一起学LangGraph构建agent专题---预构建的代理(三)大模型入门到精通,收藏这篇就足够了!
下面开始第二部分-预构建的代理;下面演示完整的示例代码及输出的结果;详细的概念定义可以参考每小节对应的官方描述
下面开始第二部分-预构建的代理;下面演示完整的示例代码及输出的结果;详细的概念定义可以参考每小节对应的官方描述,本文在这里就不在详细描述了;
官方文档:https://langchain-ai.github.io/langgraph/agents/overview/
本文介绍 预构建的代理 的0-3个小结的,完整代码已经上传到github上;文末自取;
0概述
1运行代理
2流
3模型
0概述
参考文档:
https://langchain-ai.github.io/langgraph/agents/overview/
#使用 LangGraph 进行代理开发
LangGraph 提供低级原语和高级预构建组件,用于构建基于代理的应用程序。本节重点介绍预构建的可重用组件,这些组件旨在帮助您快速可靠地构建代理系统,而无需从头开始实施编排、内存或人工反馈处理。
#本章节介绍与构建的代理的组件:
#主要特点: LangGraph 包含构建健壮的、生产就绪的代理系统所必需的几项功能:
内存集成:对短期 (基于会话) 和长期 (跨会话持久) 内存的原生支持,从而在聊天机器人和助手中实现有状态行为。 人机协同控制:执行可以无限期暂停以等待人工反馈,这与仅限于实时交互的基于 websocket 的解决方案不同。这样可以在工作流中的任何时间点进行异步审批、更正或干预。 流式处理支持:代理状态、模型令牌、工具输出或组合流的实时流式处理。 部署工具:包括无需基础设施的部署工具。LangGraph Platform 支持测试、调试和部署。 Studio:用于检查和调试工作流的可视化 IDE。 支持多种生产部署选项。
from langgraph.prebuilt import create_react_agent
from langchain_openai import ChatOpenAI
from pydantic import BaseModel
import os
from langchain.chat_models import init_chat_model
API_KEY = "sk-123"
BASE_URL = "https://api.deepseek.com"
os.environ["OPENAI_API_KEY"] = API_KEY
os.environ["OPENAI_API_BASE"] = BASE_URL
llm = init_chat_model("openai:deepseek-chat")
deftool() -> None:
"""Testing tool."""
print("tool")
classResponseFormat(BaseModel):
"""Response format for the agent."""
result: str
agent = create_react_agent(
llm,
tools=[tool],
response_format=ResponseFormat,
)
from IPython.display import Image, display
try:
display(Image(agent.get_graph().draw_mermaid_png()))
except Exception:
# This requires some extra dependencies and is optional
pass
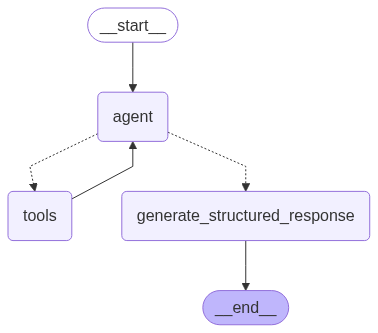
1运行代理
参考文档: https://langchain-ai.github.io/langgraph/agents/run_agents/
运行代理¶ 代理支持同步和异步执行,使用 / 表示完整响应,或使用 / 表示增量流输出。本节介绍如何提供输入、解释输出、启用流式处理和控制执行限制。.invoke()await .ainvoke().stream().astream()
# 创建llm
import os
from langchain.chat_models import init_chat_model
API_KEY = "sk-123"
BASE_URL = "https://api.deepseek.com"
os.environ["OPENAI_API_KEY"] = API_KEY
os.environ["OPENAI_API_BASE"] = BASE_URL
llm = init_chat_model("openai:deepseek-chat")
# 同步调用
from langgraph.prebuilt import create_react_agent
agent = create_react_agent(model=llm,tools=[])
response = agent.invoke({"messages": [{"role": "user", "content": "你是谁"}]})
print(response)
# 同步流式处理
for chunk in agent.stream(
{"messages": [{"role": "user", "content": "你是谁"}]},
stream_mode="updates"
):
print(chunk)
{'messages': [HumanMessage(content='你是谁', additional_kwargs={}, response_metadata={}, id='79e83afe-7e87-477d-9148-9da2a4e3dae5'), AIMessage(content='我是DeepSeek Chat,由深度求索公司(DeepSeek)开发的智能AI助手!🤖✨ 我的使命是帮助你解答各种问题,无论是学习、工作,还是日常生活中的小困惑,我都会尽力提供准确、有用的信息。 \n\n你可以问我任何问题,比如: \n- **知识科普** 📚:比如“黑洞是怎么形成的?” \n- **实用建议** 💡:比如“如何提高学习效率?” \n- **创意灵感** 🎨:比如“帮我写一首关于夏天的诗。” \n- **技术支持** 💻:比如“Python代码报错怎么解决?” \n\n目前我是**免费的**,也没有隐藏收费,随时欢迎来聊!😊 你今天有什么想问的呢?', additional_kwargs={'refusal': None}, response_metadata={'token_usage': {'completion_tokens': 151, 'prompt_tokens': 4, 'total_tokens': 155, 'completion_tokens_details': None, 'prompt_tokens_details': {'audio_tokens': None, 'cached_tokens': 0}, 'prompt_cache_hit_tokens': 0, 'prompt_cache_miss_tokens': 4}, 'model_name': 'deepseek-chat', 'system_fingerprint': 'fp_8802369eaa_prod0425fp8', 'id': 'b7823cc0-4802-4cb8-9261-3597e4501c2c', 'service_tier': None, 'finish_reason': 'stop', 'logprobs': None}, id='run--545a9933-7fa3-4133-88df-9c13331c411e-0', usage_metadata={'input_tokens': 4, 'output_tokens': 151, 'total_tokens': 155, 'input_token_details': {'cache_read': 0}, 'output_token_details': {}})]}
{'agent': {'messages': [AIMessage(content='我是DeepSeek Chat,由深度求索公司(DeepSeek)创造的智能AI助手!🤖✨ 我可以帮你解答各种问题,无论是学习、工作,还是日常生活中的小困惑,都可以问我哦!有什么我可以帮你的吗?😊', additional_kwargs={'refusal': None}, response_metadata={'token_usage': {'completion_tokens': 54, 'prompt_tokens': 4, 'total_tokens': 58, 'completion_tokens_details': None, 'prompt_tokens_details': {'audio_tokens': None, 'cached_tokens': 0}, 'prompt_cache_hit_tokens': 0, 'prompt_cache_miss_tokens': 4}, 'model_name': 'deepseek-chat', 'system_fingerprint': 'fp_8802369eaa_prod0425fp8', 'id': '57ba7939-31f3-4499-87a3-225466a68871', 'service_tier': None, 'finish_reason': 'stop', 'logprobs': None}, id='run--b4a83b2f-7099-402a-8f91-52e355facb46-0', usage_metadata={'input_tokens': 4, 'output_tokens': 54, 'total_tokens': 58, 'input_token_details': {'cache_read': 0}, 'output_token_details': {}})]}}
#异步调用
from langgraph.prebuilt import create_react_agent
agent = create_react_agent(model=llm,tools=[])
response = await agent.ainvoke({"messages": [{"role": "user", "content": "你是谁?"}]})
print(response)
# 异步流式处理
asyncfor chunk in agent.astream(
{"messages": [{"role": "user", "content": "你是谁?"}]},
stream_mode="updates"
):
print(chunk)
{'messages': [HumanMessage(content='你是谁?', additional_kwargs={}, response_metadata={}, id='02cbc726-9f8b-411c-8406-9654edaba79f'), AIMessage(content='我是DeepSeek Chat,由深度求索公司创造的智能AI助手!🤖✨ 我的使命是帮助你解答各种问题,无论是学习、工作,还是生活中的小困惑,我都会尽力提供准确、有用的信息。 \n\n你可以问我任何问题,比如: \n- **知识查询**:历史、科学、技术等 \n- **实用建议**:写作、编程、旅行规划等 \n- **趣味互动**:讲个笑话、推荐电影或书籍 \n\n我目前是**免费的**,而且支持超长上下文(128K),还能读取你上传的文档(如PDF、Word等)来辅助回答。试试看吧!😊 \n\n有什么我可以帮你的吗?', additional_kwargs={'refusal': None}, response_metadata={'token_usage': {'completion_tokens': 143, 'prompt_tokens': 5, 'total_tokens': 148, 'completion_tokens_details': None, 'prompt_tokens_details': {'audio_tokens': None, 'cached_tokens': 0}, 'prompt_cache_hit_tokens': 0, 'prompt_cache_miss_tokens': 5}, 'model_name': 'deepseek-chat', 'system_fingerprint': 'fp_8802369eaa_prod0425fp8', 'id': '7a957aab-020a-4ccf-ab16-b2ec4a6a7b71', 'service_tier': None, 'finish_reason': 'stop', 'logprobs': None}, id='run--5e17dc65-1e9f-4694-bd54-c725bbee761f-0', usage_metadata={'input_tokens': 5, 'output_tokens': 143, 'total_tokens': 148, 'input_token_details': {'cache_read': 0}, 'output_token_details': {}})]}
{'agent': {'messages': [AIMessage(content='我是DeepSeek Chat,由深度求索公司(DeepSeek)创造的智能AI助手!🤖✨ 我的使命是帮助你解答各种问题,无论是学习、工作,还是日常生活中的小困惑。我可以陪你聊天、提供建议、查找资料,甚至帮你分析复杂的问题。 \n\n有什么我可以帮你的吗?😊', additional_kwargs={'refusal': None}, response_metadata={'token_usage': {'completion_tokens': 69, 'prompt_tokens': 5, 'total_tokens': 74, 'completion_tokens_details': None, 'prompt_tokens_details': {'audio_tokens': None, 'cached_tokens': 0}, 'prompt_cache_hit_tokens': 0, 'prompt_cache_miss_tokens': 5}, 'model_name': 'deepseek-chat', 'system_fingerprint': 'fp_8802369eaa_prod0425fp8', 'id': 'fca27385-22be-447e-927a-753bf3c7c19d', 'service_tier': None, 'finish_reason': 'stop', 'logprobs': None}, id='run--1117972c-5bb3-434d-910c-87034e331a96-0', usage_metadata={'input_tokens': 5, 'output_tokens': 69, 'total_tokens': 74, 'input_token_details': {'cache_read': 0}, 'output_token_details': {}})]}}
# 最大迭代次数
from langgraph.errors import GraphRecursionError
from langgraph.prebuilt import create_react_agent
max_iterations = 3
recursion_limit = 2 * max_iterations + 1
agent = create_react_agent(
model=llm,
tools=[]
)
try:
response = agent.invoke(
{"messages": [{"role": "user", "content": "你是谁?"}]},
{"recursion_limit": recursion_limit},
)
print(response)
except GraphRecursionError:
print("Agent stopped due to max iterations.")
{'messages': [HumanMessage(content='你是谁?', additional_kwargs={}, response_metadata={}, id='0346e2fd-b76b-49af-92df-72399c437f7d'), AIMessage(content='我是DeepSeek Chat,由深度求索公司(DeepSeek)创造的智能AI助手!🤖✨ 我的使命是帮助你解答问题、提供信息、陪你聊天,甚至帮你处理各种任务。无论是学习、工作,还是日常生活中的小疑问,都可以来找我哦!😊 \n\n有什么我可以帮你的吗?', additional_kwargs={'refusal': None}, response_metadata={'token_usage': {'completion_tokens': 69, 'prompt_tokens': 5, 'total_tokens': 74, 'completion_tokens_details': None, 'prompt_tokens_details': {'audio_tokens': None, 'cached_tokens': 0}, 'prompt_cache_hit_tokens': 0, 'prompt_cache_miss_tokens': 5}, 'model_name': 'deepseek-chat', 'system_fingerprint': 'fp_8802369eaa_prod0425fp8', 'id': 'f15916d3-7bbd-4463-8d98-6f2c9a46858c', 'service_tier': None, 'finish_reason': 'stop', 'logprobs': None}, id='run--62bcbfd5-8a7c-43e8-9f52-c553c9527089-0', usage_metadata={'input_tokens': 5, 'output_tokens': 69, 'total_tokens': 74, 'input_token_details': {'cache_read': 0}, 'output_token_details': {}})]}
2流
参考文档: https://langchain-ai.github.io/langgraph/agents/streaming/
流¶ 流式处理是构建响应式应用程序的关键。您需要流式传输几种类型的数据:
Agent progress — 在执行代理图中的每个节点后获取更新。 LLM tokens — 流式处理由语言模型生成的令牌。 自定义更新 — 在执行期间从工具发出自定义数据(例如,“Fetched 10/100 records”) 您可以一次流式传输多种类型的数据。
代理进度¶ 要流式传输代理进度,请将 stream() 或 astream() 方法与 stream_mode=“updates” 一起使用。这会在每个代理步骤后发出一个事件。
例如,如果您有一个代理调用了一次工具,您应该会看到以下更新:
LLM 节点:带有工具调用请求的 AI 消息 Tool 节点:带有执行结果的工具消息 LLM 节点:最终 AI 响应
# 创建llm
import os
from langchain.chat_models import init_chat_model
API_KEY = "sk-123"
BASE_URL = "https://api.deepseek.com"
os.environ["OPENAI_API_KEY"] = API_KEY
os.environ["OPENAI_API_BASE"] = BASE_URL
llm = init_chat_model("openai:deepseek-chat")
# 同步调用
from langgraph.prebuilt import create_react_agent
from langchain_core.tools import tool
@tool
defget_time():
"""
获取当前时间
"""
import datetime
curr_tiem= datetime.datetime.now().strftime("%Y-%m-%d %H:%M:%S")
return curr_tiem
tools=[get_time]
agent = create_react_agent(model=llm,tools=tools)
# 同步流式处理
for chunk in agent.stream(
{"messages": [{"role": "user", "content": "当前时间是多少呢"}]},
stream_mode="updates"
):
print(chunk)
print("\n")
{'agent': {'messages': [AIMessage(content='', additional_kwargs={'tool_calls': [{'id': 'call_0_ae5e502c-c3d6-459c-beb1-ac8a6426027b', 'function': {'arguments': '{}', 'name': 'get_time'}, 'type': 'function', 'index': 0}], 'refusal': None}, response_metadata={'token_usage': {'completion_tokens': 15, 'prompt_tokens': 74, 'total_tokens': 89, 'completion_tokens_details': None, 'prompt_tokens_details': {'audio_tokens': None, 'cached_tokens': 0}, 'prompt_cache_hit_tokens': 0, 'prompt_cache_miss_tokens': 74}, 'model_name': 'deepseek-chat', 'system_fingerprint': 'fp_8802369eaa_prod0425fp8', 'id': '1a6c6fe4-b2be-46bf-9952-7edde4dfe571', 'service_tier': None, 'finish_reason': 'tool_calls', 'logprobs': None}, id='run--acf6544e-04f6-4e43-b32c-dd444b47048a-0', tool_calls=[{'name': 'get_time', 'args': {}, 'id': 'call_0_ae5e502c-c3d6-459c-beb1-ac8a6426027b', 'type': 'tool_call'}], usage_metadata={'input_tokens': 74, 'output_tokens': 15, 'total_tokens': 89, 'input_token_details': {'cache_read': 0}, 'output_token_details': {}})]}}
{'tools': {'messages': [ToolMessage(content='2025-05-22 13:55:05', name='get_time', id='9718b250-7b13-46b9-883e-699dcf166e2b', tool_call_id='call_0_ae5e502c-c3d6-459c-beb1-ac8a6426027b')]}}
{'agent': {'messages': [AIMessage(content='当前时间是2025年5月22日,下午1点55分05秒。', additional_kwargs={'refusal': None}, response_metadata={'token_usage': {'completion_tokens': 18, 'prompt_tokens': 105, 'total_tokens': 123, 'completion_tokens_details': None, 'prompt_tokens_details': {'audio_tokens': None, 'cached_tokens': 64}, 'prompt_cache_hit_tokens': 64, 'prompt_cache_miss_tokens': 41}, 'model_name': 'deepseek-chat', 'system_fingerprint': 'fp_8802369eaa_prod0425fp8', 'id': '1fd9c141-420b-47ce-9fb8-6a53e5b265a9', 'service_tier': None, 'finish_reason': 'stop', 'logprobs': None}, id='run--4d15855d-5509-427d-882c-dc22bedf80f5-0', usage_metadata={'input_tokens': 105, 'output_tokens': 18, 'total_tokens': 123, 'input_token_details': {'cache_read': 64}, 'output_token_details': {}})]}}
#同步传输 llm的令牌 要在 LLM 生成令牌时流式传输令牌
agent = create_react_agent(
model=llm,
tools=[get_time],
)
for token, metadata in agent.stream(
{"messages": [{"role": "user", "content": "当前的时间是多少?"}]},
stream_mode="messages"
):
print("Token", token)
print("Metadata", metadata)
print("\n")
Token content='' additional_kwargs={} response_metadata={} id='run--83823969-fd1c-4031-b99f-afcb4d2f5ec2'
Metadata {'langgraph_step': 1, 'langgraph_node': 'agent', 'langgraph_triggers': ('branch:to:agent',), 'langgraph_path': ('__pregel_pull', 'agent'), 'langgraph_checkpoint_ns': 'agent:e2167a9c-dfe6-f8dd-a332-13fee5a8212d', 'checkpoint_ns': 'agent:e2167a9c-dfe6-f8dd-a332-13fee5a8212d', 'ls_provider': 'openai', 'ls_model_name': 'deepseek-chat', 'ls_model_type': 'chat', 'ls_temperature': None}
Token content='' additional_kwargs={'tool_calls': [{'index': 0, 'id': 'call_0_9f6c647f-2936-44e5-b956-1e58d20bc0e7', 'function': {'arguments': '', 'name': 'get_time'}, 'type': 'function'}]} response_metadata={} id='run--83823969-fd1c-4031-b99f-afcb4d2f5ec2' tool_calls=[{'name': 'get_time', 'args': {}, 'id': 'call_0_9f6c647f-2936-44e5-b956-1e58d20bc0e7', 'type': 'tool_call'}] tool_call_chunks=[{'name': 'get_time', 'args': '', 'id': 'call_0_9f6c647f-2936-44e5-b956-1e58d20bc0e7', 'index': 0, 'type': 'tool_call_chunk'}]
Metadata {'langgraph_step': 1, 'langgraph_node': 'agent', 'langgraph_triggers': ('branch:to:agent',), 'langgraph_path': ('__pregel_pull', 'agent'), 'langgraph_checkpoint_ns': 'agent:e2167a9c-dfe6-f8dd-a332-13fee5a8212d', 'checkpoint_ns': 'agent:e2167a9c-dfe6-f8dd-a332-13fee5a8212d', 'ls_provider': 'openai', 'ls_model_name': 'deepseek-chat', 'ls_model_type': 'chat', 'ls_temperature': None}
Token content='' additional_kwargs={'tool_calls': [{'index': 0, 'id': None, 'function': {'arguments': '{}', 'name': None}, 'type': None}]} response_metadata={} id='run--83823969-fd1c-4031-b99f-afcb4d2f5ec2' tool_calls=[{'name': '', 'args': {}, 'id': None, 'type': 'tool_call'}] tool_call_chunks=[{'name': None, 'args': '{}', 'id': None, 'index': 0, 'type': 'tool_call_chunk'}]
Metadata {'langgraph_step': 1, 'langgraph_node': 'agent', 'langgraph_triggers': ('branch:to:agent',), 'langgraph_path': ('__pregel_pull', 'agent'), 'langgraph_checkpoint_ns': 'agent:e2167a9c-dfe6-f8dd-a332-13fee5a8212d', 'checkpoint_ns': 'agent:e2167a9c-dfe6-f8dd-a332-13fee5a8212d', 'ls_provider': 'openai', 'ls_model_name': 'deepseek-chat', 'ls_model_type': 'chat', 'ls_temperature': None}
Token content='' additional_kwargs={} response_metadata={'finish_reason': 'tool_calls', 'model_name': 'deepseek-chat', 'system_fingerprint': 'fp_8802369eaa_prod0425fp8'} id='run--83823969-fd1c-4031-b99f-afcb4d2f5ec2' usage_metadata={'input_tokens': 74, 'output_tokens': 14, 'total_tokens': 88, 'input_token_details': {'cache_read': 64}, 'output_token_details': {}}
Metadata {'langgraph_step': 1, 'langgraph_node': 'agent', 'langgraph_triggers': ('branch:to:agent',), 'langgraph_path': ('__pregel_pull', 'agent'), 'langgraph_checkpoint_ns': 'agent:e2167a9c-dfe6-f8dd-a332-13fee5a8212d', 'checkpoint_ns': 'agent:e2167a9c-dfe6-f8dd-a332-13fee5a8212d', 'ls_provider': 'openai', 'ls_model_name': 'deepseek-chat', 'ls_model_type': 'chat', 'ls_temperature': None}
Token content='2025-05-22 13:57:08' name='get_time' id='ff393b7c-dddf-48ff-8b51-2768eca4f9ad' tool_call_id='call_0_9f6c647f-2936-44e5-b956-1e58d20bc0e7'
Metadata {'langgraph_step': 2, 'langgraph_node': 'tools', 'langgraph_triggers': ('branch:to:tools',), 'langgraph_path': ('__pregel_pull', 'tools'), 'langgraph_checkpoint_ns': 'tools:fb57d373-d4fd-3efe-3579-4c8fa2d72fbd'}
Token content='' additional_kwargs={} response_metadata={} id='run--424c6397-190d-4ea3-aa3b-48bb634c4cef'
Metadata {'langgraph_step': 3, 'langgraph_node': 'agent', 'langgraph_triggers': ('branch:to:agent',), 'langgraph_path': ('__pregel_pull', 'agent'), 'langgraph_checkpoint_ns': 'agent:203ef3af-125b-48d7-67d0-39ab628239f4', 'checkpoint_ns': 'agent:203ef3af-125b-48d7-67d0-39ab628239f4', 'ls_provider': 'openai', 'ls_model_name': 'deepseek-chat', 'ls_model_type': 'chat', 'ls_temperature': None}
Token content='当前' additional_kwargs={} response_metadata={} id='run--424c6397-190d-4ea3-aa3b-48bb634c4cef'
Metadata {'langgraph_step': 3, 'langgraph_node': 'agent', 'langgraph_triggers': ('branch:to:agent',), 'langgraph_path': ('__pregel_pull', 'agent'), 'langgraph_checkpoint_ns': 'agent:203ef3af-125b-48d7-67d0-39ab628239f4', 'checkpoint_ns': 'agent:203ef3af-125b-48d7-67d0-39ab628239f4', 'ls_provider': 'openai', 'ls_model_name': 'deepseek-chat', 'ls_model_type': 'chat', 'ls_temperature': None}
Token content='的时间' additional_kwargs={} response_metadata={} id='run--424c6397-190d-4ea3-aa3b-48bb634c4cef'
Metadata {'langgraph_step': 3, 'langgraph_node': 'agent', 'langgraph_triggers': ('branch:to:agent',), 'langgraph_path': ('__pregel_pull', 'agent'), 'langgraph_checkpoint_ns': 'agent:203ef3af-125b-48d7-67d0-39ab628239f4', 'checkpoint_ns': 'agent:203ef3af-125b-48d7-67d0-39ab628239f4', 'ls_provider': 'openai', 'ls_model_name': 'deepseek-chat', 'ls_model_type': 'chat', 'ls_temperature': None}
Token content='是' additional_kwargs={} response_metadata={} id='run--424c6397-190d-4ea3-aa3b-48bb634c4cef'
Metadata {'langgraph_step': 3, 'langgraph_node': 'agent', 'langgraph_triggers': ('branch:to:agent',), 'langgraph_path': ('__pregel_pull', 'agent'), 'langgraph_checkpoint_ns': 'agent:203ef3af-125b-48d7-67d0-39ab628239f4', 'checkpoint_ns': 'agent:203ef3af-125b-48d7-67d0-39ab628239f4', 'ls_provider': 'openai', 'ls_model_name': 'deepseek-chat', 'ls_model_type': 'chat', 'ls_temperature': None}
Token content='202' additional_kwargs={} response_metadata={} id='run--424c6397-190d-4ea3-aa3b-48bb634c4cef'
Metadata {'langgraph_step': 3, 'langgraph_node': 'agent', 'langgraph_triggers': ('branch:to:agent',), 'langgraph_path': ('__pregel_pull', 'agent'), 'langgraph_checkpoint_ns': 'agent:203ef3af-125b-48d7-67d0-39ab628239f4', 'checkpoint_ns': 'agent:203ef3af-125b-48d7-67d0-39ab628239f4', 'ls_provider': 'openai', 'ls_model_name': 'deepseek-chat', 'ls_model_type': 'chat', 'ls_temperature': None}
Token content='5' additional_kwargs={} response_metadata={} id='run--424c6397-190d-4ea3-aa3b-48bb634c4cef'
Metadata {'langgraph_step': 3, 'langgraph_node': 'agent', 'langgraph_triggers': ('branch:to:agent',), 'langgraph_path': ('__pregel_pull', 'agent'), 'langgraph_checkpoint_ns': 'agent:203ef3af-125b-48d7-67d0-39ab628239f4', 'checkpoint_ns': 'agent:203ef3af-125b-48d7-67d0-39ab628239f4', 'ls_provider': 'openai', 'ls_model_name': 'deepseek-chat', 'ls_model_type': 'chat', 'ls_temperature': None}
Token content='年' additional_kwargs={} response_metadata={} id='run--424c6397-190d-4ea3-aa3b-48bb634c4cef'
Metadata {'langgraph_step': 3, 'langgraph_node': 'agent', 'langgraph_triggers': ('branch:to:agent',), 'langgraph_path': ('__pregel_pull', 'agent'), 'langgraph_checkpoint_ns': 'agent:203ef3af-125b-48d7-67d0-39ab628239f4', 'checkpoint_ns': 'agent:203ef3af-125b-48d7-67d0-39ab628239f4', 'ls_provider': 'openai', 'ls_model_name': 'deepseek-chat', 'ls_model_type': 'chat', 'ls_temperature': None}
Token content='5' additional_kwargs={} response_metadata={} id='run--424c6397-190d-4ea3-aa3b-48bb634c4cef'
Metadata {'langgraph_step': 3, 'langgraph_node': 'agent', 'langgraph_triggers': ('branch:to:agent',), 'langgraph_path': ('__pregel_pull', 'agent'), 'langgraph_checkpoint_ns': 'agent:203ef3af-125b-48d7-67d0-39ab628239f4', 'checkpoint_ns': 'agent:203ef3af-125b-48d7-67d0-39ab628239f4', 'ls_provider': 'openai', 'ls_model_name': 'deepseek-chat', 'ls_model_type': 'chat', 'ls_temperature': None}
Token content='月' additional_kwargs={} response_metadata={} id='run--424c6397-190d-4ea3-aa3b-48bb634c4cef'
Metadata {'langgraph_step': 3, 'langgraph_node': 'agent', 'langgraph_triggers': ('branch:to:agent',), 'langgraph_path': ('__pregel_pull', 'agent'), 'langgraph_checkpoint_ns': 'agent:203ef3af-125b-48d7-67d0-39ab628239f4', 'checkpoint_ns': 'agent:203ef3af-125b-48d7-67d0-39ab628239f4', 'ls_provider': 'openai', 'ls_model_name': 'deepseek-chat', 'ls_model_type': 'chat', 'ls_temperature': None}
Token content='22' additional_kwargs={} response_metadata={} id='run--424c6397-190d-4ea3-aa3b-48bb634c4cef'
Metadata {'langgraph_step': 3, 'langgraph_node': 'agent', 'langgraph_triggers': ('branch:to:agent',), 'langgraph_path': ('__pregel_pull', 'agent'), 'langgraph_checkpoint_ns': 'agent:203ef3af-125b-48d7-67d0-39ab628239f4', 'checkpoint_ns': 'agent:203ef3af-125b-48d7-67d0-39ab628239f4', 'ls_provider': 'openai', 'ls_model_name': 'deepseek-chat', 'ls_model_type': 'chat', 'ls_temperature': None}
Token content='日' additional_kwargs={} response_metadata={} id='run--424c6397-190d-4ea3-aa3b-48bb634c4cef'
Metadata {'langgraph_step': 3, 'langgraph_node': 'agent', 'langgraph_triggers': ('branch:to:agent',), 'langgraph_path': ('__pregel_pull', 'agent'), 'langgraph_checkpoint_ns': 'agent:203ef3af-125b-48d7-67d0-39ab628239f4', 'checkpoint_ns': 'agent:203ef3af-125b-48d7-67d0-39ab628239f4', 'ls_provider': 'openai', 'ls_model_name': 'deepseek-chat', 'ls_model_type': 'chat', 'ls_temperature': None}
Token content=',' additional_kwargs={} response_metadata={} id='run--424c6397-190d-4ea3-aa3b-48bb634c4cef'
Metadata {'langgraph_step': 3, 'langgraph_node': 'agent', 'langgraph_triggers': ('branch:to:agent',), 'langgraph_path': ('__pregel_pull', 'agent'), 'langgraph_checkpoint_ns': 'agent:203ef3af-125b-48d7-67d0-39ab628239f4', 'checkpoint_ns': 'agent:203ef3af-125b-48d7-67d0-39ab628239f4', 'ls_provider': 'openai', 'ls_model_name': 'deepseek-chat', 'ls_model_type': 'chat', 'ls_temperature': None}
Token content='下午' additional_kwargs={} response_metadata={} id='run--424c6397-190d-4ea3-aa3b-48bb634c4cef'
Metadata {'langgraph_step': 3, 'langgraph_node': 'agent', 'langgraph_triggers': ('branch:to:agent',), 'langgraph_path': ('__pregel_pull', 'agent'), 'langgraph_checkpoint_ns': 'agent:203ef3af-125b-48d7-67d0-39ab628239f4', 'checkpoint_ns': 'agent:203ef3af-125b-48d7-67d0-39ab628239f4', 'ls_provider': 'openai', 'ls_model_name': 'deepseek-chat', 'ls_model_type': 'chat', 'ls_temperature': None}
Token content='1' additional_kwargs={} response_metadata={} id='run--424c6397-190d-4ea3-aa3b-48bb634c4cef'
Metadata {'langgraph_step': 3, 'langgraph_node': 'agent', 'langgraph_triggers': ('branch:to:agent',), 'langgraph_path': ('__pregel_pull', 'agent'), 'langgraph_checkpoint_ns': 'agent:203ef3af-125b-48d7-67d0-39ab628239f4', 'checkpoint_ns': 'agent:203ef3af-125b-48d7-67d0-39ab628239f4', 'ls_provider': 'openai', 'ls_model_name': 'deepseek-chat', 'ls_model_type': 'chat', 'ls_temperature': None}
Token content='点' additional_kwargs={} response_metadata={} id='run--424c6397-190d-4ea3-aa3b-48bb634c4cef'
Metadata {'langgraph_step': 3, 'langgraph_node': 'agent', 'langgraph_triggers': ('branch:to:agent',), 'langgraph_path': ('__pregel_pull', 'agent'), 'langgraph_checkpoint_ns': 'agent:203ef3af-125b-48d7-67d0-39ab628239f4', 'checkpoint_ns': 'agent:203ef3af-125b-48d7-67d0-39ab628239f4', 'ls_provider': 'openai', 'ls_model_name': 'deepseek-chat', 'ls_model_type': 'chat', 'ls_temperature': None}
Token content='57' additional_kwargs={} response_metadata={} id='run--424c6397-190d-4ea3-aa3b-48bb634c4cef'
Metadata {'langgraph_step': 3, 'langgraph_node': 'agent', 'langgraph_triggers': ('branch:to:agent',), 'langgraph_path': ('__pregel_pull', 'agent'), 'langgraph_checkpoint_ns': 'agent:203ef3af-125b-48d7-67d0-39ab628239f4', 'checkpoint_ns': 'agent:203ef3af-125b-48d7-67d0-39ab628239f4', 'ls_provider': 'openai', 'ls_model_name': 'deepseek-chat', 'ls_model_type': 'chat', 'ls_temperature': None}
Token content='分' additional_kwargs={} response_metadata={} id='run--424c6397-190d-4ea3-aa3b-48bb634c4cef'
Metadata {'langgraph_step': 3, 'langgraph_node': 'agent', 'langgraph_triggers': ('branch:to:agent',), 'langgraph_path': ('__pregel_pull', 'agent'), 'langgraph_checkpoint_ns': 'agent:203ef3af-125b-48d7-67d0-39ab628239f4', 'checkpoint_ns': 'agent:203ef3af-125b-48d7-67d0-39ab628239f4', 'ls_provider': 'openai', 'ls_model_name': 'deepseek-chat', 'ls_model_type': 'chat', 'ls_temperature': None}
Token content='。' additional_kwargs={} response_metadata={} id='run--424c6397-190d-4ea3-aa3b-48bb634c4cef'
Metadata {'langgraph_step': 3, 'langgraph_node': 'agent', 'langgraph_triggers': ('branch:to:agent',), 'langgraph_path': ('__pregel_pull', 'agent'), 'langgraph_checkpoint_ns': 'agent:203ef3af-125b-48d7-67d0-39ab628239f4', 'checkpoint_ns': 'agent:203ef3af-125b-48d7-67d0-39ab628239f4', 'ls_provider': 'openai', 'ls_model_name': 'deepseek-chat', 'ls_model_type': 'chat', 'ls_temperature': None}
Token content='' additional_kwargs={} response_metadata={'finish_reason': 'stop', 'model_name': 'deepseek-chat', 'system_fingerprint': 'fp_8802369eaa_prod0425fp8'} id='run--424c6397-190d-4ea3-aa3b-48bb634c4cef' usage_metadata={'input_tokens': 105, 'output_tokens': 17, 'total_tokens': 122, 'input_token_details': {'cache_read': 64}, 'output_token_details': {}}
Metadata {'langgraph_step': 3, 'langgraph_node': 'agent', 'langgraph_triggers': ('branch:to:agent',), 'langgraph_path': ('__pregel_pull', 'agent'), 'langgraph_checkpoint_ns': 'agent:203ef3af-125b-48d7-67d0-39ab628239f4', 'checkpoint_ns': 'agent:203ef3af-125b-48d7-67d0-39ab628239f4', 'ls_provider': 'openai', 'ls_model_name': 'deepseek-chat', 'ls_model_type': 'chat', 'ls_temperature': None}
#异步传输 llm的令牌 要在 LLM 生成令牌时流式传输令牌
agent = create_react_agent(
model=llm,
tools=[get_time],
)
asyncfor token, metadata in agent.astream(
{"messages": [{"role": "user", "content": "当前时间是多少"}]},
stream_mode="messages"
):
print("Token", token)
print("Metadata", metadata)
print("\n")
Token content='' additional_kwargs={} response_metadata={} id='run--89b903a0-885e-4504-8492-fd7f6f601c5e'
Metadata {'langgraph_step': 1, 'langgraph_node': 'agent', 'langgraph_triggers': ('branch:to:agent',), 'langgraph_path': ('__pregel_pull', 'agent'), 'langgraph_checkpoint_ns': 'agent:d0816e8f-0bf4-6e18-ee78-e697f76c6ccc', 'checkpoint_ns': 'agent:d0816e8f-0bf4-6e18-ee78-e697f76c6ccc', 'ls_provider': 'openai', 'ls_model_name': 'deepseek-chat', 'ls_model_type': 'chat', 'ls_temperature': None}
Token content='' additional_kwargs={'tool_calls': [{'index': 0, 'id': 'call_0_dfe7ab70-9836-410b-aa07-5c33f3e2bb0a', 'function': {'arguments': '', 'name': 'get_time'}, 'type': 'function'}]} response_metadata={} id='run--89b903a0-885e-4504-8492-fd7f6f601c5e' tool_calls=[{'name': 'get_time', 'args': {}, 'id': 'call_0_dfe7ab70-9836-410b-aa07-5c33f3e2bb0a', 'type': 'tool_call'}] tool_call_chunks=[{'name': 'get_time', 'args': '', 'id': 'call_0_dfe7ab70-9836-410b-aa07-5c33f3e2bb0a', 'index': 0, 'type': 'tool_call_chunk'}]
Metadata {'langgraph_step': 1, 'langgraph_node': 'agent', 'langgraph_triggers': ('branch:to:agent',), 'langgraph_path': ('__pregel_pull', 'agent'), 'langgraph_checkpoint_ns': 'agent:d0816e8f-0bf4-6e18-ee78-e697f76c6ccc', 'checkpoint_ns': 'agent:d0816e8f-0bf4-6e18-ee78-e697f76c6ccc', 'ls_provider': 'openai', 'ls_model_name': 'deepseek-chat', 'ls_model_type': 'chat', 'ls_temperature': None}
Token content='' additional_kwargs={'tool_calls': [{'index': 0, 'id': None, 'function': {'arguments': '{}', 'name': None}, 'type': None}]} response_metadata={} id='run--89b903a0-885e-4504-8492-fd7f6f601c5e' tool_calls=[{'name': '', 'args': {}, 'id': None, 'type': 'tool_call'}] tool_call_chunks=[{'name': None, 'args': '{}', 'id': None, 'index': 0, 'type': 'tool_call_chunk'}]
Metadata {'langgraph_step': 1, 'langgraph_node': 'agent', 'langgraph_triggers': ('branch:to:agent',), 'langgraph_path': ('__pregel_pull', 'agent'), 'langgraph_checkpoint_ns': 'agent:d0816e8f-0bf4-6e18-ee78-e697f76c6ccc', 'checkpoint_ns': 'agent:d0816e8f-0bf4-6e18-ee78-e697f76c6ccc', 'ls_provider': 'openai', 'ls_model_name': 'deepseek-chat', 'ls_model_type': 'chat', 'ls_temperature': None}
Token content='' additional_kwargs={} response_metadata={'finish_reason': 'tool_calls', 'model_name': 'deepseek-chat', 'system_fingerprint': 'fp_8802369eaa_prod0425fp8'} id='run--89b903a0-885e-4504-8492-fd7f6f601c5e' usage_metadata={'input_tokens': 73, 'output_tokens': 14, 'total_tokens': 87, 'input_token_details': {'cache_read': 64}, 'output_token_details': {}}
Metadata {'langgraph_step': 1, 'langgraph_node': 'agent', 'langgraph_triggers': ('branch:to:agent',), 'langgraph_path': ('__pregel_pull', 'agent'), 'langgraph_checkpoint_ns': 'agent:d0816e8f-0bf4-6e18-ee78-e697f76c6ccc', 'checkpoint_ns': 'agent:d0816e8f-0bf4-6e18-ee78-e697f76c6ccc', 'ls_provider': 'openai', 'ls_model_name': 'deepseek-chat', 'ls_model_type': 'chat', 'ls_temperature': None}
Token content='2025-05-22 14:21:22' name='get_time' id='12ef988c-707f-476c-aa4f-f9b89b2040d8' tool_call_id='call_0_dfe7ab70-9836-410b-aa07-5c33f3e2bb0a'
Metadata {'langgraph_step': 2, 'langgraph_node': 'tools', 'langgraph_triggers': ('branch:to:tools',), 'langgraph_path': ('__pregel_pull', 'tools'), 'langgraph_checkpoint_ns': 'tools:ca29ac4b-6e23-3a68-165f-53776241c11e'}
Token content='' additional_kwargs={} response_metadata={} id='run--9e675e9b-1ca2-4fb2-a800-f3dc73c5b63c'
Metadata {'langgraph_step': 3, 'langgraph_node': 'agent', 'langgraph_triggers': ('branch:to:agent',), 'langgraph_path': ('__pregel_pull', 'agent'), 'langgraph_checkpoint_ns': 'agent:2d64d2c8-bcf8-a8db-70d3-6ff09b034417', 'checkpoint_ns': 'agent:2d64d2c8-bcf8-a8db-70d3-6ff09b034417', 'ls_provider': 'openai', 'ls_model_name': 'deepseek-chat', 'ls_model_type': 'chat', 'ls_temperature': None}
Token content='当前' additional_kwargs={} response_metadata={} id='run--9e675e9b-1ca2-4fb2-a800-f3dc73c5b63c'
Metadata {'langgraph_step': 3, 'langgraph_node': 'agent', 'langgraph_triggers': ('branch:to:agent',), 'langgraph_path': ('__pregel_pull', 'agent'), 'langgraph_checkpoint_ns': 'agent:2d64d2c8-bcf8-a8db-70d3-6ff09b034417', 'checkpoint_ns': 'agent:2d64d2c8-bcf8-a8db-70d3-6ff09b034417', 'ls_provider': 'openai', 'ls_model_name': 'deepseek-chat', 'ls_model_type': 'chat', 'ls_temperature': None}
Token content='时间是' additional_kwargs={} response_metadata={} id='run--9e675e9b-1ca2-4fb2-a800-f3dc73c5b63c'
Metadata {'langgraph_step': 3, 'langgraph_node': 'agent', 'langgraph_triggers': ('branch:to:agent',), 'langgraph_path': ('__pregel_pull', 'agent'), 'langgraph_checkpoint_ns': 'agent:2d64d2c8-bcf8-a8db-70d3-6ff09b034417', 'checkpoint_ns': 'agent:2d64d2c8-bcf8-a8db-70d3-6ff09b034417', 'ls_provider': 'openai', 'ls_model_name': 'deepseek-chat', 'ls_model_type': 'chat', 'ls_temperature': None}
Token content='202' additional_kwargs={} response_metadata={} id='run--9e675e9b-1ca2-4fb2-a800-f3dc73c5b63c'
Metadata {'langgraph_step': 3, 'langgraph_node': 'agent', 'langgraph_triggers': ('branch:to:agent',), 'langgraph_path': ('__pregel_pull', 'agent'), 'langgraph_checkpoint_ns': 'agent:2d64d2c8-bcf8-a8db-70d3-6ff09b034417', 'checkpoint_ns': 'agent:2d64d2c8-bcf8-a8db-70d3-6ff09b034417', 'ls_provider': 'openai', 'ls_model_name': 'deepseek-chat', 'ls_model_type': 'chat', 'ls_temperature': None}
Token content='5' additional_kwargs={} response_metadata={} id='run--9e675e9b-1ca2-4fb2-a800-f3dc73c5b63c'
Metadata {'langgraph_step': 3, 'langgraph_node': 'agent', 'langgraph_triggers': ('branch:to:agent',), 'langgraph_path': ('__pregel_pull', 'agent'), 'langgraph_checkpoint_ns': 'agent:2d64d2c8-bcf8-a8db-70d3-6ff09b034417', 'checkpoint_ns': 'agent:2d64d2c8-bcf8-a8db-70d3-6ff09b034417', 'ls_provider': 'openai', 'ls_model_name': 'deepseek-chat', 'ls_model_type': 'chat', 'ls_temperature': None}
Token content='年' additional_kwargs={} response_metadata={} id='run--9e675e9b-1ca2-4fb2-a800-f3dc73c5b63c'
Metadata {'langgraph_step': 3, 'langgraph_node': 'agent', 'langgraph_triggers': ('branch:to:agent',), 'langgraph_path': ('__pregel_pull', 'agent'), 'langgraph_checkpoint_ns': 'agent:2d64d2c8-bcf8-a8db-70d3-6ff09b034417', 'checkpoint_ns': 'agent:2d64d2c8-bcf8-a8db-70d3-6ff09b034417', 'ls_provider': 'openai', 'ls_model_name': 'deepseek-chat', 'ls_model_type': 'chat', 'ls_temperature': None}
Token content='5' additional_kwargs={} response_metadata={} id='run--9e675e9b-1ca2-4fb2-a800-f3dc73c5b63c'
Metadata {'langgraph_step': 3, 'langgraph_node': 'agent', 'langgraph_triggers': ('branch:to:agent',), 'langgraph_path': ('__pregel_pull', 'agent'), 'langgraph_checkpoint_ns': 'agent:2d64d2c8-bcf8-a8db-70d3-6ff09b034417', 'checkpoint_ns': 'agent:2d64d2c8-bcf8-a8db-70d3-6ff09b034417', 'ls_provider': 'openai', 'ls_model_name': 'deepseek-chat', 'ls_model_type': 'chat', 'ls_temperature': None}
Token content='月' additional_kwargs={} response_metadata={} id='run--9e675e9b-1ca2-4fb2-a800-f3dc73c5b63c'
Metadata {'langgraph_step': 3, 'langgraph_node': 'agent', 'langgraph_triggers': ('branch:to:agent',), 'langgraph_path': ('__pregel_pull', 'agent'), 'langgraph_checkpoint_ns': 'agent:2d64d2c8-bcf8-a8db-70d3-6ff09b034417', 'checkpoint_ns': 'agent:2d64d2c8-bcf8-a8db-70d3-6ff09b034417', 'ls_provider': 'openai', 'ls_model_name': 'deepseek-chat', 'ls_model_type': 'chat', 'ls_temperature': None}
Token content='22' additional_kwargs={} response_metadata={} id='run--9e675e9b-1ca2-4fb2-a800-f3dc73c5b63c'
Metadata {'langgraph_step': 3, 'langgraph_node': 'agent', 'langgraph_triggers': ('branch:to:agent',), 'langgraph_path': ('__pregel_pull', 'agent'), 'langgraph_checkpoint_ns': 'agent:2d64d2c8-bcf8-a8db-70d3-6ff09b034417', 'checkpoint_ns': 'agent:2d64d2c8-bcf8-a8db-70d3-6ff09b034417', 'ls_provider': 'openai', 'ls_model_name': 'deepseek-chat', 'ls_model_type': 'chat', 'ls_temperature': None}
Token content='日' additional_kwargs={} response_metadata={} id='run--9e675e9b-1ca2-4fb2-a800-f3dc73c5b63c'
Metadata {'langgraph_step': 3, 'langgraph_node': 'agent', 'langgraph_triggers': ('branch:to:agent',), 'langgraph_path': ('__pregel_pull', 'agent'), 'langgraph_checkpoint_ns': 'agent:2d64d2c8-bcf8-a8db-70d3-6ff09b034417', 'checkpoint_ns': 'agent:2d64d2c8-bcf8-a8db-70d3-6ff09b034417', 'ls_provider': 'openai', 'ls_model_name': 'deepseek-chat', 'ls_model_type': 'chat', 'ls_temperature': None}
Token content=',' additional_kwargs={} response_metadata={} id='run--9e675e9b-1ca2-4fb2-a800-f3dc73c5b63c'
Metadata {'langgraph_step': 3, 'langgraph_node': 'agent', 'langgraph_triggers': ('branch:to:agent',), 'langgraph_path': ('__pregel_pull', 'agent'), 'langgraph_checkpoint_ns': 'agent:2d64d2c8-bcf8-a8db-70d3-6ff09b034417', 'checkpoint_ns': 'agent:2d64d2c8-bcf8-a8db-70d3-6ff09b034417', 'ls_provider': 'openai', 'ls_model_name': 'deepseek-chat', 'ls_model_type': 'chat', 'ls_temperature': None}
Token content='下午' additional_kwargs={} response_metadata={} id='run--9e675e9b-1ca2-4fb2-a800-f3dc73c5b63c'
Metadata {'langgraph_step': 3, 'langgraph_node': 'agent', 'langgraph_triggers': ('branch:to:agent',), 'langgraph_path': ('__pregel_pull', 'agent'), 'langgraph_checkpoint_ns': 'agent:2d64d2c8-bcf8-a8db-70d3-6ff09b034417', 'checkpoint_ns': 'agent:2d64d2c8-bcf8-a8db-70d3-6ff09b034417', 'ls_provider': 'openai', 'ls_model_name': 'deepseek-chat', 'ls_model_type': 'chat', 'ls_temperature': None}
Token content='2' additional_kwargs={} response_metadata={} id='run--9e675e9b-1ca2-4fb2-a800-f3dc73c5b63c'
Metadata {'langgraph_step': 3, 'langgraph_node': 'agent', 'langgraph_triggers': ('branch:to:agent',), 'langgraph_path': ('__pregel_pull', 'agent'), 'langgraph_checkpoint_ns': 'agent:2d64d2c8-bcf8-a8db-70d3-6ff09b034417', 'checkpoint_ns': 'agent:2d64d2c8-bcf8-a8db-70d3-6ff09b034417', 'ls_provider': 'openai', 'ls_model_name': 'deepseek-chat', 'ls_model_type': 'chat', 'ls_temperature': None}
Token content='点' additional_kwargs={} response_metadata={} id='run--9e675e9b-1ca2-4fb2-a800-f3dc73c5b63c'
Metadata {'langgraph_step': 3, 'langgraph_node': 'agent', 'langgraph_triggers': ('branch:to:agent',), 'langgraph_path': ('__pregel_pull', 'agent'), 'langgraph_checkpoint_ns': 'agent:2d64d2c8-bcf8-a8db-70d3-6ff09b034417', 'checkpoint_ns': 'agent:2d64d2c8-bcf8-a8db-70d3-6ff09b034417', 'ls_provider': 'openai', 'ls_model_name': 'deepseek-chat', 'ls_model_type': 'chat', 'ls_temperature': None}
Token content='21' additional_kwargs={} response_metadata={} id='run--9e675e9b-1ca2-4fb2-a800-f3dc73c5b63c'
Metadata {'langgraph_step': 3, 'langgraph_node': 'agent', 'langgraph_triggers': ('branch:to:agent',), 'langgraph_path': ('__pregel_pull', 'agent'), 'langgraph_checkpoint_ns': 'agent:2d64d2c8-bcf8-a8db-70d3-6ff09b034417', 'checkpoint_ns': 'agent:2d64d2c8-bcf8-a8db-70d3-6ff09b034417', 'ls_provider': 'openai', 'ls_model_name': 'deepseek-chat', 'ls_model_type': 'chat', 'ls_temperature': None}
Token content='分' additional_kwargs={} response_metadata={} id='run--9e675e9b-1ca2-4fb2-a800-f3dc73c5b63c'
Metadata {'langgraph_step': 3, 'langgraph_node': 'agent', 'langgraph_triggers': ('branch:to:agent',), 'langgraph_path': ('__pregel_pull', 'agent'), 'langgraph_checkpoint_ns': 'agent:2d64d2c8-bcf8-a8db-70d3-6ff09b034417', 'checkpoint_ns': 'agent:2d64d2c8-bcf8-a8db-70d3-6ff09b034417', 'ls_provider': 'openai', 'ls_model_name': 'deepseek-chat', 'ls_model_type': 'chat', 'ls_temperature': None}
Token content='22' additional_kwargs={} response_metadata={} id='run--9e675e9b-1ca2-4fb2-a800-f3dc73c5b63c'
Metadata {'langgraph_step': 3, 'langgraph_node': 'agent', 'langgraph_triggers': ('branch:to:agent',), 'langgraph_path': ('__pregel_pull', 'agent'), 'langgraph_checkpoint_ns': 'agent:2d64d2c8-bcf8-a8db-70d3-6ff09b034417', 'checkpoint_ns': 'agent:2d64d2c8-bcf8-a8db-70d3-6ff09b034417', 'ls_provider': 'openai', 'ls_model_name': 'deepseek-chat', 'ls_model_type': 'chat', 'ls_temperature': None}
Token content='秒' additional_kwargs={} response_metadata={} id='run--9e675e9b-1ca2-4fb2-a800-f3dc73c5b63c'
Metadata {'langgraph_step': 3, 'langgraph_node': 'agent', 'langgraph_triggers': ('branch:to:agent',), 'langgraph_path': ('__pregel_pull', 'agent'), 'langgraph_checkpoint_ns': 'agent:2d64d2c8-bcf8-a8db-70d3-6ff09b034417', 'checkpoint_ns': 'agent:2d64d2c8-bcf8-a8db-70d3-6ff09b034417', 'ls_provider': 'openai', 'ls_model_name': 'deepseek-chat', 'ls_model_type': 'chat', 'ls_temperature': None}
Token content='。' additional_kwargs={} response_metadata={} id='run--9e675e9b-1ca2-4fb2-a800-f3dc73c5b63c'
Metadata {'langgraph_step': 3, 'langgraph_node': 'agent', 'langgraph_triggers': ('branch:to:agent',), 'langgraph_path': ('__pregel_pull', 'agent'), 'langgraph_checkpoint_ns': 'agent:2d64d2c8-bcf8-a8db-70d3-6ff09b034417', 'checkpoint_ns': 'agent:2d64d2c8-bcf8-a8db-70d3-6ff09b034417', 'ls_provider': 'openai', 'ls_model_name': 'deepseek-chat', 'ls_model_type': 'chat', 'ls_temperature': None}
Token content='' additional_kwargs={} response_metadata={'finish_reason': 'stop', 'model_name': 'deepseek-chat', 'system_fingerprint': 'fp_8802369eaa_prod0425fp8'} id='run--9e675e9b-1ca2-4fb2-a800-f3dc73c5b63c' usage_metadata={'input_tokens': 104, 'output_tokens': 18, 'total_tokens': 122, 'input_token_details': {'cache_read': 64}, 'output_token_details': {}}
Metadata {'langgraph_step': 3, 'langgraph_node': 'agent', 'langgraph_triggers': ('branch:to:agent',), 'langgraph_path': ('__pregel_pull', 'agent'), 'langgraph_checkpoint_ns': 'agent:2d64d2c8-bcf8-a8db-70d3-6ff09b034417', 'checkpoint_ns': 'agent:2d64d2c8-bcf8-a8db-70d3-6ff09b034417', 'ls_provider': 'openai', 'ls_model_name': 'deepseek-chat', 'ls_model_type': 'chat', 'ls_temperature': None}
完整代码访问github地址:
https://github.com/aixiaoxin123/langgraph_project
大模型算是目前当之无愧最火的一个方向了,算是新时代的风口!有小伙伴觉得,作为新领域、新方向人才需求必然相当大,与之相应的人才缺乏、人才竞争自然也会更少,那转行去做大模型是不是一个更好的选择呢?是不是更好就业呢?是不是就暂时能抵抗35岁中年危机呢?
答案当然是这样,大模型必然是新风口!
那如何学习大模型 ?
由于新岗位的生产效率,要优于被取代岗位的生产效率,所以实际上整个社会的生产效率是提升的。但是具体到个人,只能说是:
最先掌握AI的人,将会比较晚掌握AI的人有竞争优势。
这句话,放在计算机、互联网、移动互联网的开局时期,都是一样的道理。
但现在很多想入行大模型的人苦于现在网上的大模型老课程老教材,学也不是不学也不是,基于此我用做产品的心态来打磨这份大模型教程,深挖痛点并持续修改了近100余次后,终于把整个AI大模型的学习路线完善出来!

在这个版本当中:
您只需要听我讲,跟着我做即可,为了让学习的道路变得更简单,这份大模型路线+学习教程已经给大家整理并打包分享出来, 😝有需要的小伙伴,可以 扫描下方二维码领取🆓↓↓↓

一、大模型经典书籍(免费分享)
AI大模型已经成为了当今科技领域的一大热点,那以下这些大模型书籍就是非常不错的学习资源。

二、640套大模型报告(免费分享)
这套包含640份报告的合集,涵盖了大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。(几乎涵盖所有行业)
三、大模型系列视频教程(免费分享)

四、2025最新大模型学习路线(免费分享)
我们把学习路线分成L1到L4四个阶段,一步步带你从入门到进阶,从理论到实战。

L1阶段:启航篇丨极速破界AI新时代
L1阶段:了解大模型的基础知识,以及大模型在各个行业的应用和分析,学习理解大模型的核心原理、关键技术以及大模型应用场景。

L2阶段:攻坚篇丨RAG开发实战工坊
L2阶段:AI大模型RAG应用开发工程,主要学习RAG检索增强生成:包括Naive RAG、Advanced-RAG以及RAG性能评估,还有GraphRAG在内的多个RAG热门项目的分析。

L3阶段:跃迁篇丨Agent智能体架构设计
L3阶段:大模型Agent应用架构进阶实现,主要学习LangChain、 LIamaIndex框架,也会学习到AutoGPT、 MetaGPT等多Agent系统,打造Agent智能体。

L4阶段:精进篇丨模型微调与私有化部署
L4阶段:大模型的微调和私有化部署,更加深入的探讨Transformer架构,学习大模型的微调技术,利用DeepSpeed、Lamam Factory等工具快速进行模型微调,并通过Ollama、vLLM等推理部署框架,实现模型的快速部署。

L5阶段:专题集丨特训篇 【录播课】

全套的AI大模型学习资源已经整理打包,有需要的小伙伴可以微信扫描下方二维码,免费领取

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 22
22 0
0- 0



 已为社区贡献228条内容
已为社区贡献228条内容

所有评论(0)