不想花钱又想玩大模型?X86 电脑 + LangChain+OpenVINO GenAI,零成本实现
本文介绍了LangChain-OpenVINO GenAI示例存储库,该存储库通过OpenVINO实现英特尔硬件优化与LangChain编排的集成,为生成式AI应用提供一体化参考方案。存储库覆盖文本、视觉、语音多模态场景,包含医学转录、视频摘要等实操案例,支持多种部署环境。采用分层架构设计,集成了LangChain框架、OpenVINO工具包以及各类AI模型,包括文本生成(如Llama 3.2)、
目的和范围
在国内 AI 创新热潮下,本文聚焦 LangChain-OpenVINO GenAI 示例存储库,其核心是通过 OpenVINO 实现英特尔硬件优化与 LangChain 编排的集成,为生成式 AI 应用提供 “硬件适配 + 流程编排” 一体化参考。
该存储库覆盖文本、视觉、语音多模态场景,含医学转录、视频摘要等实操案例;材料上包含演示应用、存档参考实现、自定义 LangChain 集成方案,并支持边缘、本地、云服务多环境部署,满足不同落地需求。
系统架构
该代码库采用分层架构进行组织,该架构将演示应用程序与核心基础设施组件分开,从而使工作负载的不同部分能够分布在各种部署目标上。
高级系统架构
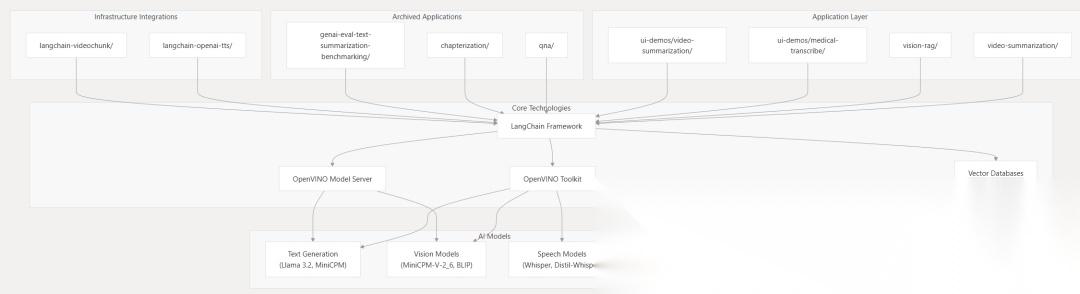
技术栈集成
该代码仓库演示了跨多种不同AI 模态将 OpenVINO 优化与 LangChain 编排集成的具体模式:
| 组件类别 | 技术 | 集成模式 |
|---|---|---|
| 编排 | LangChain 框架 | 集中的管道协调器和工作流管理 |
| 模型优化 | OpenVINO 工具包、OpenVINO 模型服务器 | 英特尔 CPU、GPU、NPU 上的硬件加速推理 |
| 文本生成 | Llama 3.2、MiniCPM、Qwen2 | 通过 OpenVINO 后端集成 LangChain LLM |
| 视觉处理 | MiniCPM-V-2_6、BLIP、D-FINE、FastSAM | 计算机视觉管道与 LangChain 集成 |
| 语音处理 | Whisper、Distil-Whisper、Kokoro、OuteTTS | 通过自定义 LangChain 组件集成 ASR 和 TTS |
| 矢量存储 | Milvus,FAISS | 用于文档和多模态检索的 RAG 实现 |
| 用户界面 | Streamlit | 基于 Web 的演示界面 |
演示类别
该代码库包含两类演示:持续维护的示例和存档的参考实现。
活动演示
当前的演示侧重于具有现代模型集成的生产就绪应用程序:

存档演示
存档演示代表过去的历史方法和参考实现:
| 演示 | 主要组件 | 地位 |
|---|---|---|
| 问答 | Distil-Whisper ASR、Qwen2 LLM、Kokoro/OuteTTS、RAG 检索 | 存档于 2025 年 8 月 14 日 |
| 章节化 | OpenVINO ASR、嵌入、K-means 聚类、LLM 处理 | 存档于 2025 年 8 月 14 日 |
| 评估文本总结的指标 | BLEU、ROUGE-N、BERTScore 指标评估 | 存档于 2025 年 8 月 14 日 |
自定义 LangChain 集成组件
该存储库包括两个自定义的 LangChain 集成包,它们扩展了框架的功能:

代码结构和入口点
整个代码仓库遵循模块化的结构设计原则:
| Structure | Purpose | Key Entry Points |
|---|---|---|
| Root Level | Repository documentation and global configuration | README.md , license files |
| Active Demos | Current demonstration applications | Individual demo directories with setup scripts |
| Archived Demos | Historical reference implementations | Read-only demonstration code |
| Integration Packages | Custom LangChain extensions | setup.py files for package installation |
| UI Demos | Streamlit-based user interfaces | streamlit_app.py , app.py files |
许可协议和模型使用
该代码仓库使用完全开源模型(Apache 2.0、MIT 许可证)和具有特定使用条款的开放可用模型。主要考虑因素包括:
- FFmpeg:LGPL 和 GPL 许可下的开源项目
- 人工智能模型:每个模型都保留其原始许可条款
- 全开放型号:Qwen、Mistral、Phi 允许不受限制使用
- 受限模型:Meta LLaMA 模型有特定的使用条款
视频摘要和Vision RAG
以下文档涵盖了代码存储库中两个密切相关的演示系统:具有多模态 RAG 功能的视频摘要管道和用于对象检测和识别的 Vision RAG 系统。这两个系统都通过 LangChain 编排利用 OpenVINO 优化的 AI 模型来处理视觉内容并启用语义搜索功能。
视频摘要系统通过检测对象、生成视觉摘要以及将多模态嵌入存储在向量数据库中以进行检索增强生成 (RAG) 查询来处理视频文件。Vision RAG 系统特别专注于使用零样本对象检测和相似性搜索比如从食品托盘图像中识别食品。
视频摘要系统架构图
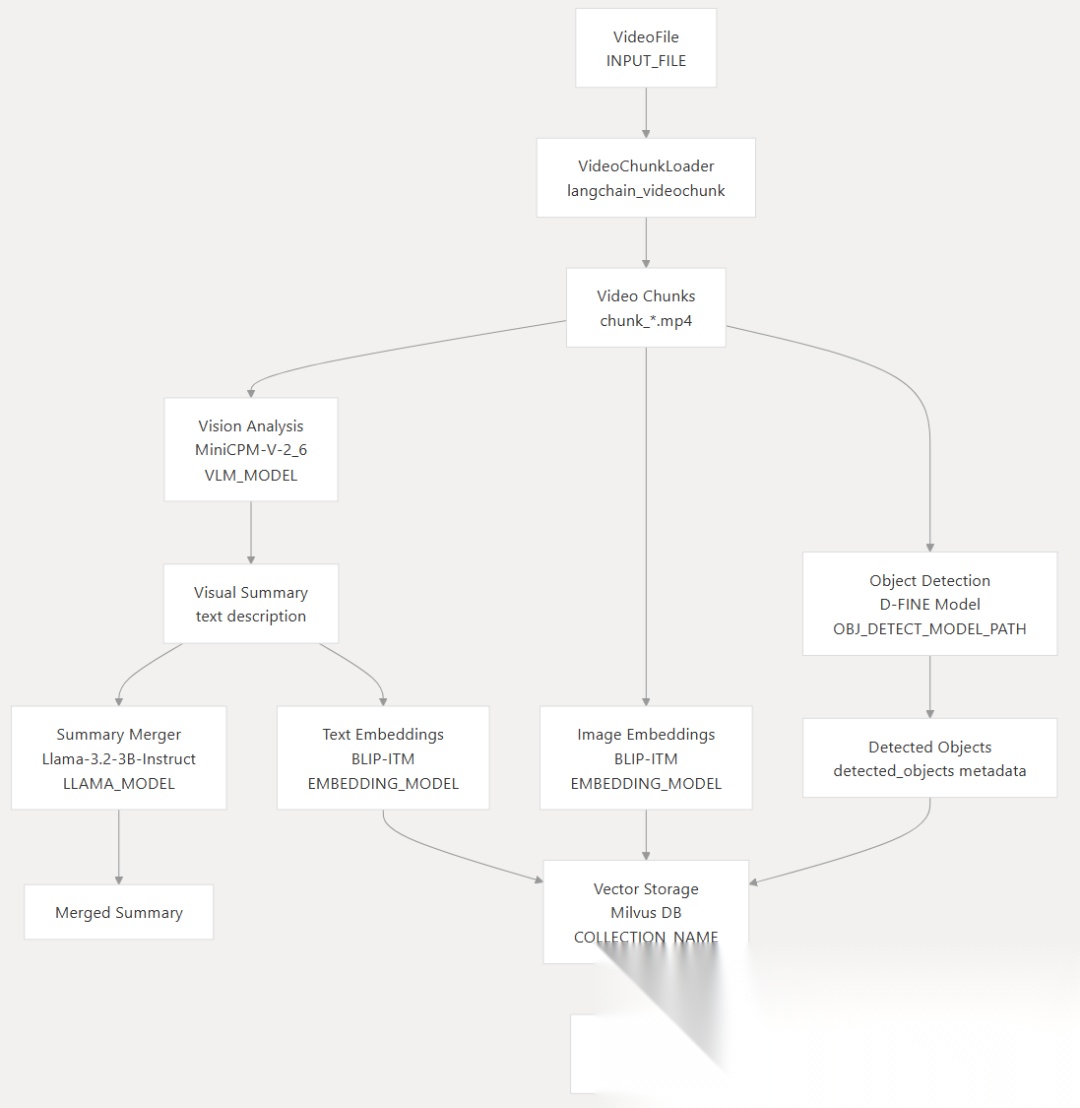
关键组件和配置
| Component | Configuration Variable | Model/Technology | Purpose |
|---|---|---|---|
| Video Chunking | VideoChunkLoader |
FFmpeg, LangChain | Segment videos into processable chunks |
| Object Detection | OBJ_DETECT_MODEL_PATH |
D-FINE (ov_dfine/dfine-s-coco.xml) | Detect objects in video frames |
| Vision-Language Model | VLM_MODEL |
MiniCPM-V-2_6 | Generate textual descriptions from visual content |
| Summary Merging | LLAMA_MODEL |
Llama-3.2-3B-Instruct | Merge multiple chunk summaries |
| Embedding Generation | EMBEDDING_MODEL |
BLIP-ITM-base-coco | Create text/image embeddings |
| Vector Storage | COLLECTION_NAME |
Milvus | Store and query multimodal embeddings |
具体实现:
- 视频处理和Chunking
管道首先将输入视频划分为可管理的块,通常长 30 秒,重叠 2 秒。这种分块策略确保了全面覆盖,同时保持了处理效率。
def generate_chunks(video_path: str, chunk_duration: int, chunk_overlap: int, chunk_queue: queue.Queue,
- 帧采样和目标检测
每个视频块都会进行帧采样,每个块最多提取 32 帧进行分析。该管道可以配置为使用 DFine 模型执行对象检测,识别和跟踪整个视频片段中的对象。
def get_sampled_frames(chunk_queue: queue.Queue, milvus_frames_queue: queue.Queue, vlm_queue: queue.Queue,
- 视觉语言模型分析
管道的核心使用 MiniCPM-V-2.6来分析采样帧并为每个块生成摘要。该模型处理视觉内容和对象检测元数据以创建全面的描述。
defgenerate_chunk_summaries(vlm_q: queue.Queue, milvus_summaries_queue: queue.Queue, merger_queue: queue.Queue,
- 向量存储与检索
该管道利用高性能矢量数据库 Milvus 来存储帧嵌入和文本摘要。这种双存储方法可实现强大的检索功能:
- 帧嵌入:使用 BLIP 模型对采样帧进行可视化表示
- 文本嵌入:用于语义搜索的块摘要的向量表示
classMilvusManager:
- 合并摘要
最后阶段涉及使用 Llama-3.2-3B-Instruct 将所有块摘要合并为连贯的总体摘要。SummaryMergeScoreTool 可确保合并的摘要维护上下文并提供异常评分。
defsend_summary_request(summary_q: queue.Queue, n: int = 3):
除了摘要之外,该管道还集成了复杂的 RAG 功能,使用户能够使用以下方法搜索处理后的视频内容:
- 基于文本的查询:搜索特定活动或描述
- 基于图像的查询:使用参考图像查找类似的视觉内容
- 元数据过滤:根据检测到的对象、时间范围或视频源缩小搜索范围
与模型服务端的集成
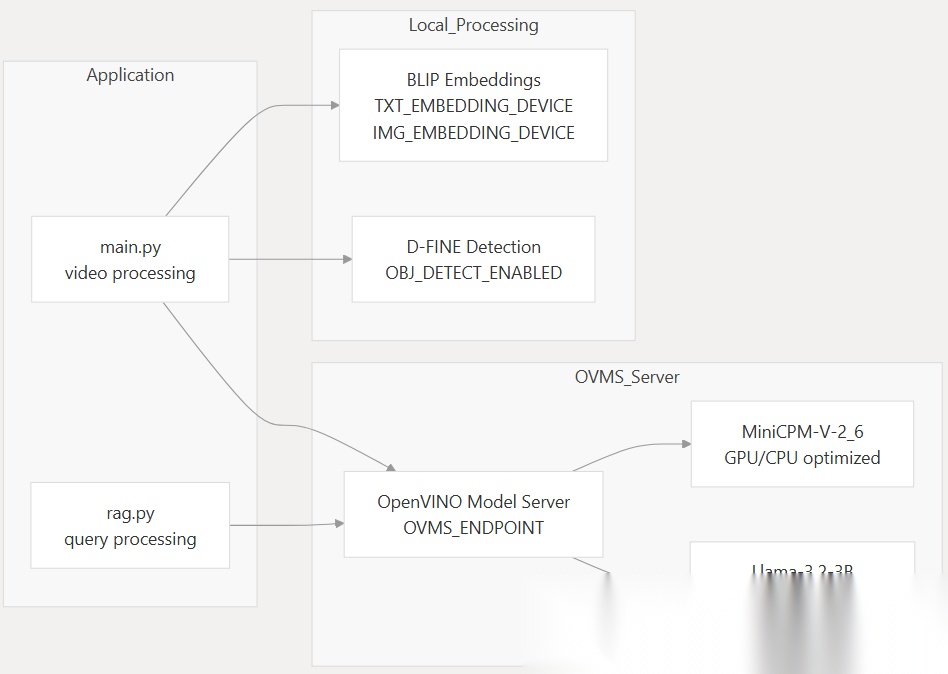
该系统在大型语言和视觉语言模型的 OpenVINO 模型服务器 (OVMS) 之间分配 AI 模型推理,以及用于嵌入生成和对象检测的本地处理。
视觉RAG系统
基于视觉的检索增强生成 (RAG) 代表了一种将计算机视觉与大型语言模型相结合以进行智能图像分析和内容生成的强大方法。此实现演示了如何使用开源模型从食品托盘中识别食品,而无需进行微调,所有这些都在英特尔酷睿平台上本地运行。
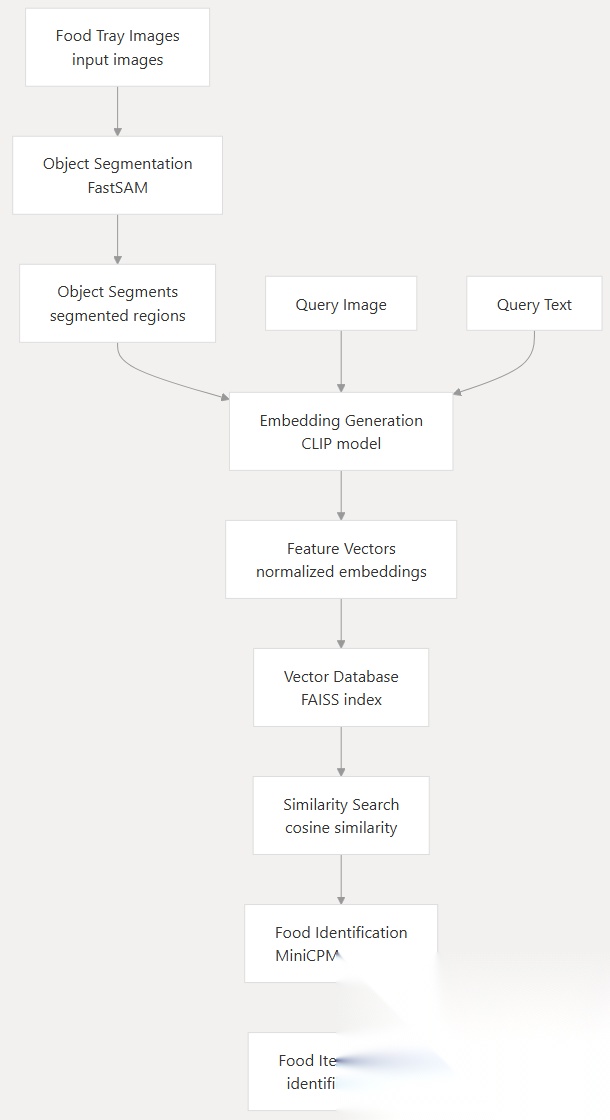
Vision RAG 管道结合了多种尖端技术,创建了一个复杂的图像分析系统。该实现的核心是通过几个阶段处理图像:对象检测、特征提取、相似性搜索和上下文合成。这种方法特别强大之处是它能够处理零样本模型而无需微调,使其适用于各种应用程序。
该系统利用 FastSAM 进行目标检测,利用 CLIP 进行图像嵌入,利用 FAISS 进行向量相似性搜索,利用 MiniCPM 进行最终合成。每个组件在将原始图像转换为有意义、上下文丰富的描述方面都发挥着至关重要的作用。整个管道使用 OpenVINO 进行了优化,以便在英特尔硬件上高效执行,展示了专门的优化如何显著提高性能。
Vision RAG 架构图
小结
基于视觉的 RAG 实现展示了将计算机视觉与大型语言模型相结合以进行智能图像分析的强大功能。通过利用零样本模型、矢量相似性搜索和优化推理,提供了一个全面的解决方案,用于识别和描述图像中的对象,而无需大量的训练数据。
该实现中的关键创新包括用于减少误报的自定义过滤功能、用于提高搜索准确性的数据增强策略以及用于最大限度地提高英特尔硬件性能的 OpenVINO 优化。这些技术使该系统在实际应用中既实用又高效。
随着计算机视觉和自然语言处理的不断发展,像这样的 Vision RAG 系统对于弥合视觉理解和上下文知识检索之间的差距将变得越来越重要。无论您是在食品服务、零售、医疗保健还是任何其他需要智能图像分析的领域工作,这种方法都为构建复杂的基于视觉的应用程序提供了坚实的基础。
技术栈对比
| Aspect | Video Summarization | Vision RAG |
|---|---|---|
| Vector Database | Milvus | FAISS |
| Object Detection | D-FINE | FastSAM |
| Embedding Model | BLIP-ITM | CLIP |
| Language Model | MiniCPM-V-2_6 + Llama-3.2 | MiniCPM |
| Use Case | General video analysis with RAG | Food item identification |
| Data Storage | Multimodal (text + image + metadata) | Image embeddings + classifications |
读者福利大放送:如果你对大模型感兴趣,想更加深入的学习大模型**,那么这份精心整理的大模型学习资料,绝对能帮你少走弯路、快速入门**
如果你是零基础小白,别担心——大模型入门真的没那么难,你完全可以学得会!
👉 不用你懂任何算法和数学知识,公式推导、复杂原理这些都不用操心;
👉 也不挑电脑配置,普通家用电脑完全能 hold 住,不用额外花钱升级设备;
👉 更不用你提前学 Python 之类的编程语言,零基础照样能上手。
你要做的特别简单:跟着我的讲解走,照着教程里的步骤一步步操作就行。
包括:大模型学习线路汇总、学习阶段,大模型实战案例,大模型学习视频,人工智能、机器学习、大模型书籍PDF。带你从零基础系统性的学好大模型!
现在这份资料免费分享给大家,有需要的小伙伴,直接VX扫描下方二维码就能领取啦😝↓↓↓
为什么要学习大模型?
数据显示,2023 年我国大模型相关人才缺口已突破百万,这一数字直接暴露了人才培养体系的严重滞后与供给不足。而随着人工智能技术的飞速迭代,产业对专业人才的需求将呈爆发式增长,据预测,到 2025 年这一缺口将急剧扩大至 400 万!!
大模型学习路线汇总
整体的学习路线分成L1到L4四个阶段,一步步带你从入门到进阶,从理论到实战,跟着学习路线一步步打卡,小白也能轻松学会!
大模型实战项目&配套源码
光学理论可不够,这套学习资料还包含了丰富的实战案例,让你在实战中检验成果巩固所学知识
大模型学习必看书籍PDF
我精选了一系列大模型技术的书籍和学习文档(电子版),它们由领域内的顶尖专家撰写,内容全面、深入、详尽,为你学习大模型提供坚实的理论基础。
大模型超全面试题汇总
在面试过程中可能遇到的问题,我都给大家汇总好了,能让你们在面试中游刃有余
这些资料真的有用吗?
这份资料由我和鲁为民博士(北京清华大学学士和美国加州理工学院博士)共同整理,现任上海殷泊信息科技CEO,其创立的MoPaaS云平台获Forrester全球’强劲表现者’认证,服务航天科工、国家电网等1000+企业,以第一作者在IEEE Transactions发表论文50+篇,获NASA JPL火星探测系统强化学习专利等35项中美专利。本套AI大模型课程由清华大学-加州理工双料博士、吴文俊人工智能奖得主鲁为民教授领衔研发。
资料内容涵盖了从入门到进阶的各类视频教程和实战项目,无论你是小白还是有些技术基础的技术人员,这份资料都绝对能帮助你提升薪资待遇,转行大模型岗位。
👉获取方式:
😝有需要的小伙伴,可以保存图片到VX扫描下方二维码免费领取【保证100%免费】
相信我,这套大模型系统教程将会是全网最齐全 最适合零基础的!!

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 40
40 0
0- 0



 已为社区贡献135条内容
已为社区贡献135条内容

所有评论(0)