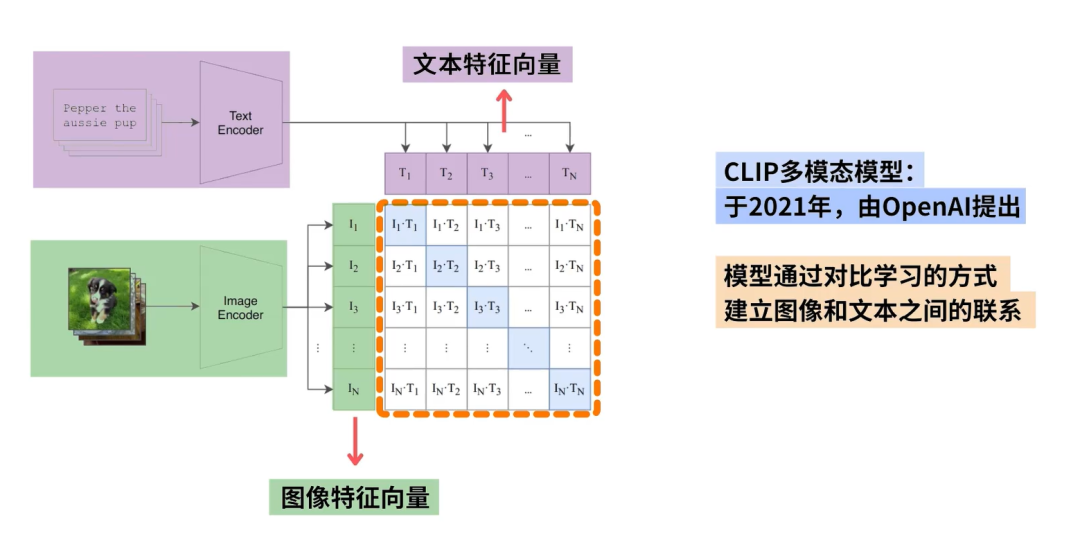
该模型学习将图像和文本映射到同一个Embedding空间中,使得匹配的图和文Embedding彼此靠近,而不匹配的图和文Embedding彼此相距较远。这种学习预测事物是否属于同一类或不属于同一类的策略通常被称为“对比学习” (contrastive Learning)。
对于一个包含了N个图像-文本对的batch而言,其中的正样本是每张图像及其对应的文本,一共有N个(正样本),而其他所有的图像-文本的组合都是不成对的,也就是负样本是N * N - N个。
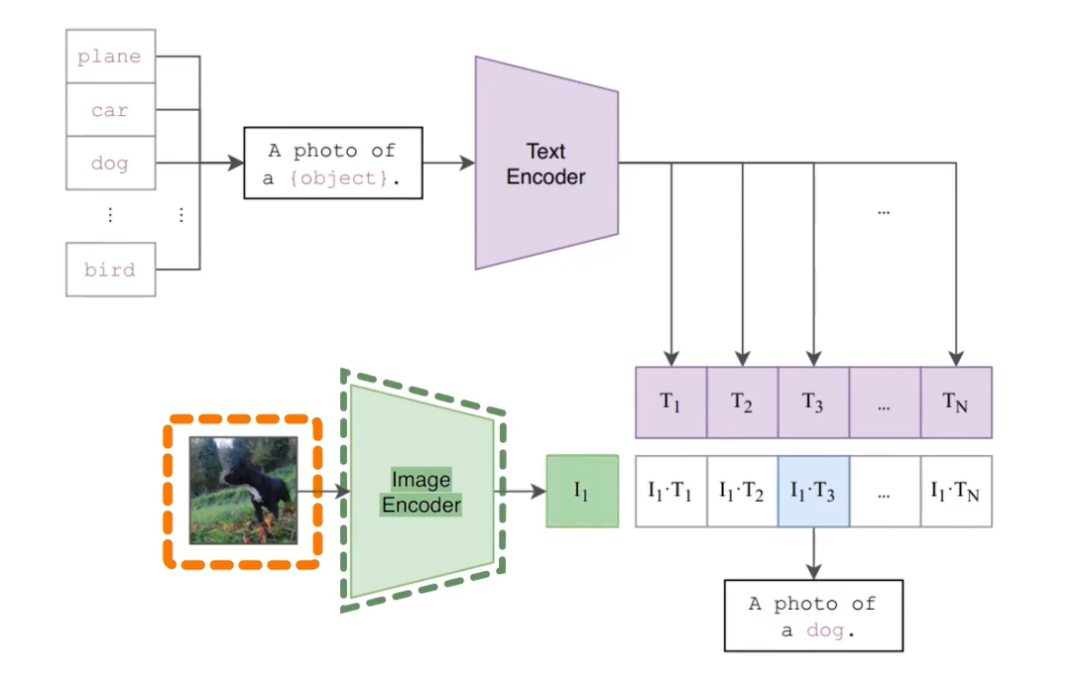
如下图所示,CLIP的主要结构是一个文本编码器Text Encoder和一个图像编码器Image Encoder,然后计算文本向量和图像向量的相似度来预测他们是否是一对。
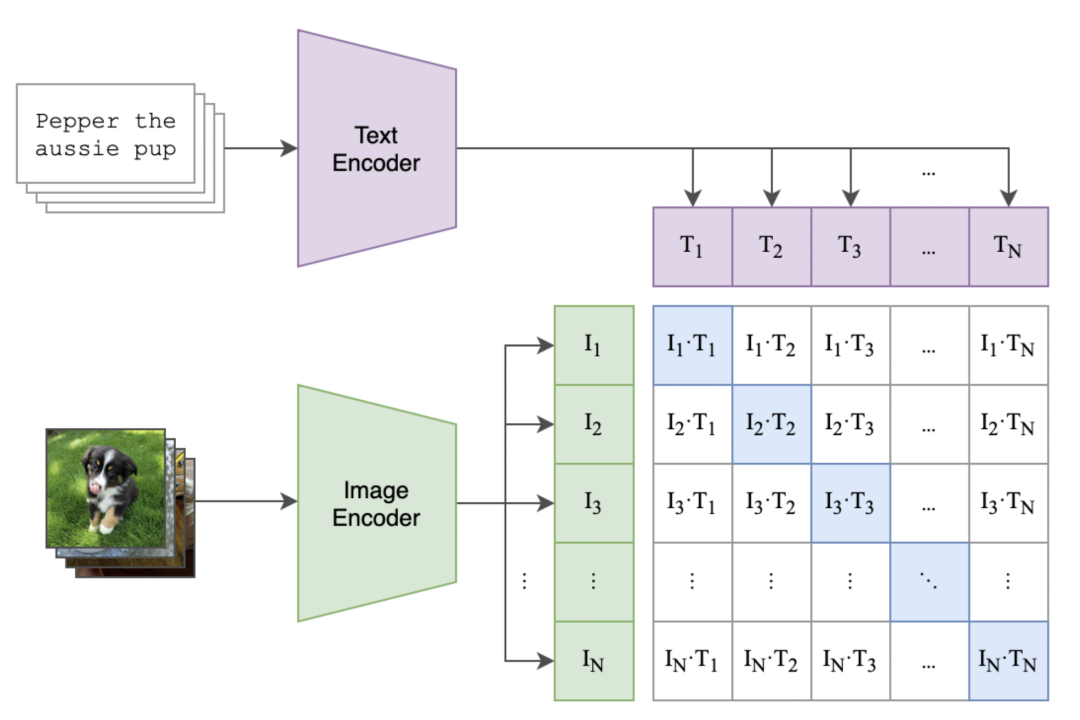
CLIP 是一种High-Level的框架,不局限于某个具体的网络结构,可以使用各种不同的子组件来实现相同的结果。
文本编码器
CLIP 中的文本编码器将输入文本转换为表示文本含义的Embedding向量(数字列表)

-
CLIP的效果对文本编码器不敏感
-
- 可以用bert也可以用Transformer
- 32 epochs Adam 优化器
- minibatch 32768
- 592 V100 GPU (跑18天)
图像编码器
图像编码器将图像转换为表示图像含义的Embedding向量(数字列表)
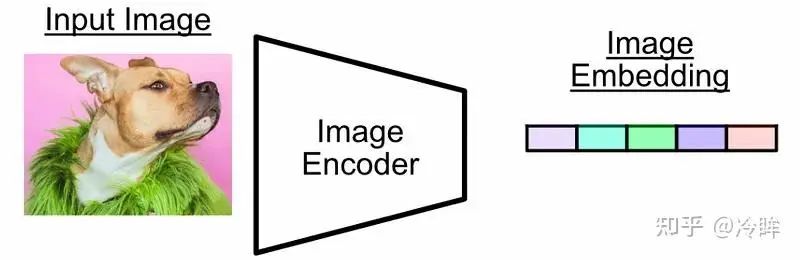
图像编码器有两种架构:
- 使用ResNet50作为基础架构;
- 使用Vision Transformer(ViT)进行实验;
CLIP 的训练样本
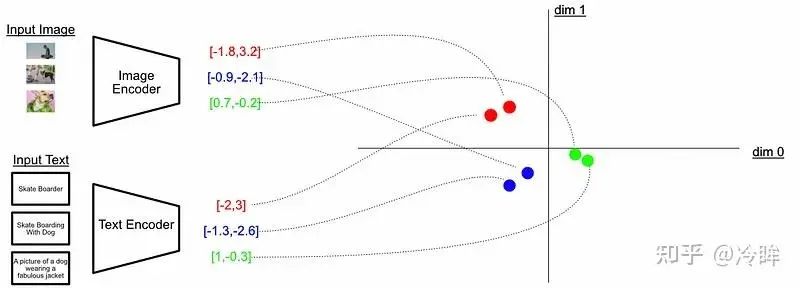
我们可以将这些Embedding 视为将输入(图片或者文本)表示为高维空间中的某个点。
将这个二维空间视为多模态嵌入空间,并且我们可以训练 CLIP(通过训练图像和文本编码器)从而将这些点映射到图文彼此接近的位置。
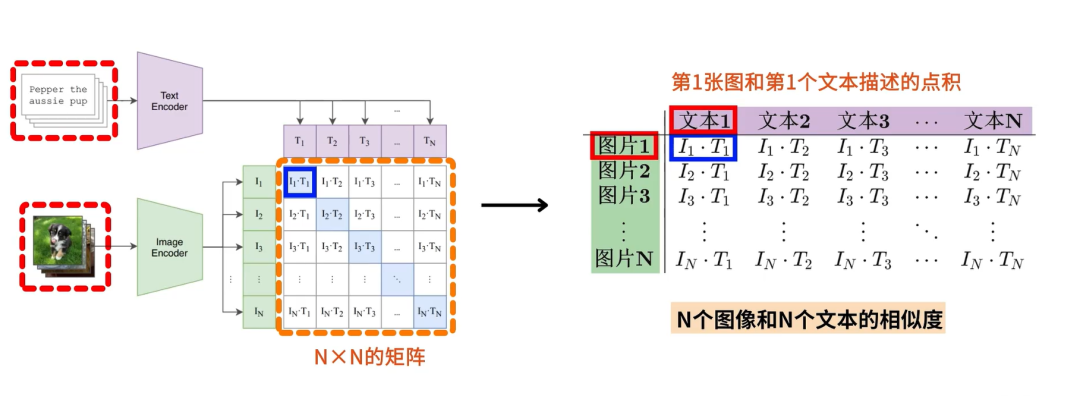
- 目标是期望对角线上的预测为正样本,其他位置预测为负样本
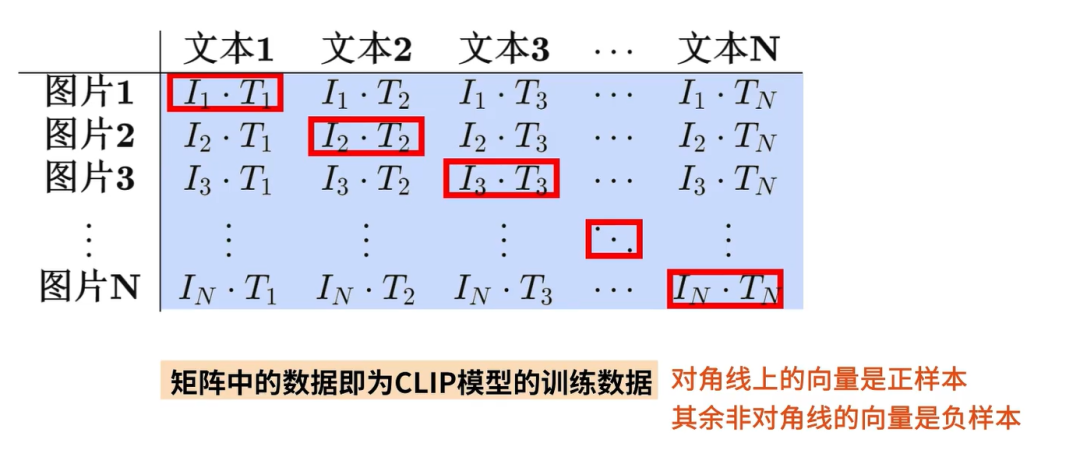
- 当图像和文本匹配的时候,他们的向量是相似的,否则他们就是不相似;
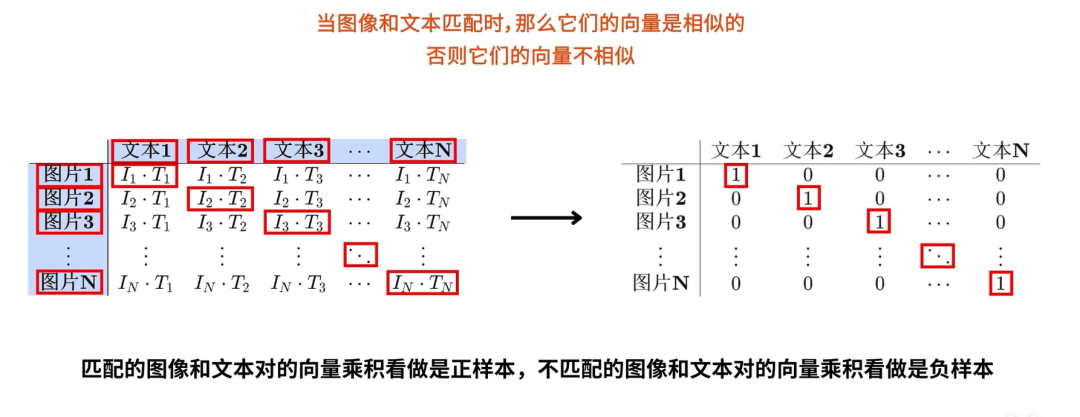
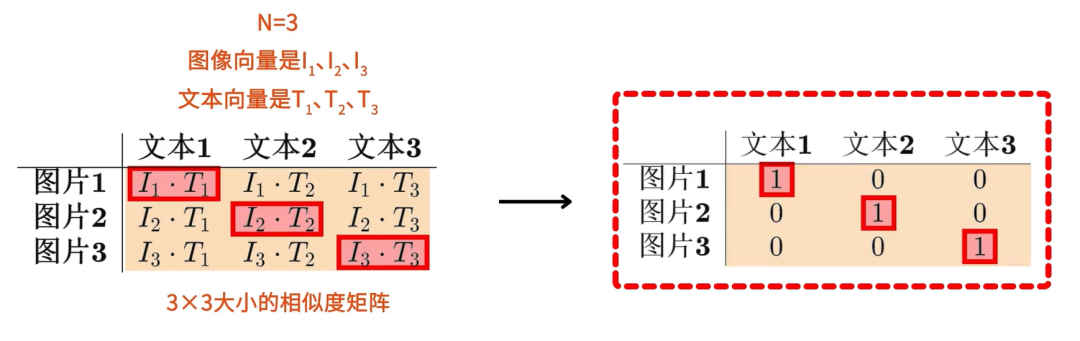
基于对比学习的损失函数
训练过程
-
第一步,根据Eccoder 计算出文本和图片的Embedding;
-
第二步,计算任意图像和文本的相似度、文本和图像的相似度;
-
第三步,已知对角线上的是正样本,其他位置是负样本,用交叉熵损失函数优化;
文字描述
训练代码
CLIP这篇工作最大的贡献,是他打破了之前固定种类标签的范式,不论在你收集数据集的时候,还是在训练模型的时候,你都不需要像imagenet一样做1000类,或这像Coco那样做80类,直接就搜集这种图像文本对就可以了,然后用无监督的方式,要么去预测它的相似性,要么去生成它
CLIP的使用
图像分类任务
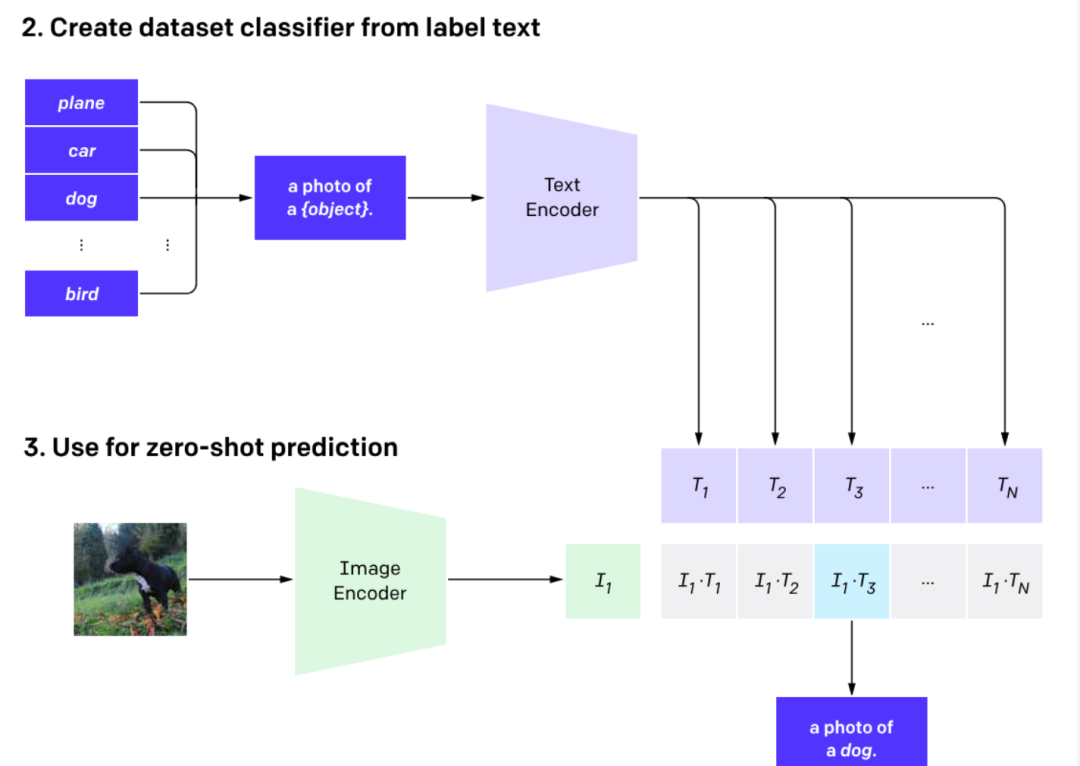
- 用提示词增强扩充类别信息,OpenAI搞了80个提示词模板;
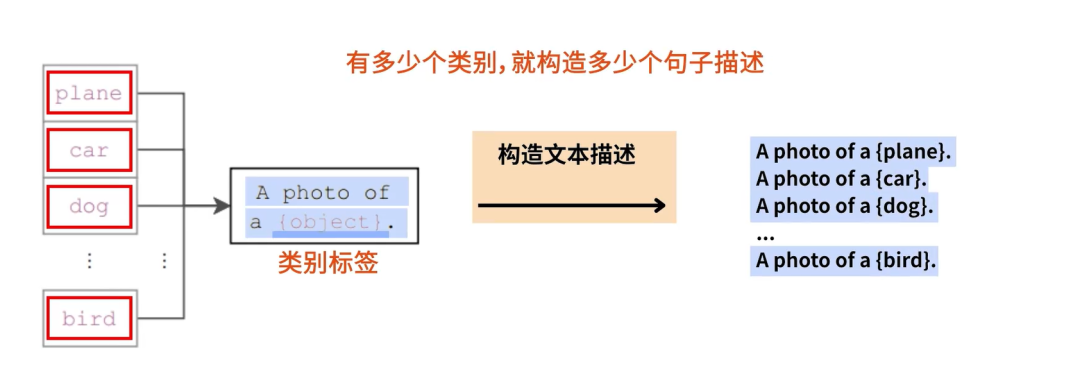
- 获取文本的embedding;
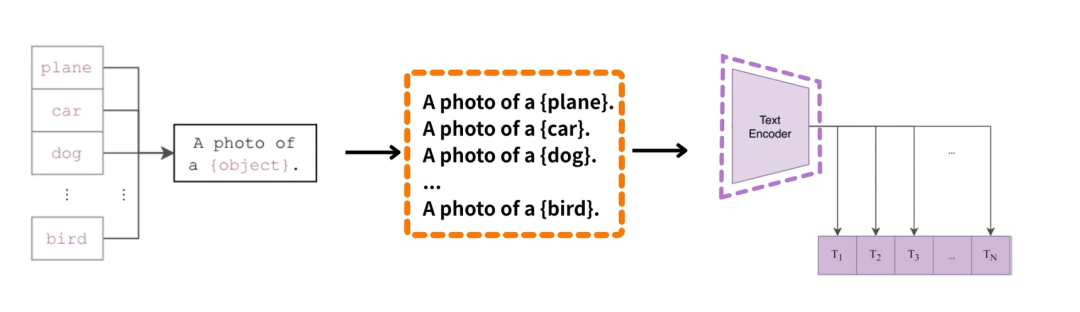
- 获取图片的embedding, 计算出最可能的类别;

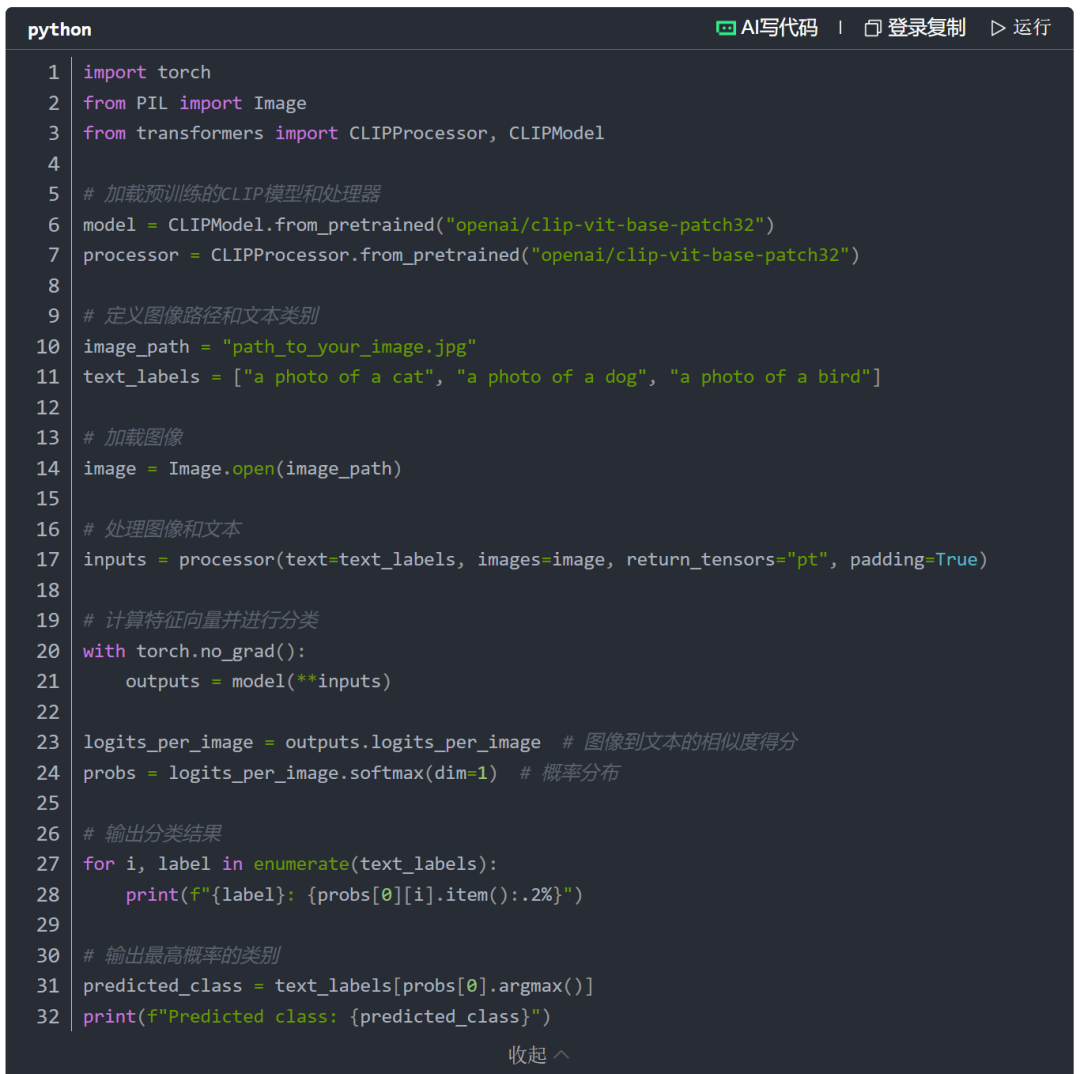
2.加载CLIP模型并进行图像分类:
CLIP的其他应用
CLIP 采用的训练策略允许我们做各种各样的事情:
-
图像搜索
-
- 用户可以输入一段描述性文本,CLIP会在图像数据库中找到与该描述最匹配的图像。
- 例如,输入"一个骑自行车的人",CLIP会返回包含骑自行车场景的图像。
-
特征抽取
-
- 使用编码器抽取Embedding供其他机器学习模型使用。
-
文本生成
-
- CLIP可以用于生成与图像内容相关的文本描述,从而应用于图像标注、自动生成图像标题等任务
最后
选择AI大模型就是选择未来!最近两年,大家都可以看到AI的发展有多快,我国超10亿参数的大模型,在短短一年之内,已经超过了100个,现在还在不断的发掘中,时代在瞬息万变,我们又为何不给自己多一个选择,多一个出路,多一个可能呢?
与其在传统行业里停滞不前,不如尝试一下新兴行业,而AI大模型恰恰是这两年的大风口,整体AI领域2025年预计缺口1000万人,人才需求急为紧迫!
由于文章篇幅有限,在这里我就不一一向大家展示了,学习AI大模型是一项系统工程,需要时间和持续的努力。但随着技术的发展和在线资源的丰富,零基础的小白也有很好的机会逐步学习和掌握。
【2025最新】AI大模型全套学习籽料(可白嫖):LLM面试题+AI大模型学习路线+大模型PDF书籍+640套AI大模型报告等等,从入门到进阶再到精通,超全面存下吧!
获取方式:有需要的小伙伴,可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】
包括:AI大模型学习路线、LLM面试宝典、0基础教学视频、大模型PDF书籍/笔记、大模型实战案例合集、AI产品经理合集等等
大模型学习之路,道阻且长,但只要你坚持下去,一定会有收获。本学习路线图为你提供了学习大模型的全面指南,从入门到进阶,涵盖理论到应用。
L1阶段:启航篇|大语言模型的基础认知与核心原理
L2阶段:攻坚篇|高频场景:RAG认知与项目实践
L3阶段:跃迀篇|Agent智能体架构设计
L4阶段:精进篇|模型微调与私有化部署
L5阶段:专题篇|特训集:A2A与MCP综合应用 追踪行业热点(全新升级板块)





AI大模型全套学习资料【获取方式】

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 15
15 0
0- 0



 已为社区贡献74条内容
已为社区贡献74条内容

所有评论(0)