构建AI智能体:二十三、RAG超越语义搜索:如何用Rerank模型实现检索精度的大幅提升
本文介绍了重排序(Rerank)技术在检索增强生成(RAG)系统中的应用。Rerank作为初始检索和最终生成之间的关键环节,通过交叉编码器对初步检索结果进行精细化排序,筛选出最相关的少量文档提供给大语言模型。相比Embedding模型,Rerank能更精准理解查询-文档的语义关系,显著提高答案质量,降低Token消耗。文章详细比较了BGE-Rerank和CohereRerank等主流模型,并通过代
一、发轫之始
在工作和生活中,我们可能经常会遇到一些场景,我们在搜索引擎中输入问题寻求解决方案,返回的却是大量重复的、基础性的、甚至是商业推广的内容。无奈的反复修正我们的检索内容,就是找不到答案,这确实是一大困扰,由于算法的局限性和商业干扰,导致搜索引擎算法倾向于流行度而非质量,商业利益常常凌驾于信息价值之上。我们得到的往往是最多人点击的,而不是最正确的。
如今随着AI的大爆发,我们也在设计AI产品,我们如何突破这种信息茧房,让我们设计的系统反馈的答案更加的精准化,首先我们已经了解到RAG的概念和优势,现在我们继续为RAG插上翅膀,集成结果的重排序Rerank模型,提升产品用户体验和系统信任度,增强搜索问题和结果之间的深层语义关系,从海量信息中精准筛选出最适合的内容,并以易于理解的方式呈现给用户。

二、 什么是Rerank模型
重排序(Rerank) 是在检索增强生成(RAG)系统中,对初步检索到的文档结果进行精细化重新排序的关键技术环节。它位于初始检索和最终生成之间,充当"质检员"和"精算师"的角色,对初步检索到的大量候选文档(例如100-1000个)进行重新评分和排序,将最相关、最准确的少量文档(例如5-10个)排在顶部,然后将其提供给LLM生成最终答案。确保传递给大语言模型(LLM)的上下文材料是最高质量的。主要用于优化初步检索结果的排序,提高最终输出的相关性或准确性。
可以通俗的将Rerank理解为一位专业的“质检员”或“决赛裁判”:
- 初始检索(如FAISS):像“海选”,快速从数百万选手中选出100位可能符合条件的。
- Rerank模型:像“专家评审”,仔细面试这100位选手,从中挑出最顶尖的5位。
- LLM:像“终极BOSS”,基于最顶尖的5位选手的信息,做出最终决策(生成答案)。
三、为什么需要Rerank
初始的向量检索器,如基于Embedding的FAISS,虽然速度快,但存在固有局限性:
- 语义相似度 ≠ 查询-文档相关性:Embedding模型学习的是广泛的语义相似性,但“相关”是一个更具体、更任务导向的概念。一个文档可能与查询在语义上很接近,但可能并未直接回答查询的问题。
- “词汇不匹配”问题:尽管比关键词搜索好,但Embedding模型有时仍然难以完美解决表述差异的问题。
- 精度与召回率的权衡:为了提高召回率(Recall),我们通常会初始检索大量文档(K值较大),但这其中必然包含许多不精确或冗余的文档,直接交给LLM会引入噪声,增加成本并可能导致错误回答。
Rerank模型通过执行更深入的“查询-文档”对交叉分析,专门针对“相关性”进行优化,完美解决了上述问题。
1. Rerank模型和Embedding模型比较
| 特性 | 嵌入(Embedding)模型 | 重排序(Rerank)模型 |
| 输入 | 单段文本 | (Query, Document) 对 |
| 输出 | 一个高维向量 | 一个相关性分数(标量) |
| 计算方式 | 对称或不对称语义搜索 | 交叉编码(Cross-Encoder),深度交互 |
| 速度 | 非常快,适合大规模初步检索 | 相对慢,适合对少量候选精排 |
| 精度 | 良好,但不够精确 | 非常高,是相关性判断的专家 |
| 典型用途 | 从海量数据中快速召回Top K个候选 | 对Top K个候选进行精细重排序 |
2. 核心工作原理:交叉编码
与生成嵌入向度的双编码器(Bi-Encoder) 不同,Rerank模型通常是交叉编码器(Cross-Encoder)。
- Bi-Encoder(双塔模型):查询和文档分别通过编码器(通常是同一个)独立地转换为向量,然后计算向量间的相似度(如余弦相似度)。优势是快,因为文档可以预先编码存储。
- Cross-Encoder(交叉编码):将查询和文档拼接在一起,作为一个完整的序列输入到模型中。模型(如BERT)的注意力机制(Attention)能够同时在查询和文档的所有词元之间进行深度的、精细的交互,从而直接输出一个相关性的分数。优势是精度极高,因为它能真正“理解”Query和Document之间的细微关系。
3. Rerank的优势
- 显著提升答案质量:提供给LLM的上下文质量更高,直接减少幻觉、提高答案准确性。
- 降低Token消耗:只需传递更少、更精炼的文档给LLM,节省了输入Token的成本。
- 增强系统鲁棒性:即使初始检索不够准确,Rerank也能在一定程度上纠正错误。
四、Rerank的流程节点和模型选择
1. Rerank在RAG流程中的位置
一个集成Rerank的完整RAG流程如下:
- 输入:用户查询(Query)。
- 初步检索(Recall):使用向量搜索引擎(如FAISS)从知识库中快速召回Top K个相关文档(K较大,例如100)。
- 重排序(Rerank):将用户查询和初步召回的每一个文档依次组成(Query, Document)对,输入到Rerank模型中获取相关性分数。
- 筛选与排序:根据Rerank分数对所有候选文档进行降序排序,并选取Top N个分数最高的文档(N较小,例如5)。
- 生成(Generation):将用户查询和精排后的Top N个文档一起构成提示(Prompt),输入给LLM生成最终答案。
- 输出:LLM生成的、基于最相关上下文的答案。
2. Rerank模型选择
BGE-Rerank和Cohere Rerank是两种广泛使用的重排序模型,它们在检索增强生成(RAG)系统、搜索引擎优化和问答系统中表现优异。
2.1 BGE-Rerank模型
- bge-reranker-base / bge-reranker-large:北京智源AI研究院开源的优秀中英双语Rerank模型,非常流行,后者在精度上更优。
- 基于Transformer的Cross-Encoder结构,直接计算查询(Query)与文档(Document)的交互相关性得分,可本地部署。
- BAAI/bge-reranker-v2-m3:智源最新的多语言、多功能重排序模型。
2.2 Cohere Rerank模型
- 由Cohere公司提供的商业API服务。
- 基于专有的深度学习模型,支持多语言(如rerank-multilingual-v3.0)。
- 训练数据:优化了语义匹配,特别适用于混合检索(如结合BM25和向量检索)后的结果优化。
- 使用方式:通过API调用,集成到LangChain、LlamaIndex等框架中。
- 简单易用,适合快速集成到现有系统,在英文和多语言任务中表现优异。
更大的模型(Large)通常精度更高,但推理速度更慢。需要在精度和速度之间做出权衡。
五、集成Rerank完整流程图
1. 完整流程图
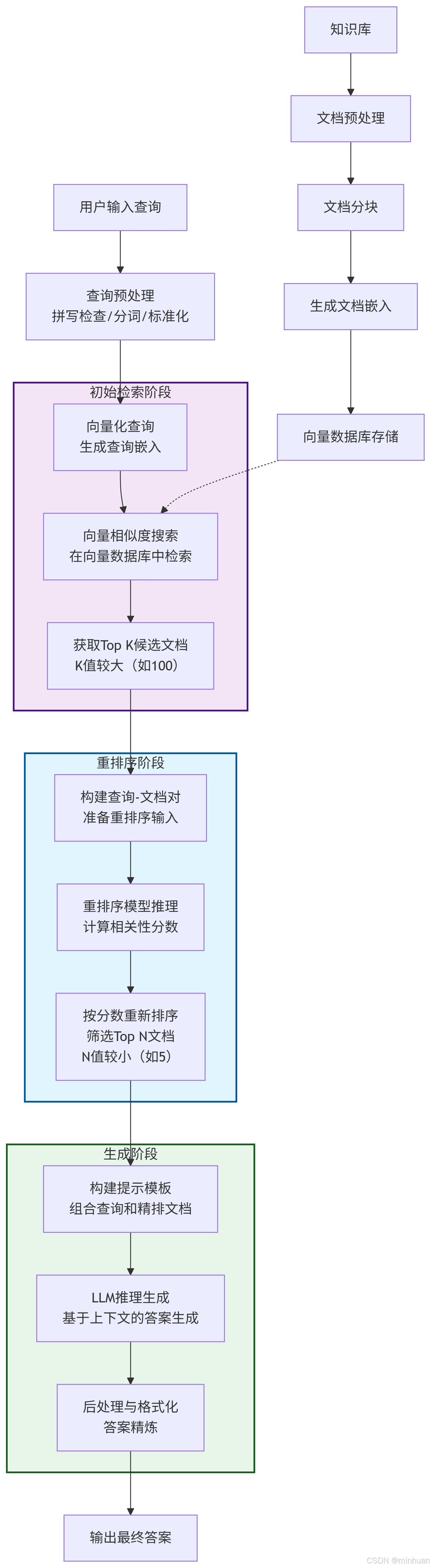
流程介绍
1. 初始检索阶段
- 用户输入查询:接收用户的自然语言问题
- 查询预处理:对查询进行清洗、标准化和分词处理
- 向量化查询:使用嵌入模型将查询转换为向量表示
- 向量相似度搜索:在向量数据库中进行近似最近邻搜索
- 获取Top K候选文档:返回相似度最高的K个文档(K值较大,确保召回率)
2. 重排序阶段 - 核心环节
- 构建查询-文档对:将查询与每个候选文档组合成(Query, Document)对
- 重排序模型推理:使用交叉编码器模型对每个对进行深度相关性分析
- 按分数重新排序:根据模型输出的相关性分数对文档降序排列
- 筛选Top N文档:选择分数最高的N个文档(N值较小,确保精确率)
3. 生成阶段
- 构建提示模板:将精排后的文档与查询组合成LLM可理解的提示
- LLM推理生成:大语言模型基于提供的上下文生成答案
- 后处理与格式化:对生成的答案进行精炼、格式化和验证
4. 知识库预处理流程
- 文档预处理:清洗和标准化原始文档
- 文档分块:将长文档分割成适当大小的块
- 生成文档嵌入:为每个文档块生成向量表示
- 向量数据库存储:将文档向量存入向量数据库以备检索
2. Rerank流程图
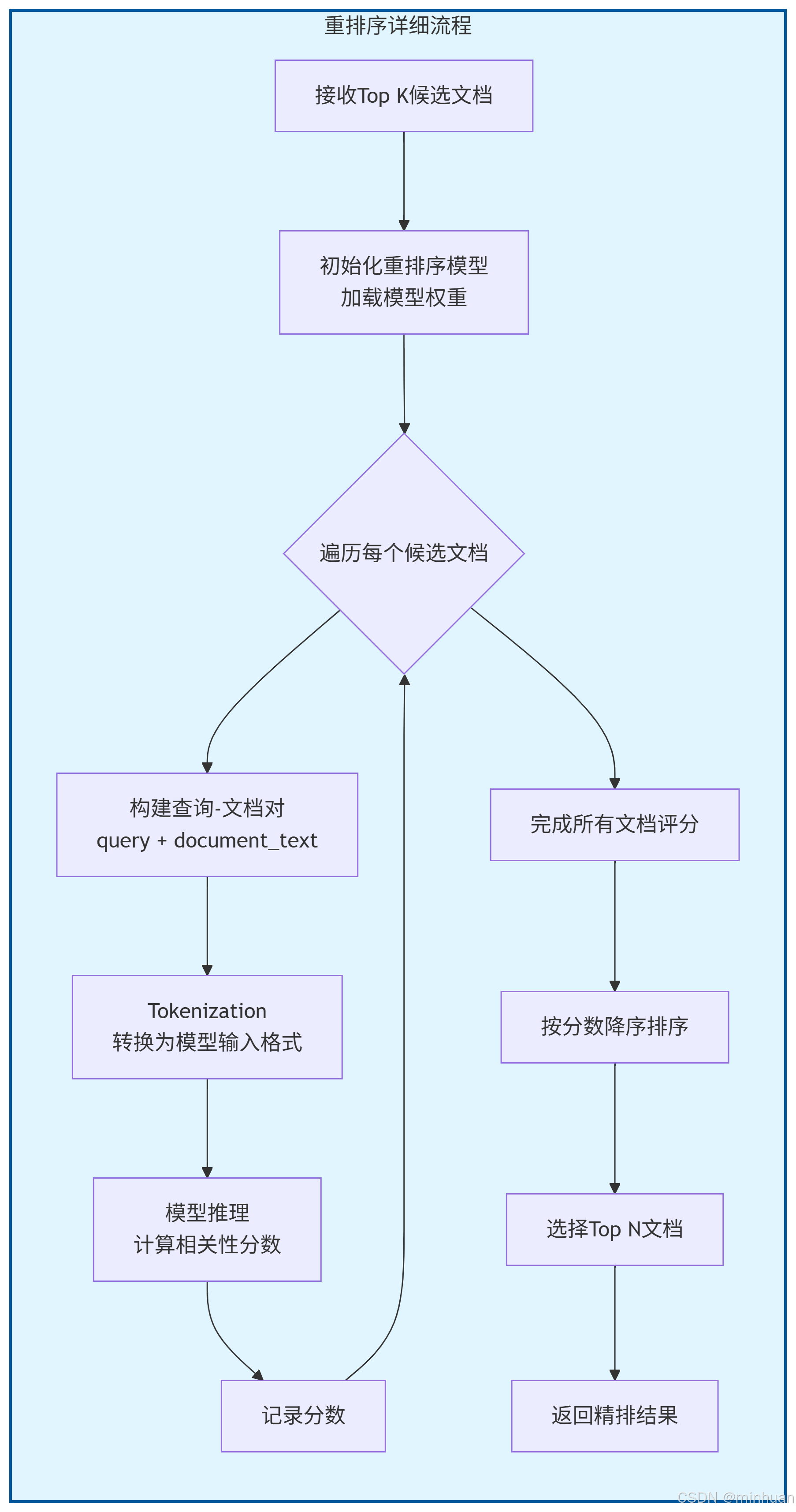
各阶段输入输出示例
1. 初始检索阶段
输入: "如何学习钢琴?"
输出:
1. 钢琴保养指南 (相似度: 0.82)
2. 音乐理论基础 (相似度: 0.79)
3. 钢琴购买指南 (相似度: 0.77)
4. 钢琴入门指法教程 (相似度: 0.75)
5. 十大钢琴家介绍 (相似度: 0.72)
... (共100个文档)
2. 重排序阶段
输入: 初始检索的100个文档 + 查询"如何学习钢琴?"
处理: 使用BGE-Reranker计算每个文档与查询的相关性分数
输出:
1. 钢琴入门指法教程 (相关性: 0.95)
2. 钢琴练习曲目推荐 (相关性: 0.92)
3. 音乐理论基础 (相关性: 0.88)
4. 钢琴学习计划制定 (相关性: 0.85)
5. 钢琴师资选择指南 (相关性: 0.82)
3. 生成阶段
输入: 精排后的5个文档 + 查询"如何学习钢琴?"
输出:
学习钢琴应该从基础开始,首先掌握正确的坐姿和手型,然后学习基本的指法。
推荐从《拜厄钢琴基本教程》开始,每天坚持练习30-60分钟。
同时建议学习基础乐理知识,如音符、节奏和和弦等。
最好找一位有经验的老师指导,可以帮助纠正错误姿势和提供个性化建议。
六、Rerank的使用场景
推荐使用场景:
- 高精度要求:医疗、法律、金融等专业领域
- 复杂查询:多概念、抽象或模糊的查询
- 关键任务:答案准确性至关重要的应用
- 文档质量不均:知识库中包含大量相似或冗余文档
可忽略场景:
- 简单事实查询:"中国的首都"、"浙江的省会"
- 实时性要求极高:需要毫秒级响应的场景
- 计算资源有限:无法承担额外推理成本
七、演示示例
-
示例1:苹果公司创始人推测
1. 基础代码
使用 bge-reranker模型在基于FAISS的RAG流程中集成Rerank模型。
from langchain_community.vectorstores import FAISS
from langchain.embeddings import HuggingFaceEmbeddings
from langchain.schema import Document
from transformers import AutoModelForSequenceClassification, AutoTokenizer
import torch
import numpy as np
# 1. 准备示例知识库和初始检索
# 初始化一个嵌入模型用于初始检索
embedding_model = HuggingFaceEmbeddings(
model_name="sentence-transformers/paraphrase-multilingual-MiniLM-L12-v2"
)
# 假设的文档库
documents = [
"苹果公司于1976年由史蒂夫·乔布斯、史蒂夫·沃兹尼亚克和罗纳德·韦恩创立,最初主要生产和销售个人电脑。",
"苹果公司最著名的产品是iPhone智能手机,它彻底改变了移动通信行业。",
"水果苹果是一种蔷薇科苹果属的落叶乔木果实,营养价值高,富含维生素和纤维。",
"苹果公司在2023年发布了其首款混合现实头显设备Apple Vision Pro。",
"吃苹果有助于促进消化和增强免疫力,是一种健康零食。",
"蒂姆·库克是苹果公司的现任首席执行官,于2011年接替史蒂夫·乔布斯。"
]
# 转换为LangChain Document对象
docs = [Document(page_content=text) for text in documents]
# 构建FAISS向量库
vectorstore = FAISS.from_documents(docs, embedding_model)
# 用户查询
query = "苹果公司的创始人是谁?"
# 初始检索:使用向量库召回Top K个文档(这里K=4)
initial_retrieved_docs = vectorstore.similarity_search(query, k=4)
print("=== 初始检索结果(基于语义相似度)===")
for i, doc in enumerate(initial_retrieved_docs):
print(f"{i+1}. [相似度得分: N/A] {doc.page_content}")
# 2. 初始化Rerank模型
# 我们使用 `BAAI/bge-reranker-base`,这是一个强大的中英双语Reranker
model_name = "BAAI/bge-reranker-base"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForSequenceClassification.from_pretrained(model_name)
model.eval() # 设置为评估模式
# 3. 重排序函数
def rerank_docs(query, retrieved_docs, model, tokenizer, top_n=3):
"""
对检索到的文档进行重排序
Args:
query: 用户查询
retrieved_docs: 检索到的文档列表
model: 重排序模型
tokenizer: 重排序模型的tokenizer
top_n: 返回顶部多少个文档
Returns:
sorted_docs: 按相关性分数降序排列的文档列表
scores: 对应的分数列表
"""
# 构建(query, doc)对
pairs = [(query, doc.page_content) for doc in retrieved_docs]
# Tokenize所有文本对
with torch.no_grad(): # 禁用梯度计算,加快推理速度
inputs = tokenizer(
pairs,
padding=True,
truncation=True,
return_tensors='pt',
max_length=512
)
# 模型前向传播,计算分数
scores = model(**inputs).logits.squeeze(dim=-1).float().numpy()
# 将分数和文档打包在一起
doc_score_list = list(zip(retrieved_docs, scores))
# 按分数降序排序
doc_score_list.sort(key=lambda x: x[1], reverse=True)
# 解包,返回Top N个文档和它们的分数
sorted_docs = [doc for doc, score in doc_score_list[:top_n]]
sorted_scores = [score for doc, score in doc_score_list[:top_n]]
return sorted_docs, sorted_scores
# 4. 执行重排序
reranked_docs, reranked_scores = rerank_docs(query, initial_retrieved_docs, model, tokenizer, top_n=3)
# 5. 打印结果
print("\n=== 重排序后结果(基于交叉编码相关性)===")
for i, (doc, score) in enumerate(zip(reranked_docs, reranked_scores)):
print(f"{i+1}. [相关性分数: {score:.4f}] {doc.page_content}")
# 6. 将精排后的上下文传递给LLM(这里用打印模拟)
context_for_llm = "\n".join([doc.page_content for doc in reranked_docs])
prompt = f"""
基于以下上下文,请回答问题。
上下文:
{context_for_llm}
=== 最终输出最优的匹配结果 ===
问题:{query}
答案:{reranked_docs[0].page_content}
"""
print(f"\n=== 最终提供给LLM的Prompt ===")
print(prompt)2. 执行结果
=== 初始检索结果(基于语义相似度)===
1. [相似度得分: N/A] 苹果公司于1976年由史蒂夫·乔布斯、史蒂夫·沃兹尼亚克和罗纳德·韦恩创立,最初主要生产和销售个人电脑
。
2. [相似度得分: N/A] 蒂姆·库克是苹果公司的现任首席执行官,于2011年接替史蒂夫·乔布斯。
3. [相似度得分: N/A] 苹果公司在2023年发布了其首款混合现实头显设备Apple Vision Pro。
4. [相似度得分: N/A] 水果苹果是一种蔷薇科苹果属的落叶乔木果实,营养价值高,富含维生素和纤维。
=== 重排序后结果(基于交叉编码相关性)===
1. [相关性分数: 9.3700] 苹果公司于1976年由史蒂夫·乔布斯、史蒂夫·沃兹尼亚克和罗纳德·韦恩创立,最初主要生产和销售个人电
脑。
2. [相关性分数: 4.5305] 蒂姆·库克是苹果公司的现任首席执行官,于2011年接替史蒂夫·乔布斯。
3. [相关性分数: -6.0679] 苹果公司在2023年发布了其首款混合现实头显设备Apple Vision Pro。
=== 最终提供给LLM的Prompt ===
基于以下上下文,请回答问题。
上下文:
苹果公司于1976年由史蒂夫·乔布斯、史蒂夫·沃兹尼亚克和罗纳德·韦恩创立,最初主要生产和销售个人电脑。
蒂姆·库克是苹果公司的现任首席执行官,于2011年接替史蒂夫·乔布斯。
苹果公司在2023年发布了其首款混合现实头显设备Apple Vision Pro。
=== 最终输出最优的匹配结果 ===
问题:苹果公司的创始人是谁?
答案:苹果公司于1976年由史蒂夫·乔布斯、史蒂夫·沃兹尼亚克和罗纳德·韦恩创立,最初主要生产和销售个人电脑。3. 代码详解
1. 初始设置:
- 使用sentence-transformers的嵌入模型和FAISS构建一个简单的向量检索库。
- 定义了一个有歧义的查询“苹果公司的创始人是谁?”。注意,知识库中既包含科技公司“苹果”,也包含水果“苹果”。
2. 初始检索:
- vectorstore.similarity_search(query, k=4) 召回了4个最“语义相似”的文档。
- 由于Embedding模型的理解是广义语义的,水果“苹果”的文档也可能被召回(例如,文档3和5)。
3. 初始化Rerank模型:
- 使用transformers库加载预训练的BAAI/bge-reranker-base模型和其对应的分词器。
- model.eval()将模型设置为评估模式,这会关闭Dropout等训练层,保证输出的一致性。
4. 重排序函数 rerank_docs:
- 构建对:将查询和每一个检索到的文档内容组成(Query, Document)对。
- Tokenize:使用tokenizer将所有这些文本对处理成模型可接受的输入格式(input_ids, attention_mask等)。padding=True和truncation=True确保了不同长度的文本对可以被批量处理。
- 模型推理:将处理好的输入传递给模型。with torch.no_grad()块确保不计算梯度,大幅减少内存消耗并加快推理速度。模型的输出是一个分数,分数越高代表相关性越强。
- 排序与筛选:根据模型计算出的相关性分数对文档进行降序排序,并返回Top N个文档。
5. 结果分析:
- 初始检索结果:可能包含水果苹果的文档,因为它们也包含“苹果”这个词,语义上有相似性。
- 重排序后结果:Rerank模型作为“相关性专家”,能够精确理解“苹果公司”这个特定实体的查询意图。它会给科技公司苹果的文档打出非常高的分数,而给水果苹果的文档打出很低的分数。最终,Top结果中只会留下最相关的科技公司苹果的文档。
4. 模型引用
示例中使用了两个模型sentence-transformers/paraphrase-multilingual-MiniLM-L12-v2和BAAI/bge-reranker-base,都可以本地化部署,前者是一个嵌入模型用于初始检索,它将句子和段落映射到384维的密集向量空间中,可用于聚类或语义搜索等任务;后者前文介绍过,是专门做Rerank的模型,它直接计算查询(Query)与文档(Document)的交互相关性得分,也可本地部署。
在代码运行时,模型检测到本地没有,会自动从线上下载:

下载完成的模型目录:
模型下载完成后,再次运行时会直接从本地读取!
从示例输出可以清晰看到,重排序后,直接包含答案“创始人”的文档排到了第一,并且所有排名靠前的文档都是关于科技公司的,水果相关的文档被有效地过滤掉了。这样提供给LLM的上下文质量极高,能保证生成答案的准确性。
通过这个流程,Rerank模型极大地提升了RAG系统的最终表现,是其从可用到好用的关键升级。
-
示例2:如何学习钢琴
1. 基础代码
import torch
from transformers import AutoModelForSequenceClassification, AutoTokenizer
class BGEReranker:
def __init__(self, model_name="BAAI/bge-reranker-base"):
self.tokenizer = AutoTokenizer.from_pretrained(model_name)
self.model = AutoModelForSequenceClassification.from_pretrained(model_name)
self.model.eval() # 设置为评估模式
def rerank(self, query: str, documents: list, top_k: int = 5):
"""
对文档进行重排序
:param query: 用户查询
:param documents: 候选文档列表
:param top_k: 返回前K个文档
:return: 排序后的文档和分数
"""
# 构建查询-文档对
pairs = [(query, doc) for doc in documents]
# 特征编码
with torch.no_grad():
inputs = self.tokenizer(
pairs,
padding=True,
truncation=True,
return_tensors='pt',
max_length=512
)
# 计算相关性分数
scores = self.model(**inputs).logits.squeeze(dim=-1).float().numpy()
# 组合文档和分数
scored_docs = list(zip(documents, scores))
# 按分数降序排序
scored_docs.sort(key=lambda x: x[1], reverse=True)
return scored_docs[:top_k]
# 使用示例
if __name__ == "__main__":
# 初始化重排序模型
reranker = BGEReranker()
# 用户查询
query = "如何学习钢琴?"
# 初始检索结果(假设从FAISS获取)
initial_docs = [
"钢琴保养和清洁方法",
"音乐理论基础入门",
"钢琴购买指南:如何选择第一台钢琴",
"钢琴入门指法教程:从零开始学习",
"十大著名钢琴家及其作品",
"钢琴练习曲目推荐:适合初学者"
]
print("初始检索结果:")
for i, doc in enumerate(initial_docs):
print(f"{i+1}. {doc}")
# 应用重排序
reranked_docs = reranker.rerank(query, initial_docs, top_k=3)
print("\n重排序后结果:")
for i, (doc, score) in enumerate(reranked_docs):
print(f"{i+1}. [分数: {score:.4f}] {doc}")
print("\n最优的匹配结果:")
print(reranked_docs[0][0])2. 执行结果
初始检索结果:
1. 钢琴保养和清洁方法
2. 音乐理论基础入门
3. 钢琴购买指南:如何选择第一台钢琴
4. 钢琴入门指法教程:从零开始学习
5. 十大著名钢琴家及其作品
6. 钢琴练习曲目推荐:适合初学者
重排序后结果:
1. [分数: 1.7239] 钢琴入门指法教程:从零开始学习
2. [分数: 0.7639] 音乐理论基础入门
3. [分数: -1.1614] 钢琴练习曲目推荐:适合初学者
最优的匹配结果:
钢琴入门指法教程:从零开始学习八、总结
重排序(Rerank)是RAG系统中提升精度的关键技术,它能够深度理解查询和文档间的语义关系、精细排序初步检索结果筛选最相关文档、显著提升最终生成答案的质量和准确性。
虽然引入了一定的计算开销,但在大多数重视准确性的应用场景中,重排序带来的性能提升远远超过了其成本,是现代RAG系统不可或缺的组件。
对于精度要求极高的场景(如医疗、法律),强烈推荐使用Rerank。对于延迟敏感或资源有限的场景,可以酌情省略或减少重排序的文档数量(K)。选择合适的重排序策略和模型,能够让RAG系统从能用升级到好用,真正发挥检索增强生成的全部潜力。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 26
26 0
0- 0



 已为社区贡献17条内容
已为社区贡献17条内容

所有评论(0)