程序员必看:Context Engineering——大模型时代的软件开发新范式(值得收藏)
本文探讨了Context Engineering在大模型开发中的重要性,将其比作LLM操作系统的用户程序开发工程。与早期预测不同,Prompt Engineering不仅未弱化,反而发展为更全面的Context Engineering,包括构建和管理上下文窗口的科学与艺术。文章分析了Context不当处理导致的问题,详细介绍了其内容类型和处理分类,并提出了面向LLM的工程方法论。Context E
几年前,当 Prompt Engineering 概念被提出来的时候,有个流行的观点:Prompt Engineering 不会存在很长时间,会随着 LLM 能力强大逐渐弱化。类比于搜索引擎刚出来的时候,有很多复杂的搜索技巧,比如使用星号作为通配符,其他特殊符号还包括加号、波浪号,甚至一些关键字 link、define 等。后来随着技术升级,用户无需了解这些技巧,搜索引擎也能找到最相关内容。
但 Prompt Engineering 的发展目前看,并没有这种被“弱化”的趋势。反而重要性越来越强,非常多论文围绕如何构建 Prompt 展开研究。最近 Prompt Engineering 的 plus 版本 —— Context Engineering 在业内被广泛讨论。
前几天,中科院、北大清华等高校联合发布了一篇关于 Context Engineering 综述:A Survey of Context Engineering for Large Language Models。该综述调研了 1400 多篇论文,对 Context Engineering 进行了系统性介绍。
什么是 Context Engineering ?为什么 Context Engineering 越来越被业界重视?为什么说 Context Engineering 是 LLM OS 时代的软件工程?本文围绕这几个问题展开讨论。
一、什么是 Context Engineering ?
Context Engineering 并没有一个权威的定义。在 A Survey of Context Engineering for Large Language Models论文中,也没有明确的定义。引用 Andrej Karpathy一篇推文描述:
When in every industrial-strength LLM app, context engineering is the delicate art and science of filling the context window with just the right information for the next step.
在简化理解:“filling the context window with just the right information”,也就是在调用 LLM 前构建 context window 的过程。
Context Engineering 与 Prompt Engineering 相比有何区别?Context Engineering 包括了 Prompt Engineering ,Prompt Engineering 是 Context Engineering 的一部分。之前的提示词工程,很多关注点在“问得巧”,而 Context Engineering 也强调要在有限的上下文窗口内 “装得全”“装得对”。
Context Engineering 除了 Prompt Engineering 还包括什么?可以使用一张图说明:
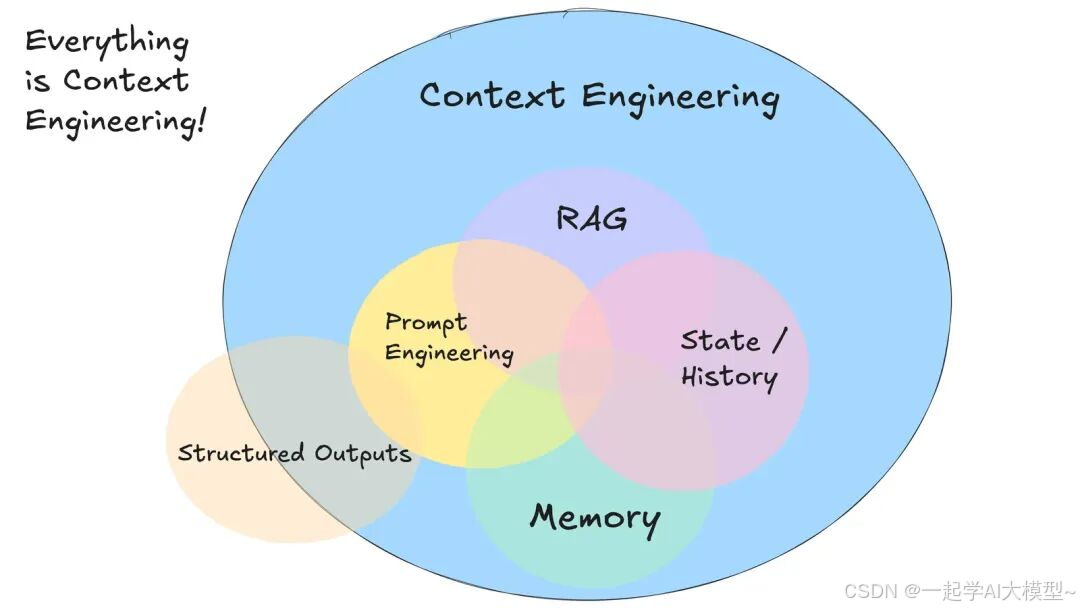
上面这张图,能清晰表明概念区别,但并不十分严谨。比如 RAG (Retrieval-Augmented Generation)更像是一类“技术实现”。尤其 RAG 后面的 G,一般理解为 LLM 的生成,并不完全属于 Context Engineering 的范围。而图中的 Memory 与 State/History 更偏重于 Context Engineering 中 Context 的构成,维度有些差异。
在 A Survey of Context Engineering for Large Language Models论文中,有区分 Context Engineering 的“基础组建”与“系统实现”,RAG 被归为后者。而把 RAG 中 R“Retrieval” 的数据与 State、History、Memory 等归为“基础组建”,从概念划分更为合理。
上图中的内容,也并不完备。在第三部分 Context Engineering 分类中,会在对 Context Engineering 都有哪些类型展开讨论,此处不在展开。
Context Engineering 的概念貌似只比 Prompt Engineering 扩大了一点,为何业内越来越关注 Context Engineering ?下一章节尝试回答此问题。

二、LLM OS 视角的 Context Engineering
“Context engineering” … is effectively the #1 job of engineers building AI agents.
–cognition.ai A Theory of Building Long-running Agents
如果把 LLM 看作一个操作系统,对比 LLM 与操作系统架构,可以有以下对应关系。
Kernel (内核) 对应 LLM 的核心模型:也就是Transformer 架构及其参数权重。
System Calls (系统调用) 对应 LLM 的 API/接口 与 工具调用能力:LLM 的预测/推理接口和函数调用(Function Calling)机制,这里的 Function Calling 目前也有了相对标准的协议 MCP。与一般的直接调用 API 不同,这里工具调用能力,类似于一种抽象的 SPI 能力。
Shell (命令行解释器) 对应 LLM 交互前端与用户界面 (UI/CLI):典型的为 ChatGPT,此外一些库提供同样的命令行工具,可以直接与模型通过 text 交互,比如Llama.cpp 命令行工具。
Library Routines (库函数) 对应 LLM 中间件:比如Prompt 模板引擎、向量数据库工具(RAG)、微调框架。模板引擎( LangChain、LlamaIndex )、微调工具(Hugging Face Transformers, PEFT/LoRA)、等。
Applications (应用程序) 对应基于 LLM 构建的 Agent 应用:如Cursor、GitHub Copilot。LLM 之上可以有不同的 LLM app,不同的 LLM app 也可以替换依赖的 LLM。比如 Cursor 可以使用 GPT o3 也可以使用 DeepSeek。就像当前的 VS code 可以运行在 Mac 上也可以运行在 Windows 上。
除了上文提到的对应关系外,仍可发现其他对应,比如 LLM 应用中经常使用的 embedding 技术,可以对应于操作系统的 File system 的索引技术。
如果把 LLM 看为操作系统 Context Engineering 相当于什么 ?Context Engineering 是 LLM 操作系统的“用户程序开发工程”,它不改动内核,但通过精心设计输入、调用资源和构造上下文,实现模型行为的“编程”。Andrej Karpathy 在分享中,把软件工程划分为三个阶段,第一个阶段为传统的软件工程,第二个阶段为训练模型权重的为主阶段,第三个阶段为通过编程对神经网络进行控制的阶段(programmable neural net)。而 Context Engineering 可以理解为 Software 3.0 阶段的软件工程。
在 LLM OS 架构图中,操作系统中 RAM 为 context window,context window 也是 Context Engineering 主要的编程对象。Context Engineering 通过多轮上下文组织、思维链、RAG 查询控制等手段,构造上下文,决定“模型看到什么”(RAM/Context window),从而影响其行为。
Context Engineering 通过精心设计 prompt、引入外部知识(RAG、函数、工具调用)、控制 token 预算与上下文长度等,就像是写 高质量 Shell 脚本 或 用户态控制程序,在不改动模型内核的前提下,最大化利用其能力。
Context Engineering 是 LLM 操作系统的“用户程序开发工程”,它不改动内核,但通过精心设计输入、调用资源和构造上下文,实现模型行为的“编程”。
传统的软件开发(Software 1.0),使用操作系统提供的系统调用,层层封装,实现用户需求。并且需要考虑成本、性能、复用性、扩展性等等。Software 3.0,基于 LLM 这个操作系统的软件开发,需要使用 LLM 提供的系统调用(只有一个主要推理接口),实现用户需求,并且需要考虑成本、性能、复用性、扩展性。对于开发者而言,这个系统调用,甚至主要参数也只有一个,一个超长的 String。那程序员的主要工作,变成了:如何构造这个 String 来满足用户需求,并且要考虑成本、性能、复用性、扩展性。
招聘软件开发人员时,往往面试的不限于软件开发的语言,有相当一部分的内容为操作系统原理。记得很早之前,自己的一次面试,自己回答的不好的一个问题 “Linux 的内核中都有什么 ?”。软件开发中,熟悉操作系统的原理,开发的软件时,才能了解软件是运行在一个什么样的世界,有哪些规则限制。
同样,在 Software 3.0,对于3.0的软件开发工程师,了解 LLM OS 的原理同样重要。一个典型的例子,前一阵 manus 分享文章:Context Engineering for AI Agents: Lessons from Building Manus中,第一点为“Design Around the KV-Cache”。大概意思是尽可能保持 context window 的前面内容稳定,前缀内容一致,能够利用的 KV cache 越多。原理上有些类似于 hbase 的 rowkey 设计或者关系数据库的最左前缀匹配规则。只这一点设计能够节省 10 倍的资源开销:“And we’re not talking about small savings: with Claude Sonnet, for instance, cached input tokens cost 0.30 USD/MTok, while uncached ones cost 3 USD/MTok—a 10x difference.”
本质上看,LLM 与传统的小模型一样,是一个无状态的函数。要想得到这个函数最好的输出,需要给到最好的输入。影响 LLM 这个函数结果的参数,主要参数只有一个,即是 Context Engineering 要构建的内容。但这内容构建并非易事,如果构建不当,会导致各种问题。什么是“最好”的输入?要了解“好”是什么,可以通过芒格提倡的逆向思维方式,看下“不好”是什么,不好的 context 会导致的问题。
三、Context 处理不当导致的问题
How Long Contexts Fail文章中,指出了四点对 context 处理不当会导致的问题。
Context Poisoning: When a hallucination makes it into the context
Context Distraction: When the context overwhelms the training
Context Confusion: When superfluous context influences the response
Context Clash: When parts of the context disagree
Context Poisoning(上下文中毒):这里的 Poisoning,与 LLM 在训练时候,语料中的 Poisoning 一个意思,指那些错误的信息语料。对于 context 而言,还有另外一个严重的问题:这种 Poisoning 会累积。因为上一轮的 context 信息会传递到下一轮的 context,Context Poisoning 也会有这样的传递。这样每一轮引入的 Context Poisoning 会慢慢积累。如果context 中关键的信息部分被影响或破坏,那么会导致 LLM 的推理计算失败。
Context Distraction(上下文干扰):上下文干扰是指当上下文变得过长时,模型会过度关注上下文,而忽略了其在训练过程中所学到的内容。心理学上,也有类似的研究,相同的一个问题,如果问题描述的冗余复杂,加入无关信息,即使信息是完备的,但会比简单明确的描述正确率差很多。在 LLM 中,越是小参数量的模型,这种注意力被分散,自身能力发挥受限的现象越明显。
Context Confusion(上下文混淆):上下文混淆是指模型利用上下文中多余的内容生成低质量回复的情况。与上下文干扰差异,上下文干扰是过于关注上下文中的信息,不能发挥 training 阶段学习的能力。而上下文混淆是错误的使用了上下文中的信息,使用的是training 阶段学习到的能力。典型的问题是,一个 Agent 中提供了过多可以利用的 tools,LLM 最终选择了错误的 tools 使用。
Context Confusion(上下文冲突):上下文冲突是指在上下文中积累的新信息和工具与该上下文中的其他信息相冲突。之前看到一个观点,特斯拉采用纯视觉端到端的方案,而不是雷达 + 视觉混合端到端的方案?主要原因之一是雷达成本高,另外一个原因是越多的信息源,越可能导致上下文冲突,而解决这种冲突的对大模型的要求非常高,很多场景无法满足准确性要求。
以上是 Context 处理不当会导致的问题,更详细内容可以阅读原文,原文中有相关的 paper 链接,可对此问题有更深入了解。
对于 Context Engineering 的重要性,在 A Survey of Context Engineering for Large Language Models论文中,3.2 节 Why Context Engineering 中有更多讨论。通过优化 prompt、多种 RAG 的优化、COT 的优化,可以提升 LLM 的最终性能。
以上讨论了什么是 Context Engineering 与 Context Engineering 的重要性,Context Engineering 具体都有什么?下一章节对此问题展开讨论。
四、Context Engineering 分类
与 Context Engineering 的定义一样,Context Engineering 的分类目前没有一个统一的共识。A Survey of Context Engineering for Large Language Models论文中的范围非常广泛,包括了 Transform 架构内对 Context 的优化。
但个人更加倾向于“狭义”的,不涉及对Transform 架构变更的定义。如果从工程视角,或者前文的 LLM OS 视角, Transform 架构为操作系统的内核,Context Engineering 对应于“用户程序开发工程”,不应改变内核。从文章开始提到的定义——“filling the context window with just the right information”,也未改变内核。
以下讨论,也是这样“狭义”的 Context Engineering 范围。
具体都有包括哪些内容?参考 Context Engineering Guide中内容,包括但不限于:
- Designing and managing prompt chains (when applicable)
- Tuning instructions/system prompts
- Managing dynamic elements of the prompt (e.g., user inputs, date/time, etc.)
- Searching and preparing relevant knowledge (i.e., RAG)
- Query augmentation
- Tool definitions and instructions (in the case of agentic systems)
- Preparing and optimizing few-shot demonstrations
- Structuring inputs and outputs (e.g., delimiters, JSON schema)
- Short-term memory (i.e., managing state/historical context) and long-term memory (e.g., retrieving relevant knowledge from a vector store)
- And the many other tricks that are useful to optimize the LLM system prompt to achieve the desired tasks.
上述内容,更侧重于静态的,或者说最终的 context window 构成。下面先通 context types 的维度,进行分类。
4.1. Context 的内容类型
参考 Context Engineering for Agents文章的分类,可简单划分为三类:Instructions、Knowledge、Tools:
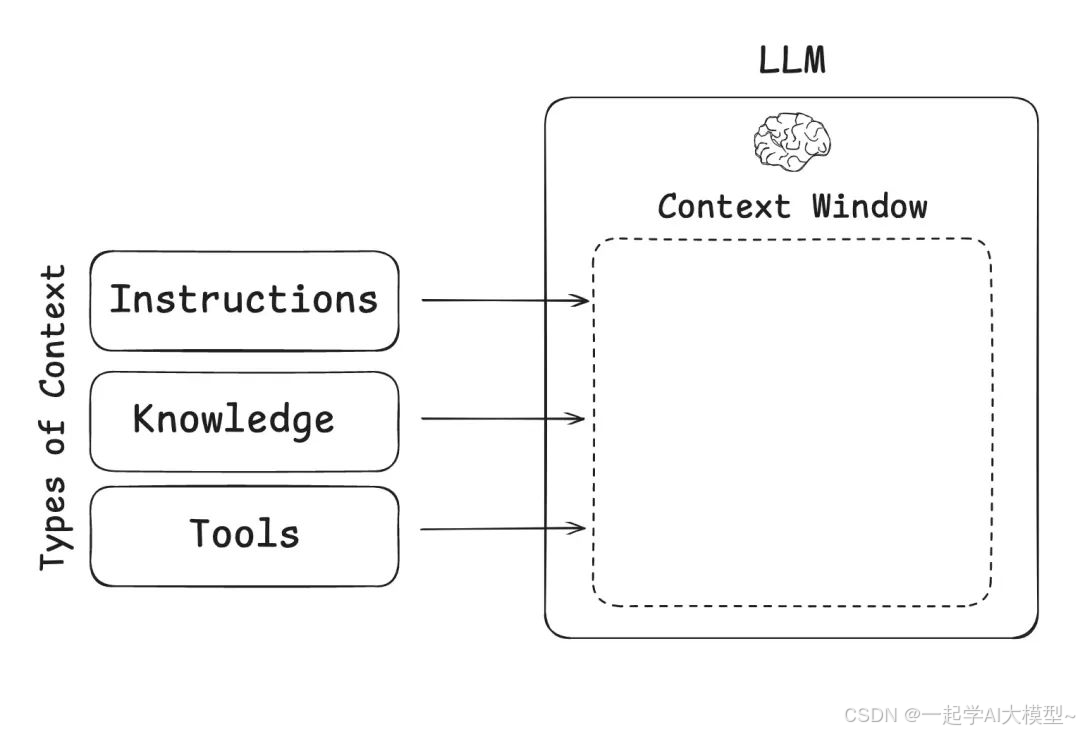
Instructions 指令包括:提示词、记忆、少样本示例、工具描述等。
Tools 工具:注意,这里是来自工具调用的反馈,而不是工具的描述,工具的描述属于 Instructions 部分。
Knowledge 知识:包括事实、记忆等。
其中,需要特别关注的是 Memory 部分,也是 Context Engineering 处理中的需要关注的地方。LLM 可以看作一个无状态的函数,这里“无状态”也是在说明 LLM 本身并没有记忆。
按照 LangGraph Memory分类,可以分为 Short-term memory与 Long-term memory,其中 Long-term memory又分为: semantic memory、 episodic memory、procedural memory。
短期记忆使应用程序能够记住单个线程或会话中的先前交互,也就是常说的历史对话。使用 LLM 提供的推理 API,最基础的参数之一,就是“历史对话”,也就是这里的短期记忆。
长期记忆,使系统能够在不同的对话或会话中保留信息,不与特定会话绑定的。例如目前的 ChatGPT 应用可以对记忆进行配置,这里的记忆均为长期记忆。
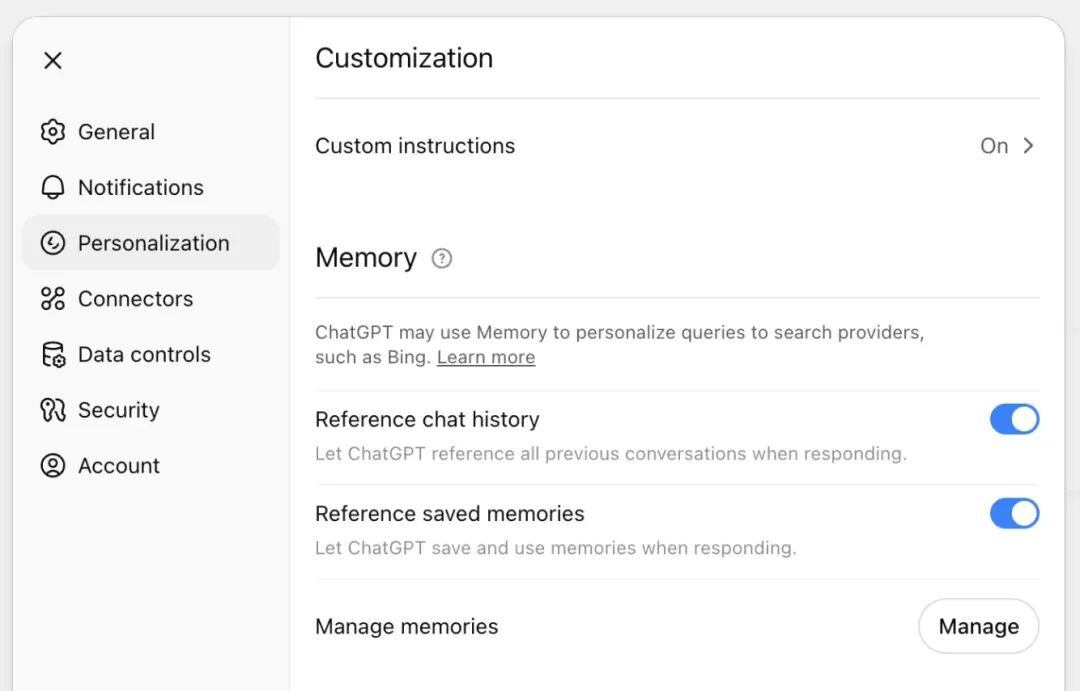
https://help.openai.com/en/articles/8590148-memory-faq
长期记忆的分类说明,如下表格。直接引用 LangGraph Memory中原文表格:

Semantic memory:语义记忆,无论是在人类还是人工智能智能体中,都涉及对特定事实和概念的保留。在人类中,它可以包括在学校学到的信息以及对概念及其关系的理解。对于人工智能智能体而言,语义记忆通常用于通过记住过去交互中的事实或概念来实现应用程序的个性化。
上述 ChatGPT 截图中 Reference saved memories功能 :“These are details you have explicitly asked ChatGPT to remember, like your name, favorite color, or dietary preferences.”,即为一种 Semantic memory(Facts)。
Episodic memory:情景记忆,在人类和人工智能智能体中,都涉及回忆过去的事件或行动。CoALA论文对此阐述:事实可以写入语义记忆,而经历则可以写入情景记忆。对于人工智能智能体而言,情景记忆通常用于帮助智能体记住如何完成一项任务。
ChatGPT 的 Reference chat history 即为 Episodic memory,对此配置功能描述:“ChatGPT can also use information from your past chats to make future conversations more helpful. For example, if you once said you like Thai food, it may take that into account the next time you ask “What should I have for lunch?” ChatGPT doesn’t remember every detail from past chats, so use saved memories for anything you want it to always keep in mind.”
Procedural memory:程序性记忆,无论是在人类还是人工智能智能体中,都涉及记住执行任务所使用的规则。在人类中,程序性记忆就像是执行任务的内在知识(方法论),例如通过基本的运动技能和平衡来骑自行车。另一方面,情景记忆涉及回忆特定的经历,比如你第一次成功地骑上没有辅助轮的自行车,或者一次难忘的骑行之旅。对于人工智能智能体来说,程序性记忆是模型权重、智能体代码和智能体提示的组合,这些共同决定了智能体的功能。
在实践中,智能体修改其模型权重或重写代码的情况相当少见。然而,智能体修改自身提示词的情况更为常见。比如在执行一个具体的任务中,LLM 开始会自动生成一个任务的 prompt 中,在任务执行结束后,用户会对 prompt 的结果进行反馈,比如“结果不超过100字”,那么在下一次执行这个任务时候,可以把这个用户对任务的要求更新到任务的 prompt 中。
人类大脑是“推训练一体”的,没有单独的“训练”阶段,都是在实践中,一边实践、一边收到反馈,一边修改大脑中的“神经元权重”。目前应用 LLM 还未见到,在运行中根据反馈来对 LLM 进行参数调整。
以上是对 Context 的内容类型一个大致分类,对 Memory 部分进行了主要讨论。Context 由什么构成,并非 Context Engineering 的难点,如何保存、生成各种类型的长期记忆,从这么多 Context 具体获取哪些 Context 给到 LLM 才是 Context Engineering 的难点。下一小节对 Context 的处理与管理的过程,进行分类讨论。
4.2. Context 的处理与管理的分类
对于 Context Engineering 处理与管理过程分类,在 A Survey of Context Engineering for Large Language Models中的 Foundational Components 部分分为:4.1. Context Retrieval and Generation、4.2. Context Processing、4.3. Context Management 三个部分。这个分类方式,后面两类 Processing、Management 有些抽象,很难表示类别的特征。本文参考 Context Engineering for Agents文章的分类,对 Context 的相关处理过程进行讨论。
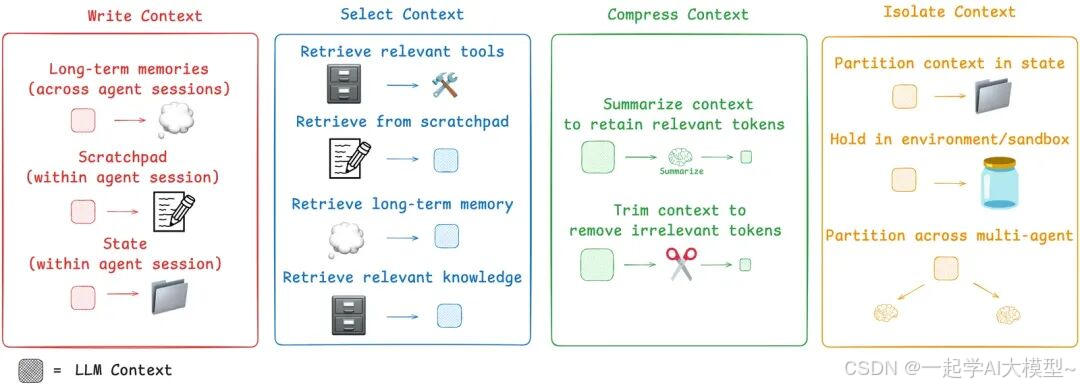
4.2.1. Write Context
Writing context means saving it outside the context window to help an agent perform a task.
Scratchpads 为上一小节提到的短期记忆。State 本质也是短期记忆,是当前会话的状态,比如执行特定任务的状态。
这里的 Long-term memoris 相对复杂很多。上一小节中提到 ChatGPT 的 Reference saved memories、Reference chat history 功能都属于此部分。
ChatGPT 的 Reference saved memories 功能:
Saved memories是你直接告诉 ChatGPT 要记住的详细信息。你可以随时新增记忆,例如:“在推荐食谱时记得我是素食者。”
已保存的记忆和自定义指令类似,但不同的是,我们的模型会自动更新这些记忆,而不需要用户手动管理。
如果你在对话中分享了可能对未来有用的信息,ChatGPT 可能会在无需你特别要求的情况下将这些信息保存为记忆。和自定义指令一样,已保存的记忆是 ChatGPT 用来生成回答的一部分上下文。除非你删除它们,否则这些记忆在未来的回答中都会被考虑进去。
在比如 langgraph 实现 Semantic memories 能力的一种方式:使用 LLM 生成新的 user 的 profile:
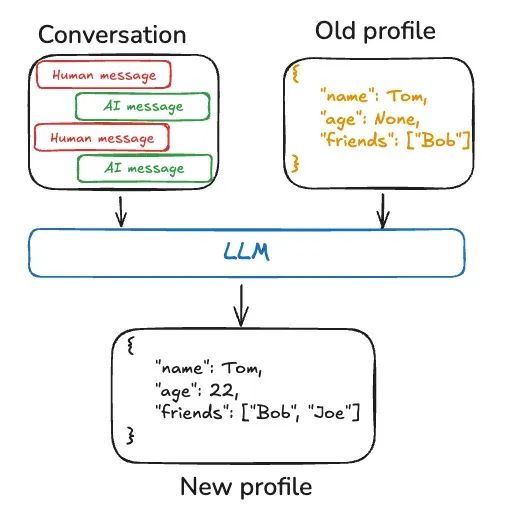
以上为 Writing context 中长期记忆的处理过程的例子。个人理解,这里的 Long-term memoris,并不只来源于 agent sessions,一些用户的基本信息,比如 KYC 时用户填入的信息,或者通过离线数据刻画的用户画像信息,都属于 Long-term memoris。对应的这些过程,本质也都属于 Writing context 的部分。
Context Engineering for AI Agents: Lessons from Building Manus文中,有一条最佳实践关于 Writing context :使用外部文件保存完整的上下文,不要丢失信息。
Use the File System as Context:智能体本质上必须基于所有先前状态预测下一个行动,而你无法可靠地预测哪一项观察结果会在十步之后变得至关重要。从逻辑角度来看,任何不可逆的压缩都存在风险。这就是为什么我们在Manus中将文件系统视为终极上下文:大小不受限制,本质上具有持久性,并且智能体本身可以直接操作。该模型学会根据需要对文件进行写入和读取——不仅将文件系统用作存储,还将其作为结构化的外部化内存。
4.2.2. Select Context
Select Context 是从已知的 Tools、外部知识库,短期、长期记忆挑选相关信息的过程。RAG 中的 R — Retrieval,是一个典型的 Select 过程。
这一环节非常重要,获取的 Context 不能太多,也不能缺失相关的必要信息。RAG 中的 Retrieval 过程非常多的策略,从语料分片(按照语句、段落、语义、固定长度)、到语料召回(embedding、关键字、GraphRAG)已有不少研究探索。
Context Engineering for AI Agents: Lessons from Building Manus文中,有一条最佳实践关于 Select context —— Keep the Wrong Stuff In:根据我们的经验,改善智能体行为的最有效方法之一看似简单:将错误的选择保留在上下文中。当模型看到一个失败的操作,以及由此产生的观察结果或堆栈跟踪时,它会隐含地更新其内部认知。这会使其先验认知偏离类似的操作,从而降低重复同样错误的可能性。
4.2.3. Compressing Context
智能体交互可能会历经数百个回合,并使用消耗大量令牌的工具调用。摘要生成是一种常见解决方法。一些 LLM 服务,会提供类似的能力。超过上下文窗口的95% 时,Claude Code会运行 “自动压缩”,它将总结用户与智能体交互的完整轨迹。这种跨智能体轨迹的压缩可以采用各种策略,如递归或分层摘要生成。
这种“压缩”最好是应用层自主控制,哪些信息重要,哪些信息不重要,只有最了解业务的应用开发者最清楚。
压缩上下文,是信息有损的,在使用时需要特别关注。Context Engineering for AI Agents: Lessons from Building Manus文中。
Use the File System as Context:智能体本质上必须基于所有先前状态预测下一个行动,而你无法可靠地预测哪一项观察结果会在十步之后变得至关重要。从逻辑角度来看,任何不可逆的压缩都存在风险。这就是为什么我们在Manus中将文件系统视为终极上下文:大小不受限制,本质上具有持久性,并且智能体本身可以直接操作。该模型学会根据需要对文件进行写入和读取——不仅将文件系统用作存储,还将其作为结构化的外部化内存。
Manipulate Attention Through Recitation:在Manus中,一个典型的任务平均需要大约50次工具调用。这是一个很长的循环,而且由于Manus依赖大语言模型(LLMs)进行决策,它很容易偏离主题或忘记早期目标,尤其是在长上下文或复杂任务中。通过不断重写待办事项列表,Manus 将其目标复述到上下文的末尾。这将全局计划推到模型最近的注意力范围内,避免了“中间迷失”问题,并减少了目标不一致的情况。实际上,它是在使用自然语言将自身的关注点偏向任务目标,而无需对架构进行特殊更改。
4.2.4. Context Isolation
最常见的隔离上下文的场景是将其分配给多个子智能体。OpenAI 的 Swarm库的一个设计动机是“关注点分离”,即由一组智能体来处理子任务。每个智能体都有一套特定的工具、指令以及自己的上下文窗口。
此外,即使非多智能体的场景,一个智能体对于 LLM 不同任务时所暴露的状态也应是隔离的。
上下文隔离,本质上是对 LLM 进行信息隐藏和上下文封装的策略,它与软件工程中的信息隐藏原则和最小知识原则非常相似:只暴露最少必要的信息,以保持系统的模块性、稳定性和可控性。
4.2.5. 小结
以上为 Context Engineering 处理过程分类,但并非全部,比如上文提到的 Context Engineering for AI Agents: Lessons from Building Manus文中,面向 KVCache 缓存优化的技术,也属于 Context Engineering。其他最佳实践,根据原文整理如下(绝大部分为原文直接翻译):
Design Around the KV-Cache:具有相同前缀的上下文可以利用键值缓存(KV-cache),降低了首个令牌生成时间(TTFT)和推理成本。
Mask, Don’t Remove:1. 在大多数大语言模型中,工具定义在序列化后位于上下文的前部附近,通常在系统提示之前或之后。因此,任何更改都会使所有后续操作和观察的键值缓存失效。2. 当之前的行动和观察结果仍然指向当前上下文中不再定义的工具时,模型就会感到困惑。如果没有约束解码,这通常会导致违反模式或产生幻觉行动。
Don’t Get Few-Shotted(第三章中 Context Confusion 类型):语言模型是出色的模仿者;它们会模仿上下文中的行为模式。如果你的上下文充满了类似的过往行动 - 观察对,模型就会倾向于遵循这种模式,即使它不再是最优的。解决办法是增加多样性。Manus在行动和观察中引入少量有组织的变化——不同的序列化模板、不同的措辞、顺序或格式上的细微干扰。这种可控的随机性有助于打破模式,并调整模型的注意力。
以上,为 Context Engineering 处理与管理过程的大概分类。分类并不一定全面准确,但对于认识 Context Engineering 能够思路更清晰。
五、如何面向 LLM Context 开展 Engineering?
如果上文提到的两个观点成立:
1)Software 将进入 3.0,对神经网络进行编程。
2) LLM 是 Software 3.0 开发的操作系统。
由于软件开发的对象变化,从传统的 Linux 操作系统变为 LLM,那么新的软件开发一些方法论也会有对应的改变。
Software 1.0 的软件工程中,开发面对的对象主要有两个:一是开发人员,二是操作系统。对象为开发人员,主要是因为需求一直在演进,需要长期进行维护,变更、新增需求。另外一个对象为操作系统,因为开发出代码是运行在操作系统上,需要考虑性能,在高并发的时候需要考虑扩展性。
LLM 应用的开发,开发面对的对象从传统的操作系统变为 LLM。这会导致多个层面的变化。
1)传统操作系统执行的为高级编程语言编译后的指令,开发时候需要遵循高级开发语言的语法规则。而 LLM 操作系统计算时为自然语言映射后的 token。虽然构造 context window 内容的代码还是 Software 1.0 的代码,但本质上运行时的性能,运行的耗时根本是决定于 context window 内容,而与构建 context window 的代码没有直接关系。
2)底层运行原理不一致,导致性能优化的方法论不一致。典型的为上文提到的 manus 优化推理性能的例子,需要考虑 LLM 运行时 KVCache 的数据结构、多张显卡推理时 IO 的消耗,而不是传统操作系统考虑的磁盘 IO优化、CPU多级缓存等机制。
3)面向 LLM OS 开发时,需要面向 LLM,使用 LLM 友好的“数据结构”。非常典型的是目前的 MCP 协议,不仅仅是标准化了 LLM 调用工具的协议,更大的意义是定义了一种对 LLM 友好,LLM 容易理解的协议。如果设计出的 MCP 的接口只是格式符合,但 LLM 无法理解,就背离了协议的初衷。
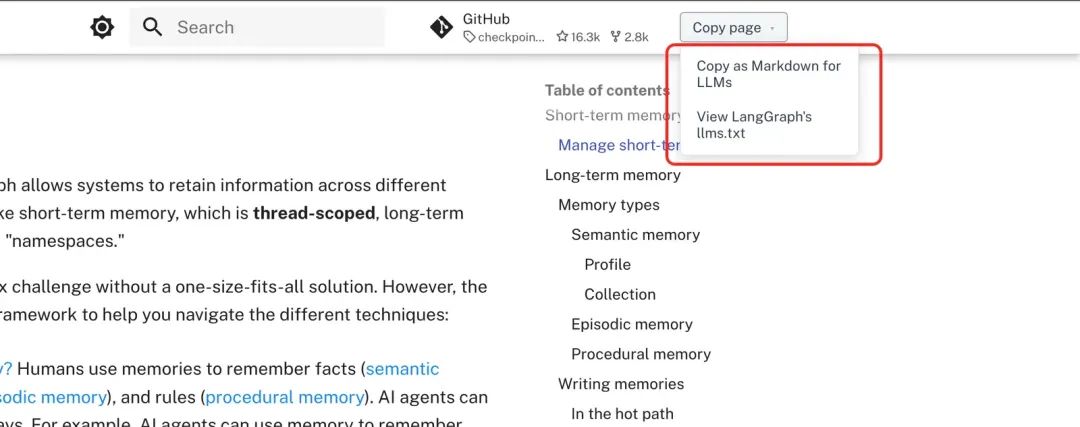
在 RAG 中,如果秉承“面向 LLM”开发,那么文档的格式需要为 LLM 容易理解的格式,比如为 markdown 格式。一些网站的设计,已经开始“面向 LLM”设计,比如上文提到的关于 Memory 分类的网页: LangGraph Memory中,右上角有有单独的两个文件,“Copy as Markdown for LLMs”就是直接copy 出当前网页的 markdown格式,更适合 LLM 理解。“llm.txt” 类似于整个网站页面为 LLM 设计的导航,里面为markdown格式的各个页面的说明与地址。
开发 LLM Agent时,不仅需要考虑在生成的 context window 最终运行的 LLM 操作系统中的性能,也需要考虑是否需要被其他 LLM Agent 集成。LLM Agent 会辅助用户完成大量的工作,而回去访问之前用户直接访问的信息,比如购物网站。那么这个时候,购物网站就像上面的网站一样,既需要对用户友好,也能够被其他 LLM Agent 方便集成。
“面向 LLM”开发,是一种关注点的彻底改变。在开发人员的视角,LLM 不仅是执行未来 LLM Agent 的操作系统,也是消费 LLM Agent 信息的一类“用户”。
如何做好 Context Engineering 目前并没有权威的方法论。目前 LLM OS 的发展阶段类比于操作系统的发展,可能还处于计算机刚诞生的 60 年代。随着 LLM 发展,Context Engineering 也会不断演化。最后以 12 factor agents中经常提到的一句话结尾:
I don’t know what’s the best way to hand context to an LLM, but I know you want the flexibility to be able to try EVERYTHING.
以上,感谢阅读。
普通人如何抓住AI大模型的风口?
领取方式在文末
为什么要学习大模型?
目前AI大模型的技术岗位与能力培养随着人工智能技术的迅速发展和应用 , 大模型作为其中的重要组成部分 , 正逐渐成为推动人工智能发展的重要引擎 。大模型以其强大的数据处理和模式识别能力, 广泛应用于自然语言处理 、计算机视觉 、 智能推荐等领域 ,为各行各业带来了革命性的改变和机遇 。
目前,开源人工智能大模型已应用于医疗、政务、法律、汽车、娱乐、金融、互联网、教育、制造业、企业服务等多个场景,其中,应用于金融、企业服务、制造业和法律领域的大模型在本次调研中占比超过 30%。
随着AI大模型技术的迅速发展,相关岗位的需求也日益增加。大模型产业链催生了一批高薪新职业:
人工智能大潮已来,不加入就可能被淘汰。如果你是技术人,尤其是互联网从业者,现在就开始学习AI大模型技术,真的是给你的人生一个重要建议!
最后
只要你真心想学习AI大模型技术,这份精心整理的学习资料我愿意无偿分享给你,但是想学技术去乱搞的人别来找我!
在当前这个人工智能高速发展的时代,AI大模型正在深刻改变各行各业。我国对高水平AI人才的需求也日益增长,真正懂技术、能落地的人才依旧紧缺。我也希望通过这份资料,能够帮助更多有志于AI领域的朋友入门并深入学习。
真诚无偿分享!!!
vx扫描下方二维码即可
加上后会一个个给大家发
大模型全套学习资料展示
自我们与MoPaaS魔泊云合作以来,我们不断打磨课程体系与技术内容,在细节上精益求精,同时在技术层面也新增了许多前沿且实用的内容,力求为大家带来更系统、更实战、更落地的大模型学习体验。

希望这份系统、实用的大模型学习路径,能够帮助你从零入门,进阶到实战,真正掌握AI时代的核心技能!
01 教学内容

-
从零到精通完整闭环:【基础理论 →RAG开发 → Agent设计 → 模型微调与私有化部署调→热门技术】5大模块,内容比传统教材更贴近企业实战!
-
大量真实项目案例: 带你亲自上手搞数据清洗、模型调优这些硬核操作,把课本知识变成真本事!
02适学人群
应届毕业生: 无工作经验但想要系统学习AI大模型技术,期待通过实战项目掌握核心技术。
零基础转型: 非技术背景但关注AI应用场景,计划通过低代码工具实现“AI+行业”跨界。
业务赋能突破瓶颈: 传统开发者(Java/前端等)学习Transformer架构与LangChain框架,向AI全栈工程师转型。

vx扫描下方二维码即可
本教程比较珍贵,仅限大家自行学习,不要传播!更严禁商用!
03 入门到进阶学习路线图
大模型学习路线图,整体分为5个大的阶段:
04 视频和书籍PDF合集

从0到掌握主流大模型技术视频教程(涵盖模型训练、微调、RAG、LangChain、Agent开发等实战方向)

新手必备的大模型学习PDF书单来了!全是硬核知识,帮你少走弯路(不吹牛,真有用)
05 行业报告+白皮书合集
收集70+报告与白皮书,了解行业最新动态!
06 90+份面试题/经验
AI大模型岗位面试经验总结(谁学技术不是为了赚$呢,找个好的岗位很重要)

07 deepseek部署包+技巧大全

由于篇幅有限
只展示部分资料
并且还在持续更新中…
真诚无偿分享!!!
vx扫描下方二维码即可
加上后会一个个给大家发

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 16
16 0
0- 0



 已为社区贡献133条内容
已为社区贡献133条内容

所有评论(0)