大模型如何“练成”?详解训练、微调与强化学习的基础逻辑,大模型入门到精通,收藏这篇就足够了!
本文对这些概念和模式进行梳理汇总,并结合DeepSeek和Qwen两个案例进行说明,方便像我一样从信息化领域转型过来刚入门的同学也能快速了解“训练”的范围和基础逻辑。
我们或多或少都听说LLM大模型是先“训练”出来,然后再用于“推理”,那怎么理解这个“训练”过程?
是不是经常听说行业性场景中要使用垂域大模型,比通用大模型效果会更好,然后都说垂域大模型是“微调”出来的,那么什么是“微调”?和上面说的“训练”是什么关系?
当你尝试去深入了解这些问题时,搜到的各种介绍是不是都有点深奥?看到预训练、后训练、监督微调、强化学习、低秩适应、奖励模型等一堆概念是不是有点懵逼?
本文对这些概念和模式进行梳理汇总,并结合DeepSeek和Qwen两个案例进行说明,方便像我一样从信息化领域转型过来刚入门的同学也能快速了解“训练”的范围和基础逻辑。
预训练(Pre-Training)和后训练(Post-Training)
“训练Training”其实是多年前机器学习时代就有的概念,把机器学习模型可以想象成一个包含有多元变量的数学函数公式y=w1x1+w2x2+…+wnxn+b,其中X1、X2…Xn就是预先选择好要参与计算的特征变量,然后利用一组包含特征值x和结果值y的历史数据,进行训练得到就是各个特征变量的权重系数W1、W2…Wn,这样这个函数就建立起来(训练出来)了,然后预测过程就是将新的一组变量x代入这个函数公式(模型)进行计算,得到函数结果y就是预测值。
虽然大模型本质和机器学习差异还是巨大的,比如大模型的训练过程是不需要人工预先选择/设计特征x的,而是自动学习提取出来的;大模型的权重系数W的数量是巨大的,几十亿到上万亿参数量;大模型的推理是基于词向量的概率推理,和机器学习这种确定性映射计算不同等。
但为了便于理解,我们还是可以将大模型的训练过程简单理解成以上数学函数的训练过程,最终都是为了训练得到这个函数的一套权重参数(只不过大模型的这个函数公式特别通用化、变量特征不固定、权重参数量特别多)。这个过程就包括预训练(pre-training)和后训练(post-train),其相互关系如下:
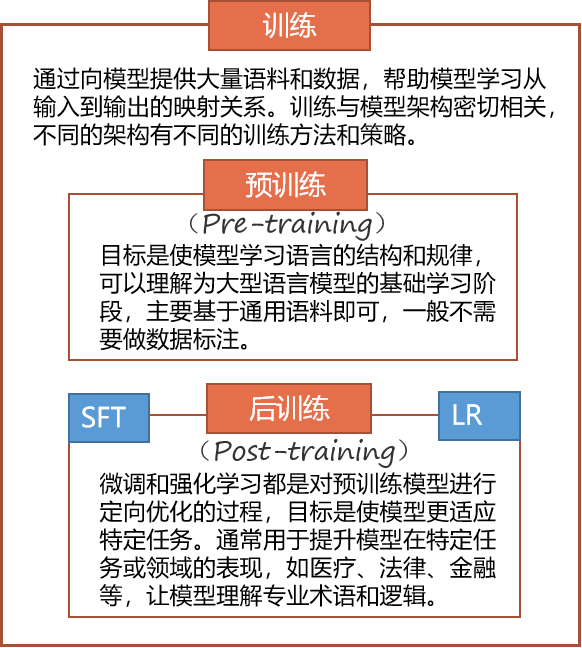
预训练(pre-training)得到的叫基座模型,可以认为是得到数学函数的一套基础权重参数,可以满足一般场景的预测和推理需要。
后训练(post-train)则是在这个基座模型基础上,结合业务场景需要和行业知识数据等进一步训练,最终是调整了基座模型的某些权重参数,以更精准的满足具体业务场景预测和推理需要。
监督微调(SFT)和强化学习(RL)
后训练(post-train)内部又包含监督微调Supervised Fine-Tuning(SFT)和强化学习Reinforcement Learning(RL)两个方向,其主要实现机制对比如下:
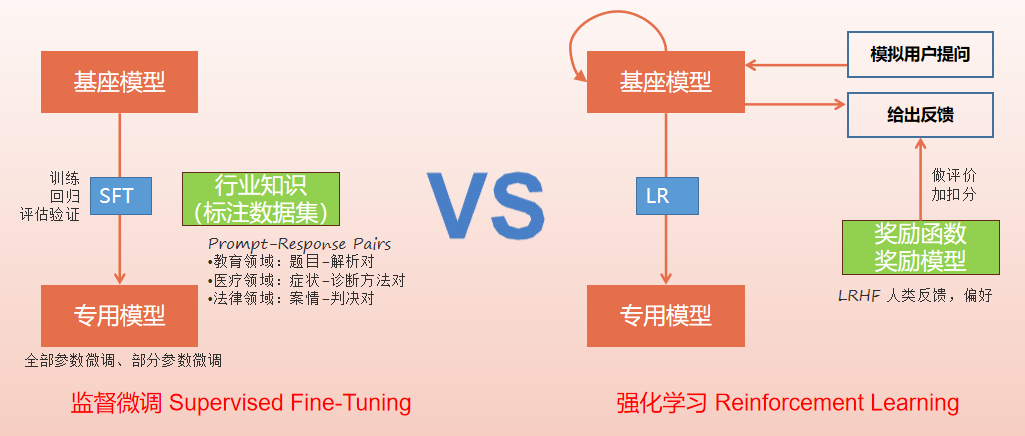
先利用前文所述数学函数的例子,来看看监督微调与强化学习的区别:监督微调是要准备一组特征值X和结果值Y(也就是所谓的标注/标签)组成的数据集来进行训练,通过调整函数的权重参数,让它的预测值与结果值Y尽可能接近,它的核心目标就是要最小化预测值与真实标签的误差;而强化学习则不需要预先准备好结果值Y,它只要提供输入让函数模拟计算,再通过与环境的交互获得反馈(奖励或惩罚),通过调整参数尽可能获取奖励,它的核心目标是要能最大化长期累积奖励期望值。
更形象的比喻,监督微调有点像刷练习题,预先准备好题目和标准答案,通过同类题目的反复练习和纠错(调参),确保碰到新题也能作对;而强化学习有点像模拟考,需要阅卷老师评价,通过反复模拟考,提升书写规范性、掌握时间分配、符合阅卷老师倾向等,以尽可能得高分。
如上所述监督微调Supervised Fine-Tuning(SFT)核心是要用到精确标注的数据集,而且是输入(特征)/输出(标签)成对出现的数据集,比如教育领域的题目和解题方法,医疗领域的症状和诊断方法,法律领域的案情和判决结果等,经过微调部分参数或全部参数,得到一个适用于特定行业领域更精准的专有模型。
这里推荐大神“智能体AI”写的《你真的了解大模型怎么“调”?四种主流LLM微调方法详解》这篇文章,基础逻辑讲得非常清晰,按微调的代价从高到低包括:全量微调Full-Tuning给基座模型“重塑金身”,相当于对以上所说数学函数的权重参数w全部都调整;冻结部分参数Freeze-Tunging只调“头部”参数;低秩适应LoRA给基座模型加外挂配件,相当于不用改模型本身参数,而是通过做加法,在基座模型上额外增加一些小的数学函数,以确保最终预测和推理结果也能符合行业特性;还有更轻量的量化低秩适应QLoRA,是把基座模型先量化压缩后,再做加法。
强化学习Reinforcement Learning(RL)的核心逻辑和微调SFT差别很大,它核心是通过奖励函数/奖励模型(Reward Model)的方式,来引导大模型形成一定的“肌肉记忆”,就是通过对模型输出,选择某些质量维度(如回答的有用性、安全性)进行评价,生成奖励分数,来指导大模型自我优化方向,举个例子可能更好理解:
比如我们常用的一些聊天对话大模型,之所以能够提供所谓的“情绪价值”,之所以不会出现暴力和涩涩的回答,很大程度上是通过强化学习实现的,在强化学习期间,如果大模型的输出是温暖和正面的,奖励模型就给它加分,经过长时间的强化学习引导,大模型的回答自然就会符合这些价值观和偏好。
所以强化学习的核心就在于奖励模型,这个才是灵魂和难度所在,当然强化学习内部又还有多种策略,比如RLHF(人类反馈强化学习)、PPO(近端策略优化)、GRPO(群体相对策略优化)等,后面案例中也会有所展开。
DeepSeek的模型谱系示例
接下来我们用DeepSeek的模型谱系案例,来理解上述预训练、监督微调和强化学习等不同训练方法的具体实践:
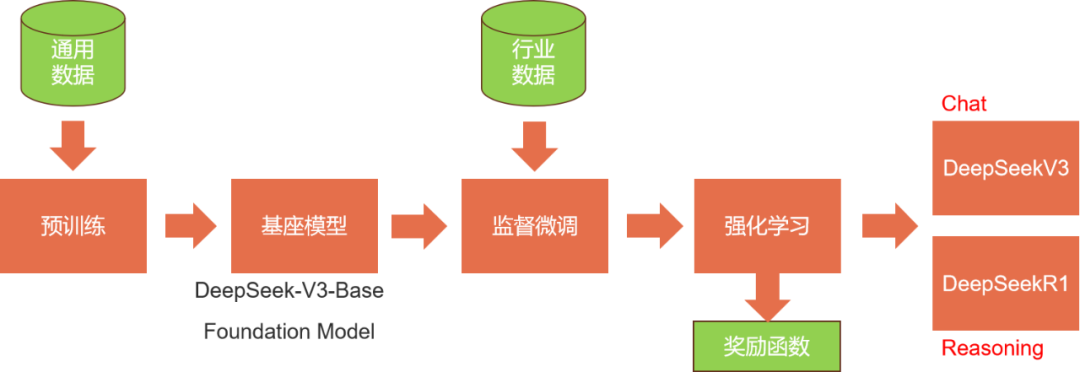
如图,我们都很熟悉DeepSeek有两种比较常用的模型,通用语言模型V3和推理增强模型R1,这两种模型实际都是在基座模型DeepSeek-V3-Base基础上经过监督微调和强化学习出来的。
和我们一般认知有所不同,都说R1是基于V3的,实际指的是基于V3-Base这个基座模型(Foundation Model)。
然后用于聊天对话的V3,实际也是在V3-Base基础上经过专门的后训练得出来的(基于标注好的问答数据集做SFT,基于强化学习评价引导等),所以才能在聊天对话中提供“情绪价值”。
而R1则是推理增强模型,其核心也包括监督微调SFT过程,利用带思维链推理过程标注的数据集;也包括强化学习RL过程,利用奖励模型来评分(如有推理过程和格式就加分,推理过程越清晰得分越多等)。经过多轮次交替最终得到这种推理增强模型,细节可以参考《一文读懂DeepSeek R1训练过程》这篇文章。
额外提一句:R1推理模型因为有Thinking思考过程,响应时间更慢一些,但可解释性更强一些,所以更适合复杂分析和总结的场景,而需要即时响应并反馈的场景,则更适合用通用语言模型V3。五一前夕出来的Qwen3模型,则是一个混合推理模型,可以按需开启/关闭推理思考过程。
Qwen2.5-Math模型谱系示例
前段时间因为要引用Qwen的数学模型(Qwen2.5-Math-7B-Instruct),在魔搭社区找到该模型的介绍,看到其模型谱系如下:
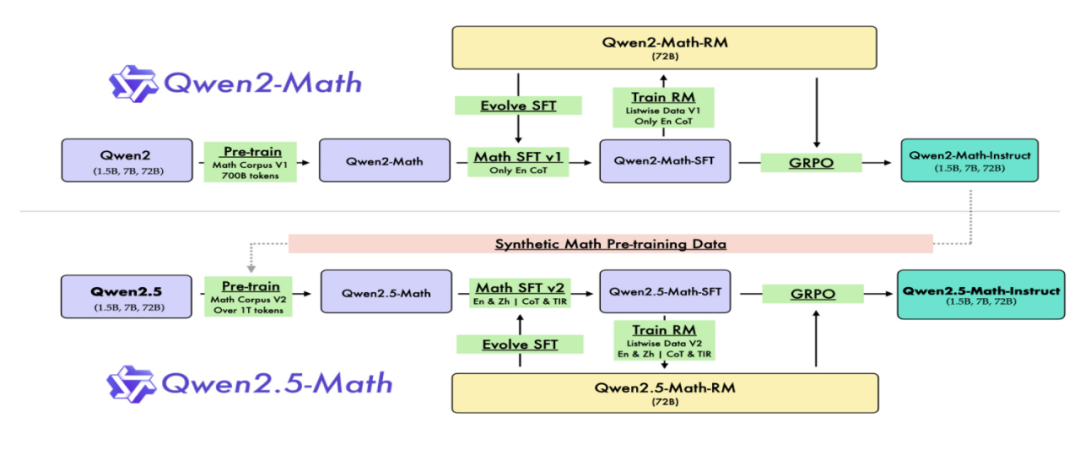
如图在Qwen2.5模型基础上,利用数据集“Math Corpus V2”,经过预训练Pre-train得到Qwen2.5数学模型系列的基座模型“Qwen2.5-Math”。
在基座模型“Qwen2.5-Math”基础上,经过监督微调SFT,得到Qwen2.5-Math-SFT模型,这里提到SFT过程包括:

这段英文主要说明微调SFT过程用到了思维链CoT做法,以及集成工具推理TIR的做法,关键是利用“Math SFT V2”这套标注数据集,实现中英文数学问题的解答。
在Qwen2.5-Math-SFT模型基础上进一步进行强化学习,其核心是利用“Qwen2.5-Math-RM(72B)”这个评价模型(Reward Model),同时基于群体相对策略优化GRPO(Group Relative Policy Optimization),才最终得到我们要在业务场景中使用的模型“Qwen2.5-Math-7B-Instruct”。
对这个案例有兴趣的同学,可以看看魔搭上这个模型介绍的原文链接(https://modelscope.cn/models/Qwen/Qwen2.5-Math-7B-Instruct),顺便可以学习下英文哈。
大模型算是目前当之无愧最火的一个方向了,算是新时代的风口!有小伙伴觉得,作为新领域、新方向人才需求必然相当大,与之相应的人才缺乏、人才竞争自然也会更少,那转行去做大模型是不是一个更好的选择呢?是不是更好就业呢?是不是就暂时能抵抗35岁中年危机呢?
答案当然是这样,大模型必然是新风口!
那如何学习大模型 ?
由于新岗位的生产效率,要优于被取代岗位的生产效率,所以实际上整个社会的生产效率是提升的。但是具体到个人,只能说是:
最先掌握AI的人,将会比较晚掌握AI的人有竞争优势。
这句话,放在计算机、互联网、移动互联网的开局时期,都是一样的道理。
但现在很多想入行大模型的人苦于现在网上的大模型老课程老教材,学也不是不学也不是,基于此我用做产品的心态来打磨这份大模型教程,深挖痛点并持续修改了近100余次后,终于把整个AI大模型的学习路线完善出来!

在这个版本当中:
您只需要听我讲,跟着我做即可,为了让学习的道路变得更简单,这份大模型路线+学习教程已经给大家整理并打包分享出来, 😝有需要的小伙伴,可以 扫描下方二维码领取🆓↓↓↓

一、大模型经典书籍(免费分享)
AI大模型已经成为了当今科技领域的一大热点,那以下这些大模型书籍就是非常不错的学习资源。

二、640套大模型报告(免费分享)
这套包含640份报告的合集,涵盖了大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。(几乎涵盖所有行业)
三、大模型系列视频教程(免费分享)

四、2025最新大模型学习路线(免费分享)
我们把学习路线分成L1到L4四个阶段,一步步带你从入门到进阶,从理论到实战。

L1阶段:启航篇丨极速破界AI新时代
L1阶段:了解大模型的基础知识,以及大模型在各个行业的应用和分析,学习理解大模型的核心原理、关键技术以及大模型应用场景。

L2阶段:攻坚篇丨RAG开发实战工坊
L2阶段:AI大模型RAG应用开发工程,主要学习RAG检索增强生成:包括Naive RAG、Advanced-RAG以及RAG性能评估,还有GraphRAG在内的多个RAG热门项目的分析。

L3阶段:跃迁篇丨Agent智能体架构设计
L3阶段:大模型Agent应用架构进阶实现,主要学习LangChain、 LIamaIndex框架,也会学习到AutoGPT、 MetaGPT等多Agent系统,打造Agent智能体。

L4阶段:精进篇丨模型微调与私有化部署
L4阶段:大模型的微调和私有化部署,更加深入的探讨Transformer架构,学习大模型的微调技术,利用DeepSpeed、Lamam Factory等工具快速进行模型微调,并通过Ollama、vLLM等推理部署框架,实现模型的快速部署。

L5阶段:专题集丨特训篇 【录播课】

全套的AI大模型学习资源已经整理打包,有需要的小伙伴可以微信扫描下方二维码,免费领取

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 8
8 0
0- 0



 已为社区贡献225条内容
已为社区贡献225条内容

所有评论(0)