IJCAI2025 | T2S:首个领域无关文本引导时序生成框架,解决数据稀疏 + 长度限制两大痛点!
来自IJCAI2025,最新前沿时序技术,提出了T2S模型与TSFragment-600K数据集,T2S模型是首个领域无关的文本引导时间序列生成框架,能生成语义对齐的任意长度时间序列。
本篇论文来自IJCAI2025,最新前沿时序技术,提出了T2S模型与TSFragment-600K数据集,T2S模型是首个领域无关的文本引导时间序列生成框架,能生成语义对齐的任意长度时间序列。
了解顶会最新技术,紧跟科研潮流,研究与写作才能保持在时代一线,全部49篇IJCAI2025前沿时序合集小时已经整理好了,在功🀄浩“时序大模型”发送“资料”扫码回复“IJCAI2025时序合集”即可自取~其他顶会时序合集也可以回复相关顶会名称自取哈~(AAAI25,ICLR25,ICML25等)
文章信息
论文名称:T2S: High-resolution Time Series Generation with Text-to-Series Diffusion Models
论文作者:Yunfeng Ge、Jiawei Li、Yiji Zhao、Haomin Wen、Zhao Li、Meikang Qiu、Hongyan Li、Ming Jin and Shirui Pan

研究背景
现有文本引导时间序列生成(Text-to-Time Series, T2S)存在两大核心挑战:
-
一是缺乏通用的时间序列描述数据集,现有数据集多为特定领域(如医疗、经济),泛化性差;
-
二是模型无法生成任意长度的时间序列,受限于训练数据的固定长度,难以适配真实场景需求。
同时,扩散模型在文本引导图像、音频生成中已获成功,但在时间序列领域应用尚处于早期阶段。
为此,文章提出了T2S模型,以解决上述问题。

模型框架

新的数据集与新模型
新数据集构建:提出TSFragment-600K数据集,包含超 60 万个高分辨率 “时间序列片段 - 文本” 对,填补了片段级(Fragment-level)时间序列描述数据集的空白,平衡了点级(Point-level,细粒度但忽略全局)和实例级(Instance-level,全局但模糊局部)描述的不足。
新模型设计:提出T2S 模型,是首个领域无关的文本引导时间序列生成框架,能生成语义对齐的任意长度时间序列,核心组件包括:
-
长度自适应变分自编码器(LA-VAE):将不同长度的时间序列编码为统一的 latent 嵌入,解决长度适配问题。
-
T2S 扩散 Transformer(T2S-DiT):以流匹配为扩散骨干,Diffusion Transformer 为去噪器,通过自适应层归一化实现文本表示与 latent 嵌入的对齐。
训练策略与性能:采用交错训练策略,支持多长度数据统一训练
核心技术
时间序列描述分类:首次将时间序列文本描述系统分为三级,明确不同粒度的引导作用:
-
点级(Point-level):为单个时间点提供标注,细粒度引导。
-
片段级(Fragment-level):为非重叠连续片段标注,兼顾局部趋势与上下文。
-
实例级(Instance-level):为整个时间序列提供全局标注,宏观引导。
扩散与对齐机制:
-
采用整流流(Rectified Flow) 实现扩散过程,相比 DDPM 生成质量更高、训练成本更低,通过最小化真实速度与预测速度的 MSE 损失优化模型。
-
引入无分类器引导(Classifier-free Guidance),训练时随机置零文本条件,推理时结合条件与无条件生成结果,平衡灵活性与生成质量。
长度适配与训练优化:
-
LA-VAE 通过上采样 / 下采样将不同长度时间序列映射到统一 latent 空间,引入 latent 空间一致性损失 ,减少插值导致的失真。
-
交错训练通过随机混合不同长度数据集的样本,避免传统训练的 “灾难性遗忘”,提升模型泛化性。
实验数据
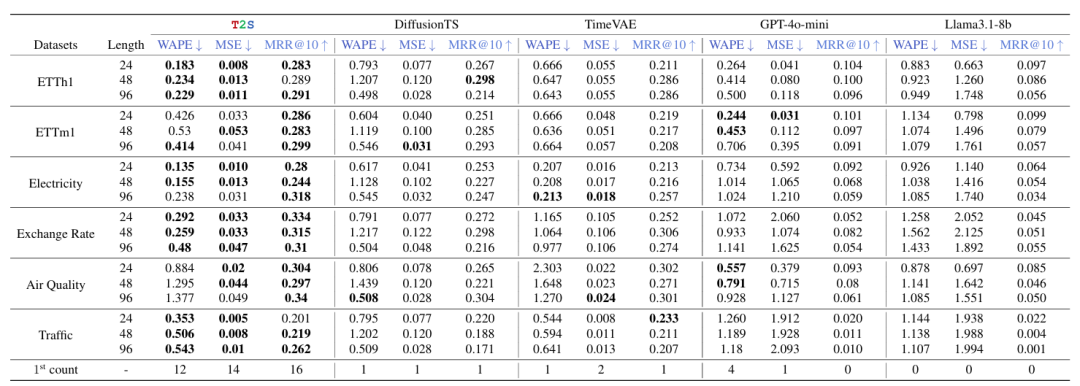
片段级性能(RQ1):在 6 个数据集(如 ETTh1、汇率、交通)上,T2S 在 MSE、WAPE、MRR@10 三项指标中占据 14/18(77.8%)的最优项,在汇率数据集上 MSE 较 DiffusionTS 降低 56.0%、较 TimeVAE 降低 68.9%。
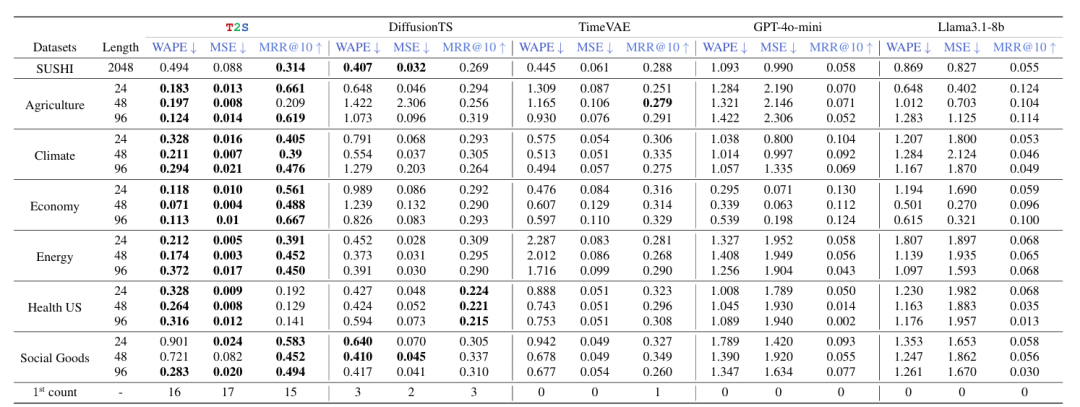
点级与实例级性能(RQ2):在 7 个数据集(如 SUSHI、农业、气候)上,T2S 在 MSE 指标中 17/18 次最优,实例级 SUSHI 数据集上 MRR@10 达 0.314,显著优于零样本大模型。
消融实验(RQ3):移除文本引导、替换流匹配为 DDPM、替换 DiT 为 MLP,分别导致平均误差上升 495.13%、311.00%、877.67%,验证各组件的必要性。
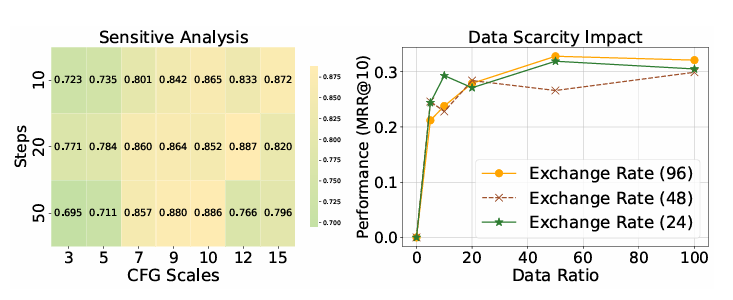

鲁棒性验证(RQ4-RQ5):CFG 值 7-10、生成步数 20-50 时性能最优;仅用 50% 数据即可达到全量数据 93.8% 的性能,证明数据稀缺场景下的强泛化性。
小小总结
文章通过构建片段级数据集、设计领域无关的 T2S 模型及交错训练策略,解决了文本引导时间序列生成的 “数据集稀缺” 与 “长度固定” 问题,在多领域验证了 SOTA 性能,为 T2S 研究提供了统一的数据集与模型框架,推动了扩散模型在时间序列生成领域的应用。
2025顶会前沿时序合集,攻🀄豪关注“时序大模型”,回复“资料”即可自取~
关注小时,持续学习前沿时序技术!

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 34
34 0
0- 0



 已为社区贡献13条内容
已为社区贡献13条内容

所有评论(0)