Java程序员转型秘籍:迈向AI大模型开发之路,我的成功学习路线分享!
本文为Java程序员提供向AI大模型开发转型的实用指南。首先分析了Java开发者面临的行业困境及AI领域的新机遇,指出架构设计能力和严谨开发流程等Java经验在大模型开发中的迁移价值。随后给出系统的技能提升路径:1)掌握机器学习/深度学习基础理论;2)熟练使用TensorFlow/PyTorch框架;3)优化编程能力与算法;4)补足线性代数等数学基础。文末提供包含104G学习资源的免费大礼包,涵盖
Java现在是后端转后厨,没办法自己卷AI吧,这路上踩的坑是真不少啊,大家有时间可以看看你的学习路线和我这个相差多少,还是那句话我学习中用到的资料你们通通都可以拿。
一、Java 程序员的当下困境与新机遇
在技术浪潮汹涌的当下,Java 程序员的职场之路,正面临着前所未有的挑战。随着行业的逐渐成熟,Java 开发领域的竞争愈发激烈,市场对于 Java 程序员的要求也在不断提高。从初级岗位的激烈角逐,到中高级职位对技术深度和广度的严苛要求,每一位 Java 程序员都在这场竞争中努力寻找自己的立足之地。
与此同时,人工智能的飞速发展,也为 Java 程序员带来了新的机遇与挑战。大模型开发作为人工智能领域的热门方向,正逐渐成为行业的焦点。大模型在自然语言处理、图像识别、智能推荐等领域的广泛应用,不仅为企业带来了更高的效率和创新能力,也为从业者创造了广阔的发展空间。对于 Java 程序员来说,转岗大模型开发,不仅是一次职业的转型,更是一次拥抱未来技术趋势的勇敢尝试。

二、Java 程序员转岗大模型开发的独特优势
虽然转岗意味着要面对新的挑战,但 Java 程序员在多年的编程实践中积累的技能和经验,也为顺利过渡到这个全新领域奠定了坚实的基础。
在长期的 Java 开发工作中,程序员们对软件架构有着深入的理解和实践经验。无论是经典的三层架构,还是当下流行的微服务架构,Java 程序员都能熟练运用,构建出高效、可维护的系统。这种对架构的敏锐洞察力,在大模型开发中同样至关重要。大模型的开发涉及到复杂的神经网络架构和分布式计算,需要开发者具备良好的系统设计能力,以确保模型的高效运行和可扩展性。例如,在设计一个基于大模型的智能推荐系统时,Java 程序员可以借鉴以往的架构经验,合理地划分模块,将数据处理、模型训练和推理等功能进行分离,提高系统的性能和稳定性。
Java 程序员对开发流程的熟悉也是一项重要优势。从需求分析、设计、编码、测试到部署,每一个环节都有严格的规范和流程。这种严谨的开发习惯,能够帮助 Java 程序员在大模型开发中更好地管理项目,确保项目的顺利进行。在大模型开发中,数据的收集、清洗、标注,模型的训练、评估、优化等步骤,都需要有条不紊地进行。Java 程序员可以将以往的开发流程应用到这些环节中,提高开发效率和质量。比如,在数据标注阶段,制定详细的标注规范和流程,确保标注数据的准确性和一致性;在模型训练阶段,设置合理的训练参数和监控指标,及时发现和解决问题。
三、转岗必备技能提升指南
(一)夯实理论基础
机器学习、深度学习作为大模型开发的核心理论,是转岗必备的知识基石。机器学习通过数据构建模型,让计算机自动从数据中学习规律并进行预测,涵盖分类、回归、聚类等多种任务;深度学习则是基于神经网络的机器学习技术,通过构建多层神经网络,让模型自动学习数据的复杂特征表示,在图像、语音、自然语言处理等领域取得了卓越成果。理解线性回归、逻辑回归、决策树、神经网络等基础模型的原理和应用场景,是入门的关键。例如,线性回归常用于预测连续值,如房价预测;逻辑回归则适用于二分类问题,如判断邮件是否为垃圾邮件。
为了深入学习这些理论知识,你可以参考《机器学习实战》这本书,它通过大量的实例和代码,帮助你理解机器学习算法的原理和实现;《深度学习》(花书)则是深度学习领域的经典教材,全面系统地介绍了深度学习的基础知识、模型架构和训练方法。此外,吴恩达的《机器学习》和《深度学习专项课程》在 Coursera 平台上广受欢迎,课程内容深入浅出,讲解细致,非常适合初学者。
(二)掌握关键工具与框架
在大模型开发中,TensorFlow 和 PyTorch 是两款主流的深度学习框架,它们为开发者提供了高效的模型构建、训练和部署工具。TensorFlow 由谷歌开发,具有强大的分布式训练能力和可视化工具,适用于大规模数据的深度学习任务,在工业界应用较为广泛;PyTorch 则以其动态计算图的特性而受到广泛欢迎,在研究和开发中具有很高的灵活性,易于调试和快速迭代,很多新的研究成果都是基于 PyTorch 实现的。
以图像分类任务为例,使用 TensorFlow,你可以利用其 Keras API 快速构建一个卷积神经网络模型:
|
import tensorflow as tf from tensorflow.keras import layers, models # 构建模型 model = models.Sequential([ layers.Conv2D(32, (3, 3), activation='relu', input_shape=(28, 28, 1)), layers.MaxPooling2D((2, 2)), layers.Conv2D(64, (3, 3), activation='relu'), layers.MaxPooling2D((2, 2)), layers.Flatten(), layers.Dense(64, activation='relu'), layers.Dense(10, activation='softmax') ]) # 编译模型 model.compile(optimizer='adam', loss='sparse_categorical_crossentropy', metrics=['accuracy']) |
而使用 PyTorch 实现同样的任务,代码风格则更加灵活:
|
import torch import torch.nn as nn import torch.optim as optim from torchvision import datasets, transforms # 数据预处理 transform = transforms.Compose([ transforms.ToTensor(), transforms.Normalize((0.5,), (0.5,)) ]) trainset = datasets.MNIST(root='./data', train=True, download=True, transform=transform) trainloader = torch.utils.data.DataLoader(trainset, batch_size=64, shuffle=True) # 模型定义 class SimpleNN(nn.Module): def __init__(self): super(SimpleNN, self).__init__() self.fc1 = nn.Linear(28 * 28, 128) self.fc2 = nn.Linear(128, 64) self.fc3 = nn.Linear(64, 10) def forward(self, x): x = x.view(x.shape[0], -1) x = torch.relu(self.fc1(x)) x = torch.relu(self.fc2(x)) x = self.fc3(x) return x # 模型训练 device = torch.device('cuda' if torch.cuda.is_available() else 'cpu') model = SimpleNN().to(device) criterion = nn.CrossEntropyLoss() optimizer = optim.SGD(model.parameters(), lr=0.01) for epoch in range(5): running_loss = 0 for images, labels in trainloader: images, labels = images.to(device), labels.to(device) optimizer.zero_grad() output = model(images) loss = criterion(output, labels) loss.backward() optimizer.step() running_loss += loss.item() print(f'Epoch {epoch + 1}, Loss: {running_loss / len(trainloader)}') |
学习这些框架,你可以从官方文档入手,深入了解其 API 和使用方法;同时,在 Kaggle 等平台上参与相关的项目实践,通过实际案例加深对框架的理解和掌握。
(三)精进编程能力
在大模型开发中,高效的编程能力是实现复杂算法和模型的关键。Java 程序员虽然已经具备了一定的编程基础,但在处理大规模数据和复杂计算时,仍需要进一步提升编程技巧,优化算法和代码结构 。
优化算法可以从减少循环次数、避免重复计算、选择合适的数据结构等方面入手。例如,在查找操作频繁的场景中,使用哈希表代替数组可以显著提高查找效率;在处理大规模数据时,采用并行计算技术,如多线程或分布式计算,能够充分利用硬件资源,加快计算速度。
在代码结构方面,遵循良好的编程规范和设计模式,能够提高代码的可读性和可维护性。例如,使用面向对象编程的思想,将相关的功能封装成类和方法,使代码结构更加清晰;采用设计模式,如工厂模式、单例模式等,能够提高代码的可扩展性和复用性。
此外,掌握一些调试技巧也非常重要。在开发过程中,难免会遇到各种错误和问题,熟练使用调试工具,如 PyTorch 的pdb、TensorFlow 的tfdbg,能够快速定位和解决问题,提高开发效率。
(四)补齐数学短板
数学是大模型开发的底层支撑,扎实的数学基础能够帮助你更好地理解和实现各种算法和模型。线性代数中的向量、矩阵运算,是理解神经网络中数据变换的基础;概率论与数理统计用于处理模型中的不确定性和数据的统计规律;微积分中的导数、梯度等概念,则是优化算法的核心,帮助模型通过梯度下降等方法找到最优解。
为了提升数学水平,你可以从基础的数学教材入手,如《线性代数》《概率论与数理统计》《高等数学》等,系统地学习相关知识。同时,结合实际的算法和模型,深入理解数学知识在其中的应用。例如,在学习神经网络时,理解权重矩阵的乘法运算、梯度下降算法中的导数计算等。
在线课程也是学习数学的好帮手,如 Coursera 上的《线性代数基础》《概率论基础》等课程,由专业的教授授课,讲解详细,配有大量的实例和练习题,能够帮助你更好地掌握数学知识。
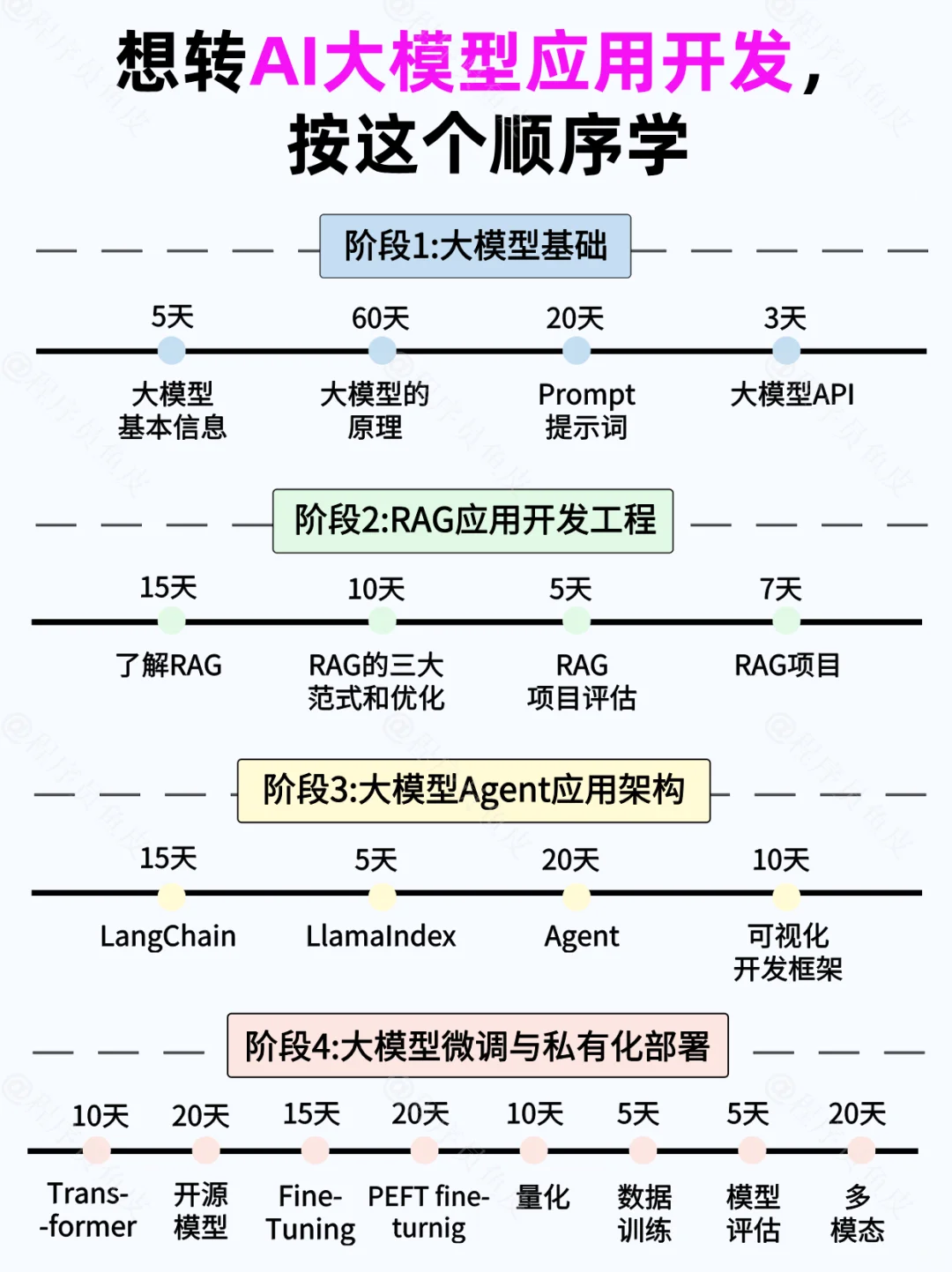



四、AI大模型从0到精通全套学习大礼包
我在一线互联网企业工作十余年里,指导过不少同行后辈。帮助很多人得到了学习和成长。
只要你是真心想学AI大模型,我这份资料就可以无偿共享给你学习。大模型行业确实也需要更多的有志之士加入进来,我也真心希望帮助大家学好这门技术,如果日后有什么学习上的问题,欢迎找我交流,有技术上面的问题,我是很愿意去帮助大家的!
如果你也想通过学大模型技术去帮助就业和转行,可以扫描下方链接👇👇
大模型重磅福利:入门进阶全套104G学习资源包免费分享!
01.从入门到精通的全套视频教程
包含提示词工程、RAG、Agent等技术点
02.AI大模型学习路线图(还有视频解说)
全过程AI大模型学习路线


03.学习电子书籍和技术文档
市面上的大模型书籍确实太多了,这些是我精选出来的


04.大模型面试题目详解


05.这些资料真的有用吗?
这份资料由我和鲁为民博士共同整理,鲁为民博士先后获得了北京清华大学学士和美国加州理工学院博士学位,在包括IEEE Transactions等学术期刊和诸多国际会议上发表了超过50篇学术论文、取得了多项美国和中国发明专利,同时还斩获了吴文俊人工智能科学技术奖。目前我正在和鲁博士共同进行人工智能的研究。
所有的视频由智泊AI老师录制,且资料与智泊AI共享,相互补充。这份学习大礼包应该算是现在最全面的大模型学习资料了。
资料内容涵盖了从入门到进阶的各类视频教程和实战项目,无论你是小白还是有些技术基础的,这份资料都绝对能帮助你提升薪资待遇,转行大模型岗位。


智泊AI始终秉持着“让每个人平等享受到优质教育资源”的育人理念,通过动态追踪大模型开发、数据标注伦理等前沿技术趋势,构建起"前沿课程+智能实训+精准就业"的高效培养体系。
课堂上不光教理论,还带着学员做了十多个真实项目。学员要亲自上手搞数据清洗、模型调优这些硬核操作,把课本知识变成真本事!

如果说你是以下人群中的其中一类,都可以来智泊AI学习人工智能,找到高薪工作,一次小小的“投资”换来的是终身受益!
应届毕业生:无工作经验但想要系统学习AI大模型技术,期待通过实战项目掌握核心技术。
零基础转型:非技术背景但关注AI应用场景,计划通过低代码工具实现“AI+行业”跨界。
业务赋能 突破瓶颈:传统开发者(Java/前端等)学习Transformer架构与LangChain框架,向AI全栈工程师转型。
👉获取方式:
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 13
13 0
0- 0



 已为社区贡献198条内容
已为社区贡献198条内容

所有评论(0)