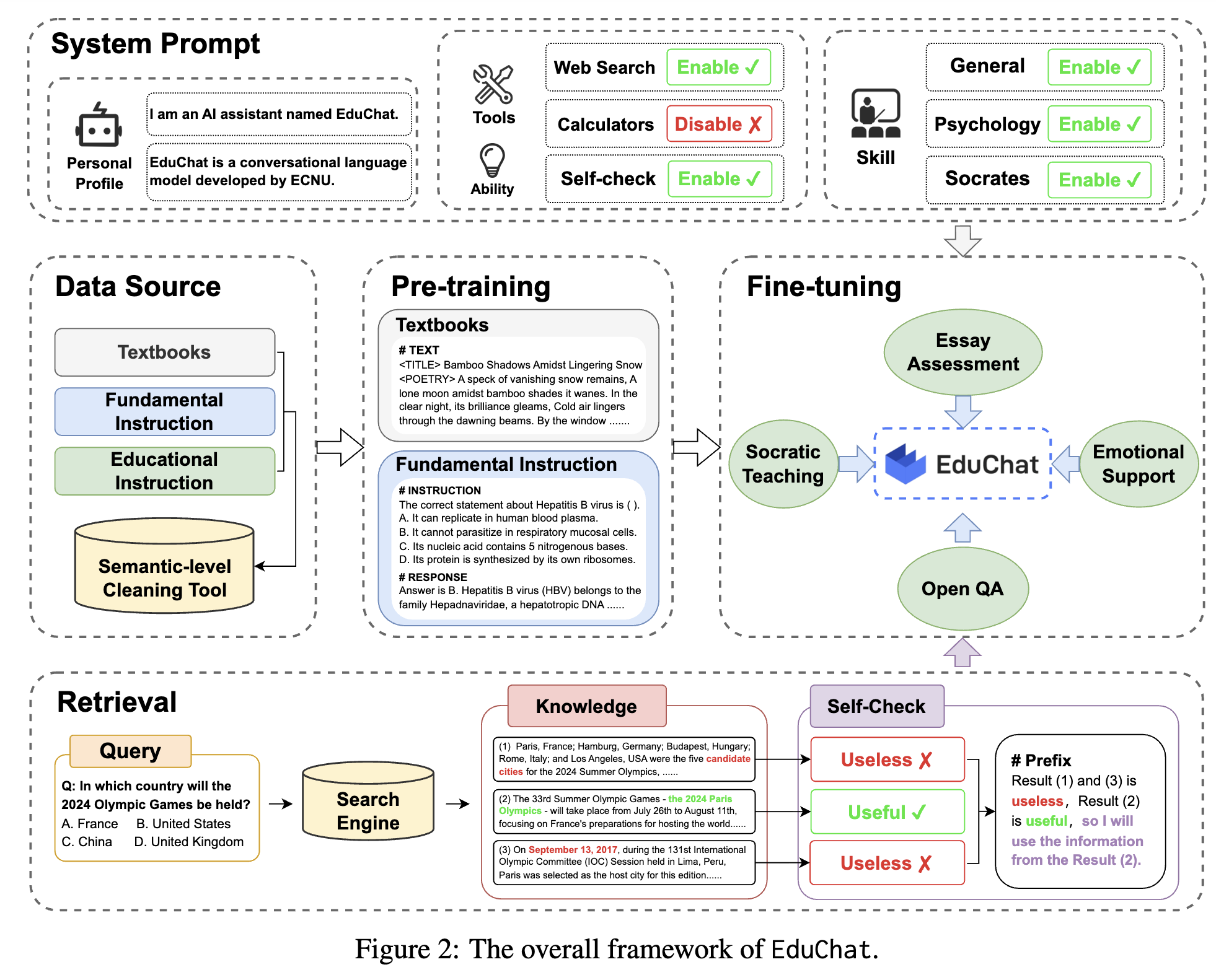
EduChat的EduChat-R1 (educhat-r1-001-8b-qwen3.0)的下载与使用
EduChat是华东师范大学开发的教育领域大模型,基于Qwen3.0 8B微调而成。本文介绍了如何下载使用该模型,包括选择educhat-r1-001-8b-qwen3.0版本,并提供了处理Excel文件的Python脚本。脚本自动加载模型,批量读取指定文件夹中的Excel文件,对每行第一列内容进行模型推理生成结果,并将输出写入第二列后保存。测试结果显示模型能成功处理教育相关问题,但作者认为这种微
·
0 相关资料
https://github.com/icalk-nlp/EduChat
https://arxiv.org/pdf/2308.02773
论文阅读:arxiv 2023 EduChat: A Large-Scale Language Model-based Chatbot System for Intelligent Education
b站视频:https://www.bilibili.com/video/BV15Ea3zQEVz/
EduChat是华东师范大学开发的 教育领域的垂直大模型,我的理解就是,把教育数据集在现有开源数据上微调一下,就变成教育大模型了,挺扯蛋的。
1 下载模型
https://github.com/icalk-nlp/EduChat
我选择了:EduChat-R1 (educhat-r1-001-8b-qwen3.0):基于Qwen3.0 8B训练得到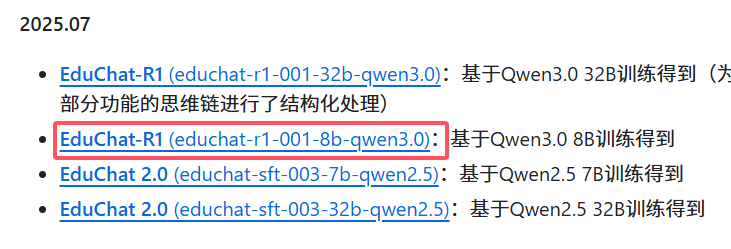
2 使用模型
下载下来后,我的文件体系如下:
执行脚本如下:
excel_processor.py
'''
这段代码用于加载指定的大语言模型,批量处理指定文件夹中的Excel文件,
对每个Excel文件从第二行开始的第一列内容进行模型生成处理,并将结果写入对应行的第二列后保存文件。
'''
import os
import pandas as pd
from modelscope import AutoModelForCausalLM, AutoTokenizer
import torch
def process_excel_files(folder_path):
# 加载模型和分词器
model_name = "/home/winstonYF/Qwen3/model/educhat-r1-001-8b-qwen3.0"
print(f"正在加载模型: {model_name}")
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(
model_name,
torch_dtype="auto",
device_map="auto"
)
model.eval() # 设置为评估模式
# 获取文件夹中所有Excel文件
excel_files = [f for f in os.listdir(folder_path)
if f.endswith(('.xlsx', '.xls', '.xlsm'))]
if not excel_files:
print("指定文件夹中没有找到Excel文件")
return
print(f"找到{len(excel_files)}个Excel文件,开始处理...")
# 逐个处理Excel文件
for file in excel_files:
file_path = os.path.join(folder_path, file)
print(f"\n处理文件: {file_path}")
try:
# 读取Excel文件,不使用第一行作为表头
df = pd.read_excel(file_path, header=None)
# 从第二行开始处理(索引为1)
for index, row in df.iterrows():
if index < 1: # 跳过第一行
continue
# 获取第一列内容
input_text = row[0] if pd.notna(row[0]) else ""
if not input_text:
print(f"行 {index+1} 第一列内容为空,跳过处理")
continue
print(f"处理行 {index+1}: {input_text[:50]}...")
# 准备模型输入
messages = [{"role": "user", "content": input_text}]
text = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True,
enable_thinking=False
)
model_inputs = tokenizer([text], return_tensors="pt").to(model.device)
# 生成回复
with torch.no_grad(): # 禁用梯度计算,节省内存
generated_ids = model.generate(
**model_inputs,
max_new_tokens=4096, # 适当调整最大生成 tokens
temperature=0.1, # 控制生成多样性
do_sample=True
)
# 解析生成结果
output_ids = generated_ids[0][len(model_inputs.input_ids[0]):].tolist()
try:
# 查找思考内容结束标记
index_thinking = len(output_ids) - output_ids[::-1].index(151668)
except ValueError:
index_thinking = 0
# 获取实际回复内容
content = tokenizer.decode(
output_ids[index_thinking:],
skip_special_tokens=True
).strip("\n")
# 将结果写入第二列
df.at[index, 1] = content
# 保存处理后的Excel文件
df.to_excel(file_path, index=False, header=None)
print(f"文件处理完成并保存: {file_path}")
except Exception as e:
print(f"处理文件 {file} 时出错: {str(e)}")
print("\n所有文件处理完毕")
if __name__ == "__main__":
# 指定Excel文件夹路径
excel_folder = "./excel"
process_excel_files(excel_folder)

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 5
5 0
0- 0



 已为社区贡献63条内容
已为社区贡献63条内容

所有评论(0)