AI | 大模型从入门到精通:通俗易懂理解蒸馏、量化、MoE、MLA、token、蒸馏、微调、RAG
软标签通常是教师模型的输出概率分布,它携带了更多的信息,例如类别之间的相似度,这使得学生模型能够在较少的数据和参数的情况下,学到更加丰富的知识。Token =AI眼中的"文字乐高块",中文名称可译为“词元”,是AI理解文本的最小单位,就像人类阅读时自动拆分的“信息颗粒”,AI不是按字而是按token处理文本。"分别是六个字符级token。更复杂一点的,现在大模型比较流行的子词级token还有字节对
“ 什么是蒸馏、量化、MoE架构、MLA。”
知识蒸馏(模型压缩)技术
一、什么是知识蒸馏
知识蒸馏(Knowledge Distillation)是一种模型压缩技术,通过训练小型“学生模型”模仿大型“教师模型”的输出分布,实现知识迁移。其核心在于利用教师模型的软标签(概率分布)而非硬标签,传递更丰富的类别间关系信息。14年NIPS上由Google 的Hinton发表的《Distilling the Knowledge in a Neural Network》是首次提出知识蒸馏这个概念。
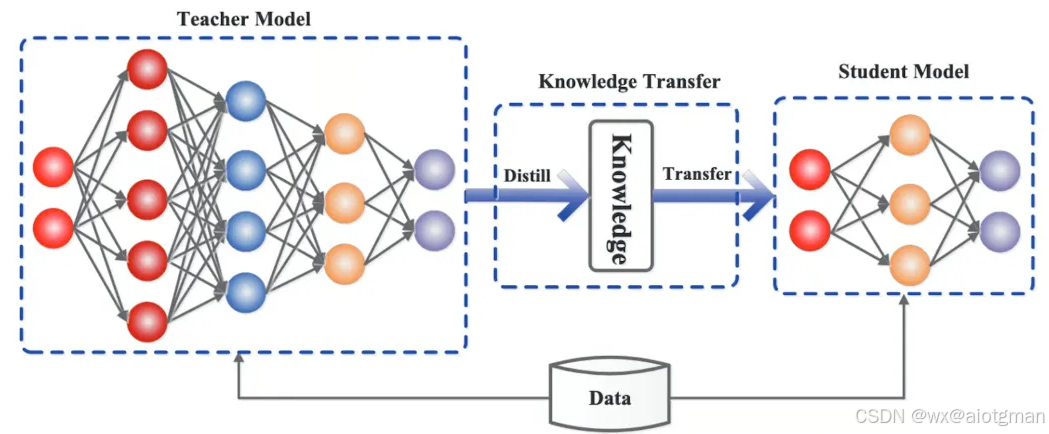
蒸馏过程通常包括以下几个步骤:
教师模型训练:首先,训练一个性能强大的大模型,这个模型通常具有大量的参数,能在各种任务上提供优异的性能。这个大模型即为“教师模型”。
学生模型设计:学生模型通常较小,参数量比教师模型少得多。其目的是在保证模型精度的同时,减少计算资源消耗,提高推理速度。
蒸馏过程:在训练学生模型时,采用教师模型的输出作为监督信号。不同于传统的监督学习,蒸馏技术利用教师模型的软标签(Soft Labels)而非硬标签。软标签通常是教师模型的输出概率分布,它携带了更多的信息,例如类别之间的相似度,这使得学生模型能够在较少的数据和参数的情况下,学到更加丰富的知识。
优化与精炼:学生模型通过模拟教师模型的行为,逐渐学习到其潜在的知识结构。通过反复训练,学生模型在大部分情况下能够接近或达到教师模型的性能,同时具有更高的计算效率和更小的内存占用。
二、主要作用
模型压缩:蒸馏技术可以将大型模型压缩成较小的模型,使得其在移动设备或计算资源有限的环境中依然可以发挥较高的性能。
知识迁移:学生模型不仅继承了教师模型的知识,还能在一些情况下进行自我优化,提升性能。
推理效率:由于学生模型的规模较小,它在推理时所需的计算资源和时间都显著减少,有助于加速推理过程,尤其适用于实时应用场景。
大模型在场景落地时,会存在部署推理成本高、专业知识不足、幻觉问题严重等问题,因此在专业级市场,需要基于蒸馏、微调、RAG等手段,提升大模型在垂直领域的表现。
模型量化
一、什么是模型量化
模型量化(Quantization)是指以较低的推理精度损失将连续取值(通常为float32或者大量可能的离散值)的浮点型权重近似为有限多个离散值(通常为int8)的过程。通过以更少的位数表示浮点数据,模型量化可以减少模型尺寸,进而减少在推理时的内存消耗,并且在一些低精度运算较快的处理器上可以增加推理速度。具体如下图所示,[-T, T]是量化前的数据范围,[-127, 127]是量化后的数据范围。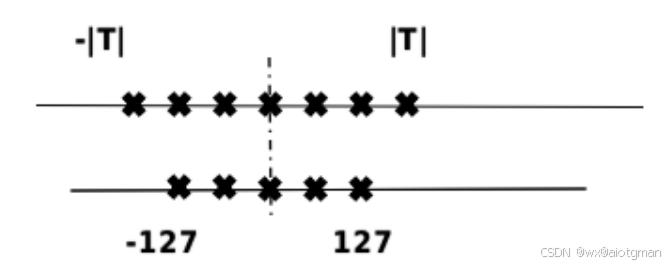
量化将模型参数的表示从浮点数精度降低为整数或低精度形式,以减小模型的存储和计算开销。
二、主要作用
减小模型大小
如 int8 量化可减少 75% 的模型大小,int8 量化模型大小一般为 32 位浮点模型大小的 1/4:
减少存储空间:在端侧存储空间不足时更具备意义。
减少内存占用:更小的模型当然就意味着不需要更多的内存空间。
减少设备功耗:内存耗用少了推理速度快了自然减少了设备功耗;
加快推理速度
访问一次 32 位浮点型可以访问四次 int8 整型,整型运算比浮点型运算更快;CPU 用 int8 计算的速度更快
某些硬件加速器如 DSP/NPU 只支持 int8
比如有些微处理器属于 8 位的,低功耗运行浮点运算速度慢,需要进行 8bit 量化。
模型量化主要意义就是加快模型端侧的推理速度,并降低设备功耗和减少存储空间。
MoE混合专家模型技术
训练大型语言模型(LLM)通常需要大量的计算资源,这对许多组织和研究人员来说是一个很高的门槛。混合专家(MoE)技术通过将大型模型分解成更小的、专门的网络来解决这一难题。
MoE(Mixture of Experts,混合专家模型)是一种通过动态选择子模型(专家)处理输入数据的深度学习架构,旨在提升模型性能与效率。其核心思想是“术业有专攻”,即让不同专家专注于特定任务,通过门控网络动态调度专家资源,在降低计算成本的同时实现高性能输出。
一、什么是MoE
想象一个人工智能模型是一个专家团队,每个人都有自己独特的专业知识。混合专家(MoE)模型通过将复杂任务划分为(称为专家的)更小的专业网络来运行这一原则。每个专家专注于问题的一个特定方面,使模型能够更有效、更准确地解决任务。就像医生负责医疗问题,技师负责汽车问题,厨师负责烹饪一样,每个专家都有自己擅长的事情。通过合作,这些专家可以更有效地解决更广泛的问题。
二、主要作用
计算高效性。MoE通过动态分配任务,减少冗余计算。例如,DeepSeek-MoE 16B的推理仅激活2.8B参数,计算量比同等性能的稠密模型降低60%。
参数可扩展性。一是专家的多样化能力使MoE模型具有高度的灵活性,通过召集具有专业能力的专家,MoE模式可以承担更广泛的任务。二是将复杂的问题分解成更小、更易于管理的任务,有助于MoE模型处理日益复杂的输入。三是支持扩展到数百甚至上千个专家,模型容量大幅提升(如谷歌的Switch Transformer达1.6万亿参数),同时保持分布式并行计算的可行性。
任务适应性。一是MoE的“分而治之”方法,其中任务分别执行,增强了模型对故障的容错弹性。如果一个专家遇到问题,并不一定会影响整个模型的功能。二是在多模态、复杂推理等场景中,MoE通过专家分工实现精准处理,例如GPT-4的MoE架构能分别处理文本生成、逻辑推理和图像分析任务。
MLA多头潜在注意力机制技术
多头注意力机制(Multi-Head Attention)是深度学习领域中一种重要的技术,最早由Vaswani等人在2017年的论文《Attention is All You Need》中提出。
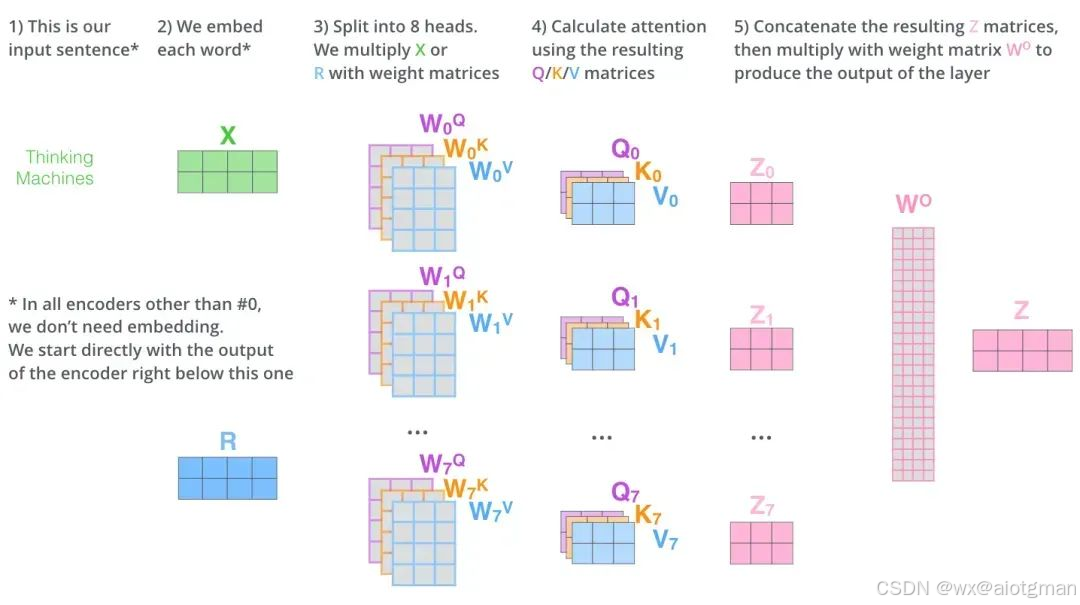
多头注意力(Multi-Head Attention)是一种在Transformer模型中被广泛采用的注意力机制扩展形式,它通过并行地运行多个独立的注意力机制来获取输入序列的不同子空间的注意力分布,从而更全面地捕获序列中潜在的多种语义关联。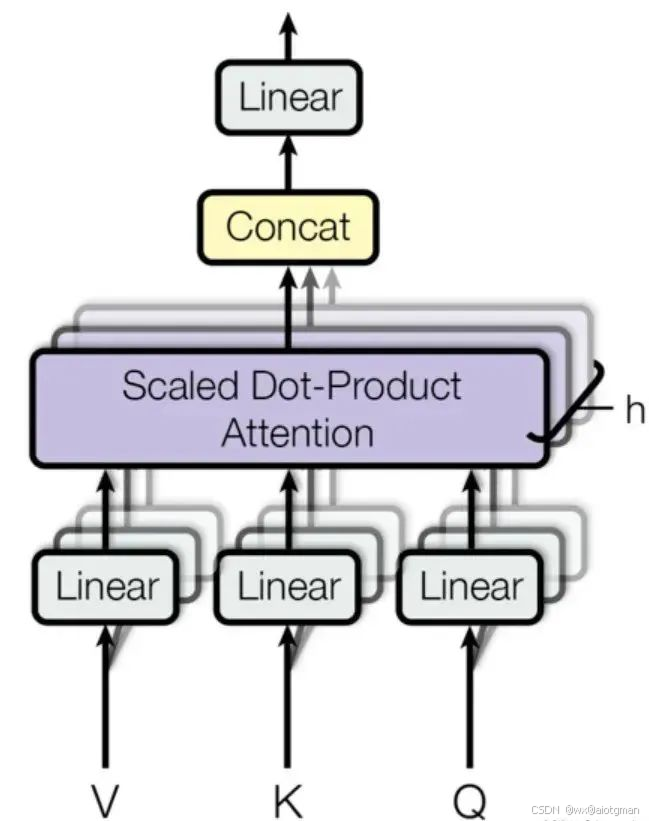
在多头注意力中,输入序列首先通过三个不同的线性变换层分别得到Query、Key和Value。然后,这些变换后的向量被划分为若干个“头”,每个头都有自己独立的Query、Key和Value矩阵。对于每个头,都执行一次Scaled Dot-Product Attention(缩放点积注意力)运算,即: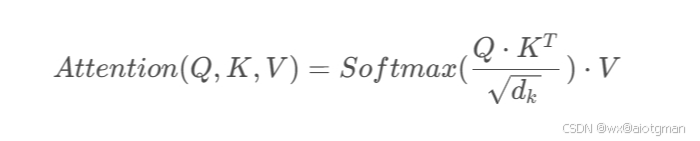
最后,所有头的输出会被拼接(concatenate)在一起,然后再通过一个线性层进行融合,得到最终的注意力输出向量。
通过这种方式,多头注意力能够并行地从不同的角度对输入序列进行注意力处理,提高了模型理解和捕捉复杂依赖关系的能力。在实践中,多头注意力能显著提升Transformer模型在自然语言处理和其他序列数据处理任务上的性能。
大家在用ChatGPT的API时,是按token计费的。例如,你提问消耗了 100 token,ChatGPT根据你的输入,回答了200token,那么一共消费的 token 数就是 300。
有时候看一些偏技术的文章,一些模型后面带着8k、32k,甚至100k,这也是指模型能处理的蕞大token长度。
既然token在大模型领域这么高频出现,我们不禁要问:
什么是token?
它是怎么计算的?
一个token是指一个字吗?
中文和英文的token是一样的吗?
一、什么是Token?
大模型世界的最小积木——Token
Token =AI眼中的"文字乐高块",中文名称可译为“词元”,是AI理解文本的最小单位,就像人类阅读时自动拆分的“信息颗粒”,AI不是按字而是按token处理文本。就像乐高小块能拼出无限可能,大模型把文本拆成Token,再重组出智能回答~
大模型中的"token"是指文本的蕞小处理单位在大模型处理中,将文本划分为token是对文本进行分析和处理的基本步骤之一。
通常情况下,一个token可以是一个单词、一个标点符号、一个数字,或者是其他更小的文本单元,如子词或字符。
以下是不同token切分类型的介绍:
单词级token: 即token是按照单词进行划分的。一个句子中的每个单词通常都会成为一个独立的token。例如,在句子"我是智泊AI"中,“我”、"是”、"智泊AI"分别是三个单词级token.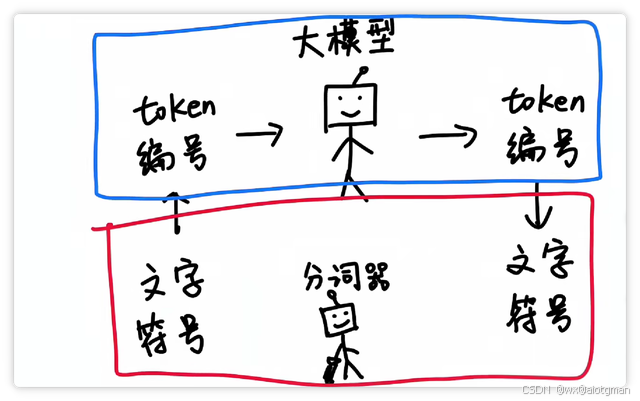
标点符号级token: 除了单词,标点符号通常也作为独立的token存在。这是因为标点符号在语义和语法上都具有重要的作用。
例如,在句子"token好理解吗?“中,除了"token好理解吗"作为一个整体的token外:蕞后的问号”?"也是一个独立的token。
子词级token: 为了更好地处理复杂的语言情况,有时候将单词进一步划分为子词级的token。例如,单词"unhappiness"可以被划分为子词级token"un-"、、"happiness’
更复杂一点的,现在大模型比较流行的子词级token还有字节对编码(BPE),这也是ChatGPT的guan方采用的token编码方法它是通过合并出现频繁的子词对来实现的。
字符级token: 在某些情况下,特别是在字符级别的处理任务中,文本会被划分为字符级token。这样做可以处理字符级别的特征和模式。例如,在句子"Hello!“中,“H”、“e”““、” ”“o"和”!"分别是六个字符级token。
通过对文本做成一个一个的token,LLM模型能够更好地理解和处理语言,从而实现任务如文本生成、机器翻译、文本分类等。
因此,现在主流的大模型都会自带一个tokenizer,也就是自动将输入文本解析成一个一个的token,然后做编码(就是查字典转换成数字),作为大模型真正的“输入
蕞后,那么在ChatGPT中,一个token到底是多长?下面是一些有用的经验法则,可以帮助理解token的实际长度:
对于英文文本,1个token大约是4个字符或0.75个单词。通常来说,也就是1000个Token约等于750个英文单词。
对于中文,1000个Token通常等于400~500个汉字。
但是…!!!
Token ≠ 汉字/单词
中文: 1个token≈1-2个汉字(比如"人工智能"会被拆成2-3个token)
英文:1个token≈0.75个单词(比如"unbelievable"可能会被拆分成"un+believetable")
空格也算token!大家输入时千万别乱敲空格哦~
二、为什么重要?
算力成本: 每次对话消耗token量=你的"算力账单"(GPT-4每千token约¥0.3)
内容长度: ChatGPT-3.5最多支持4096 tokens(约3000汉字)
回答质量: 超出限制会"失忆",重要信息要前置!
三、技术原理3层拆解
分词算法: 用unigram/BPE算法找最佳拆分组合
分词器(tokenizer)黑科技:
英文: 按词根拆分(如“unbelievable"一[“un”,“##belie”,“##able”])
中文: 混合策略("人工智能"可能拆为[“人”,“工”,“智能”])
Emoii/符号: 每个表情算1个token
词表映射: 每个token对应唯一ID(比如"猫"→3827,🐱→12850)
向量转换: ID转换成768维数学向量,模型才能真正“理解”
概率预测: 根据前文猜下一个token
四、Tokens的作用:
1⃣ 输入限制:AI模型对每次处理的Token数量有限制(比如GPT-4最多支持32K Tokens),超过限制的部分会被截断。
2⃣ 计费标准:很多AI平台按Tokens数量收费,比如输入和输出的Tokens总和决定了使用成本。
3⃣ 模型理解:模型通过Tokens来“理解”文本,Token化方式直接影响模型的性能和效果。
五、日常应用Tips
优化prompt: 删减冗余词=省token空间
控制输出: 设置max tokens参数
处理长文本: 用"继续"触发连贯生成
现在你明白了吗?Tokens是AI大模型的核心概念之一,了解它有助于更好地使用AI工具哦!

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 21
21 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)