CVPR 2025 | 兼顾局部性与连续性的图像复原Mamba,即插即用,涨点起飞!
摘要:四川大学团队提出MaIR模型,一种专为图像恢复设计的Mamba架构创新。该模型通过嵌套S型扫描策略(NSS)在保持零计算成本的前提下,有效维护图像局部性和空间连续性;结合序列混洗注意力模块(SSA)实现多方向特征智能融合。实验表明,MaIR在超分辨率、去噪等14项任务中超越40个SOTA模型,PSNR/SSIM指标显著提升。其核心模块可作为即插即用组件增强现有视觉Mamba模型,官方代码已开
1. 基本信息

-
标题: MaIR: A Locality- and Continuity-Preserving Mamba for Image Restoration (MaIR: 一种为图像恢复设计的保持局部性和连续性的 Mamba 模型)
-
论文来源: https://ieeexplore.ieee.org/document/11094318
-
作者与单位: Boyun Li, Haiyu Zhao, Wenxin Wang, Peng Hu, Yuanbiao Gou, Xi Peng。主要来自四川大学计算机科学学院。
2. 核心创新点
-
提出MaIR框架:一个专为图像恢复设计的 Mamba 模型,它在高效捕获长距离依赖的同时,首次成功地保持了自然图像固有的局部性(locality)和连续性(continuity)。
-
设计嵌套S型扫描策略 (NSS):一种零成本的图像扫描方法,通过“条带划分”保留局部区域信息,并利用“S型路径”维护像素间的空间连续性,解决了传统扫描方式破坏图像结构的问题。
-
引入序列混洗注意力模块 (SSA):一种新颖的序列聚合机制,通过计算并应用跨序列对应通道的注意力权重,有效融合来自不同扫描方向(如前向、后向)的互补信息。
➔➔➔➔点击查看原文,获取本文及其他精选即插即用模块集合![]() https://mp.weixin.qq.com/s/TcaBoo9sD3nWfb31gT6Acw
https://mp.weixin.qq.com/s/TcaBoo9sD3nWfb31gT6Acw
3. 方法详解
整体结构概述
MaIR 模型的整体架构遵循经典的三段式设计:浅层特征提取、深层特征提取和图像重建。输入的低质量图像首先经过一个卷积层提取浅层特征。这些特征随后被送入由多个残差Mamba组 (RMG) 堆叠而成的深层特征提取网络。每个RMG由若干个残差Mamba块 (RMB) 构成,而RMB的核心是*视觉Mamba模块 (VMM),其中嵌入了本文提出的关键组件 MaIR模块 (MaIRM)。最后,网络将浅层与深层特征融合,通过重建模块生成高质量的输出图像。
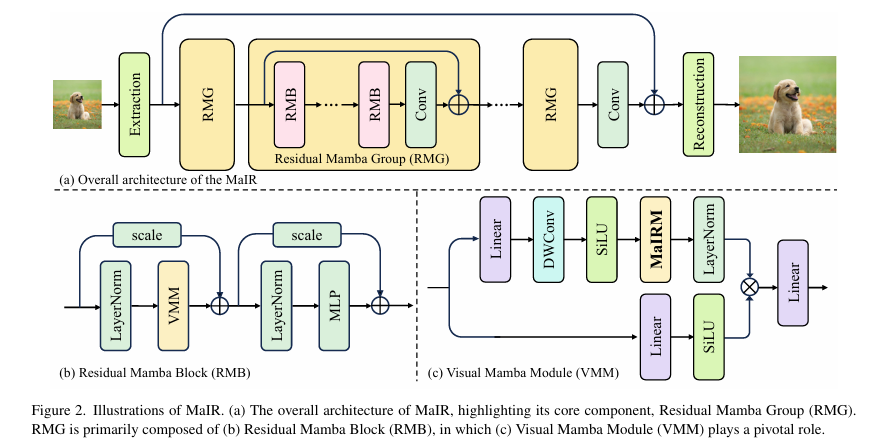
MaIR整体架构图
步骤分解
MaIR 的核心在于其 MaIR Module (MaIRM),其内部处理流程可分解为三个关键步骤:
- 嵌套S型扫描 (NSS):此步骤负责将二维图像特征图转换为一维序列,为 Mamba 的选择性扫描操作 (SSO) 做准备。
-
保持局部性: 将特征图划分为多个不重叠的垂直条带 (stripe)。扫描操作首先在单个条带内部进行,限制了感受野,从而保留了图像的局部结构。
-
保持连续性: 在每个条带内部以及条带之间,均采用S型扫描路径。这确保了扫描顺序在空间上是平滑过渡的,避免了传统Z型扫描的突变,从而维护了图像的连续性。
-
移位条带机制 (Shift-Stripe Mechanism): 在连续的 MaIRM 模块之间,条带的划分会进行半个宽度的移位。这使得在前一模块中位于条带边界的区域,在当前模块中被完整地包含在单个条带内,增强了相邻区域间的信息交流。
-
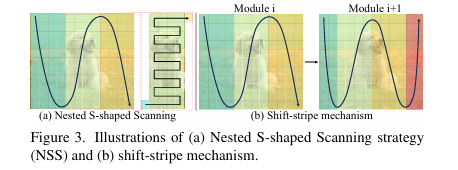
NSS策略和移位条带机制示意图
-
选择性扫描操作 (SSO):这是 Mamba 模型的核心。经过 NSS 展平后的四个方向(例如,左上到右下、右下到左上等)的一维序列,被独立地送入 SSO 模块。SSO 能够根据输入内容动态调整其狀態空间参数,从而以线性复杂度高效地捕获序列内的长距离依赖关系。
-
序列混洗注意力 (SSA):此步骤负责将经过 SSO 处理后的多条(通常是4条)一维序列智能地聚合回二维特征图。
-
特征提取与重排: 首先对每条序列进行空间平均池化以降低计算量,然后将它们拼接成一个长序列。通过序列混洗 (Sequence Shuffle) 操作,将不同序列在同一通道上的特征聚合在一起。
-
权重计算: 利用分组卷积(group convolution)对混洗后的序列进行处理,高效地为每个序列的每个通道计算出注意力权重。
-
加权聚合: 将权重反混洗 (Unshuffle) 回原始序列顺序,并对原始的四条序列(未经池化的)进行加权求和,最终得到融合了多方向上下文信息的输出特征。
-
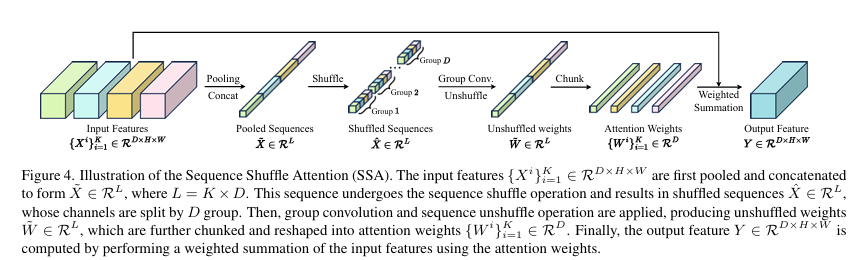
SSA模块工作流示意图
关键公式
-
MaIR 模块 (MaIRM) 的数学表达:
-
图像超分辨率使用的L1损失函数:
-
图像去噪、去模糊、去雾使用的Charbonnier损失函数:
-
SSA 模块的最终加权求和:
4. 即插即用模块作用
MaIR 的核心思想,特别是 NSS 和 SSA 模块,可以被视为对现有视觉 Mamba 模型的“即插即用”式增强。
适用场景
该技术可广泛应用于各种底层视觉和图像恢复任务,论文中已验证的场景包括:
-
图像超分辨率 (Classic & Lightweight)
-
图像去噪 (Synthetic & Real-world)
-
图像去模糊 (Motion Deblurring)
-
图像去雾 (Indoor & Outdoor)
主要作用
它能为现有的或未来的视觉 Mamba 模型带来以下具体收益:
-
模拟CNN的结构感知能力: 通过 NSS 策略,使原本处理一维序列的 Mamba 也能像 CNN 一样感知和保留图像的二维局部结构与空间连续性。
-
零计算开销: NSS 是一种扫描策略的重新设计,本身不引入任何额外的计算参数或浮点运算(FLOPs),实现了“零成本”的性能提升。
-
增强信息融合能力: SSA 模块提供了一种比简单相加更智能的序列聚合方式,能够自适应地融合不同扫描方向的特征,从而更充分地利用上下文信息。
-
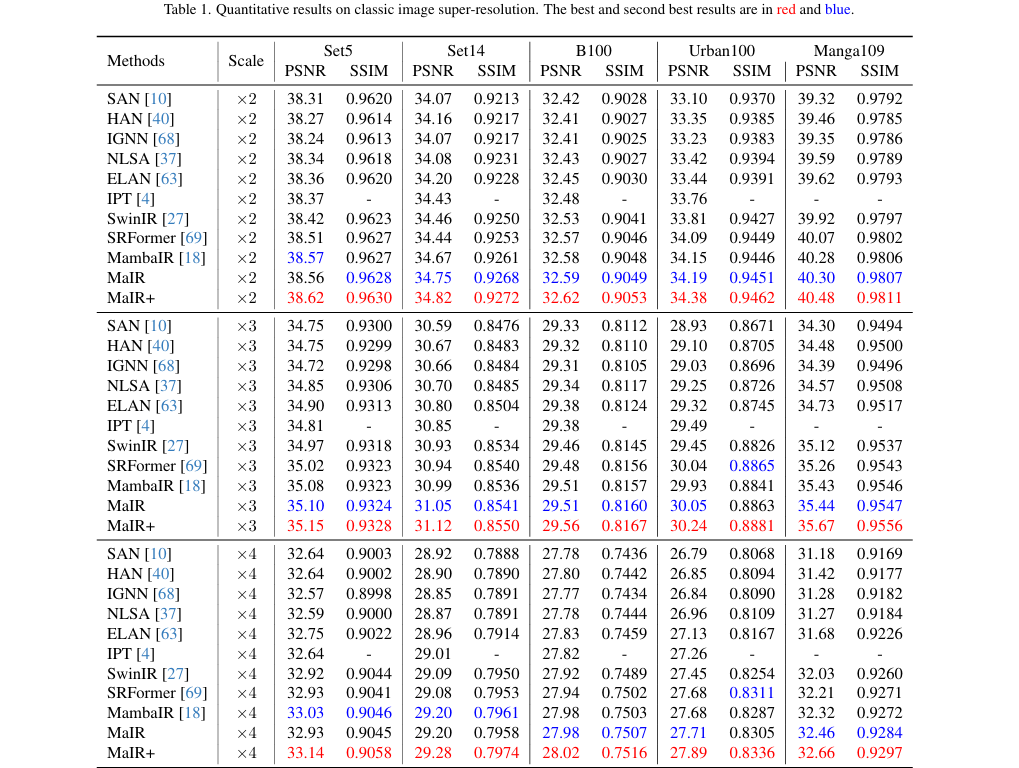
提升恢复质量: 显著提升图像恢复任务的性能指标(如PSNR/SSIM),在多达14个基准测试中超越了40个现有SOTA模型,生成视觉效果更自然、伪影更少的图像。
总结
MaIR 通过巧妙的“嵌套S型扫描”与“序列混洗注意力”机制,为视觉Mamba模型装上了“结构之眼”,使其在保持长距离建模优势的同时,精准捕捉图像的局部细节与连续性,成为图像恢复领域的性能新标杆。
➔➔➔➔点击查看原文,获取本文及其他精选即插即用模块集合![]() https://mp.weixin.qq.com/s/TcaBoo9sD3nWfb31gT6Acw
https://mp.weixin.qq.com/s/TcaBoo9sD3nWfb31gT6Acw
5. 即插即用模块
论文原文中未提供具体的代码片段,但其核心思想可以通过以下伪代码来理解。完整的实现细节请参考官方开源项目。
import torch
import torch.nn as nn
class SequenceShuffleAttention(nn.Module):
def __init__(self, in_features, out_features, hidden_features=None, group=4, act_layer=nn.GELU, input_resolution=(64,64)):
super().__init__()
self.group = group # 分组数,用于通道重排
self.input_resolution = input_resolution # 输入的分辨率
self.in_features = in_features # 输入特征通道数
self.out_features = out_features # 输出特征通道数
# 定义 gating 部分,使用平均池化后经过卷积层和 Sigmoid 激活
self.gating = nn.Sequential(
nn.AdaptiveAvgPool2d(1), # 自适应平均池化,输出大小为 1x1
nn.Conv2d(in_features, out_features, groups=self.group, kernel_size=1, stride=1, padding=0), # 卷积层,使用分组卷积
nn.Sigmoid() # Sigmoid 激活函数
)
# 通道重排操作,打乱输入张量的通道
def channel_shuffle(self, x):
batchsize, num_channels, height, width = x.data.size() # 获取输入张量的维度
assert num_channels % self.group == 0 # 确保通道数可以被分组数整除
group_channels = num_channels // self.group # 每个组的通道数
# 将输入张量 reshape 成 (batch_size, group_channels, group, height, width)
x = x.reshape(batchsize, group_channels, self.group, height, width)
# 调整维度顺序,使得每个组的通道打乱
x = x.permute(0, 2, 1, 3, 4)
# 将张量恢复成 (batch_size, num_channels, height, width)
x = x.reshape(batchsize, num_channels, height, width)
return x
# 通道重新排列操作,和通道重排类似,但这里不进行打乱,只是重新排列
def channel_rearrange(self, x):
batchsize, num_channels, height, width = x.data.size() # 获取输入张量的维度
assert num_channels % self.group == 0 # 确保通道数可以被分组数整除
group_channels = num_channels // self.group # 每个组的通道数
# 将输入张量 reshape 成 (batch_size, group, group_channels, height, width)
x = x.reshape(batchsize, self.group, group_channels, height, width)
# 调整维度顺序,使得每个组的通道重新排列
x = x.permute(0, 2, 1, 3, 4)
# 将张量恢复成 (batch_size, num_channels, height, width)
x = x.reshape(batchsize, num_channels, height, width)
return x
# 前向传播函数
def forward(self, x):
y = x # 保存输入张量,用于残差连接
x = self.channel_shuffle(x) # 对输入进行通道重排
x = self.gating(x) # 使用 gating 对输入进行处理
x = self.channel_rearrange(x) # 对处理后的张量进行通道重新排列
return y * x # 将原始输入与处理后的输出相乘
from torchinfo import summary # 需要安装 torchinfo:pip install torchinfo
if __name__ == '__main__':
# 设置输入参数
batch_size = 1 # 批次大小
in_channels = 32 # 输入通道数
out_channels = 32 # 输出通道数
input_resolution = (256, 256) # 输入分辨率
# 创建随机输入张量 (batch_size, channels, height, width)
x = torch.randn(batch_size, in_channels, input_resolution[0], input_resolution[1]).cuda() # 输入张量
# 创建 SequenceShuffleAttention 模块
model = SequenceShuffleAttention(in_features=in_channels, out_features=out_channels, input_resolution=input_resolution).cuda()
# 使用 torchinfo 进行模型分析
summary(model, input_size=(batch_size, in_channels, input_resolution[0], input_resolution[1]))
# 前向传播
output = model(x)
# 打印输入和输出张量的形状
print(f"输入张量形状: {x.shape}")
print(f"输出张量形状: {output.shape}")

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 5
5 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)