【Agent】LongCat-Flash Technical Report
提出了两个部分的改进。1)引入零计算专家,输出等于输入,和其他专家在同一层级中。用于在简单token生成时候减少参数计算的开销。每次激活K个专家,难的token激活的非零专家会更多,计算参数会更多,简单的会激活的零专家会增多,计算参数减少。通过快捷连接MoE架构克服共享专家架构与单个专家计算的通信重叠。实验发现,引入快捷连接后性能与不引入相比几乎没有多少损失。在预训练方面,介绍了Tokenizer
·
论文:https://arxiv.org/abs/2509.01322
代码:https://github.com/meituan-longcat/LongCat-Flash-Chat
架构方面
提出了两个部分的改进。1)引入零计算专家,输出等于输入,和其他专家在同一层级中。用于在简单token生成时候减少参数计算的开销。每次激活K个专家,难的token激活的非零专家会更多,计算参数会更多,简单的会激活的零专家会增多,计算参数减少。2)引入快捷连接。通过快捷连接MoE架构克服共享专家架构与单个专家计算的通信重叠。实验发现,引入快捷连接后性能与不引入相比几乎没有多少损失。在预训练方面,介绍了Tokenizer、训练稳定性、预训练数据过滤、长文能力增强等。
后训练方面
- 推理能力:数学、代码逻辑能力
- 工具调用能力:排除特定领域知识情况,将任务难度归为三个因素:
- 信息复杂度:模型必须参与复杂的推理过程,将信息集成并转换为所需的组件。
- 工具集复杂度:将工具集建模为基于工具间依赖关系的有向图,复杂性可以通过图的节点基数和边缘密度来定量表征。
- 用户交互复杂度:模型必须学会以最小的频率进行多轮战略提问,适应不同的会话风格、沟通意愿水平和信息披露模式,从而在确保充分信息获取的同时促进有效的用户交互。
构建了一个多智能体数据合成框架
- 用户配置Agent:除了生成包含个人信息和偏好的基本用户配置文件之外,还进一步实现了对用户会话风格、沟通意愿水平和信息披露模式的控制,以更准确地模拟真实的用户交互场景,同时提高任务复杂性。
- 工具集Agent:为了最大限度地提高数据多样性并防止过度拟合到特定场景,采用了类似于Kimi-K2的方法,枚举40个不同的领域,随后利用模型枚举1600个应用程序。基于这些应用,构建了80,000个模拟工具,形成了一个广泛的工具图。通过随机漫步方法,系统地从该综合工具图中抽取具有预定节点数量的子图,从而通过节点数量控制工具图的复杂度。
- 指令Agent:推理的难度量化为以下几个维度:约束复杂性、推理点的数量和推理链的长度。该模型需要基于工具集Agent提取的工具集生成全面描述完整任务的指令。
- 环境Agent:根据用户配置Agent和指令Agent生成的内容增强环境信息,包括项目细节、位置细节、时间参数和气象条件。此外,我们还引入了物品和地点的混淆元素,以进一步增加推理的复杂性。
- 规则Agent:根据各种与任务相关的信息构建了一系列全面的具体清单。在最后的评估中,考虑到代理任务固有的长上下文特征,我们采用滑动窗口方法来评估整个轨迹,不断更新清单项目的完成状态。
- 校验Agent和去重Agent:从多个角度检查最终任务的质量,并删除任何过于相似的内容。这个过程确保了我们有多样化和高质量的任务。
构建数量适当的冷启动训练集,揭示了多样化的模式,并保持了较高的探索能力。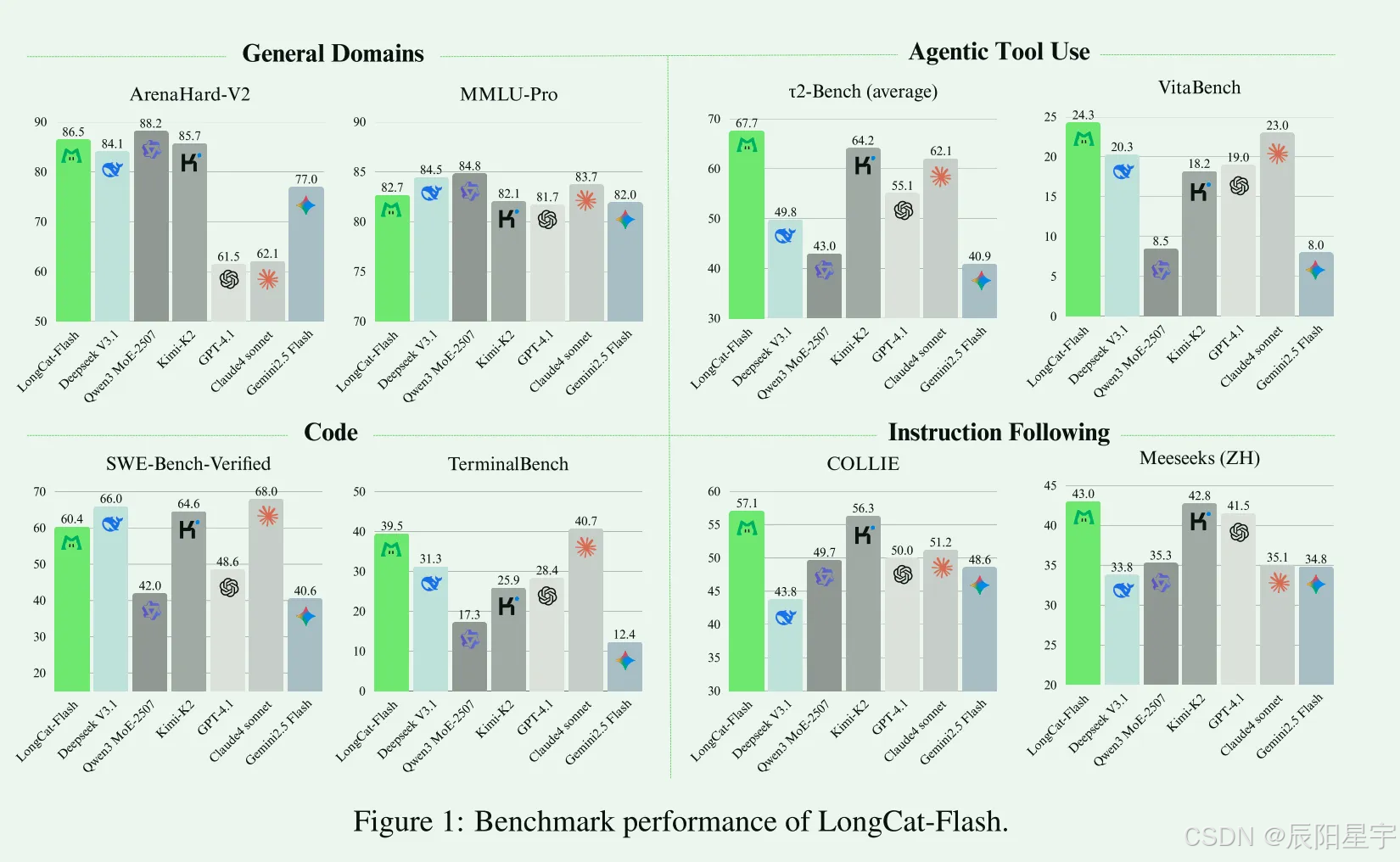

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 4
4 0
0- 0



 已为社区贡献19条内容
已为社区贡献19条内容

所有评论(0)