本地部署运行Dify、ollama并配置免费模型实现ai问答智能体
本地部署运行Dify、ollama并配置免费模型实现ai问答智能体
目录
环境准备
运行环境:
docker:v28.1.1
如果没有docker可以命令下载(注意这是mac命令,win10可查询资料):
brew install --cask --appdir=/Applications docker
appdir=/Applications可以改成自定义的路径
注意:需要先启动docker
1.下载并启动Dify
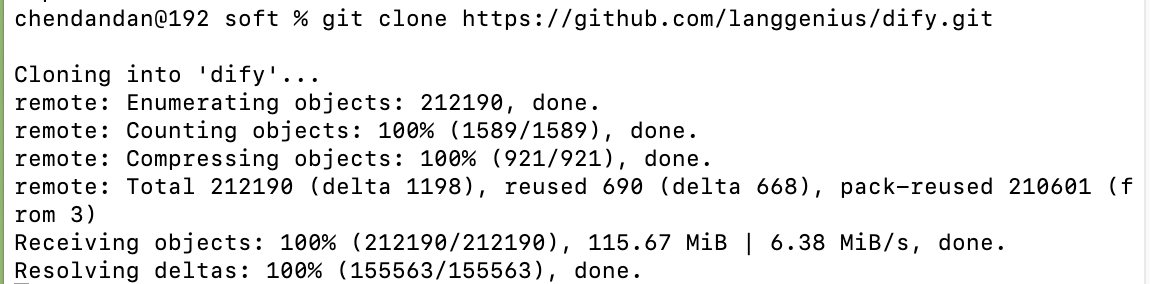
git下载dify命令
git clone https://github.com/langgenius/dify.git
进入 Dify 源代码的 docker 目录,执行一键启动命令:
cd dify/docker
cp .env.example .env
docker compose up -d
启动成功,第一次输入命令的话,会先pull,这个过程会比较慢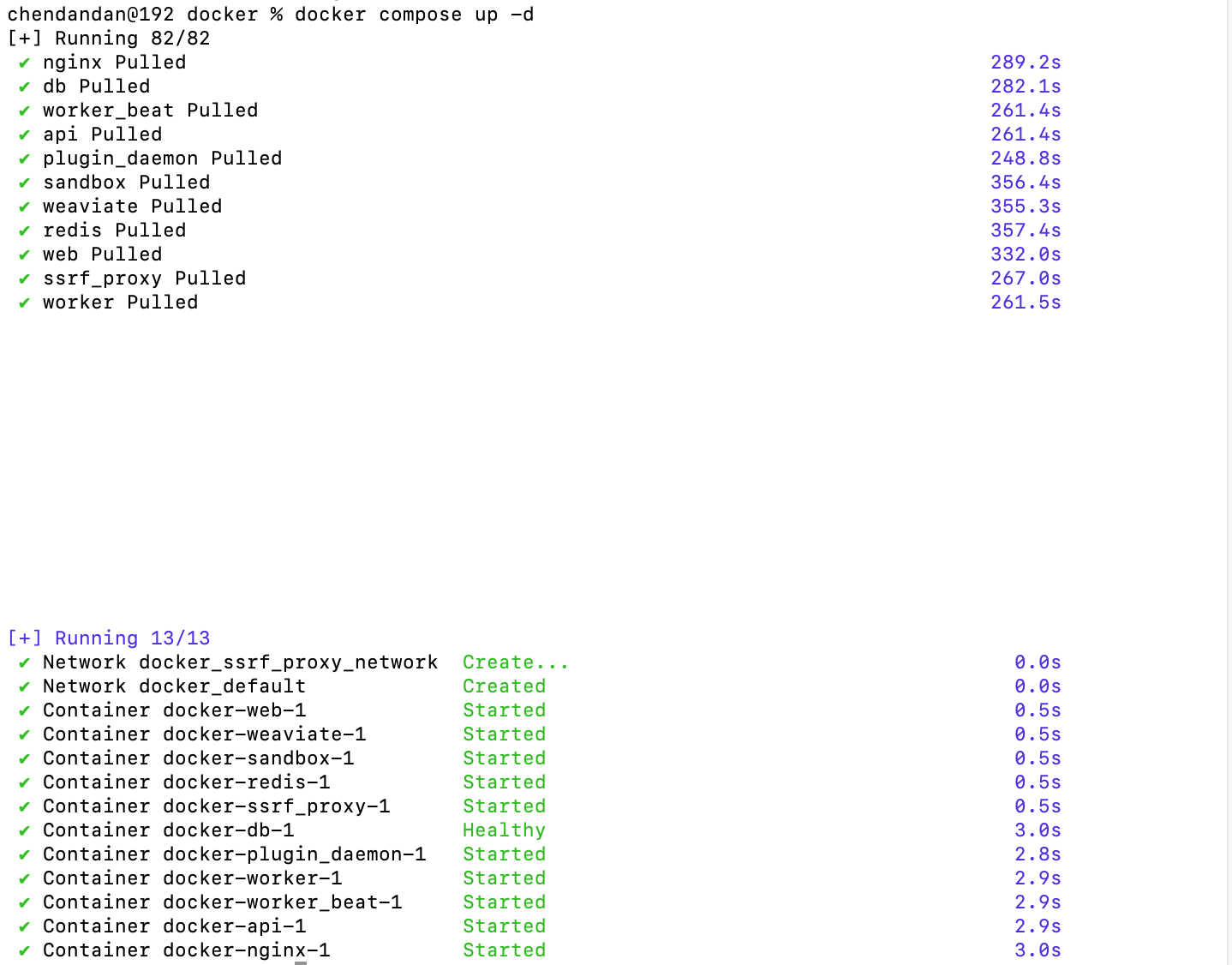
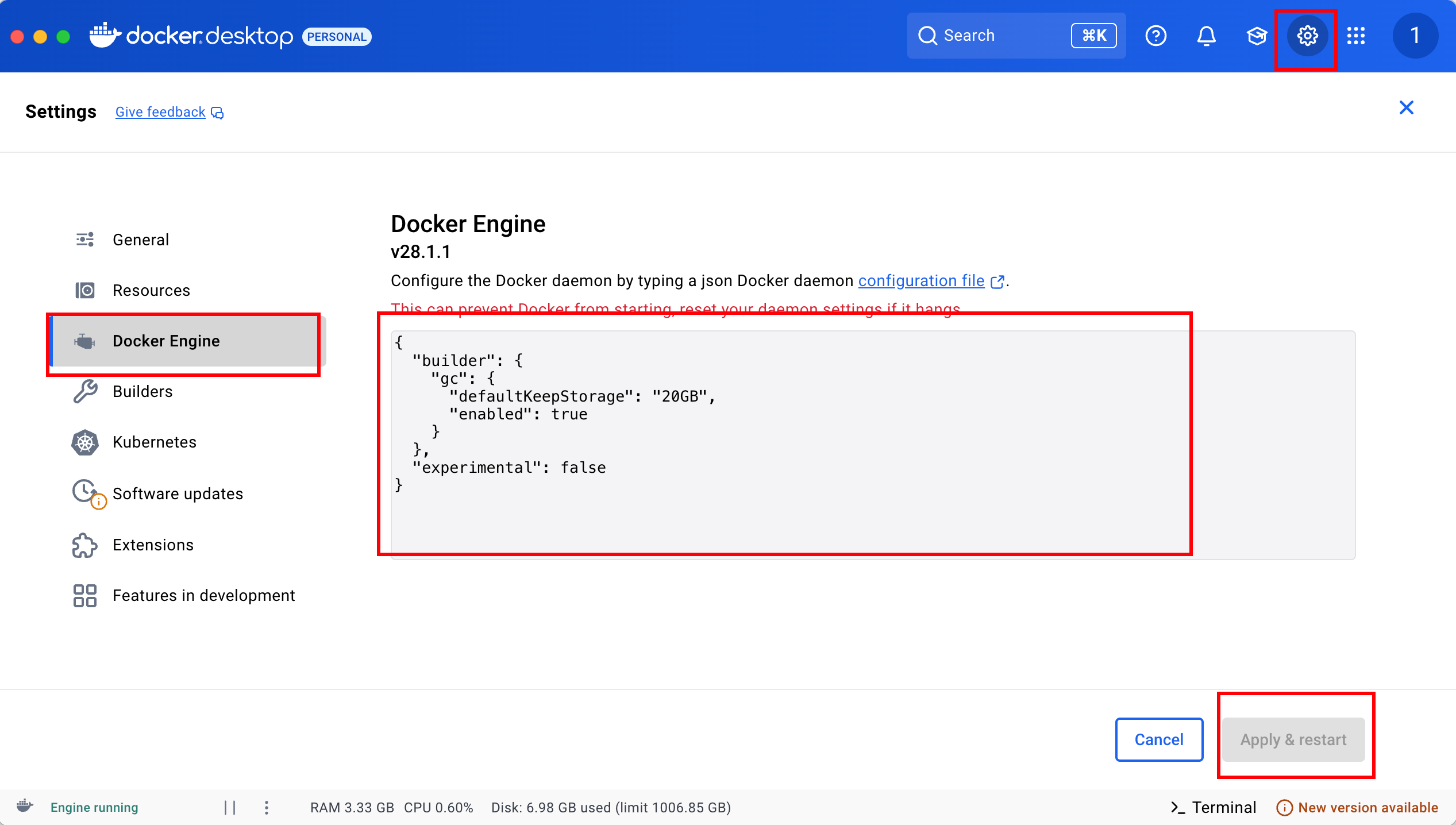
【pull失败】 如果在pull的过程中失败了,可以增加docker的镜像,因为我本身有翻墙vpn,所以这里没有配置国内镜像
启动成功后,本地访问:http://127.0.0.1
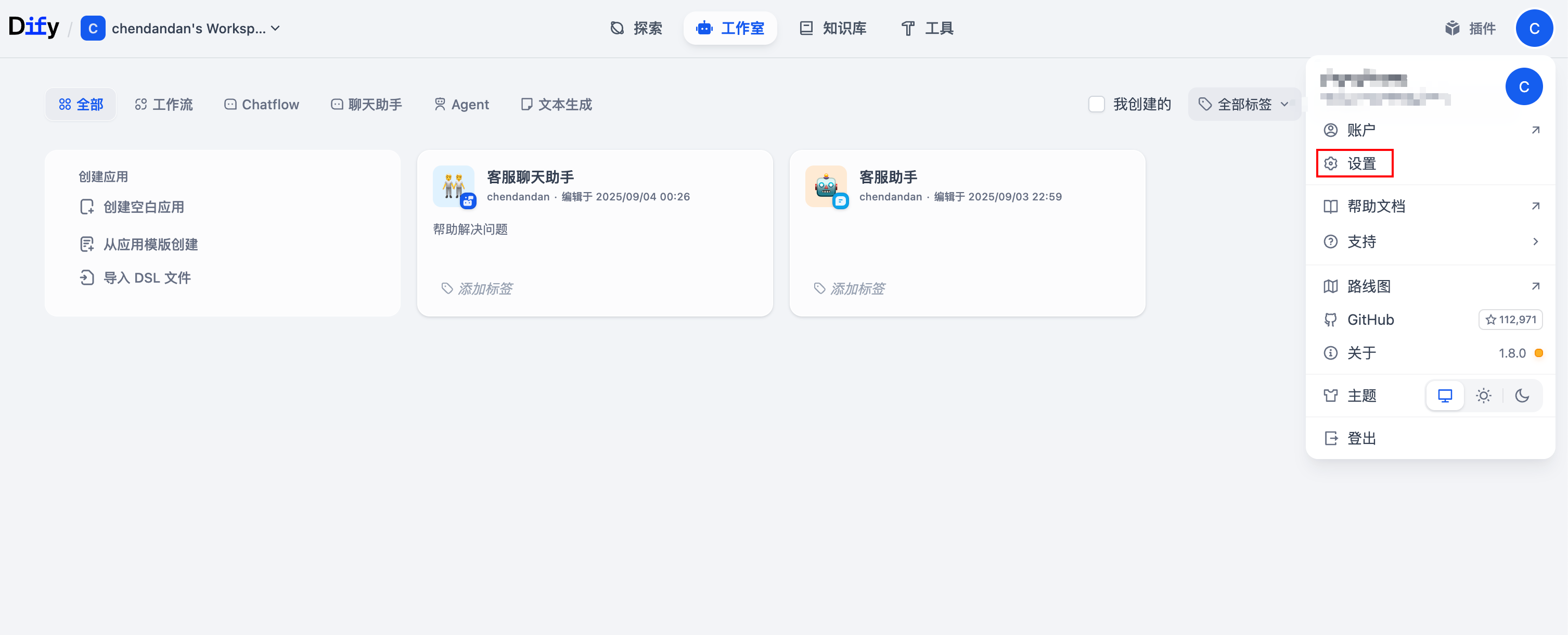
设置账号密码后进入设置:选择模型供应商
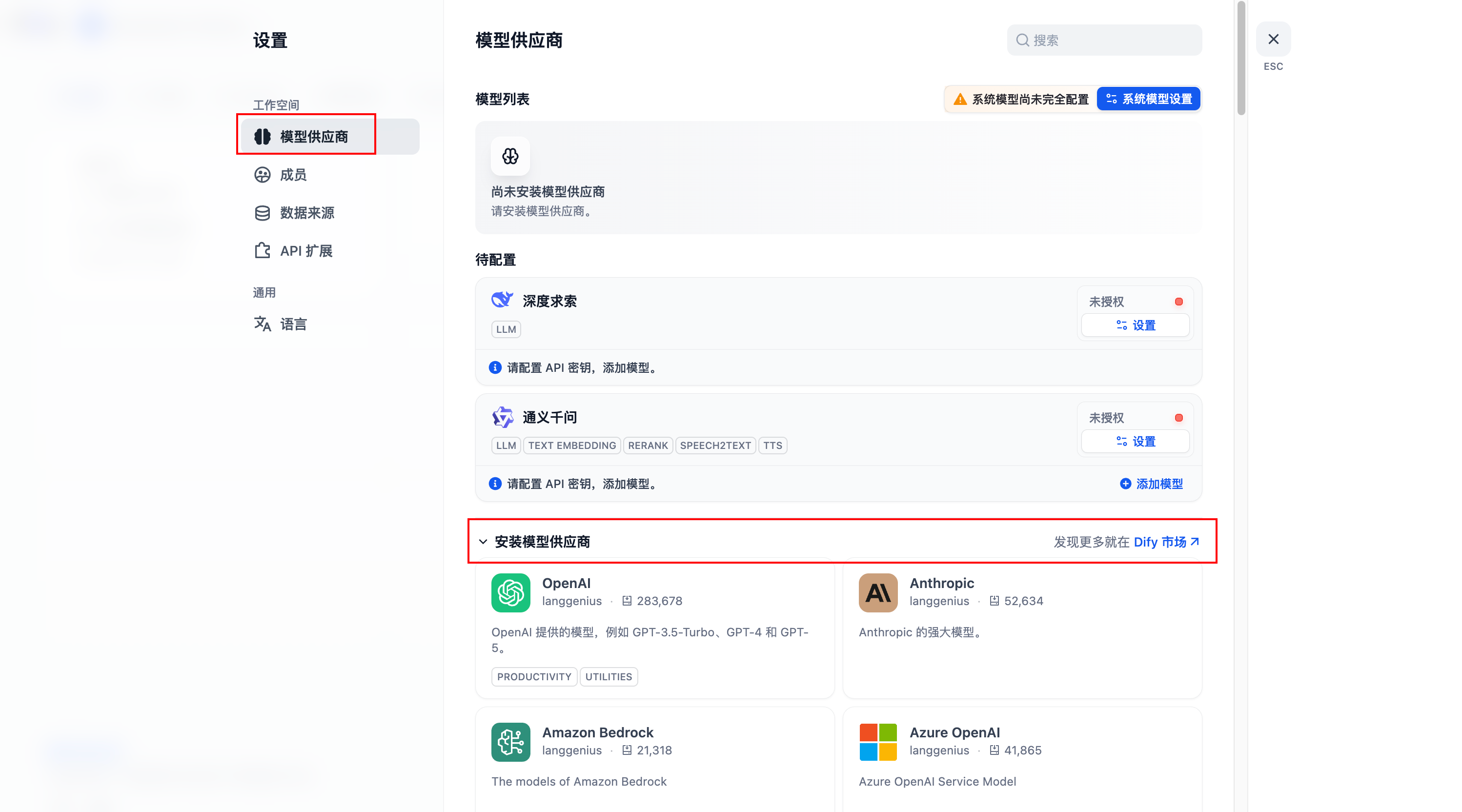
这个插件里面,比如选择了通义模型的话,是需要appkey的,这个是要钱的,如果本身就有付费的key,就可以直接输入使用了,但是咱尽量看看能不能免费使用模型呢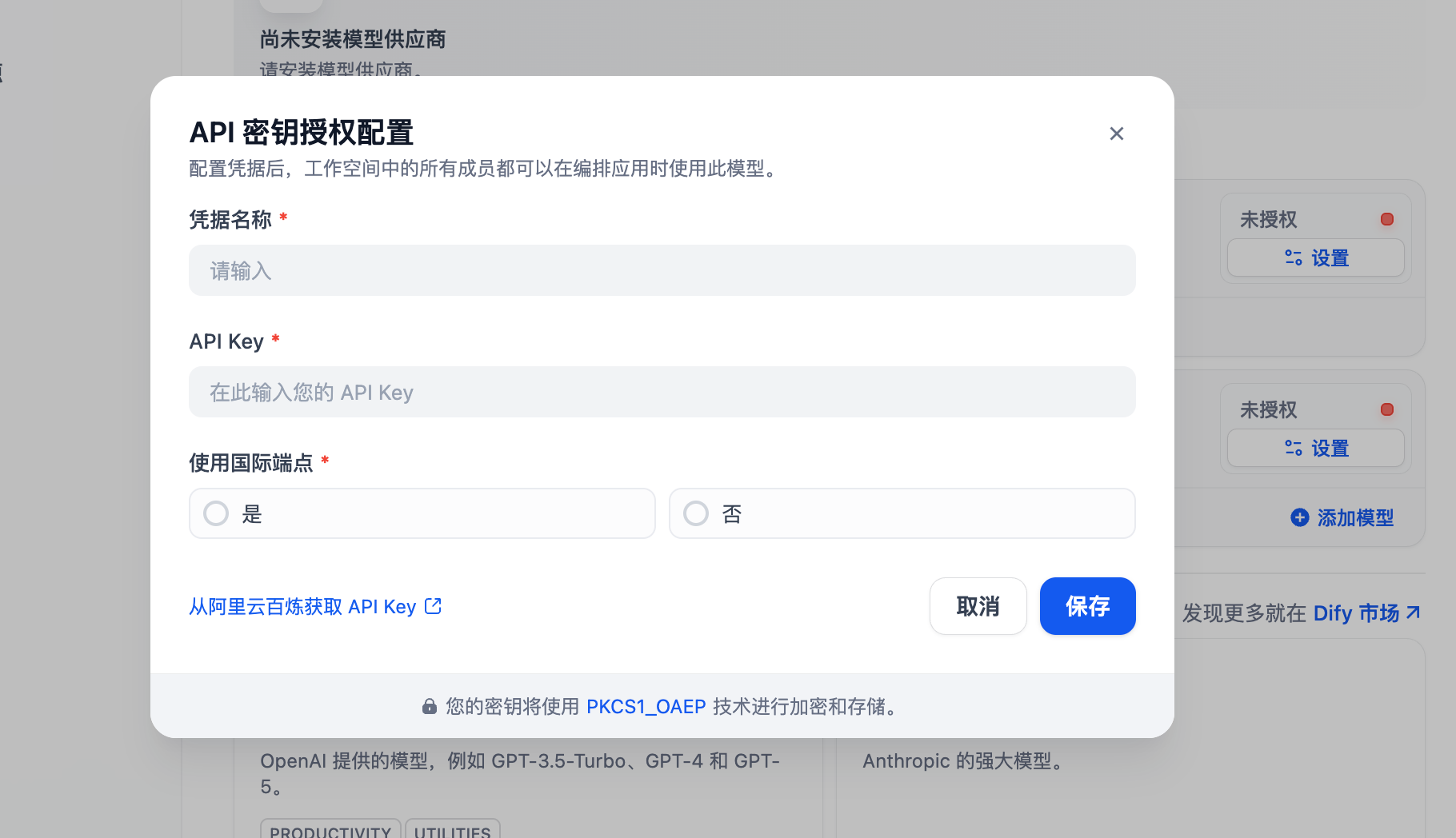
2.下载并运行ollama
访问官方直接下载:https://ollama.com/download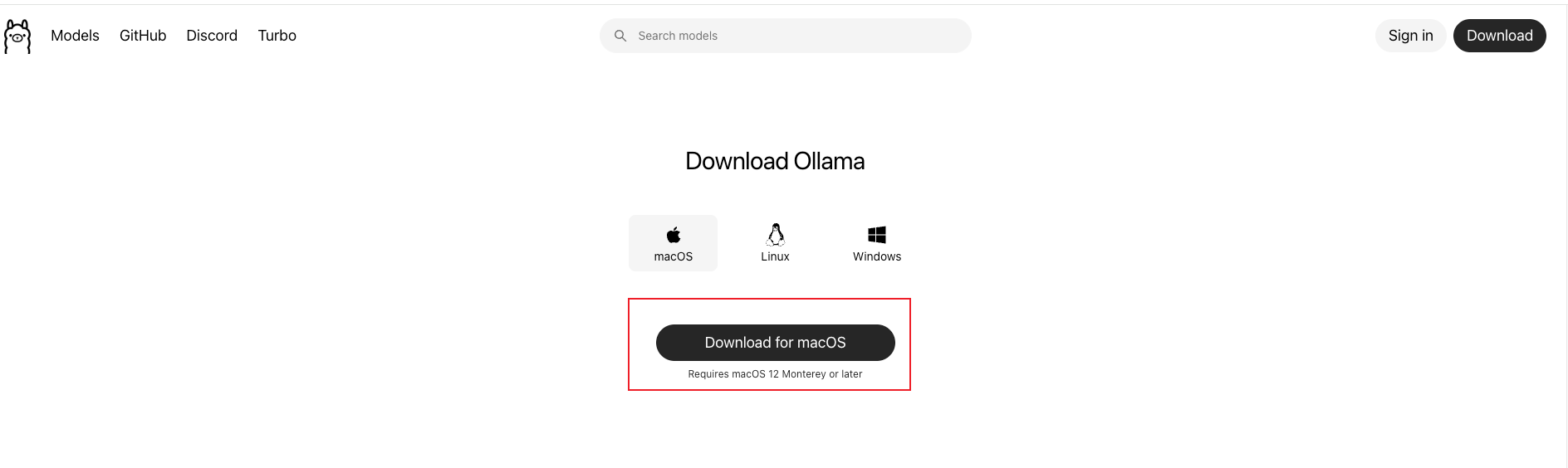
安装完成后可以下载模型,这里以一个轻量小模型为例
ollama run qwen:0.5b
ollama: 一个开源框架,用于在本地计算机上运行、管理和部署大型语言模型(LLM)
run: Ollama 的子命令,用于加载并启动一个模型,然后进入交互式聊天界面
qwen:0.5b: 要运行的特定模型
qwen: 模型名称(可能是 Qwen 或其他模型的变种)
0.5b: 表示这是 5 亿参数的版本(0.5 billion parameters)这个越大对电脑的性能配置要求就更高了
之前我有尝试过下32b,运行起来很慢
# 运行不同的模型
ollama run llama2 # 运行 Meta 的 Llama2 模型
ollama run mistral # 运行 Mistral 模型
ollama run codellama # 运行代码专用的 CodeLlama 模型
ollama run qwen:14b # 运行 140 亿参数的 Qwen 模型
下载成功后,打开ollama就会有显示在这个选项里,选择后进行测试: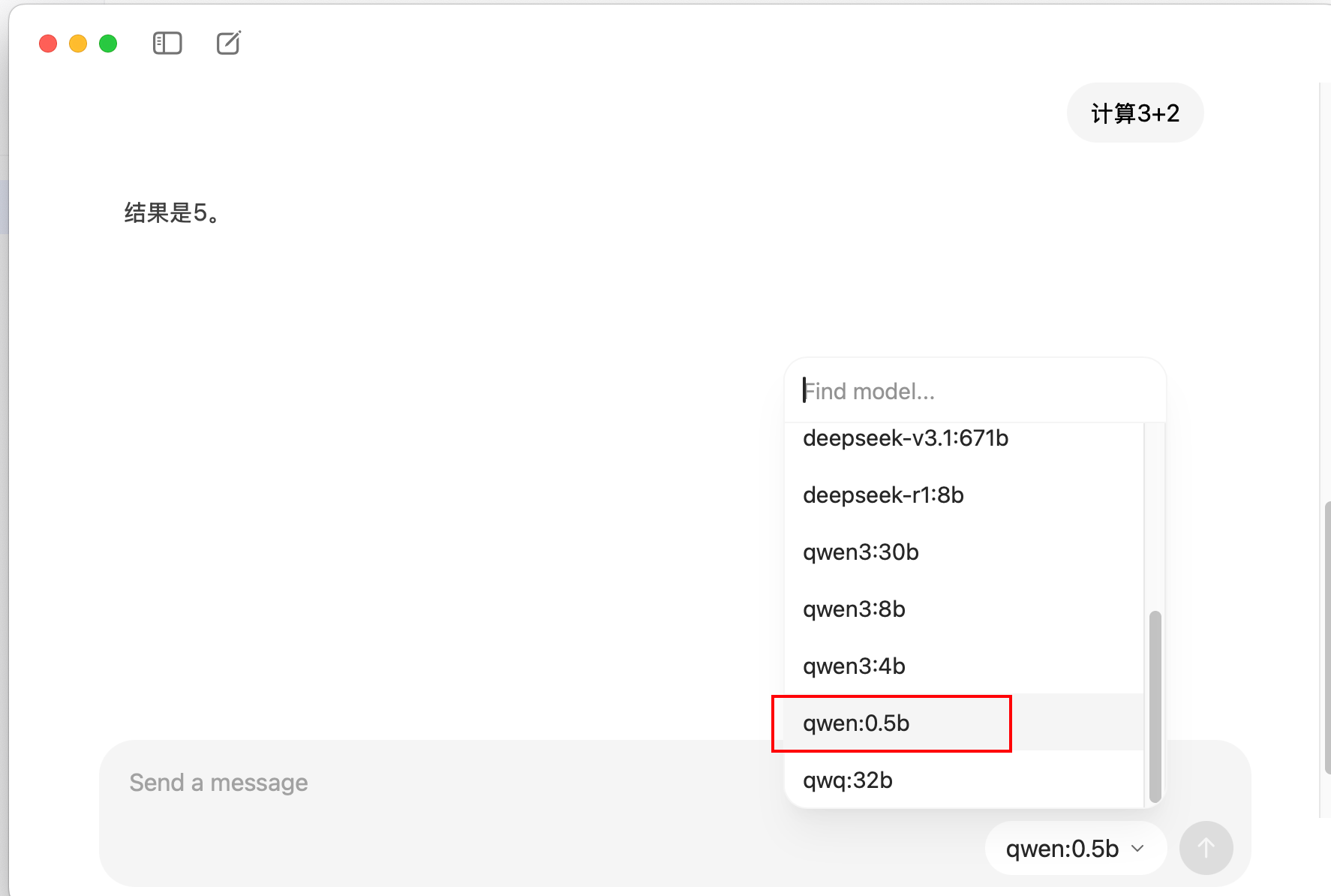
3.Dify中配置模型并创建简单聊天智能体
(1)打开Dify的设置,选择安装Ollama插件,然后添加模型
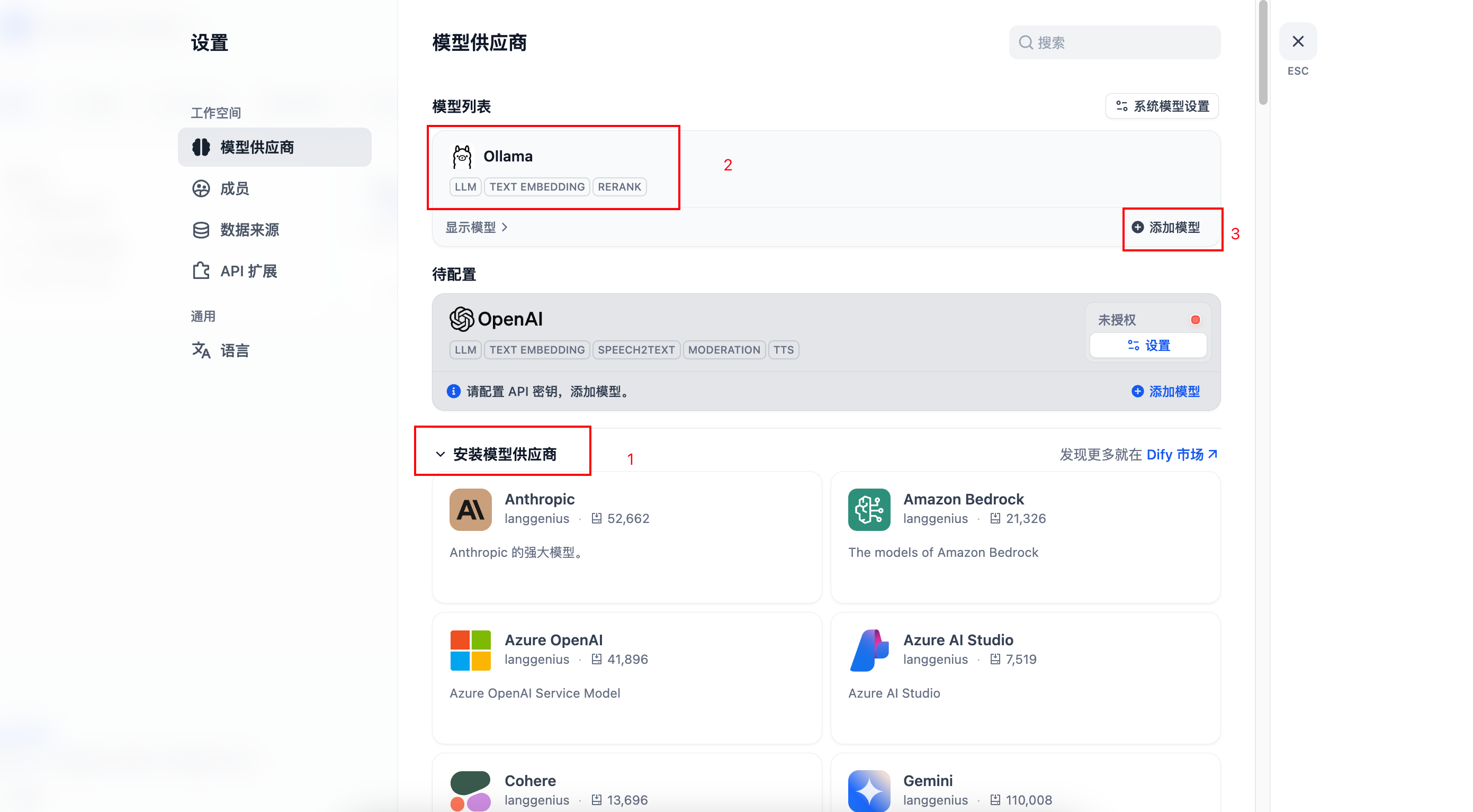
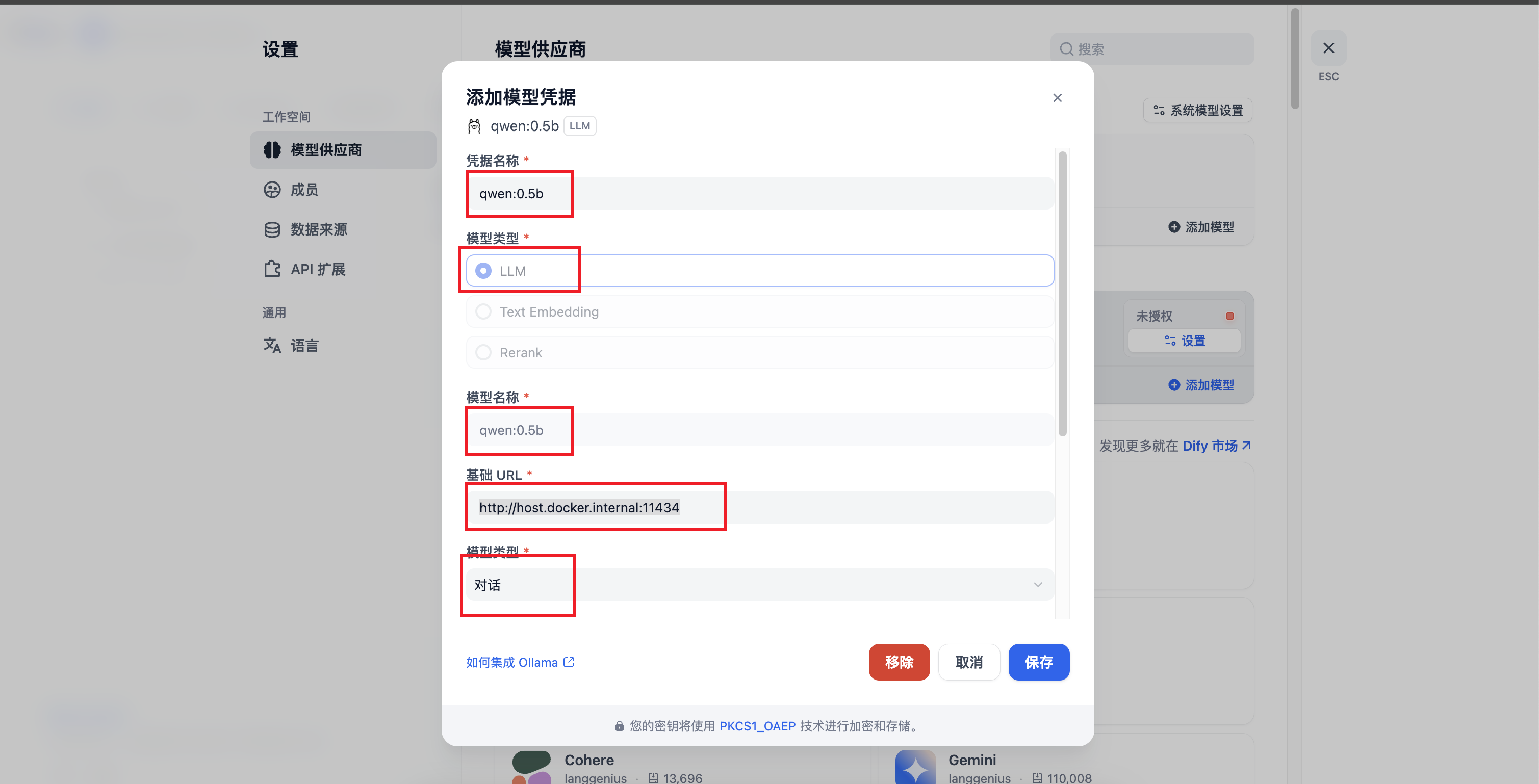
(2)配置Ollama下载好的模型
基础url输入:http://host.docker.internal:11434
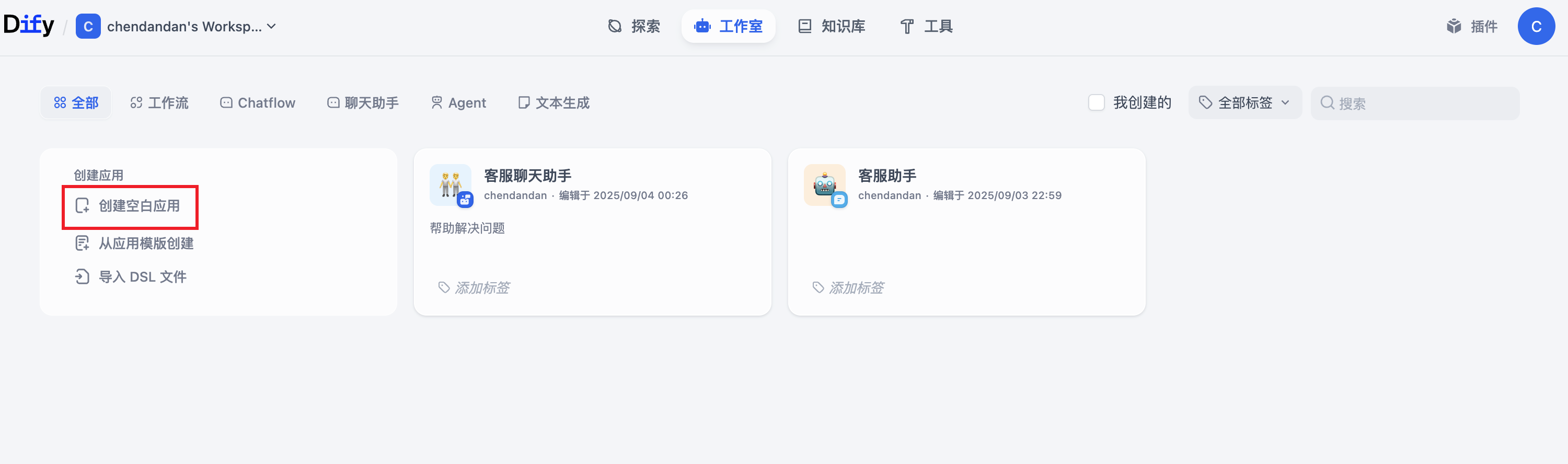
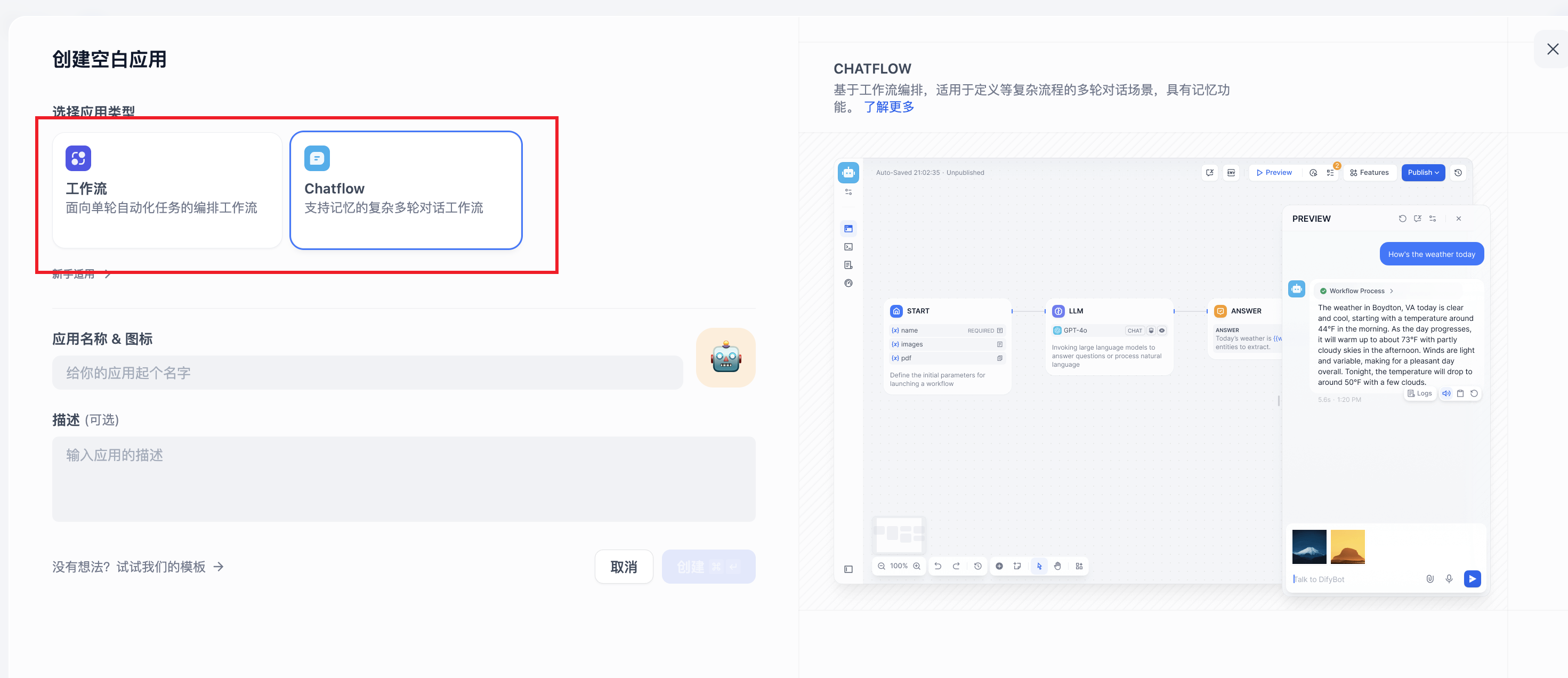
(3)保存后就可以创建一个空白应用/从应用模版中创建
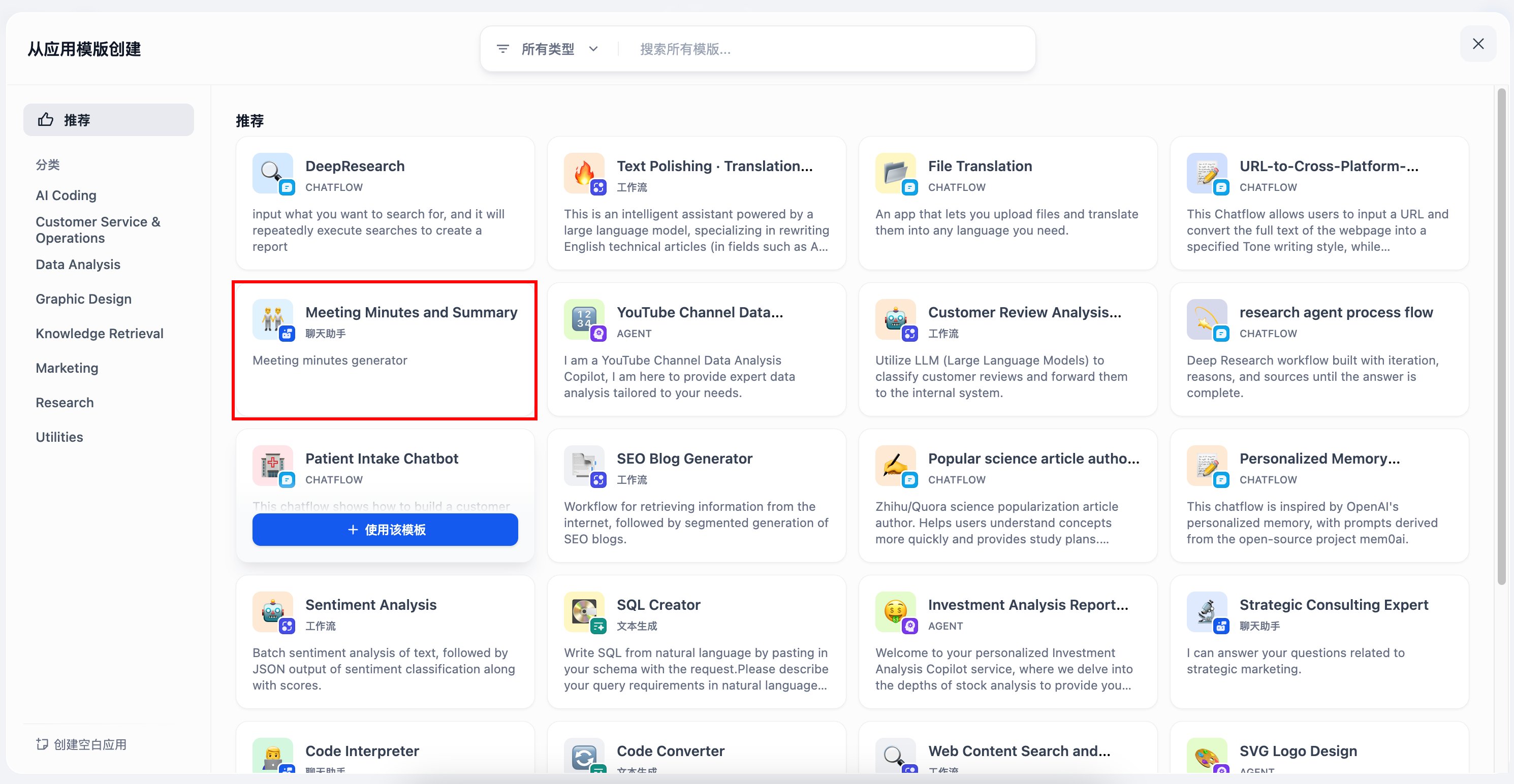
我不知道为什么现在空白应用只有两种选项(工作流/Chatflow),如果想要创建聊天机器人,就选择从应用模版中创建
选择聊天助手只要标记是聊天助手的模版就行,英文名称啥的都是可以更改的
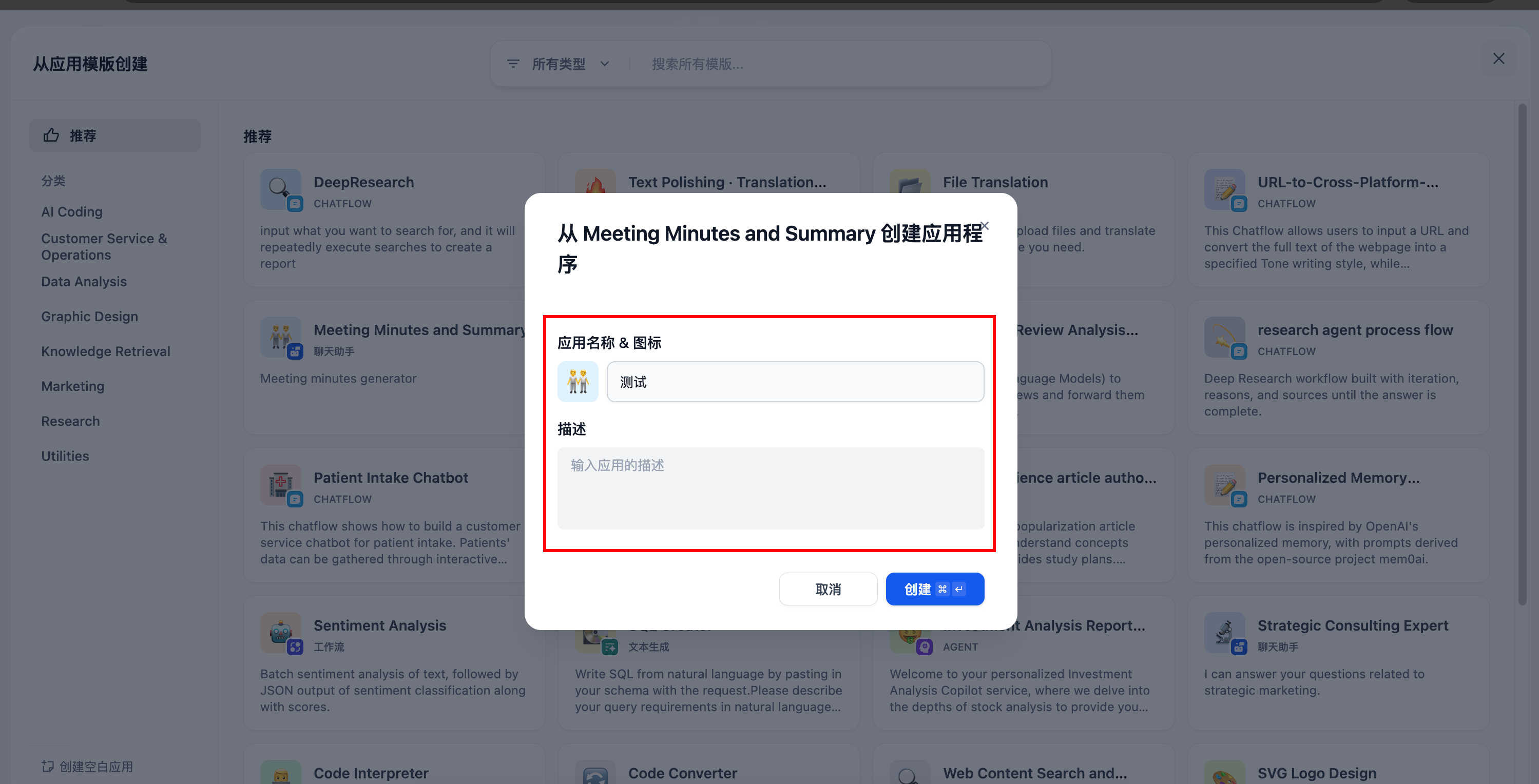
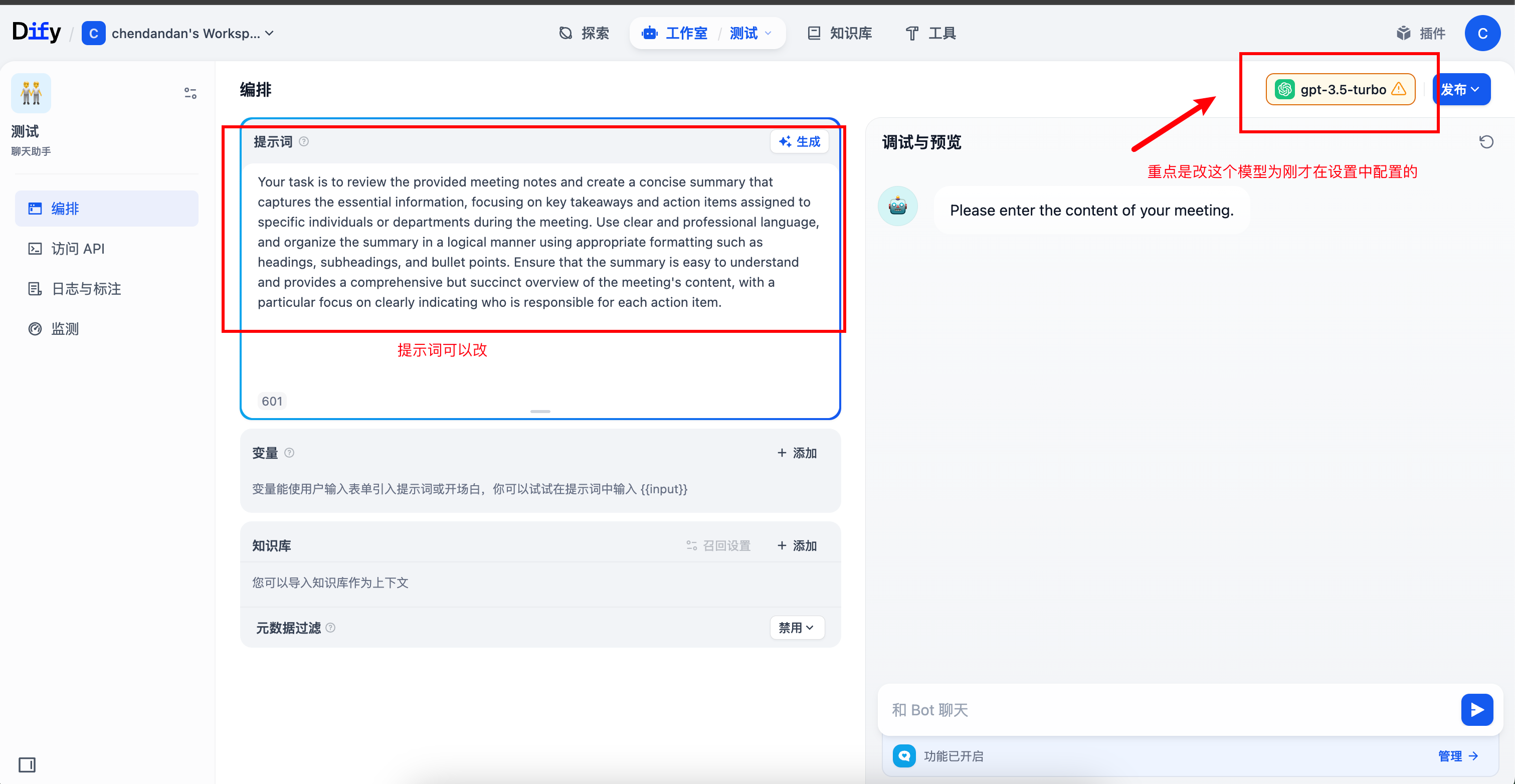
(4)创建之后,更改模型为刚才配置好的模型
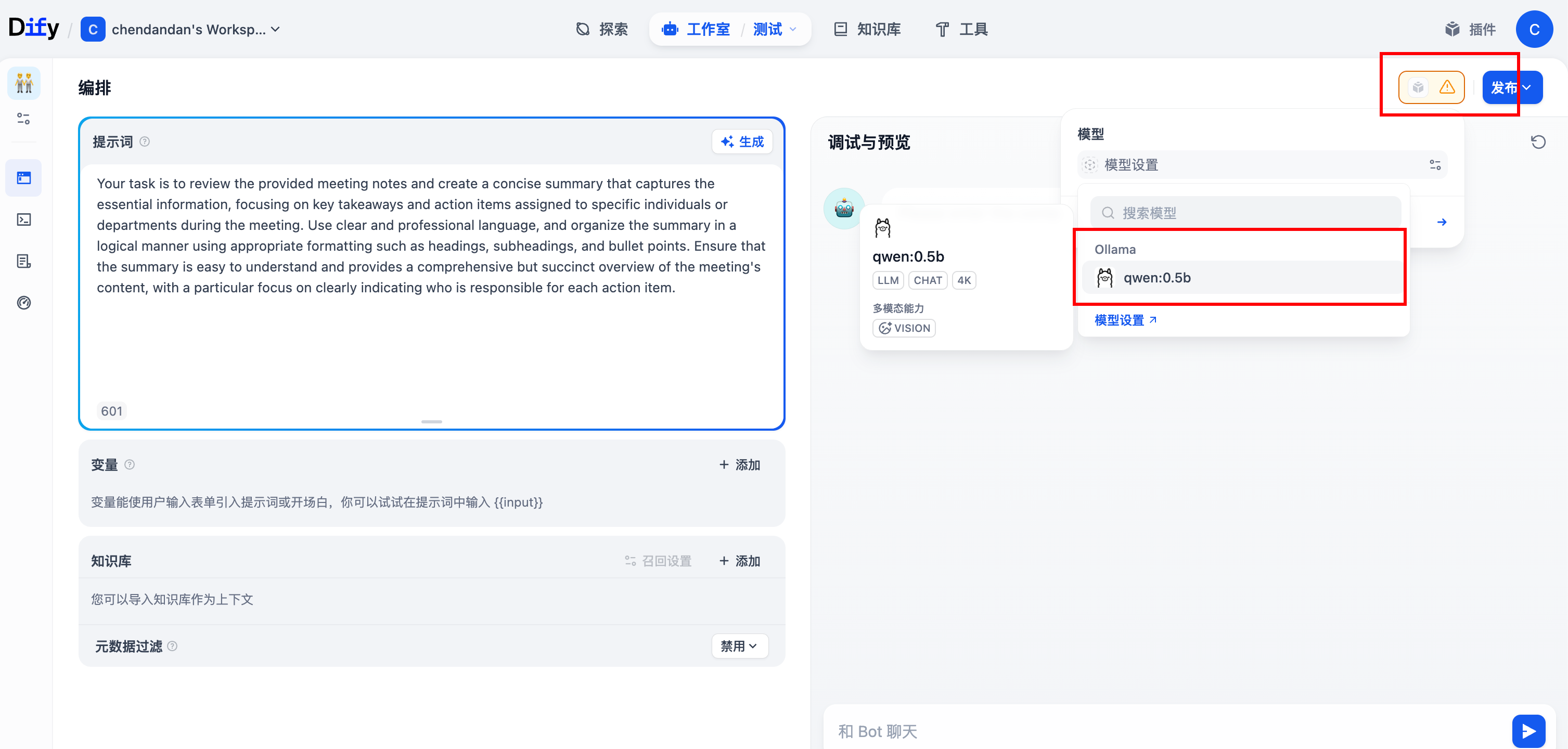
(5)创建知识库
点到知识库中,进行新建,一般选用导入文档等方式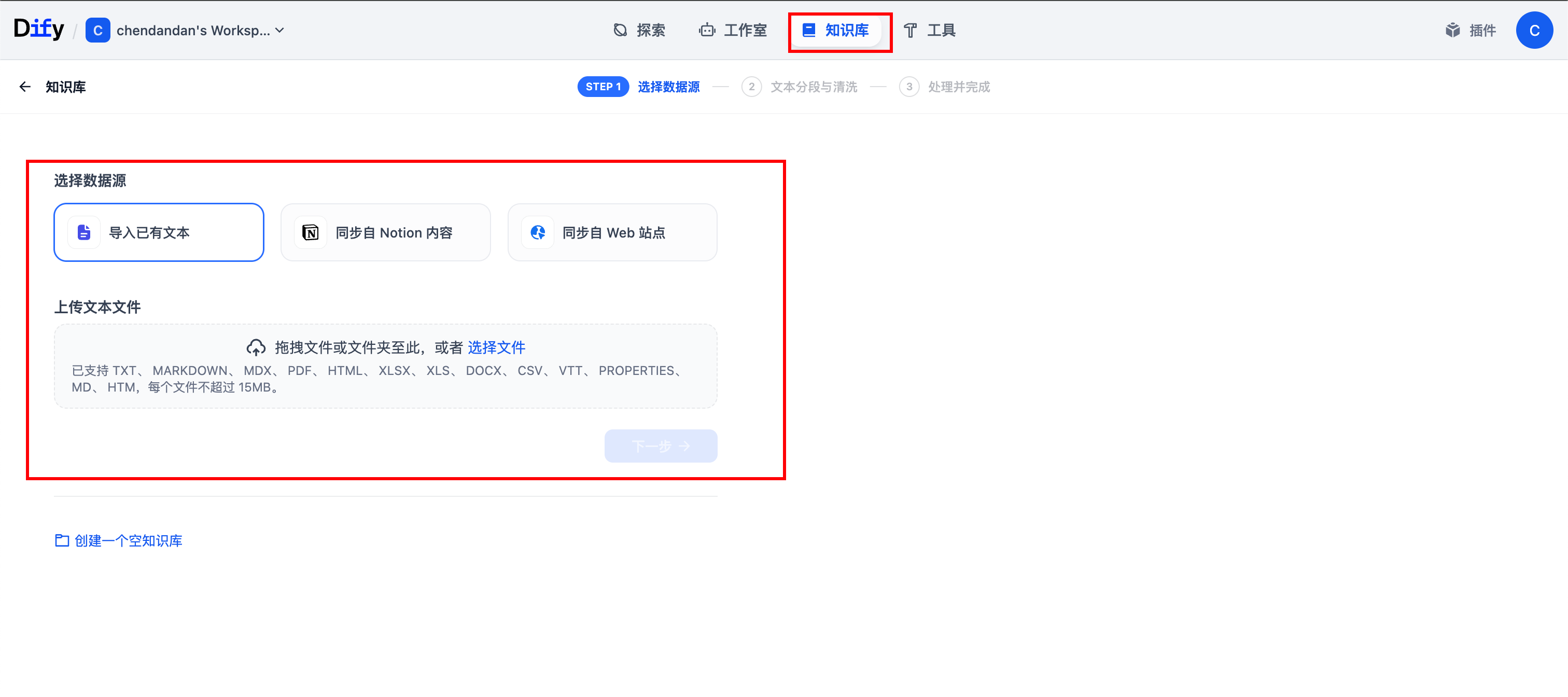
比如我上传一个设计模式的文档,进行下一步并保存,其他参数可以看着改,可以考虑先默认即可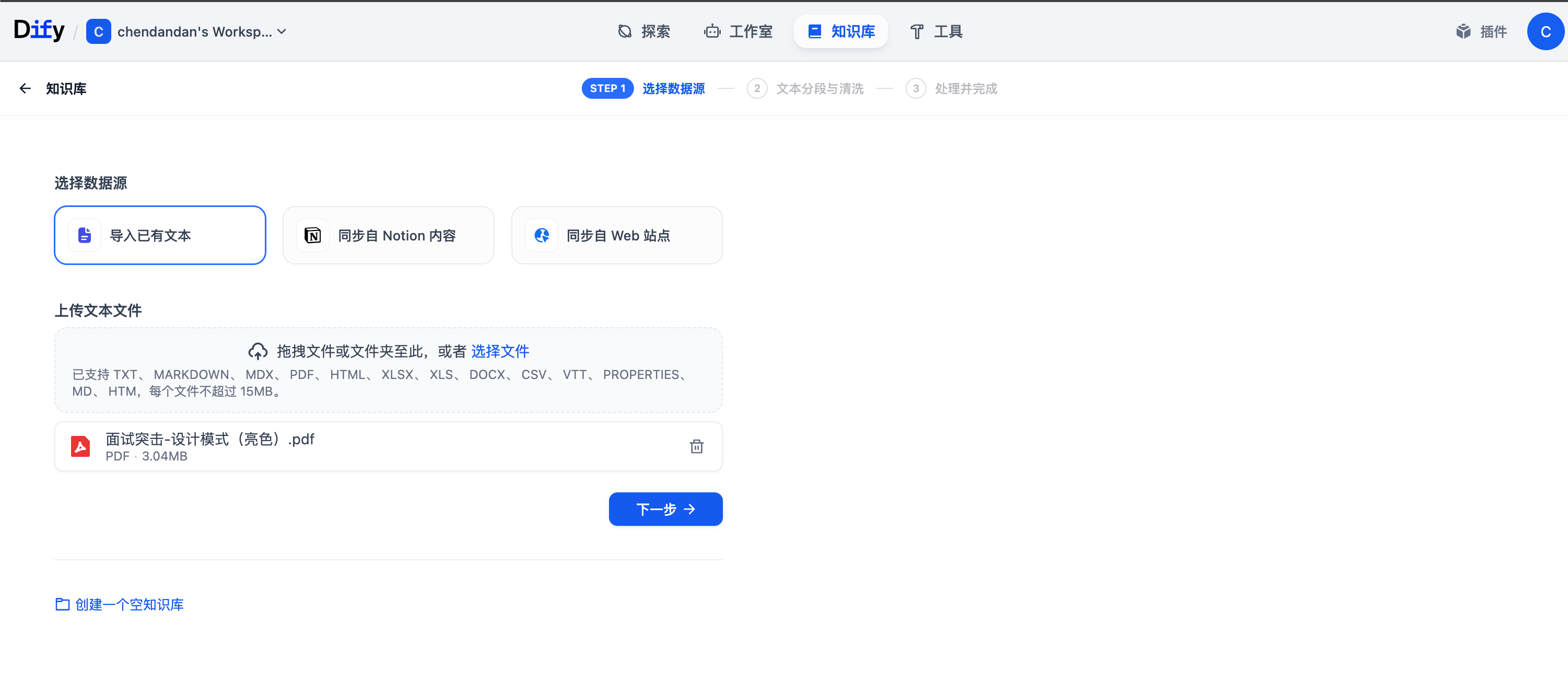
(6)添加知识库和变量
然后回到刚才的聊天机器人,在知识库栏里添加这个知识库之后就能帮你解答了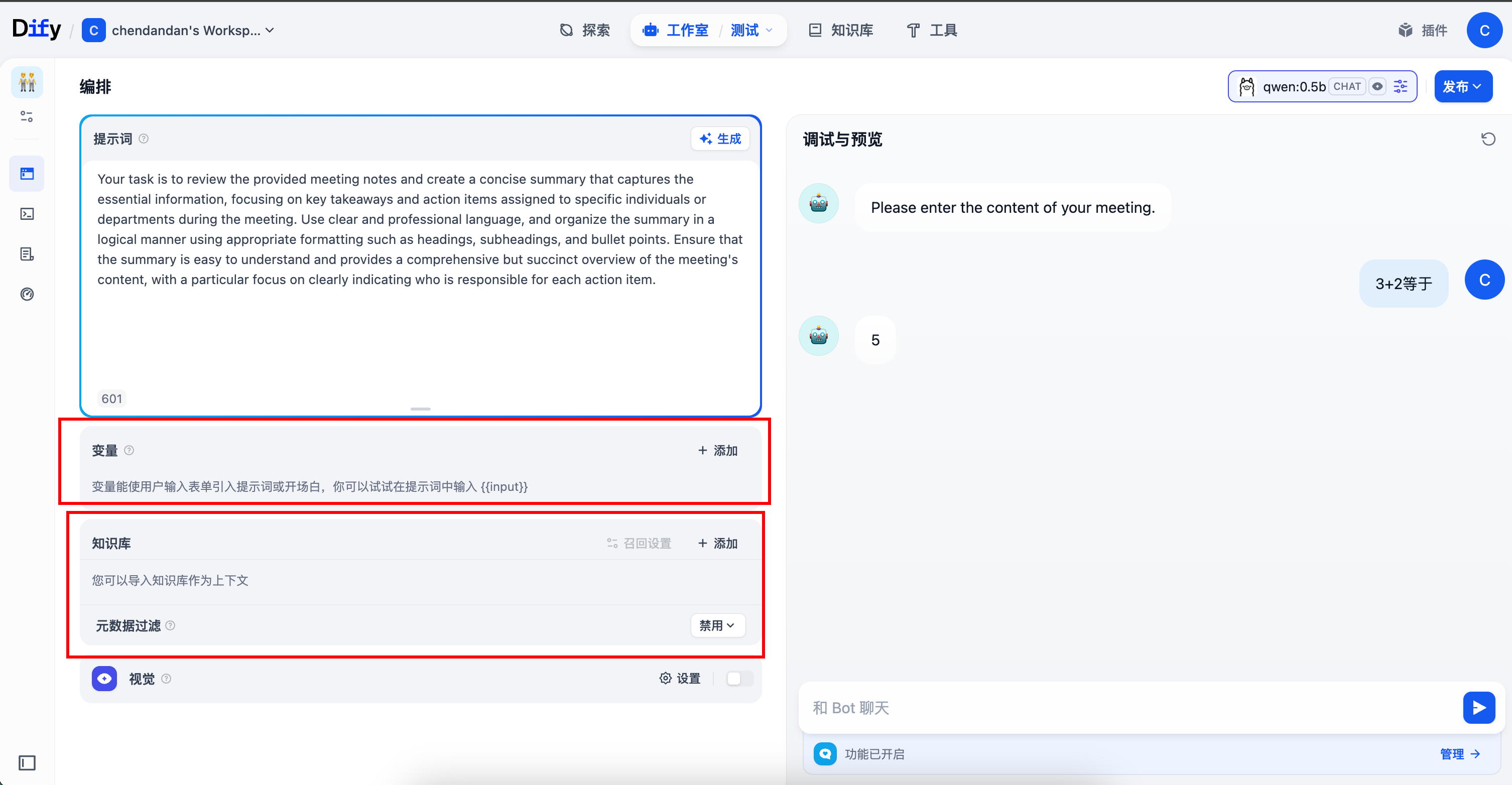

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 25
25 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)