【Agent】Kimi K2: Open Agentic Intelligence
Kimi K2,参数量为1T,激活参数为320亿参数的MoE模型。利用标记高效的MuonClip优化器和15.5 T标记高质量数据集(主要涉及:Web文本、代码、数学和知识)进行预训练。构建工具合成和用户问题合成Pipline,使用3000+真实MCP工具,合成20000种工具,在SFT阶段训练智能体工具使用能力。在RL阶段,训练数学、STEM和逻辑推理领域能力。
论文:https://arxiv.org/abs/2507.20534
代码:https://github.com/moonshotai/Kimi-K2
简介
Kimi K2,参数量为1T,激活参数为320亿参数的MoE模型。利用标记高效的MuonClip优化器和15.5 T标记高质量数据集(主要涉及:Web文本、代码、数学和知识)进行预训练。构建工具合成和用户问题合成Pipline,使用3000+真实MCP工具,合成20000种工具,在SFT阶段训练智能体工具使用能力。在RL阶段,训练数学、STEM和逻辑推理领域能力。
1、优化器进行优化
一种新的优化器MuonClip,它将令牌高效的Muon算法与称为QK-Clip的稳定性增强机制集成在一起。使用MuonClip,我们成功地在15.5万亿token上对Kimi K2进行了预训练,没有出现一次损失峰值。
2、训练数据增管方案
epoch太少,学习不够充分,epoch太多,学习会过拟合。为了让模型能充分学习知识并且不过拟合,采用对原始数据进行数据增广的方式,让LLM基于原始数据生成更多种类的新数据,使用这些新数据和原始数据训练一轮,发现比原始数据训练多轮效果更好。
-
知识数据重述:采用不同风格和观点重述原始数据内容。
- 风格和视角多样化的提示:为了在保持事实完整性的同时增强语言的多样性,我们采用了一系列精心设计的提示。这些提示引导一个大型语言模型,以不同的风格和不同的角度生成忠实的原始文本的改写。
- 基于块的自回归生成:为了保持全局一致性并避免长文档中的信息丢失,采用了基于块的自回归重写策略。文本被分成几段,单独改写,然后拼接在一起形成完整的段落。这种方法减轻了通常存在于大型语言模型中的隐式输出长度限制。
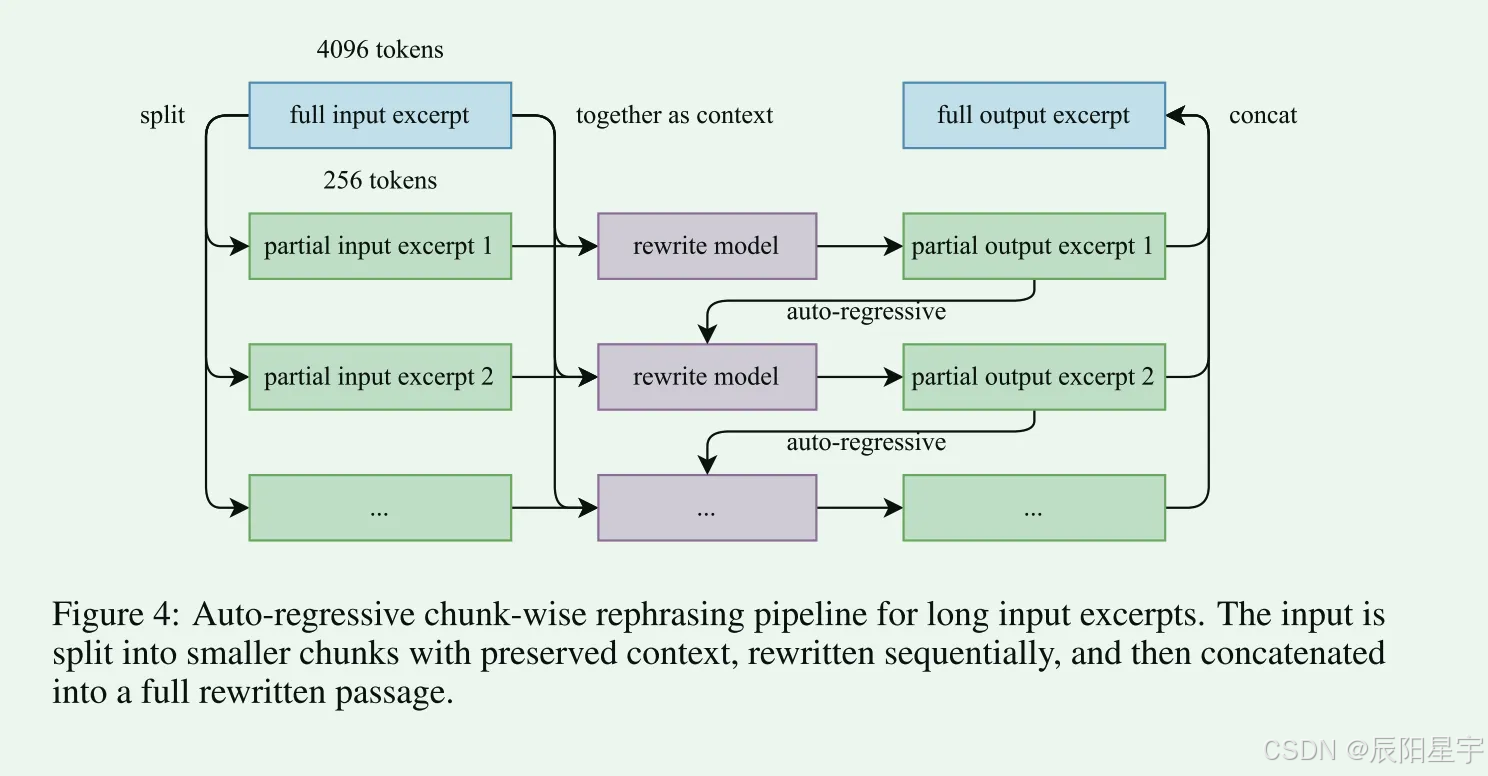
- 保真度验证:为了确保原始和重写内容之间的一致性,执行保真度检查,比较每个改写段落与其源的语义一致性。这是培训前的初始质量控制步骤。

-
数学数据重述:将数学文档采用SwallowMath中的方式,重写为“learning-note”,将其他语言数学材料翻译成英文。
3、预训练模型
训练数据
15.5万亿高质量数据,主要四个方面:Web文本、代码、数学和知识。
训练模型
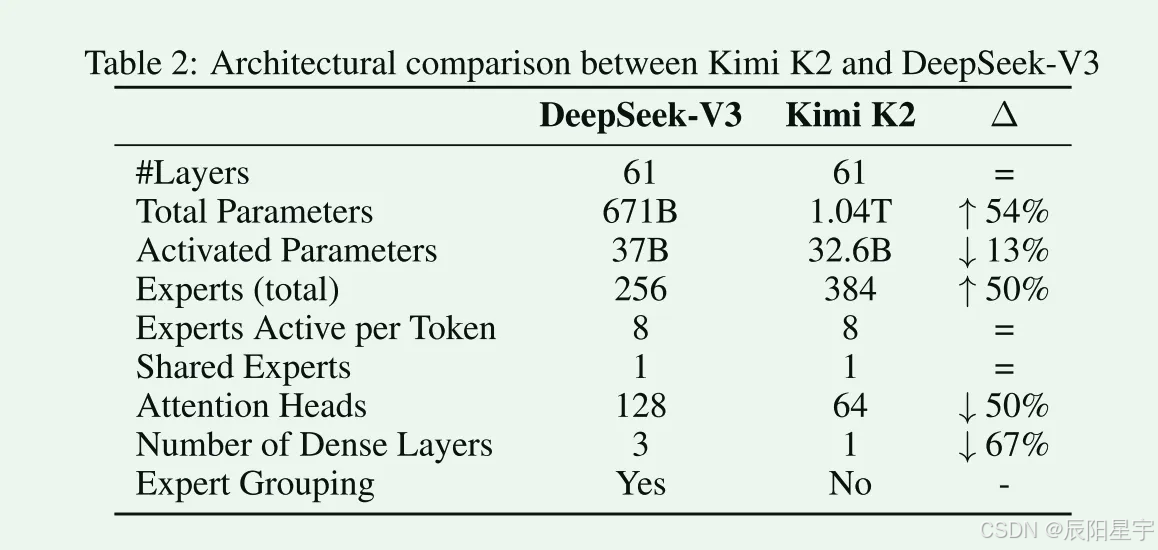
Kimi K2是 1.04万亿参数的MoE模型,激活值320亿个激活参数。采用和DeepSeek-V3类似的架构,采用MLA注意机制,模型隐藏层维度7168,MoE专家隐藏层维度2048。
- 稀疏度扩展:经验显示,稀疏度(专家总数:激活专家)的持续增加会产生实质的性能改善,将MoE专家个数增加到了384个。为减少计算开销,注意力头数减少到64个。
- 注意力头数扩展:DeepSeek-V3的注意力头数是模型层数的大约两倍,但随着序列长度增加,过多的注意力头数会增加推理开销。经实验发现,注意力头数变为两倍,只会对验证损失产生微小的改善(从0.5%到1.2%范围之内),由于已经增加了稀疏度,考虑到边际收益不合理,只设置为64个头。
4、后训练模型
训练数据
SFT
-
提供了一个工具、任务、执行轨迹合成pipline
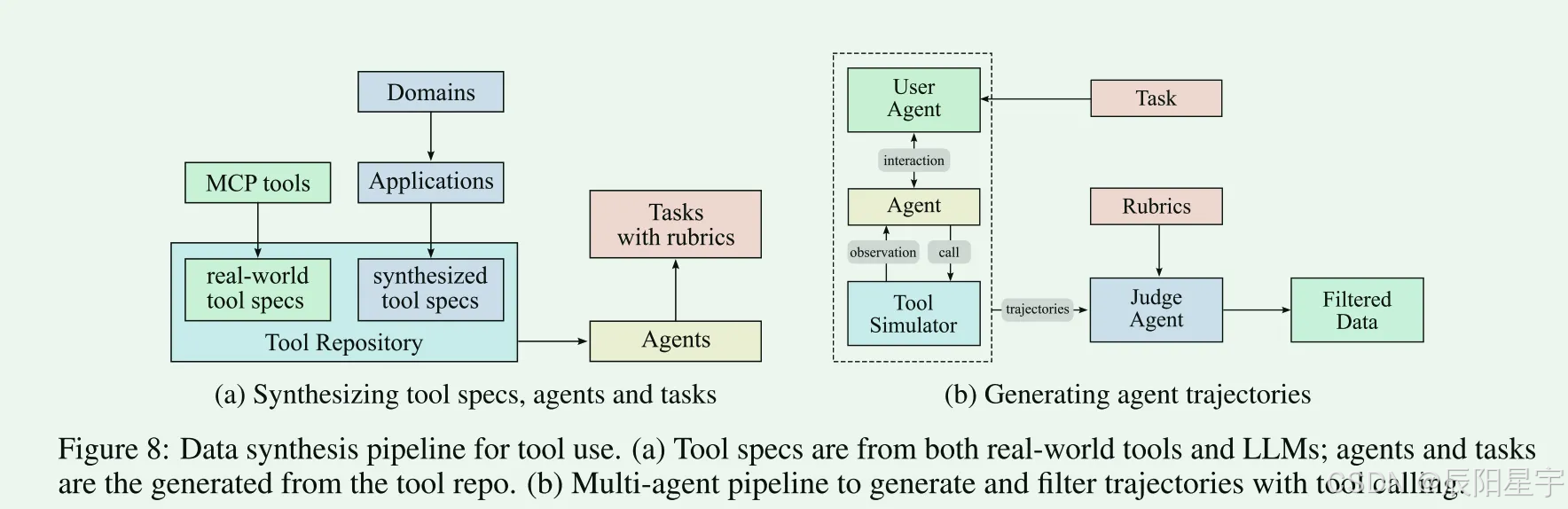
- 使用3000+真实MCP工具,合成20000种工具。每个Agent配备从简单到复杂操作的任务,每个任务都有一个明确的规则,该规则制定了成功的标准、预期的工具使用模式和评估检查点。
- 多轨迹生成:1)用户模拟:使用LLM生成不同风格和偏好的用户;2)工具执行环境:使用合成工具执行并提供真实世界的反馈
- 质量过滤:使用LLM对每个轨迹根据规则进行评判。
- 数据质量混合:为了保证与真实世界一致的反馈特性,使用一个真实的执行沙箱来模拟环境。
RL
强化学习(RL)被认为比SFT具有更好的标记效率和泛化能力。开发了一个类似gym的可扩展框架,以促进RL在各种场景中的应用。
验证奖励
对于数学,STEM和逻辑推理领域,RL数据准备遵循两个关键原则,多样化的覆盖范围和适度的难度。
- 多样化:对于数学和stem任务,使用专家注释、内部QA提取管道和开放数据集的组合来收集高质量的QA对。在收集过程中,我们利用标记系统故意增加未覆盖域的覆盖率。对于逻辑任务,我们的数据集包含各种格式,包括结构化数据任务(例如,多跳表推理,跨表聚合)和逻辑谜题(例如,24局游戏,数独,谜语,密码和莫尔斯码解码)。
- 适当难度:RL提示集不能太简单也不能太难,因为太简单会产生很小的信号,降低学习效率。我们使用SFT模型的pass@k准确性评估每个问题的难度,并只选择中等难度的问题。
复杂指令遵循
有效的指令遵循不仅需要理解明确的约束,还需要导航隐含的需求,处理边缘情况,并保持扩展对话的一致性。
- 混合规则验证:(1)通过代码解释器对具有可验证输出(例如,长度、风格约束)的指令进行确定性评估;(2)对于需要对约束有细微理解的指令使用llm进行评估。为了解决潜在的对抗行为,即模型可能在没有实际遵守的情况下声称指令实现,合成了一个额外的黑客检查层,专门检测这种欺骗性的声明。
- 多源指令生成:(1)专门的专家制作的复杂条件提示和规则;(2)受AutoIF启发Agent指令增强;(3)微调一个专门用于生成指令的模型,用于生成探测特定故障模式或边缘情况的附加指令。
RL算法
采用K1.5中提出的策略优化算法。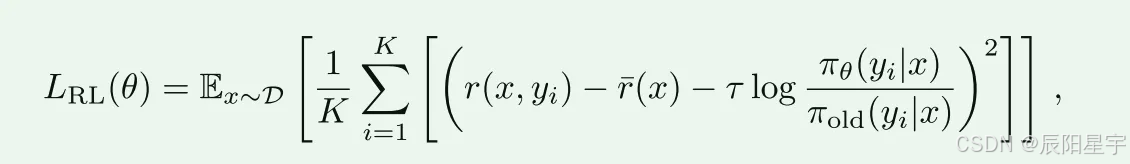
其中 r ^ _ ( x ) = 1 k ∑ i = 1 k r ( x , y i ) \hat{r}\_(x)=\frac{1}{k}\sum_{i=1}^kr(x,y_i) r^_(x)=k1∑i=1kr(x,yi)是采样响应的平均奖励。最后一项的系数大于0是促进稳定学习的正则化参数。
为了让模型能高效的使用token,设置了一个最大token惩罚项,当response超出这个阈值,则会被截断并被惩罚。
训练细节
引入温度衰减时间表,在前期使用高值temperature,后面如果保持高值会影响输出质量,过于随机。在后期阶段,减小temperature,将其从探索,转为利用,保证输出稳定且高质量。
5、工具调用模版
工具调用token中有三个组件:
● 工具声明消息:定义可用工具的列表和参数的模型
● 助手消息中的工具调用部分:编码模型调用工具的请求
● 工具结果消息:封装被调用工具的执行结果
蓝色标记是特殊token,绿色标记是工具声明内容。工具声明有两种形式:
(1)JSON形式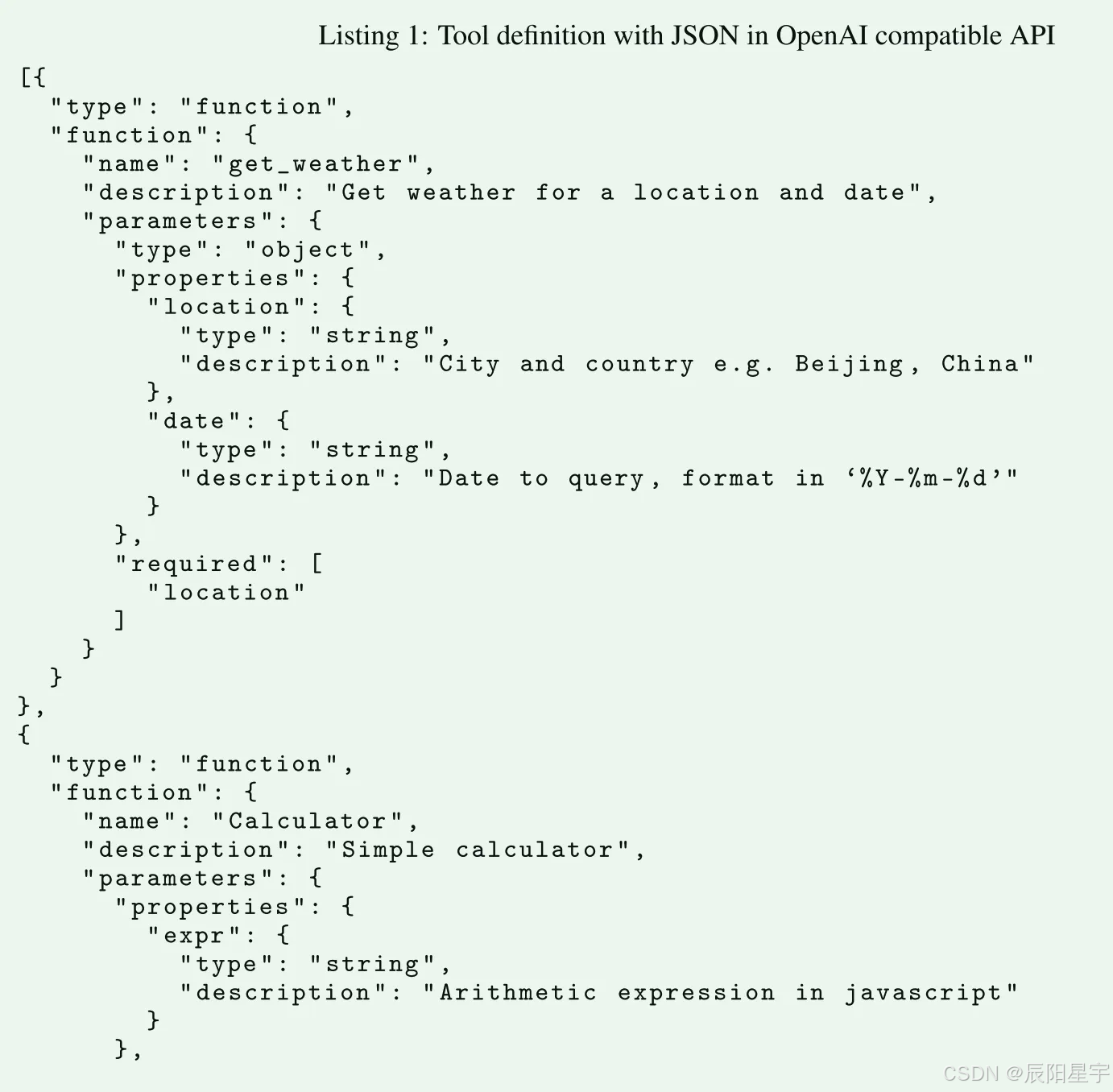

(2)TypeScript形式

模型响应消息中工具调用部分的令牌模板如下所示:
● 在单个响应轮中放置多个工具调用来支持并行工具调用。每个工具调用都有一个唯一的调用id,格式化为函数。{tool-name}:{counter},其中tool-name是工具的名称,counter是对话框中从0开始的所有工具调用的自动递增计数器。
● 在推理期间,模型可能偶尔会生成意外的token,从而在解析工具调用时导致格式错误。为了解决这个问题,受lm-format-enforcer的启发,开发了一个名为enforcer的受限解码模块。当生成<tool_call_section_begin|>时,它确保即将到来的与工具相关的token遵循预定义的模板,并且JSON参数字符串遵循声明的模式。
工具结果消息是用工具的调用id和相应的结果编码的文本消息。
6、通用RL数据规则评判准则
核心准则
- 清晰性和相关性:评估响应的简洁程度,同时充分解决用户的意图。重点是消除不必要的细节,与中心查询保持一致,并使用有效的格式,如简短的段落或紧凑的列表。除非特别要求,否则应避免冗长的逐项说明。当需要选择时,回应应该清楚地提供一个单一的、定义明确的答案
- 会话流畅性和参与度:评估回应对自然流畅的对话的贡献,而不仅仅是简单的问答。这包括保持连贯性,表现出对话题的适当参与,提供相关的观察或见解,在适当的时候潜在地建设性地引导谈话,明智地使用后续问题,优雅地处理假设或个人类比问题,有效地调整语气以适应对话环境(例如,共情的、正式的、随意的)。
- 客观和有根据的交互:评估响应保持客观和有根据的语气的能力,直接关注用户请求的实质。它评估避免元评论(分析查询的结构、主题组合、感知到的奇怪现象或交互本身的性质)和针对用户或其输入的毫无根据的奉承或过度赞扬。优秀的回应尊重而中立,优先考虑直接的、以任务为中心的帮助,而不是对谈话动态的评论或试图通过赞美来讨好。
规定性规则
- 最初的赞美:回应不能以直接对用户或问题的赞美开始(例如,“这是一个漂亮的问题”,“好问题!”)。
- 明确的理由:解释为什么响应是好的,或者它如何成功地满足了用户的要求的任何句子或从句。这与简单地描述内容不同。
限制
- 避免自我限制:规定性规则禁止自我评估、明确的免责声明或模棱两可的语言(例如,“这可能不准确”、“我可能错了”)。虽然这些短语可以反映认知上的谦卑,但它们经常被认为是非信息性的或表现性的。
- 对清晰和独特的偏好:当用户要求推荐或解释时,标题奖励直接,果断的答案。在复杂或开放式的场景中,这可能会抑制适当谨慎或多角度的反应。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 24
24 0
0- 0



 已为社区贡献19条内容
已为社区贡献19条内容

所有评论(0)