RAG分块21式:彻底解决检索增强生成难题
本文系统介绍了21种RAG系统数据分块策略。从最基础的换行符分割到高级的混合分块法,覆盖了不同数据类型和应用场景的需求。重点策略包括:定长分块法适用于杂乱文本,滑动窗口保持上下文连贯,按句/段分块处理结构化文档,语义分块基于嵌入相似度聚合内容。特别指出智能体分块法虽成本高但能处理复杂内容,分层分块法适合技术文档等多层次结构。最后强调混合分块法可组合多种策略应对复杂数据结构。合理选择分块策略是提升R
前言
检索增强生成(RAG)是让AI工程师又爱又恨的技术。
表面上看,原理极其简单:只需"从定制数据中检索相关信息,再让大语言模型基于此生成回答"。
但实践起来却困难重重:你不得不面对杂乱无章的数据——它们以各种混乱的格式存储,然后陷入数日反复调试的噩梦:
- 调整文本块
- 更换嵌入模型
- 替换检索器
- 优化排序器
- 重写提示词 即便如此,模型仍可能回复:"相关信息不足"。
更糟的是,它还会充满自信地给出错误答案(即产生幻觉)。
虽然RAG系统包含众多复杂组件,但真正决定成败的关键因素其实是数据分块(chunking)。
不同数据类型、文件格式、内容结构、文档长度和应用场景,都需要匹配特定的分块策略。
一旦分块不当,你的模型要么抓不住重点,要么...依然抓不住重点。
本文将详解21种分块策略(从基础到进阶),并说明每种策略的适用场景,让你的RAG系统不再...掉链子。
正文
1)基础分块法(按换行符分割)Naive chunking (split by newline)
遇到换行符就分割文本。仅此而已。

适用场景:
- 处理由换行符统一分隔的文本:笔记、项目列表、FAQ、聊天记录或每一行都包含完整语义的文字转录稿。
注意:如果内容行过长,可能超出 LLM 的词元限制。如果内容行过短,模型可能遗漏上下文或产生幻觉。
2)定长分块法 Fixed-size/fixed window chunking
按固定字符数 / 单词数切割文本(即便这样会切断完整句子或语义单元)。

适用场景:
- 适用于原始的、杂乱的文本数据,如扫描文档、质量较差的转录文本,或无标点、无标题、无其他结构的大型文本文件。
3)滑动窗口分块法 Sliding window chunking
类似定长分块,但每个文本块会与前块内容重叠,以保持跨块上下文之间的关联。

适用场景:
- 处理需要保持长句间逻辑连贯性的文本类型:议论文、叙述性报告、自由形式的写作等。
- 与定长分块法类似,适用于无结构的文本(无标题、无标点、无框架等),但需注意词元消耗与上下文连贯性间的平衡。
4)按句分块法 Sentence-based chunking
在句子结尾处分割文本(通常以句号、问号或感叹号为标记)。

适用场景:
- 适用于语义清晰的规整文本,每句话都承载着完整的语义,如技术博客、内容摘要或文档。
- 可作为初级的分块手段产出小而聚焦的文本块,便于后续通过更复杂的分块技术重新组合或重排序这些文本块。
5)按段分块法 Paragraph-based chunking
依据段落分割文本(通常以双换行符为界),使每块均包含完整的语义单元。

适用场景:
- 当按句分块所得内容过于零碎时
- 处理已具备段落结构的文档,如议论文、博客文章或研究报告
6)按页分块法 Page-based chunking
将每个物理页面视为一个独立文本块。

适用场景:
- 处理含固定页面的文档,如扫描版 PDF、演示文稿或书籍。
- 需保留页面布局的检索场景(如在检索时需要引用页码)。
7)按预定结构分块法 Structured chunking
依据预定结构(如具有固定格式的系统日志记录、结构化数据中的预定义字段、HTML 标签或 Markdown 元素)分割文本。

适用场景:
- 处理结构化 / 半结构化数据,如系统日志、JSON 记录、CSV 文件或 HTML 文档。
8)基于文档层级的分块法 Document-Based Chunking
基于文档固有结构分块(按标题 / 小标题 / 章节划分)。

适用场景:
- 当源文件具备清晰的章节结构时,如在技术文章、操作手册、教材或学术论文中。
- 可作为进阶分块技术(如按层级分块(hierarchical chunking))的预处理步骤。
9)基于关键词的分块法 Keyword-based chunking
在预设关键词出现处分割文本,将其视为逻辑断点。

适用场景:
- 文档无标题结构但含标志性的关键词(且这些关键词可稳定标记新主题的起始)时使用
10)基于实体的分块法 Entity-based chunking
使用命名实体识别(NER)模型检测人物、地点、产品等实体,将相关文本围绕每个实体分组形成区块。

适用场景:
- 处理特定类型的实体(人物 / 地点 / 组织等)对文档理解起决定性作用的文件,如新闻报道、法律合同、案例研究或电影剧本。
11)基于词元数的分块法 Token-based chunking
通过 tokenizer(分词器)按词元数量分割文本。
建议结合按句分块法(sentence chunking)等技术使用,避免破坏句子完整性导致上下文被破坏。
适用场景:
- 无标题 / 无段落结构的非结构化文档。
- 使用低词元限制的 LLM 时(避免响应被强制截断或长文本输入被丢弃)。
12)基于主题的分块法 Topic-based chunking
当文本主题发生变化时,可以通过以下方式对文本进行分块:
- 首先,将文本拆分为小单元(句子 / 段落)
- 然后,使用主题建模或聚类算法将相关单元合并为区块
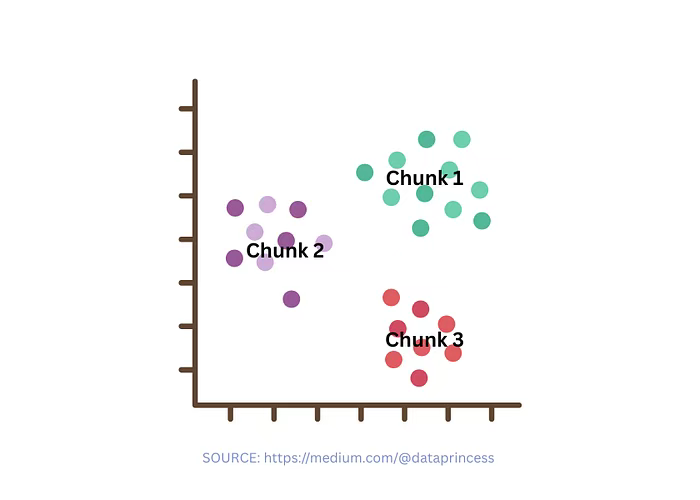
适用场景:
- 当文档涵盖多个主题,且需保持语义焦点时。
- 适用于主题转变较为平缓但未通过明确的标题或关键词标注的文本。
13)表格感知分块法 Table-aware chunking
独立识别表格内容,并按 JSON 或 Markdown 格式分块(可逐行 / 逐列 / 整表处理)。
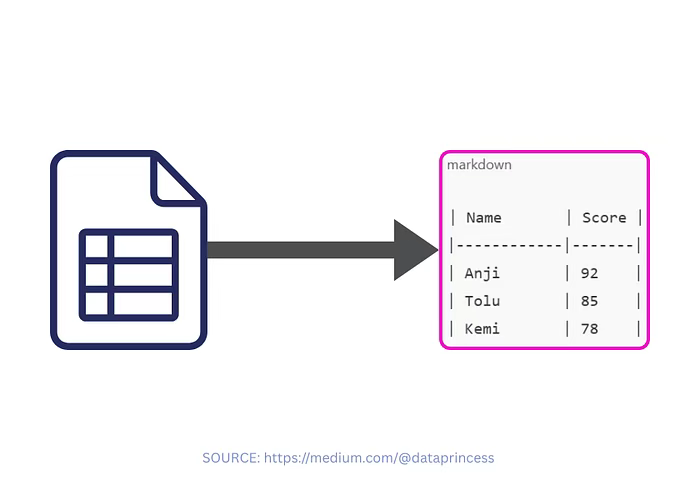
适用场景:
- 含表格元素的文档。
14)内容感知分块法 Content-aware chunking
根据内容类型动态调整分块策略(为段落 / 表格 / 列表等内容适配不同规则)。
适用场景:
- 混合格式的文档(含多种文本结构)。
- 需保持原生格式完整性的场景(表格不分割 / 段落不截断等)。
15)上下文增强分块法 Contextual chunking
通过 LLM 实现:
- 分析知识库的部分或全部内容。
- 在嵌入前为每个文本块注入简短且相关的上下文
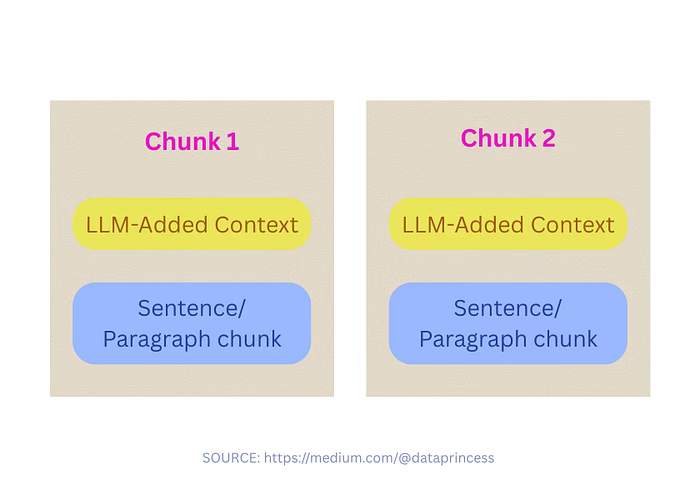
适用场景:
- 知识库的全部内容或部分内容在 LLM 的词元限额内。
- 处理复杂文档(如财报 / 合同等)。
16)语义分块法 Semantic chunking
基于嵌入相似度聚合主题相关的句子 / 段落,保持语义聚焦性。
适用场景:
- 当按段分块法或定长分块法失效时
- 处理含混杂主题的长文档。
17)递归分块法 Recursive chunking
首先使用大粒度的分隔符(如段落)分割文本。
如果任何生成的分块超过预设的分块大小限制,对这些区块递归使用小粒度分隔符(如句子或单词)进行分割,直至所有分块都符合所需大小。
适用场景:
- 处理句子长度不规则或不可预测的文本,如访谈记录、演讲内容、自由形式的写作内容。
18)嵌入优先分块法 Embedding chunking
常规流程是先分块后嵌入,但此方法先将所有句子全部嵌入,再按顺序逐一处理,若相邻句的相似度高于设定阈值则合并为一组,低于阈值则进行拆分。
适用场景:
- 无结构(无句子分隔 / 标题 / 章节符 / 标记等)的文档
- 当基础技术(如滑动窗口分块法)效果不佳时
19)基于大模型 / 智能体的分块法 Agentic / LLM-based chunking
将分块的决策权完全交由 LLM,由其自主决定文本的分割方式。
适用场景:
- 当内容复杂或结构不明确,需要类似人类的判断力来确定分块边界时
注意:该方法计算成本较高。
20)分层分块法 Hierarchical chunking
将文本按照多个层次(如章节、子章节、段落)进行分块,以便用户能够以不同详细程度检索信息。
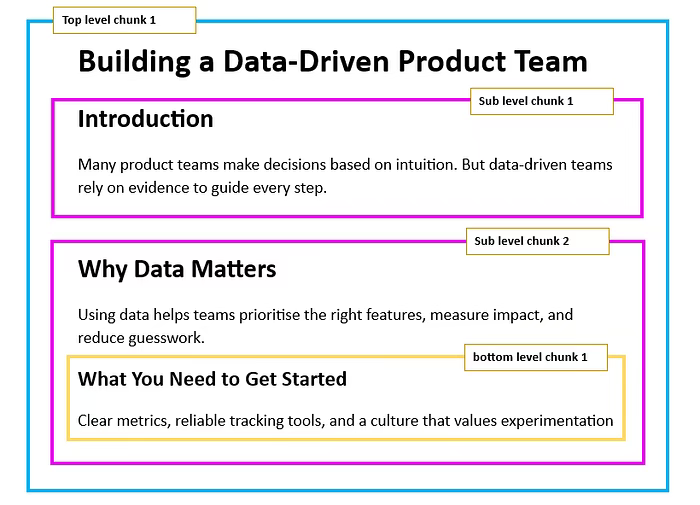
适用场景:
- 具备清晰层次结构的文档,如技术文章、手册、教材、研究论文等
- 希望用户在不丢失上下文的情况下,同时探索整体概述和详细信息。
21)多模态分块法 Modality-Aware Chunking
针对不同内容类型(文本、图像、表格)实施差异化的分块策略。
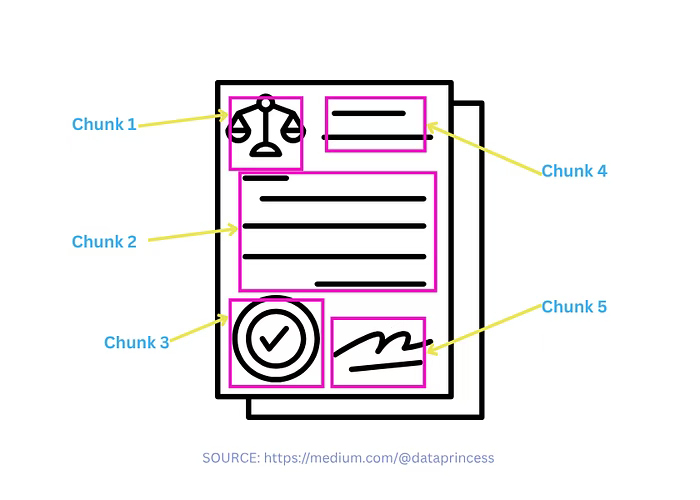
BONUS:混合分块法 Hybrid chunking
融合多种分块技术、启发式规则、嵌入模型以及 LLM 来提升分块过程的可靠性。
适用场景:
- 单一分块方法效果不足时,需组合方案应对复杂的数据结构。
总结
本文系统梳理了21种RAG系统数据分块策略,从基础换行符分割到高级混合分块法,全面满足不同数据类型和应用场景需求。核心策略包括:定长分块法适合处理杂乱文本,滑动窗口技术确保上下文连贯性,句/段分块法适用于结构化文档,语义分块则基于嵌入相似度进行内容聚合。其中,智能体分块虽然成本较高但能处理复杂内容,分层分块则特别适合技术文档等多层次结构的数据处理。混合分块法通过组合多种策略,可有效应对复杂数据结构。合理选择分块策略是提升RAG系统性能的核心要素。
END

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 12
12 0
0- 0



 已为社区贡献28条内容
已为社区贡献28条内容

所有评论(0)