错题智能识别分析项目的开发
ErrorMind是一款基于AI的智能错题管理系统,通过图像识别和深度学习技术帮助学生高效整理分析错题。系统采用Python+Flask技术栈,核心功能包括:1)智能OCR识别(Tesseract-OCR)自动提取题目文本;2)DeepSeek API进行错题分析,生成知识点标签和难度评估;3)数据可视化展示学习弱项;4)提供个性化学习建议。系统支持多学科分类,采用SQLite数据库存储错题记录,
# ErrorMind - 智能错题管理系统 📚


## 项目简介
ErrorMind 是一个基于AI的智能错题管理系统,通过图像识别和深度学习技术,帮助学生高效整理和分析错题,提供个性化学习建议。
## 功能特性 ✨
- **智能OCR识别**:自动提取图片中的题目文本
- **AI错题分析**:深度解析错误原因和知识点
- **数据可视化**:直观展示学习弱项
- **学习建议**:生成个性化提升方案
- **多学科支持**:覆盖主流学科分类
## 📂 项目结构、
- 📁 ErrorMind/
- 📄 app.py # Flask应用主入口
- 📄 config.py # 应用配置文件
- 📄 learning.db # SQLite数据库文件
- 📁 database/ # 数据库模块
- 📄 init.py
- 📄 operations.py # 数据库CRUD操作
- 📁 services/ # 业务服务
- 📄 ai_service.py # DeepSeek AI分析服务
- 📄 ocr_service.py # OCR文字识别服务
- 📁 static/ # 静态资源
- uploads/ # 用户上传文件存储
- 📁 templates/ # Jinja2模板
- 📄 dashboard.html # 数据看板
- 📄 history.html # 错题历史
- 📄 index.html # 首页
- 📄 result.html # 分析结果
## 技术栈
| 模块 | 技术选型 | 说明 |
|------------|------------------|--------------------------|
| 前端 | Bootstrap + jQuery | 轻量级响应式设计 |
| 后端 | Flask | Python轻量框架 |
| 数据库 | SQLite | 内嵌数据库,无需单独部署 |
| OCR识别 | Tesseract-OCR | 开源解决方案 |
| AI分析 | DeepSeek API | 直接调用云端能力 |
| 可视化 | Chart.js | 轻量级图表库 |
## 🚀 快速开始
# 📦 依赖安装指南
## 系统要求
- Python 3.13+
- pip 20.0+
- 推荐使用虚拟环境
## 基础安装
### 1. 创建虚拟环境(推荐)
```bash
python -m venv env
source env/bin/activate # Linux/Mac
env\Scripts\activate # Windows
```
### 2.安装依赖命令:
```bash
pip install flask pytesseract pillow requests
```
### 3. 运行项目
```bash
python app.py
一、Tesseract-OCR的安装
Tesseract-OCR是一款开源的OCR引擎,具备出色的多语言识别能力,涵盖多种常见及小众语言。其广泛应用于文档扫描、图像文字提取等任务,能高效准确地完成文字识别工作。本文将详细介绍如何在Windows平台上安装Tesseract-OCR 5.5.0版本。
(1)访问Tesseract OCR的GitHub项目页面(“https://github.com/UB-Mannheim/tesseract/wiki”),下载tesseract-ocr-w64-setup-5.5.0.20241111.exe安装包。
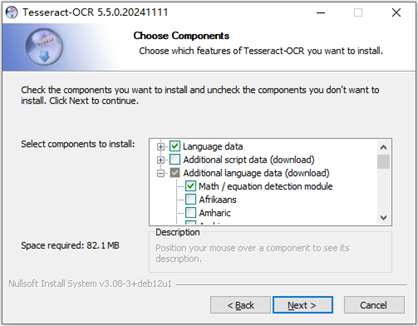
(2)由于网络等因素可能导致语言包下载失败。此时需要前往(https://github.com/tesseract-ocr/tessdata)语言资源页面手动下载所需的语言包(例如中文简体chi_sim.traineddata)。然后将下载的语言包文件放到Tesseract OCR安装目录下的tessdata文件夹下即可(示例路径为D:\Tesseract-OCR\tessdata)。
(3)配置Tesseract-OCR环境变量,方便后续的使用。右键点击“此电脑->属性->高级系统设置->环境变量”,在系统变量中找 Path,点击编辑,新增Tesseract-OCR的路径(如D:\Tesseract-OCR),然后点击确定保存。
二、DeepSeek API秘钥的获取
在使用DeepSeek API接口时,需要提供相应的秘钥,来进行权限的验证。获取API秘钥需要前往DeepSeek官网(https://www.deepseek.com/),通过手机号进行账号注册,然后单击官网页面中的“API开发平台”进入管理页面。然后选择API keys选项,点击“创建API key”按钮,随意输入一个秘钥名称(如,aiApi)进行秘钥的创建:

三、数据库构建
整个项目出于简化与快速实现的目的,仅需要两张表即可完成基础的功能需求,一张用来存储历史错题记录(包含题目id、图片路径、OCR识别文本等字段),一张用来存放知识点统计信息(包含知识点标签、次数、学科等字段)。
import sqlite3
from datetime import datetime
from config import Config
# 初始化数据库,用来创建相应的表结构
def init_db():
conn = sqlite3.connect(Config.DATABASE)
c = conn.cursor()
# 创建错题表
c.execute('''CREATE TABLE IF NOT EXISTS mistakes (
id INTEGER PRIMARY KEY AUTOINCREMENT,
question TEXT NOT NULL,
analysis TEXT NOT NULL,
knowledge_tags TEXT,
difficulty INTEGER,
subject TEXT,
image_path TEXT,
timestamp DATETIME DEFAULT CURRENT_TIMESTAMP
)''')
# 创建知识点统计表
c.execute('''CREATE TABLE IF NOT EXISTS knowledge_stats (
tag TEXT PRIMARY KEY,
error_count INTEGER DEFAULT 0,
subject TEXT,
last_occurrence DATETIME
)''')
conn.commit()
conn.close()
四、图片识别
OCR识别服务主要是用来从图片中提取出文本信息
from PIL import Image
import pytesseract
# 处理图片,转变为灰度图,并二值化处理,提高图片中文字识别的准确度
def preprocess_image(image_path):
img = Image.open(image_path)
img = img.convert('L')
img = img.point(lambda x: 0 if x < 180 else 255)
return img
# 进行OCR图片识别,提取图片上的文字
def extract_text_from_image(image_path):
try:
img = preprocess_image(image_path)
text = pytesseract.image_to_string(img, lang='chi_sim+eng')
return text.strip()
except Exception as e:
return str(e)
测试图片
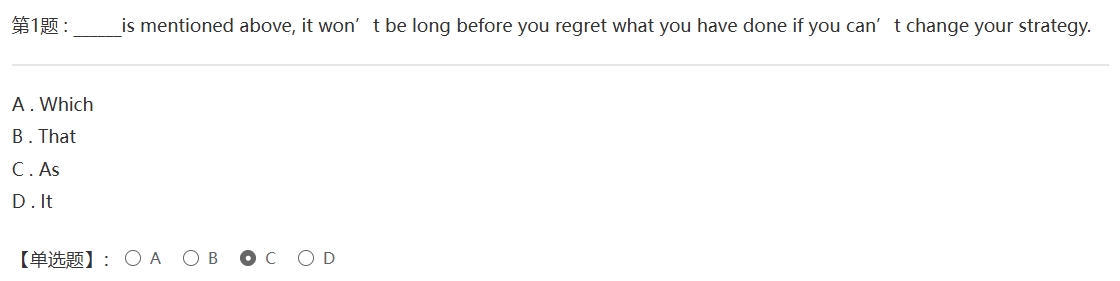
图片识别结果:
第 1 题 : is mentioned above, it won”t be long before you regret what you have done ifyou can” t change your strategy.
站 .Which
B.That
C .As
D .Ht
【 单 选 题 ] : OA O 〇 B @Cc co
受限于语言包的性能以及图片质量等情况的显示,OCR服务有时会出现部分字符无法识别或者识别错误,但是已经正确识别出了大部分文本,能够基本满足我们的需求,若是需要识别准确度更高的OCR识别服务,可以切换一些收费的OCR服务(如百度OCR API)。
五、AI错题解析
接收OCR提取的题目文本作为输入参数,并通过调用DeepSeek API对这个题目进行分析,生成指定格式的题目解析:
# 对OCR识别的错题图片文本调用AI进行分析,并生成符合要求的内容
def analyze_with_deepseek(question):
headers = {
"Authorization": f"Bearer {Config.API_KEY}",
"Content-Type": "application/json"
}
prompt = f"""
你是一名专业教师,请分析以下题目:
题目:{question}
请按照以下结构化格式返回分析结果:
{{
"analysis": "详细分析错误原因、解题思路和相关知识点",
"subject": "学科分类(数学、语文、英语、编程、物理、化学、生物、政治、历史、地理等)",
"knowledge_tags": ["知识点1", "知识点2", "知识点3"],
"difficulty": 难度等级(1-5的整数),
"summary": "题目解析(需要包含正确答案,解析长度在1000字以内)"
}}
要求:
1. 学科分类要准确
2. 知识点标签不超过3个,使用中文
3. 难度等级:1=非常简单,2=简单,3=中等,4=困难,5=非常困难
4. 确保返回结果是合法的JSON格式
"""
payload = {
"model": "deepseek-chat",
"messages": [
{"role": "system", "content": "你是一名专业教师,请准确分析题目"},
{"role": "user", "content": prompt}
],
"temperature": 0.3
}
try:
response = requests.post(Config.DEEPSEEK_API, json=payload, headers=headers)
response.raise_for_status()
result = response.json()
content = result['choices'][0]['message']['content']
json_match = re.search(r'\{[\s\S]*\}', content)
if json_match:
return json.loads(json_match.group(0))
return {"analysis": content}
except (json.JSONDecodeError, KeyError) as e:
return {"error": f"解析失败: {str(e)}", "raw_response": content}
except requests.exceptions.HTTPError as http_err:
return {"error": f"HTTP错误: {http_err}"}
except Exception as err:
return {"error": f"其他错误: {str(err)}"}
六、存储数据
将AI生成的解析数据,存储到数据库中:
# 将错题记录到数据库中,并更新知识点统计表
def save_mistake(question, analysis, image_path):
conn = sqlite3.connect(Config.DATABASE)
c = conn.cursor()
subject = analysis.get('subject', '未知')
difficulty = analysis.get('difficulty', 3)
knowledge_tags = analysis.get('knowledge_tags', [])
knowledge_tags = ",".join(knowledge_tags[:3]) if isinstance(knowledge_tags, list) else "未分类"
analysis_text = analysis.get('analysis', str(analysis))
c.execute('''INSERT INTO mistakes
(question, analysis, knowledge_tags, difficulty, subject, image_path)
VALUES (?, ?, ?, ?, ?, ?)''',
(question, analysis_text, knowledge_tags, difficulty, subject, image_path))
for tag in knowledge_tags.split(','):
if tag.strip():
c.execute('''INSERT OR IGNORE INTO knowledge_stats (tag,subject, error_count) VALUES (?,?, 0)''',
(tag, subject))
c.execute('''UPDATE knowledge_stats
SET error_count = error_count + 1, last_occurrence = datetime('now')
WHERE tag = ?''', (tag,))
conn.commit()
conn.close()
七、学情分析
使用DeepSeek API对根据用户最近的错题记录进行分析,生成指定格式的学习建议,具体实现代码如下所示:
def get_learning_recommendation():
recent_errors=get_recent_mistakes()
if not recent_errors:
return {
"success": False,
"message": "暂无足够数据生成学习建议,请先上传错题"
}
prompt = f"""
请根据以下学生近期错题记录,生成个性化的学习建议:
近期错题分析:
{''.join(recent_errors)}
请按照以下格式提供建议:
1. 主要薄弱知识点分析
2. 推荐的学习路径(3-5个步骤)
3. 3道针对性练习题(包含题目和答案)
"""
headers = {
"Authorization": f"Bearer {Config.API_KEY}",
"Content-Type": "application/json"
}
payload = {
"model": "deepseek-chat",
"messages": [{"role": "user", "content": prompt}],
"temperature": 0.5
}
try:
response = requests.post(Config.DEEPSEEK_API, json=payload, headers=headers)
response.raise_for_status()
result = response.json()
recommendation = str(result['choices'][0]['message']['content'])
return {
"success": True,
"recommendation": recommendation
}
except Exception as e:
return {
"success": False,
"message": f"生成学习建议时出错: {str(e)}"
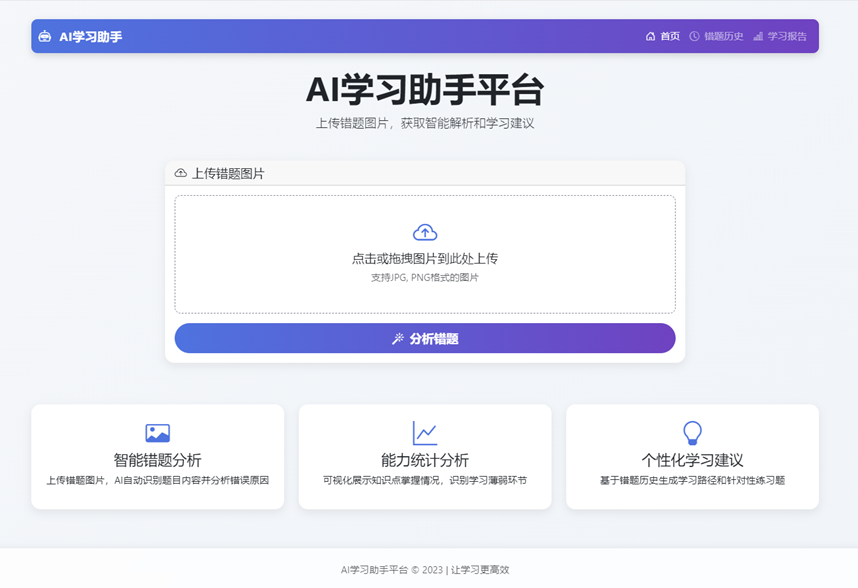
}八、项目运行效果图
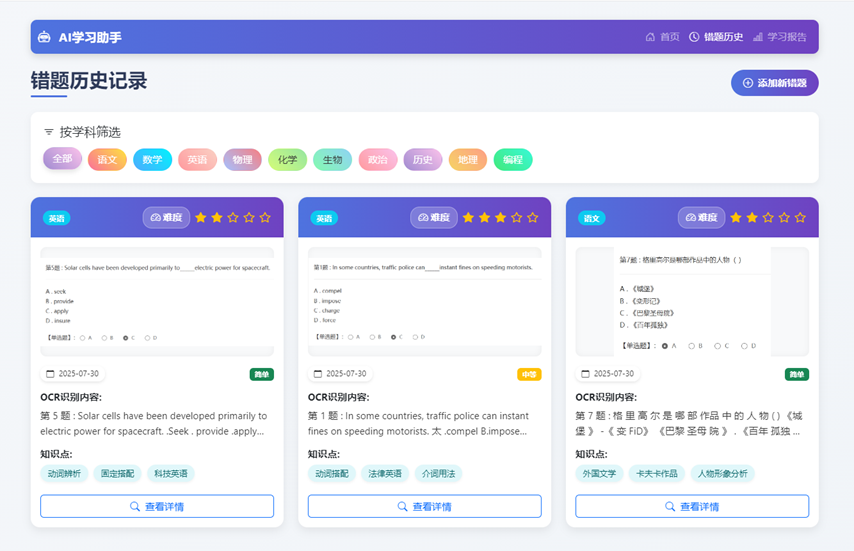
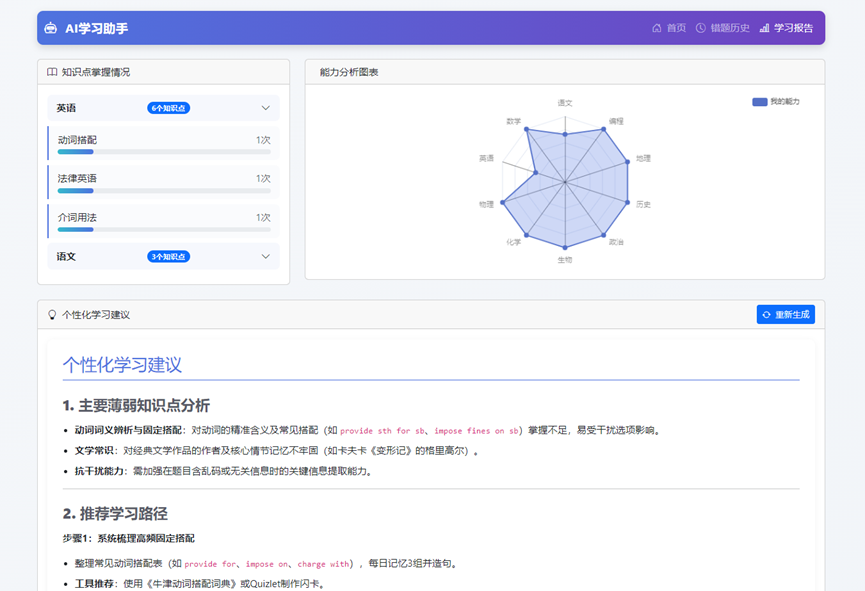

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 30
30 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)