大模型训练技术:1概述
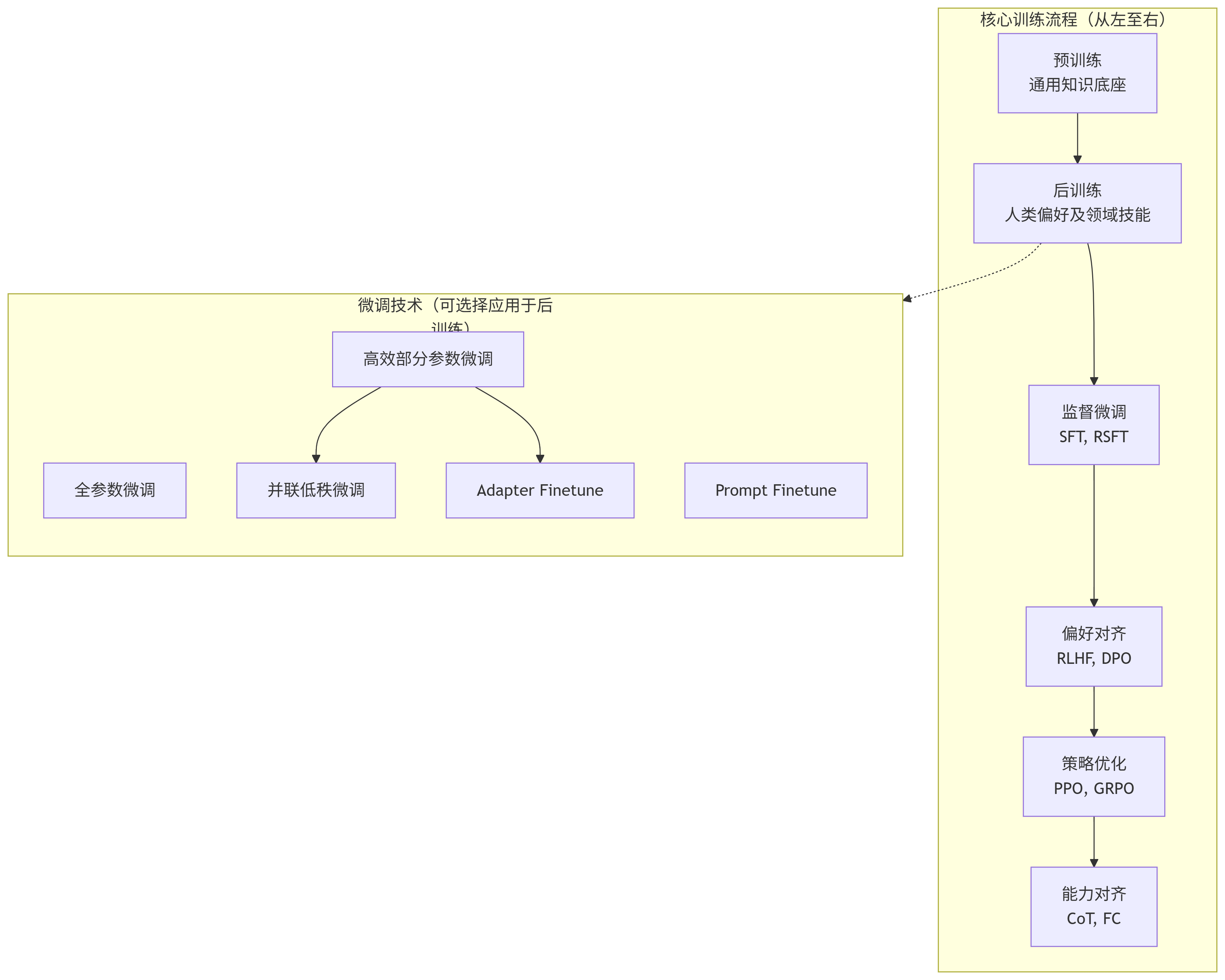
大模型训练分为预训练和后训练两阶段。预训练通过自回归或自编码方法从海量文本中学习通用语言知识;后训练则通过监督微调、强化学习等技术实现任务适配与偏好对齐。关键技术包括SFT(监督微调)、RLHF(人类反馈强化学习)、DPO(直接偏好优化)等,不同方法可组合使用:轻量任务用SFT+RSFT,高安全需求需SFT→DPO→领域适配。后训练流程需分阶段实施,先建立基础能力再优化生成质量,最终实现价值观对齐
大模型训练的核心流程可分为预训练(Pre-Training) 与后训练(Post-Training) 两阶段,二者协同实现从通用语言理解到任务精准适配的能力跃迁。
一、预训练阶段:构建通用知识基座
模型从海量文本中学习语法、语义、常识和领域知识。常用的方法有:
-
自回归模型(如GPT系列):通过预测下一个词来训练模型。
-
自编码模型(如BERT):通过掩码语言模型(Masked Language Modeling, MLM)任务训练模型。
-
混合方法:结合自回归和自编码的优势(如T5、BART)
预训练过程一般可分为三阶段:
-
初期训练:学习基础语言统计规律(如词频、共现关系);
-
中期训练:捕获语法结构及语义关联(如上下文依赖);
-
退火训练:优化表示空间,增强特征泛化性。
总之预训练阶段的核心目标是使模型掌握语言的通用模式(如BERT的掩码预测、GPT的自回归生成),为下游任务提供知识基础。
二、后训练阶段:对齐人类偏好与领域需求
预训练模型虽具备通用知识,但存在幻觉风险与指令遵循弱的问题。后训练通过微调技术实现:
核心目标:
-
提升生成质量与事实准确性;
-
强化指令理解与价值观对齐;
-
适配专业领域(如医疗、编程)。
关键技术方法:
|
类别 |
代表方法 |
功能 |
|---|---|---|
|
监督微调 |
SFT、RSFT |
基础任务适配与质量筛选 |
|
偏好对齐 |
RLHF、DPO |
人类价值观注入与安全控制 |
|
策略优化 |
PPO、GRPO |
平衡探索与稳定性 |
|
能力增强 |
思维链、工具调用 |
复杂推理与工具协作能力强化 |
后训练流程设计:多环节协同演进
后训练需分阶段组合技术,典型流程如下:
-
指令数据构建 收集多场景数据(日常对话、知识问答、代码等),构建任务导向数据集。
-
监督微调(SFT) 用指令数据微调模型,建立基础任务能力(如格式遵循、基础推理)。
-
拒绝采样微调(RSFT) 通过人工/模型筛选高质量样本,迭代优化生成质量(SFT的强化版)。
-
偏好对齐训练 RLHF路径:SFT → 奖励模型训练 → PPO优化; DPO路径:直接利用偏好数据优化策略,跳过奖励模型训练。
-
专项能力增强 注入领域知识(如医学术语、城市治理、工业生产)、集成思维链(CoT)提升长程推理、结合工具调用解决复杂问题。
大模型的后训练阶段各方法通常需要多环节组合使用
-
SFT不可跳过: 直接应用RLHF/DPO会导致强化学习难以收敛(缺乏任务基础)。
-
流程灵活组合: 轻量任务可仅用SFT+RSFT;高安全需求任务需SFT→DPO→领域适配。
-
新兴范式创新: 如GRPO通过群体输出对比替代PPO的Critic模型,降低计算开销
三、后训练技术路线的另一个角度
我们日常中可能遇到更笼统的说法,用某种名词指代某条技术路线。如:
1. ReFT(强化微调)
核心公式:ReFT = SFT + PPO + 自动化评估
• 流程:
-
监督微调(SFT):使用标注数据训练模型,建立基础语言能力;
-
强化学习优化(PPO):通过自动化程序(如规则引擎或参考答案比对)评估模型输出,生成奖励信号,驱动PPO调整参数。
• 优势:
-
自动化评估:无需人工干预,适用于数学求解、代码生成等客观标准明确的任务;
-
数据高效:仅需数十条样本即可显著提升效果(如GSM8K数学数据集)。
2. RLHF(基于人类反馈的强化学习)
核心公式:RLHF = SFT + PPO + 人类反馈
• 流程:
-
SFT初步训练:奠定任务基础能力;
-
人类反馈整合:直接使用人类对输出的评分/排序指导PPO;或训练奖励模型(Reward Model),替代人工生成奖励信号。
• 优势:
-
主观对齐:使输出更符合人类价值观,适用于对话系统、创意生成等需复杂评判的任务;
• 局限:
-
人类标注成本高,且可能存在偏好不一致问题。
3. DPO(直接偏好优化)
核心特点:跳过强化学习,采用监督学习直接优化偏好
• 流程:
-
SFT预训练:获得基础模型;
-
偏好数据构建:收集人类对多个输出的偏好选择(如选择答案A而非B);
-
损失函数设计:通过参考模型(Reference Model)计算偏好概率差,直接微调参数(如最大化偏好输出概率)。
• 优势: -
训练稳定:避免PPO的探索性试错,收敛更快;
-
资源高效:无需奖励模型,降低计算复杂度;
• 适用场景:拥有大量人类偏好数据的任务(如安全对齐、风格适配)。
4. RLAIF(基于AI反馈的强化学习)
核心公式:RLAIF = SFT + PPO + AI反馈
• 流程:
-
SFT初始化;
-
AI替代人类:由辅助AI模型(如预训练奖励模型)生成奖励信号,驱动PPO优化;
• 优势:
-
低成本:减少人类标注依赖,适合规模化应用;
• 局限:
-
效果高度依赖辅助模型质量,劣质AI反馈可能导致奖励黑客(Reward Hacking)。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 22
22 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)