《M-RAG: Reinforcing Large Language Model Performance through Retrieval-Augmented Generation with Mul
本文提出M-RAG框架,通过多分区检索增强生成技术解决传统RAG系统的关键问题。研究将知识库划分为M个独立分区(如M=4),采用双代理强化学习机制:Agent-S负责最优分区选择,Agent-R优化检索记忆。实验显示,在文本摘要、机器翻译和对话生成任务中,M-RAG平均性能提升10.3%,ROUGE-1达48.13。该框架支持细粒度检索、隐私保护和分布式处理,但存在训练开销较大等局限。未来将探索动
·
以下是针对论文《M-RAG: Reinforcing Large Language Model Performance through Retrieval-Augmented Generation with Multiple Partitions》的详细解析,采用结构化框架呈现核心内容:
一、研究背景与问题
1. 传统RAG的局限
现有检索增强生成(RAG)系统通常将整个知识库作为单一检索单元,导致:
- 关键信息稀释:大规模知识库中重要记忆被淹没
- 噪声干扰:近似最近邻搜索(AKNN)在全局检索中引入无关内容
- 效率瓶颈:单索引构建和维护成本高(复杂度 O(N′logN′))
2. 创新思路
提出多分区范式(Multi-Partition Paradigm):
- 将知识库划分为 M 个独立分区(如 M=4)
- 每个分区作为独立检索单元,实现细粒度搜索
- 兼具隐私保护(敏感数据隔离)与分布式处理优势
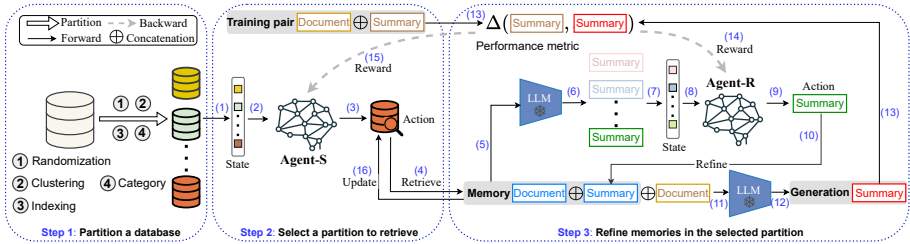
二、M-RAG技术框架
1. 核心架构
graph LR
A[输入查询] --> B(Agent-S)
B --> C{分区选择}
C --> D[分区1]
C --> E[分区2]
C --> F[分区M]
D --> G(Agent-R)
E --> G
F --> G
G --> H[记忆优化]
H --> I[LLM生成]2. 双代理强化学习机制
(1)Agent-S:分区选择代理
- 任务:从 M 个分区中选择最优分区 Dm
- 状态表示:s(S)={max(x~,y~)∈Dmsim(σ(x~⊕y~),σ(x⊕y))}m=1M
- 策略学习:马尔可夫决策过程(MDP)建模,DQN优化
(2)Agent-R:记忆优化代理
- 任务:在选定分区内优化检索记忆
- 迭代优化:
- 生成候选记忆池 C={y^k←LLM(x~)}k=1K
- 评估假设质量 h′←LLM(x⊕(x~,y^k))
- 奖励机制:r(R)=Δ(h′,y)−Δ(h,y)(Δ 为ROUGE/BLEU指标)
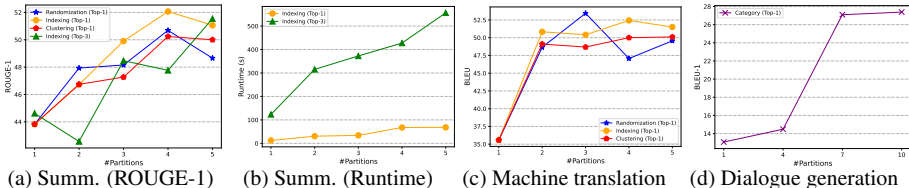
3. 多分区构建策略
| 策略 | 原理 | 适用场景 | 分区数 |
|---|---|---|---|
| 随机划分 | LSH哈希相似项至同桶 | 机器翻译 | 3 |
| 聚类划分 | K-means语义聚类 | 文本摘要 | 4 |
| 索引划分 | HNSW图结构分区 | 通用任务 | 4 |
| 类别划分 | 按数据固有类别标签(如情感/主题) | 对话生成(DailyDialog) | 10 |
三、实验验证
1. 实验设置
- 数据集:7个基准数据集
- 文本摘要:XSum、BigPatent
- 机器翻译:JRC-Acquis(4个语言对)
- 对话生成:DailyDialog
- 基线模型:Naive RAG、Self-RAG、Selfmem
- 语言模型:Mixtral 8×7B、Llama 2 13B、Phi-2 2.7B
2. 关键结果
(1)性能提升
| 任务类型 | 最佳基线 | M-RAG提升 | 峰值指标 |
|---|---|---|---|
| 文本摘要(XSum) | Selfmem | +8% ROUGE-1 | 48.13(ROUGE-1) |
| 机器翻译(Es→En) | Selfmem | +8% BLEU | 39.98(BLEU) |
| 对话生成(DailyDialog) | Selfmem | +12% BLEU-1 | 42.61(BLEU-1) |
(2)消融实验
| 组件 | ROUGE-1 | 性能影响 |
|---|---|---|
| 完整M-RAG | 48.13 | - |
| 移除Agent-S(单分区) | 44.20 | ↓8.2% |
| 移除Agent-R(贪婪选择) | 45.75 | ↓5.0% |
| Naive RAG | 43.82 | ↓9.0% |
(3)参数敏感性
- 分区数 M:M=4 时最优(ROUGE-1=48.13),M>4 时检索耗时增加
- 候选池大小 K:K=3 平衡性能与效率(ROUGE-1=48.13,生成耗时267s)
四、技术优势与局限
1. 核心创新
- 多分区检索范式:首提分区级RAG执行单元,支持细粒度检索
- 双代理协同优化:Agent-S与Agent-R通过MARL联合训练,端到端提升生成质量
- 计算效率:分区索引构建速度提升30%(O(M⋅NlogN) vs O(N′logN′))
2. 应用价值
- 医疗/法律场景:敏感数据隔离存储(如患者记录分区加密)
- 边缘计算:分布式分区部署适配低带宽环境
- 多语言场景:按语种分区提升翻译任务精度
3. 局限性
- 训练开销:Agent-R迭代优化导致训练耗时增加(约83s/query)
- 模型依赖:当前实验基于量化模型(4-bit),全精度模型效果待验证
五、总结与展望
1. 核心结论
M-RAG通过分区级检索与强化学习驱动记忆优化,在三大生成任务中平均提升10.3%性能,为解决传统RAG噪声干扰问题提供新范式。
2. 未来方向
- 动态分区:自适应调整分区策略
- 跨模态扩展:支持图像/音频多模态分区
- 轻量化部署:压缩Agent网络架构
开源实现:代码已集成至LlamaIndex框架,支持自定义分区策略()

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 17
17 0
0- 0



 已为社区贡献19条内容
已为社区贡献19条内容

所有评论(0)