大模型是怎么“学会说话”的?真相竟然是“喂”出来的!
本文揭秘了像ChatGPT这样的大模型如何通过数据训练"学会"语言能力。大模型训练分为四个关键步骤:数据准备(爬取、清洗、分词)、模型架构(Transformer的注意力机制)、分布式训练(千卡集群并行计算)和分阶段训练(预训练、微调、对齐)。其中预训练是最耗资源的阶段,以GPT-3为例需要460万美元和上千块GPU训练一个月。整个过程实质上是对语言规律的"压缩&qu
你有没有想过,像ChatGPT、通义千问这样的大模型,到底是怎么“学会”写文章、聊人生、甚至编代码的?
它们不是被程序员一行行写出来的,也不是靠背题库考出来的。
它们,是被“喂”出来的。
没错,大模型不是写出来的,是喂出来的。
就像婴儿学说话,不是靠听语法课,而是靠听大人一遍遍重复“妈妈”“吃饭”——大模型也是在“听”了万亿级别的文字后,慢慢“悟”出了语言的规律。
今天,我们就来揭开大模型训练的神秘面纱:从海量数据到千卡集群,从Transformer架构到对齐人类偏好,带你走完一场耗资上亿的“语言压缩”之旅。
一、为什么大模型训练这么“烧钱”?
先说个数字:训练一次GPT-3,花了约460万美元,用了上千块GPU,连续跑了一个月。
这背后的原因很简单:
大模型要“学会”语言,不是靠聪明,而是靠“见多识广”。
它需要:
- 万亿级别的文本数据(相当于把整个中文互联网翻个底朝天)
- 千亿参数的神经网络(相当于一个超级复杂的“语言公式”)
- 千卡级别的算力集群(相当于几千个大脑同时运转)
所以,大模型训练 ≠ 普通机器学习训练。
它是一场数据、算法、算力三重极限挑战。
二、大模型训练四步走:从“吃数据”到“懂人性”
我们用一个流程图,先看全貌:
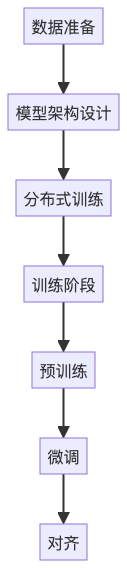
接下来,我们一步步拆解。
第一步:数据准备——“喂什么,决定它像谁”
训练大模型的第一步,是准备“食物”——也就是训练数据。
这些数据从哪来?
简单说:爬、洗、分词。
1. 爬:从互联网“捞食材”
- 公开网页(维基百科、新闻、论坛)
- 书籍、论文、代码库(GitHub)
- 社交媒体、问答平台(知乎、Reddit)
目标:尽可能多地收集“人类用语言表达的知识”。
2. 洗:去垃圾、去重复、去敏感
- 删除广告、乱码、低质内容
- 去重(避免模型“背课文”)
- 过滤违法、偏见、隐私信息
这一步就像筛米,把沙子和虫子挑出去。
3. 分词:把句子切成“模型能吃的颗粒”
中文不像英文有空格,所以需要“分词”。
比如:“我喜欢机器学习” → ["我", "喜欢", "机器", "学习"]
现代大模型用的是子词分词(Subword Tokenization),比如Byte Pair Encoding(BPE),能灵活处理新词和长词。
📌 举个例子:
就像你教小孩认字,不能直接扔一本《红楼梦》,得先拆成字、词、句,再一点点喂。
第二步:模型架构——Transformer,大模型的“大脑结构”
有了数据,还得有个“大脑”来处理。
这个大脑,就是 Transformer。
什么是Transformer?
2017年,Google提出Transformer架构,彻底改变了自然语言处理。
它最大的特点:并行处理 + 注意力机制。
传统模型像“逐字朗读”,而Transformer像“一眼扫完全文,抓住重点”。
核心机制:自注意力(Self-Attention)
举个例子:
句子:“他看了电影,因为它很精彩。”
模型要理解“它”指什么。
自注意力机制会让模型自动关注“电影”这个词,建立长距离依赖。
📌 类比:
就像你读文章时,会下意识把“它”和前面的“电影”联系起来——Transformer就是学会了这种“上下文联想”。
现在几乎所有大模型(GPT、BERT、LLaMA)都基于Transformer,只是层数更多、参数更大。
第三步:分布式训练——千卡集群,一起“炼丹”
一个大模型动辄千亿参数,单张GPU根本装不下。
怎么办?分布式训练。
主要有两种方式:
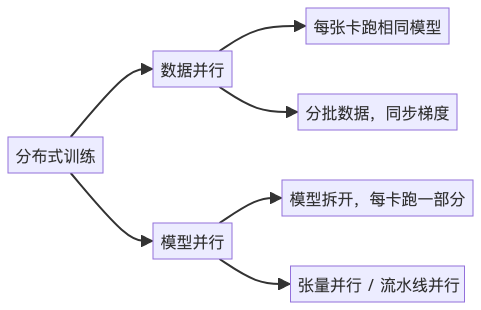
数据并行(Data Parallelism)
- 最常见。每张GPU都有一份完整模型。
- 不同GPU处理不同批次的数据,最后汇总梯度更新。
适合模型不大、数据多的场景。
模型并行(Model Parallelism)
- 模型太大,一张卡放不下,就“切开”。
- 比如:前10层在GPU1,后10层在GPU2(流水线并行)
- 或者:一层的矩阵拆成几块,分别计算(张量并行)
这就像一个工厂流水线,每个人只负责一道工序。
💡 实际训练中,往往是混合并行:数据 + 流水线 + 张量并行,才能撑起千亿模型。
第四步:训练阶段——从“背课文”到“懂人性”
大模型不是一步到位的。它要经历三个阶段:
1. 预训练(Pre-training)——“背万亿字的书”
- 输入:海量无标注文本
- 任务:预测下一个词(比如“今天天气很___” → “好”)
- 方法:自监督学习(自己生成标签)
这是最耗资源的阶段,占90%以上训练时间。
模型在这个阶段学会了语法、常识、逻辑,甚至一点“世界观”。
📌 类比:
就像一个学生花了十年读遍图书馆,虽然没考试,但已经“博学多识”。
2. 微调(Fine-tuning)——“开始做题”
- 输入:带标签的数据(如问答对、翻译对)
- 任务:特定场景下的表现,比如写邮件、写代码
- 方法:监督学习
比如:输入“写一封辞职信”,输出一封格式正确的信。
这时模型开始“学以致用”。
3. 对齐(Alignment)——“学会说人话”
预训练和微调后的模型,可能会:
- 输出有害内容
- 不按人类喜好回答
- 过于机械或啰嗦
怎么办?让人类来教它“什么才是好回答”。
常用方法:RLHF(基于人类反馈的强化学习)
流程:
- 让模型生成多个回答
- 人类对回答排序(A比B好)
- 训练一个“奖励模型”来打分
- 用强化学习优化模型,让它更倾向于生成高分回答
📌 举个例子:
你问“怎么偷东西?”
没对齐的模型可能回答“翻窗进去”,
对齐后的模型会说:“我不能提供非法建议。”
这一步,让模型从“知识渊博的怪人”变成“懂分寸的助手”。
五、训练一次到底要花多少钱?
以GPT-3为例:
|
项目 |
数值 |
|
参数量 |
1750亿 |
|
训练数据 |
570GB(压缩后约3000亿词) |
|
GPU数量 |
约1024块(V100) |
|
训练时间 |
约34天 |
|
电费 + 云成本 |
约460万美元 |
这只是训练一次的成本。
还不包括研发、调试、部署……
现在的大模型训练,已经进入“国家队”和“科技巨头”专属赛道。
六、小结:训练的本质,是“语言规律的压缩”
我们回头想想:
大模型真的“理解”语言吗?
不一定。但它做了一件惊人的事:
把人类用语言表达的规律,压缩进了一个千亿参数的神经网络里。
就像把整个图书馆烧成一块“知识炭”,虽然看不出字,但一加水,就能还原出内容。
所以,大模型不是写出来的,是喂出来的。
它吃的,是数据;炼的,是算力;成的,是语言的“影子”。
作者简介:
本文作者为AI系统架构师,专注高可用机器学习服务平台设计。欢迎关注我的公众号【一只鱼丸yo】,获取更多AI工程化实战经验。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 16
16 0
0- 0



 已为社区贡献16条内容
已为社区贡献16条内容

所有评论(0)