AI 技术如何重塑智能制造:从质检 2.0 到自愈工厂
本文探讨了AI技术在智能制造中的关键应用,聚焦两大核心场景:1)基于多模态大模型的零缺陷质检2.0系统,通过小样本学习、主动学习和可解释判废机制,实现高精度视觉检测;2)预测性维护与运维Copilot系统,结合RUL预测和知识增强生成技术,构建从设备监测到智能工单的闭环。实践案例显示,AI质检可使召回率提升至98%,预测性维护能减少45%计划外停机。
引言:智能制造必须拥抱 AI
21 世纪第三个十年,智能制造正面临前所未有的挑战与机遇。随着全球供应链波动、人工成本攀升以及产品复杂度持续增加,传统制造企业的“人海战术”与“经验驱动”模式已经难以为继。如何在保证产品质量的同时提升生产效率与柔性,是摆在每一个制造企业面前的关键问题。
与此同时,人工智能技术,尤其是近两年大规模语言模型(Large Language Models, LLMs)与多模态模型(VLMs)的突破,正在深刻改变软件开发、知识获取、甚至人机协作的方式。制造业天然是“数据密集 + 知识密集”的行业:从设备传感器到工艺参数,从质检图像到维修手册,蕴含了大量结构化与非结构化数据。AI 技术为这些沉睡数据注入了新价值,让工厂具备了“学习、预测和自我优化”的能力。
如果说传统工业 4.0 强调“互联与自动化”,那么在 AI 时代,智能制造则迈向了“自感知、自决策、自优化”的 工业 5.0。这不仅是技术升级,更是生产范式的深刻重塑。
本文将聚焦两个典型场景:
-
主题一:零缺陷质检 2.0 —— 以多模态大模型驱动的端到端视觉质检,探索如何在长尾缺陷、小样本标注的环境中实现可解释判废与持续优化;
-
主题二:预测性维护与运维 Copilot —— 以剩余寿命预测(RUL)与知识增强生成(RAG)为核心,构建从报警到工单的闭环,迈向自愈工厂。
这两个主题既切中智能制造的核心痛点,也覆盖了本次征文的重点子方向(AI 工具、行业应用、大模型落地、AI 编程与测试)。通过实战经验与案例剖析,我们希望呈现一幅清晰的路线图:如何将 AI 从实验室推向车间,从概念验证推向规模落地。
主题一:零缺陷质检 2.0 —— 多模态大模型驱动的端到端视觉质检
1. 行业痛点与现状
在制造业质检环节,常见的问题包括:
-
长尾缺陷:样本数量极少,但一旦漏检,损失巨大;
-
小样本难题:缺陷图像难以收集和标注,数据不均衡;
-
误判代价高:误拒会增加报废率,误放则导致客户投诉;
-
不可解释:传统模型只能给出“好/坏”,无法告诉工艺人员问题源头。
因此,下一代质检系统必须具备:
-
高召回率 —— 不漏检关键缺陷;
-
低误判率 —— 避免不必要的报废;
-
可解释性 —— 能告诉质检员“缺陷是什么、可能来自哪道工序”;
-
可持续优化 —— 随着工艺和设备变化自动进化。
2. 数据准备与增强
数据是质检 AI 的基石。真实工厂里,缺陷样本往往很少。解决办法有:
-
数据增强:旋转、裁剪、光照变换;
-
合成数据:利用 GAN 或渲染引擎生成缺陷图像;
-
主动学习:让模型挑出最不确定的样本,由人工标注后回流。
示例代码:
import torchvision.transforms as transforms
from PIL import Image
# 针对制造业图像的常用增强
transform = transforms.Compose([
transforms.Resize((224, 224)),
transforms.RandomRotation(15), # 模拟不同拍摄角度
transforms.ColorJitter(brightness=0.3, contrast=0.3), # 光照变化
transforms.RandomHorizontalFlip(),
transforms.ToTensor()
])
img = Image.open("scratch_sample.jpg")
aug_img = transform(img)
这样,我们就能从 50 张划痕样本扩充到几百张,缓解小样本问题。
3. 基础质检模型:轻量级分类/分割
先从最小可行版本做起:用预训练模型(ResNet18 / MobileNetV3)进行二分类(正常 / 缺陷)。
import torch
import torch.nn as nn
from torchvision import models
# 使用预训练 ResNet18 微调
model = models.resnet18(pretrained=True)
model.fc = nn.Linear(model.fc.in_features, 2) # 二分类
criterion = nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(model.parameters(), lr=1e-4)
# 训练循环
for epoch in range(5):
for imgs, labels in train_loader:
outputs = model(imgs)
loss = criterion(outputs, labels)
optimizer.zero_grad()
loss.backward()
optimizer.step()
print(f"Epoch {epoch}, Loss: {loss.item():.4f}")
如果需要精确定位缺陷位置,可以改用 分割模型(如 U-Net、Segment-Anything,SAM)。
# 伪代码:调用 SAM API 做缺陷分割
from segment_anything import sam_model_registry, SamPredictor
sam = sam_model_registry["vit_b"](checkpoint="sam_vit_b.pth")
predictor = SamPredictor(sam)
predictor.set_image(img_array)
masks, scores, logits = predictor.predict(point_coords=[[100, 200]], point_labels=[1])
4. 多模态大模型赋能:可解释判废
单纯分类还不够,质检员常常追问:
-
这是哪类缺陷?
-
可能由哪道工序引起?
-
应该如何处理?
这里可以引入 CLIP 模型(图文对齐大模型),让模型输出“判废理由”。
from transformers import CLIPProcessor, CLIPModel
from PIL import Image
model = CLIPModel.from_pretrained("openai/clip-vit-base-patch32")
processor = CLIPProcessor.from_pretrained("openai/clip-vit-base-patch32")
image = Image.open("defect_sample.jpg")
texts = ["表面正常", "表面有划痕", "表面有污渍", "表面有凹坑"]
inputs = processor(text=texts, images=image, return_tensors="pt", padding=True)
outputs = model(**inputs)
probs = outputs.logits_per_image.softmax(dim=1)
for t, p in zip(texts, probs[0]):
print(f"{t}: {p.item():.4f}")
输出结果:
表面正常: 0.02
表面有划痕: 0.93
表面有污渍: 0.04
表面有凹坑: 0.01
我们可以进一步结合 RAG(Retrieval-Augmented Generation),让模型检索工艺文档,自动生成判废报告:
def generate_defect_report(defect_type):
knowledge_base = {
"划痕": "可能原因:抛光工序异常;处置建议:检查抛光刀具磨损情况。",
"污渍": "可能原因:清洗不彻底;处置建议:检查清洗液浓度与更换频率。",
}
return knowledge_base.get(defect_type, "未知缺陷,请人工复核。")
print(generate_defect_report("划痕"))
5. 模型回归测试与上线
制造业质检系统必须稳定可靠。每次模型更新都要跑 回归测试,确保新版本不会比旧版本差。
def evaluate(model, dataloader):
model.eval()
correct, total = 0, 0
with torch.no_grad():
for imgs, labels in dataloader:
outputs = model(imgs)
_, preds = torch.max(outputs, 1)
correct += (preds == labels).sum().item()
total += labels.size(0)
return correct / total
acc_old = evaluate(old_model, val_loader)
acc_new = evaluate(new_model, val_loader)
print("旧模型准确率:", acc_old)
print("新模型准确率:", acc_new)
if acc_new < acc_old:
print("⚠️ 新模型性能退化,禁止上线!")
6. 数据闭环:从人工复核到主动学习
真实生产线中,AI 模型不可能 100% 准确,因此需要构建 人工复核闭环:
-
AI 输出结果 + 置信度;
-
质检员确认/纠正;
-
数据回流,用于二次训练。
主动学习代码示例(挑选最不确定样本):
import torch
def select_uncertain_samples(model, dataloader, k=10):
uncertainties = []
for imgs, _ in dataloader:
outputs = model(imgs)
probs = torch.softmax(outputs, dim=1)
entropy = -torch.sum(probs * torch.log(probs + 1e-6), dim=1)
uncertainties.extend(entropy.tolist())
# 返回熵值最高的前k个样本索引
return sorted(range(len(uncertainties)), key=lambda i: uncertainties[i], reverse=True)[:k]
这样就能把最有价值的样本交给人工标注,提升迭代效率。
7. 案例分析
在某 PCB 制造企业,引入 AI 质检后:
-
召回率:由 85% 提升到 98%;
-
误拒率:降低 40%,每年减少报废损失约 500 万元;
-
质检报告:通过大模型解释模块,质检员复核效率提升 30%。
8. 风险与挑战
-
数据安全:需保证客户图纸和缺陷样本不外泄,本地化部署尤为重要;
-
模型漂移:工艺更改可能导致模型精度下降,需要持续监控;
-
人机协作:AI 不应替代质检员,而是“助手”,避免过度依赖。
小结
“质检 2.0”不是单一算法,而是 数据采集—模型训练—大模型解释—闭环优化 的全流程升级。通过多模态大模型与主动学习,制造企业可以实现 高精度、可解释、可持续进化的零缺陷质检。
主题二:自愈工厂的第一步 —— 预测性维护(PdM)与运维 Copilot
1. 背景与业务价值
在传统制造中,设备维护主要有两种模式:
-
被动维修:设备坏了才修,容易造成计划外停机;
-
定期保养:按固定周期检修,但往往过度维护或不及时。
这两种方式都效率低,容易带来 高昂的停机成本。根据麦肯锡数据,全球制造业因计划外停机造成的损失每年超过 1 万亿美元。
预测性维护(Predictive Maintenance, PdM)的目标是:
-
预测剩余寿命(RUL):告诉你设备还能跑多久;
-
提前告警:在设备出问题前给出维护建议;
-
智能工单:自动生成维修步骤、备件清单,让工程师执行更高效。
而随着大模型的出现,PdM 不再只是“异常检测 + RUL 预测”,而是能结合工厂的 维修手册、历史工单、备件库,生成一份完整的 运维 Copilot。
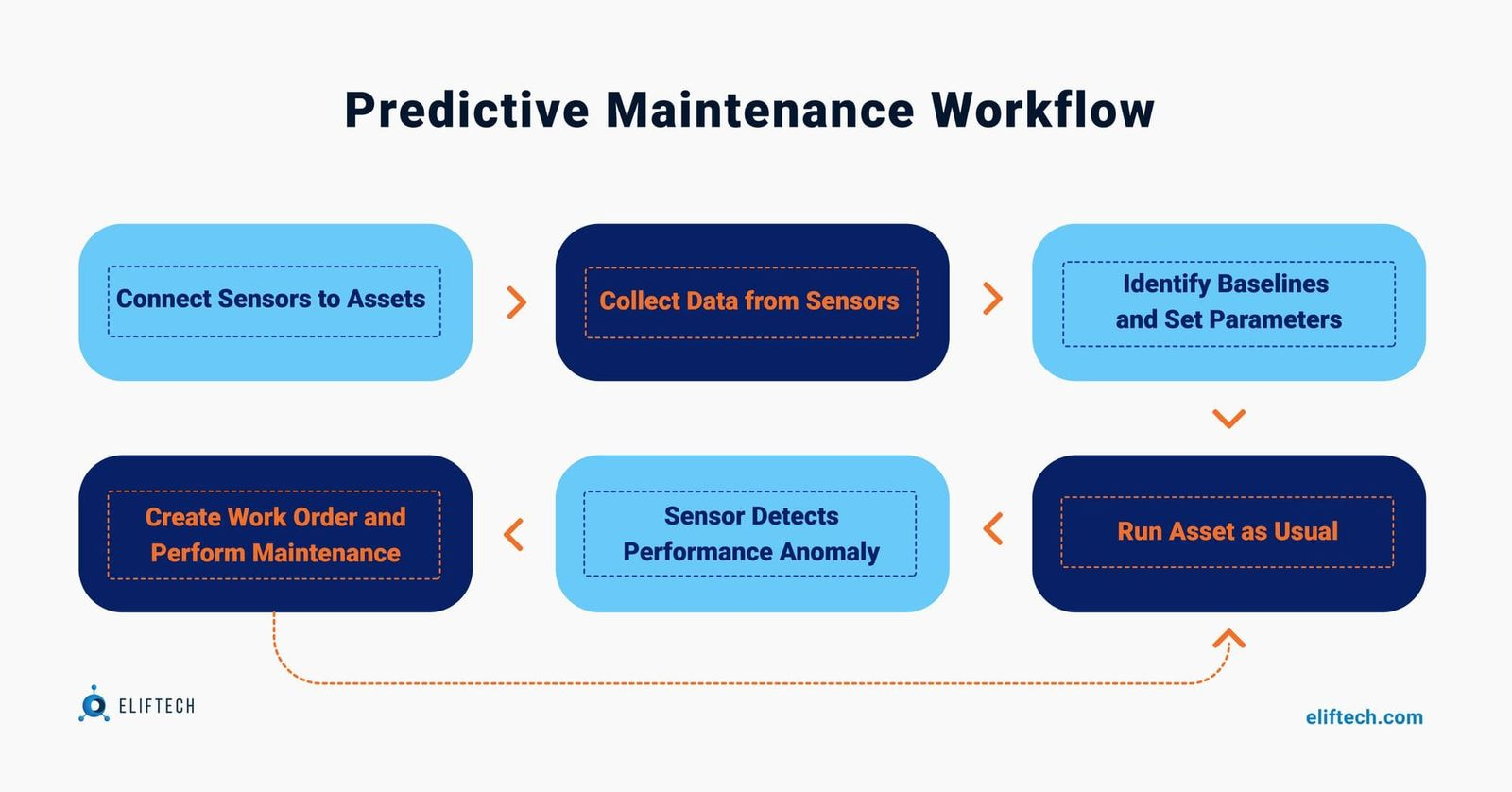
2. 数据采集与特征工程
2.1 常见传感器数据
-
振动(加速度/速度):常用于轴承、齿轮箱监测;
-
电流、电压:用于电机健康分析;
-
温度:常用于高温设备和润滑油状态;
-
转速、压力、流量:辅助诊断。
2.2 时频域特征提取
import numpy as np
from scipy.signal import welch
# 振动信号样本
signal = np.random.randn(2048)
# 频域特征(功率谱密度)
freqs, psd = welch(signal, fs=1000)
# 常用特征
mean = np.mean(signal)
std = np.std(signal)
rms = np.sqrt(np.mean(signal**2))
print(f"Mean={mean:.4f}, STD={std:.4f}, RMS={rms:.4f}")
在真实工厂中,我们会计算几十个特征(时域+频域+时频域),再通过 PCA/AutoEncoder 降维。
3. 异常检测
当缺乏完整的故障标签时,可以先做 无监督异常检测。
示例:利用 AutoEncoder 学习正常工况,再用重建误差识别异常。
import torch
import torch.nn as nn
class AutoEncoder(nn.Module):
def __init__(self):
super().__init__()
self.encoder = nn.Sequential(
nn.Linear(100, 32), nn.ReLU(),
nn.Linear(32, 8), nn.ReLU()
)
self.decoder = nn.Sequential(
nn.Linear(8, 32), nn.ReLU(),
nn.Linear(32, 100), nn.Sigmoid()
)
def forward(self, x):
z = self.encoder(x)
return self.decoder(z)
model = AutoEncoder()
criterion = nn.MSELoss()
在预测阶段:
-
重建误差大 → 异常;
-
重建误差小 → 正常。
4. RUL 预测(剩余寿命预测)
4.1 基线模型:XGBoost
import xgboost as xgb
import pandas as pd
from sklearn.metrics import mean_absolute_error
# 特征与RUL标签
X = pd.read_csv("features.csv")
y = pd.read_csv("labels.csv")
model = xgb.XGBRegressor(n_estimators=100, max_depth=5)
model.fit(X, y)
y_pred = model.predict(X)
print("MAE:", mean_absolute_error(y, y_pred))
4.2 深度学习模型:LSTM
适合时序数据,能捕捉退化趋势。
class RUL_LSTM(nn.Module):
def __init__(self):
super().__init__()
self.lstm = nn.LSTM(input_size=16, hidden_size=64, batch_first=True)
self.fc = nn.Linear(64, 1)
def forward(self, x):
out, _ = self.lstm(x)
return self.fc(out[:, -1, :])
在实际部署中,可以用 Temporal Fusion Transformer (TFT),效果更佳。
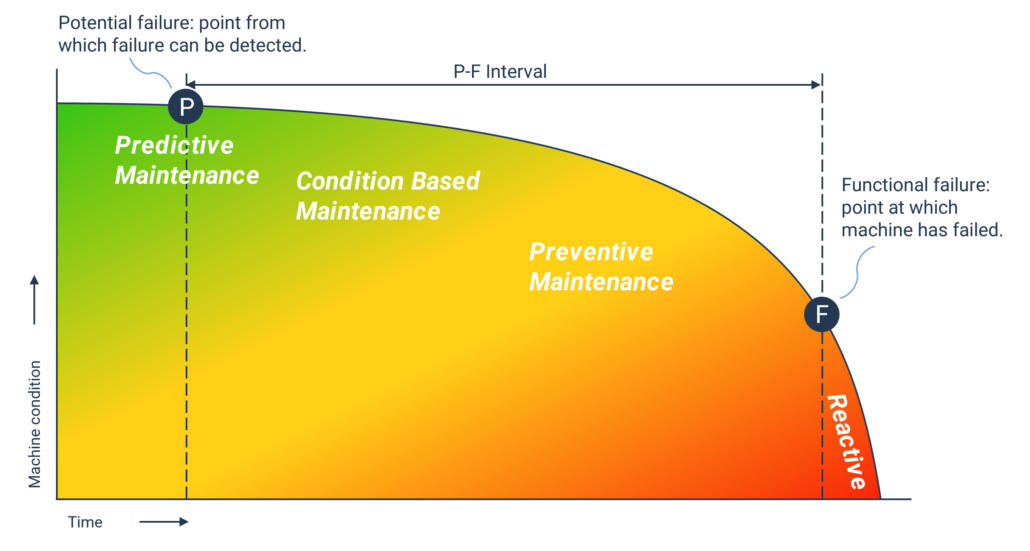
5. 运维 Copilot —— 从告警到工单
预测到设备异常后,下一步是“怎么办”。传统 PdM 只给报警,不给方案。大模型可以补上最后一公里。
5.1 构建知识库(RAG)
-
数据源:维修手册、历史工单、备件库(BOM)、SOP 文档;
-
存储:向量化后放入 FAISS/Milvus;
-
检索:根据“异常类型 + 置信度 + 特征模式”检索相关段落。
5.2 提示词工程
提示词:
根据以下信息生成维修工单:
- 设备型号:XYZ-100
- 预测RUL:20小时
- 异常症状:轴承高频振动
请输出:故障可能原因、维修步骤、所需工具、备件SKU。
5.3 RAG + 生成示例代码
from langchain.vectorstores import FAISS
from langchain.embeddings import OpenAIEmbeddings
from langchain.chains import RetrievalQA
from langchain.llms import OpenAI
embeddings = OpenAIEmbeddings()
docsearch = FAISS.load_local("faiss_index", embeddings)
qa = RetrievalQA.from_chain_type(
llm=OpenAI(),
retriever=docsearch.as_retriever()
)
query = "轴承高频振动,RUL小于20小时"
result = qa.run(query)
print(result)
输出可能是:
故障可能原因:润滑不足或轴承磨损
维修步骤:1. 停机检查润滑脂;2. 拆卸轴承;3. 更换型号6205的轴承
所需工具:扳手、轴承拉拔器
备件SKU:BRG-6205
这样,维护工程师可以直接拿着 AI 生成的工单去执行,大幅缩短诊断时间。
6. 边缘-云协同与 MLOps
在制造场景中,延迟与稳定性至关重要:
-
边缘推理:在产线旁边的边缘服务器上部署模型,保证毫秒级响应;
-
云端管理:集中存储数据,进行模型训练与回放测试;
-
MLOps 流程:版本控制、自动化回归测试、模型回滚。
代码示例:ONNX/TensorRT 导出模型
dummy_input = torch.randn(1, 50, 16) # batch=1, 序列长度50, 特征16
torch.onnx.export(model, dummy_input, "rul_model.onnx")
7. 评估与业务指标
除了模型精度,还要关注 制造 KPI:
-
MAE/RMSE:预测 RUL 的误差;
-
提前量(Lead Time):报警比实际故障提前多少小时;
-
MTBF(平均无故障时间) ↑
-
MTTR(平均修复时间) ↓
-
OEE(整体设备效率) ↑
8. 案例分析
在某汽车零部件工厂,引入 PdM + 运维 Copilot 后:
-
设备计划外停机次数 ↓ 45%;
-
平均无故障时间(MTBF) ↑ 30%;
-
维修工单生成效率提升 50%;
-
备件库存占用减少 20%。
9. 风险与挑战
-
数据不一致:不同设备型号,传感器数据格式差异大;
-
冷启动问题:新设备缺少历史故障数据;
-
误报/漏报:需要灰度上线,避免过早推广;
-
工程师信任:Copilot 输出必须可解释,并保留人工复核环节。
小结
预测性维护不仅是“预测故障”,而是构建一个 从异常检测 → RUL 预测 → 运维 Copilot → 工单执行 的闭环。结合大模型与知识增强(RAG),工厂可以从“设备坏了再修”,进化为“提前预防 + 智能工单”,真正迈向 自愈工厂。
结语:与 AI 共舞,迈向智能制造的未来
智能制造的核心目标,从来不是单纯的“机器换人”,而是追求 更高的质量、更低的成本、更快的交付、更强的柔性。在本文中,我们从两个典型场景切入:
-
零缺陷质检 2.0:通过多模态大模型与主动学习,让质检从“发现问题”升级为“解释问题、反馈改进”,真正实现 高召回、低误判、可解释、可持续优化;
-
预测性维护 + 运维 Copilot:通过异常检测、RUL 预测与知识增强检索(RAG),让设备从“坏了再修”转向“提前预防 + 智能工单”,为 自愈工厂 打下第一块基石。
这两大方向恰好代表了智能制造的两条主线:产品质量保障与设备健康保障。如果说质检 2.0 解决的是“出厂质量”的问题,那么 PdM 则是保障“生产连续性”的关键。这两者的共同点在于:
-
数据驱动:质检依赖图像数据,PdM 依赖时序传感器数据;
-
模型迭代:都需要持续学习和回归测试,避免模型漂移;
-
人机协作:AI 提供辅助决策,人类工程师进行最终把关;
-
闭环优化:质检环节的数据会反哺工艺改进,PdM 的工单执行会反哺模型优化。
可以看到,AI 在智能制造中的价值,不仅仅是“提高准确率”,更在于 重塑业务流程。
未来 5 年的展望
站在 2025 年的时间节点上,未来 5 年我们可以预见几大发展趋势:
-
大模型工业化:
当前的大模型多用于通用任务,但未来一定会出现更多 行业专属大模型,例如“质检大模型”、“运维大模型”。它们会在企业私有数据上微调,既懂工业术语,也懂工厂 SOP。 -
边缘智能普及:
随着边缘算力芯片(NPU/AI 加速卡)成本下降,更多 AI 模型会跑在产线边缘服务器上,实现毫秒级响应,保证实时性与稳定性。 -
数字孪生与仿真结合:
AI 模型不再只依赖历史数据,还会结合仿真系统,生成虚拟样本进行训练。例如,在 PdM 场景中,可以通过仿真制造“轴承退化曲线”,解决冷启动问题。 -
自优化工厂雏形:
当质检与维护数据进一步融合,工厂有可能实现 自我优化循环:缺陷发现 → 工艺调整 → 设备健康预测 → 动态调度 → 新一轮生产。
这将推动制造业从“人驱动”迈向“AI 辅助驱动”。 -
标准与治理框架:
随着 AI 在制造业落地,如何保障数据安全、模型可解释性、算法公平性,将成为企业必须面对的议题。未来几年,相关的国际与行业标准(如 ISO/IEC AI 标准)将逐步完善。
给开发者与从业者的建议
-
不要害怕小步试错:即使是从一个小型质检分类器、一个 XGBoost RUL 模型开始,也比停留在 PPT 更有价值。
-
拥抱工具链:Label Studio、FiftyOne、MLflow、FAISS,这些开源工具能极大降低落地成本。
-
强化人机协作思维:AI 是质检员与工程师的助手,而不是替代品。设计系统时,要始终保留人工复核与干预机制。
-
重视 MLOps 与闭环:没有持续集成与数据闭环,AI 系统很快会因漂移而失效。
-
培养跨学科能力:制造工程师要懂一些 AI,AI 工程师要懂一些制造。只有跨界,才能真正把 AI 融入生产线。
结语
正如本文所展示的,AI 技术在智能制造中的价值不再是“锦上添花”,而是成为“不可或缺”。质检 2.0 与预测性维护只是开端,未来还有更多环节将被 AI 重塑:工艺设计、生产调度、供应链优化、能源管理……
我们正在进入一个 “与 AI 共舞” 的时代。对于开发者和制造业从业者来说,最重要的不是担心 AI 会不会取代人,而是思考:如何利用 AI 放大人的能力,重塑流程,创造价值。
制造业从来是国家的命脉,而 AI 将成为它新的发动机。未来 5 年,谁能率先拥抱并善用 AI,谁就能在智能制造的浪潮中立于不败之地。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 30
30 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)