ReACT Agent概述
ReACT Agent 是一个将大型语言模型的推理能力与外部工具的执行能力相结合的框架。它通过“思考-行动-观察”的循环,让模型能够有计划、有步骤地解决复杂问题,其过程类似于人类解决问题的方式,既强大又透明。它是构建下一代 AI 智能代理(如 AutoGPT、BabyAGI 等)的核心技术基础之一。
目录
ReACT 是一个非常重要的框架,它代表了构建能够推理(Reason)和行动(Act)的智能代理(Agent)的一种范式性突破。它由 Google Research 和普林斯顿大学的研究人员在 2022 年的论文《ReACT: Synergizing Reasoning and Acting in Language Models》中提出。
1. 核心思想:解决传统方法的局限性
在 ReACT 之前,使用大型语言模型(LLM)完成任务主要有两种方式:
-
标准提示(Standard Prompting): 直接向模型提问,希望它一步到位生成答案。缺点是: 对于需要多步推理、知识检索或工具使用的复杂任务,模型容易产生“幻觉”(编造事实),且过程不透明。
-
行动(Act)系列提示: 让模型执行一系列动作(如调用搜索 API),但不进行显式的推理。缺点是: 模型的行为类似于一个“无脑”的策略执行者,缺乏对任务全局和当前状态的深入思考,容易在错误的方向上越走越远。
ReACT 的核心思想是:将 推理(Reasoning) 和 行动(Acting) 结合起来,让模型在决定下一步行动之前,先进行一步内部的、可解释的思考(Think)。这种“三思而后行”的机制极大地提高了复杂任务处理的准确性、可靠性和可解释性。
2. ReACT 的工作原理:一个循环过程
ReACT 代理的工作流程是一个典型的 “思考-行动-观察”循环,直到任务完成为止。这个循环通常包含三个关键步骤:
-
Thought(思考)
-
内容: 代理分析当前的任务目标、历史记录(之前的思考、行动和观察结果)以及当前状态,然后推理出下一步应该做什么。
-
目的: 让模型的“推理轨迹”外部化、可视化。这是理解代理“为什么这么做”的关键,也是其可解释性的来源。
-
示例:
“用户想知道莱昂纳多·迪卡普里奥的奥斯卡竞争对手是谁。要回答这个问题,我需要先知道他是什么时候因哪部电影获奖的。我应该先搜索这个信息。”
-
-
Act(行动)
-
内容: 根据上一步的“思考”,代理决定执行一个具体的动作。这个动作通常是调用一个工具(Tool)。
-
常见工具:
Search(搜索),Lookup(知识库查询),Calculator(计算器),Python REPL(代码执行),API Call等。 -
格式: 动作通常以标准格式输出,例如
Action: Search和Action Input: "Leonardo DiCaprio Oscar win year",以便系统解析并执行。
-
-
Observation(观察)
-
内容: 环境(或系统)执行代理所要求的动作(如执行搜索),并将结果返回给代理。
-
目的: 为代理提供新的、可靠的外部信息,减少其依赖内部知识可能带来的幻觉。
-
示例:
“莱昂纳多·迪卡普里奥于 2016 年凭借电影《荒野猎人》获得第 88 届奥斯卡最佳男主角奖。”
-
这个循环会一直持续,直到代理在“思考”步骤中认为已经获得了足够的信息来给出最终答案。此时,它会触发一个特殊的动作:
-
Final Answer(最终答案)
-
内容: 代理基于所有之前的思考、行动和观察,综合生成一个完整、准确的回答。
-
格式:
Action: Finish或Final Answer: ...
-
3. 技术实现的关键要素
-
提示工程(Prompt Engineering):
-
ReACT 的强大功能严重依赖于精心设计的提示(Prompt)。这个提示通常包含:
-
任务说明: 解释代理的角色和目标。
-
输出格式规范: 明确规定代理必须严格按照
Thought:,Action:,Action Input:的格式输出。 -
工具描述: 详细说明代理可以使用哪些工具,以及每个工具的用途和调用格式。
-
示范例子(Few-Shot Examples): 提供一两个完整的任务解决示例,让模型学会如何遵循这个流程。
-
-
-
大型语言模型(LLM):作为代理的“大脑”,负责生成“思考”和决定“行动”。模型需要具备较强的逻辑推理和指令遵循能力。
-
工具(Tools):扩展了 LLM 的能力边界,使其能够获取实时信息、执行精确计算等,弥补了 LLM 静态知识和容易出错的短板。
ReAct 的核心是一个循环往复的过程,如下图所示:
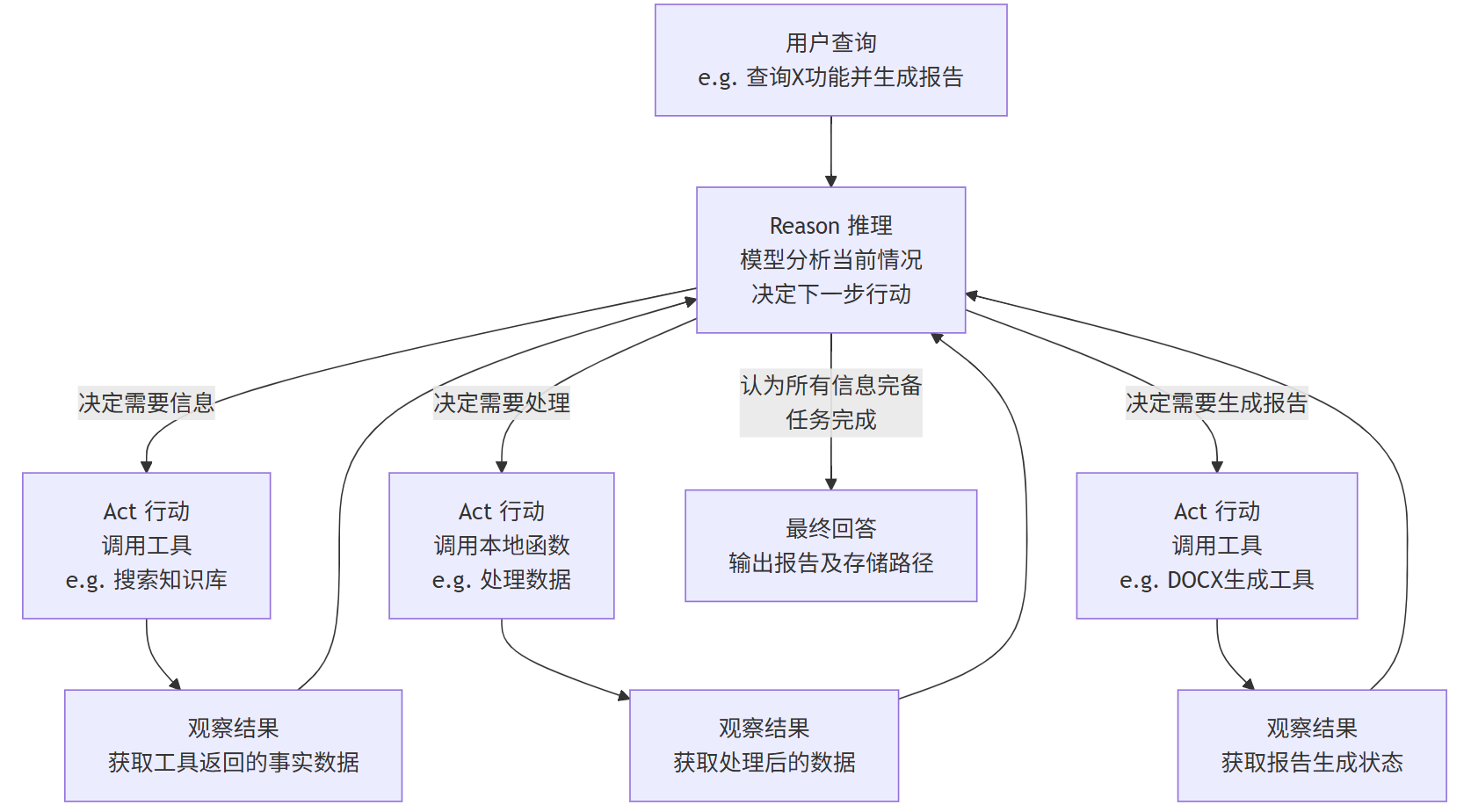
这个循环会一直持续,直到模型推理后认为已经获得了足够的信息,可以给出最终的、基于事实的答案为止。
4. ReACTAgent 在任务中的具体工作流程
一个 ReACTAgent 的工作流程会是这样的:
-
输入:用户提问:“帮我从帮助文档中查找关于【X功能】的说明,并总结成一份Word报告。”
-
循环开始:
-
Reason(推理):模型(Agent)的“内心独白”:“用户需要关于X功能的信息。我应该先使用搜索工具在知识库中查找相关内容。”
-
Act(行动):模型调用工具:
search_knowledge_base(query="X功能") -
Observe(观察):工具返回:来自帮助文档的几段关于X功能的详细文本。
-
-
下一轮循环:
-
Reason(推理):“好的,我找到了相关信息。但这些信息比较零散,我需要先对其进行归纳总结,提取关键点。我可以用一个文本摘要的本地函数来处理一下。”
-
Act(行动):模型调用本地函数:
summarize_text(text=检索到的文本) -
Observe(观察):函数返回:一段简洁、连贯的关于X功能的摘要。
-
-
最终循环:
-
Reason(推理):“信息现在已经处理好了,非常清晰。接下来我应该按照用户要求,将这些内容生成一份Word文档。”
-
Act(行动):模型调用工具:
generate_docx(content=处理后的摘要, title="X功能报告") -
Observe(观察):工具返回:
{"status": "success", "file_path": "/reports/X功能报告.docx"}
-
-
结束循环,最终输出:
-
Reason(推理):“任务已完成!我已经成功生成了报告。”
-
最终回答:模型对用户说:“已完成您的要求。报告已生成并保存至
/reports/X功能报告.docx。内容包括X功能的主要介绍和使用方法。”
-
5. 优势与重要性
-
减少幻觉(Reduces Hallucination): 通过依赖工具获取的外部事实(Observation)而非纯粹的内部记忆,答案更准确。
-
增强可解释性(Improves Interpretability): 整个“思考”过程是透明的,我们可以追溯代理的决策逻辑,更容易诊断错误。
-
模块化与灵活性(Modular and Flexible): 可以轻松地为代理添加新的工具(如数据库连接、软件API),扩展其能力,而无需重新训练模型。
-
协同效应(Synergy): “推理”和“行动”相互促进。推理指导行动的方向,行动的结果为下一步推理提供信息。
6. 挑战与局限性
-
提示工程复杂: 设计一个能稳定工作的 ReACT 提示需要大量的调试和迭代。
-
依赖模型能力: 如果底层 LLM 的推理能力较弱,它可能无法生成合理的“思考”或选择正确的工具。
-
循环可能无法终止: 代理有时会陷入死循环或偏离正轨,需要设置最大循环次数等安全机制。
-
工具执行成本: 每次调用外部工具(如搜索API)都可能产生费用或延迟。
总结
ReACT Agent 是一个将大型语言模型的推理能力与外部工具的执行能力相结合的框架。它通过“思考-行动-观察”的循环,让模型能够有计划、有步骤地解决复杂问题,其过程类似于人类解决问题的方式,既强大又透明。它是构建下一代 AI 智能代理(如 AutoGPT、BabyAGI 等)的核心技术基础之一。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 5
5 0
0- 0



 已为社区贡献18条内容
已为社区贡献18条内容

所有评论(0)