Dify学习(三)
首先,需要做一个Agent工具,请求redbook连接后,可以拿到body,然后通过代码转换成想要的内容其次,我们需要一个图生图工具使用百度的千帆AI,跟视频课用的方法不一样,但是结果一样。自己使用的是直接HTTP请求变成了然后,就可以集合起来,搞一个red Book仿写了:应该是对的,但是报错,报错:说我调用的太频繁了。。。明天再试试。
·
13. Red book
首先,需要做一个Agent工具,请求redbook连接后,可以拿到body,然后通过代码转换成想要的内容
import re
import json
def main(html: str) -> dict:
# 提取og:title内容
og_title_pattern = r'<meta[^>]*name="og:title"[^>]*content="([^"]*)"'
og_title_match = re.search(og_title_pattern, html)
og_title = og_title_match.group(1) if og_title_match else ""
# 提取description内容
desc_pattern = r'<meta[^>]*name="description"[^>]*content="([^"]*)"'
desc_match = re.search(desc_pattern, html)
description = desc_match.group(1) if desc_match else ""
# 提取所有og:image内容
og_image_pattern = r'<meta[^>]*name="og:image"[^>]*content="([^"]*)"'
og_images = re.findall(og_image_pattern, html)
# 构建结果字典
result = {
"og_title": og_title,
"description": description,
"og_images": og_images
}
return {"result": result}
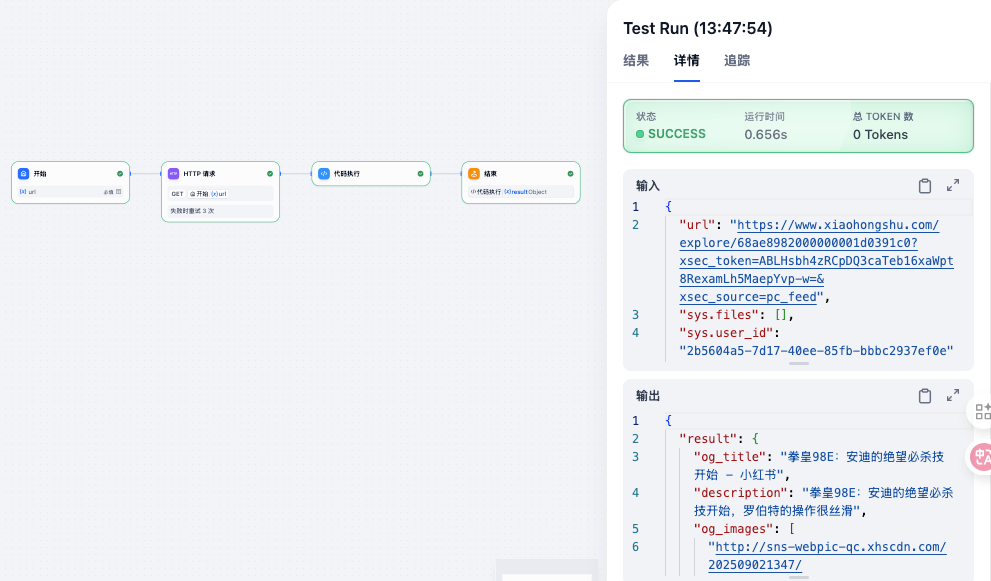
其次,我们需要一个图生图工具
使用百度的千帆AI,接口文档
跟视频课用的方法不一样,但是结果一样。自己使用的是直接HTTP请求
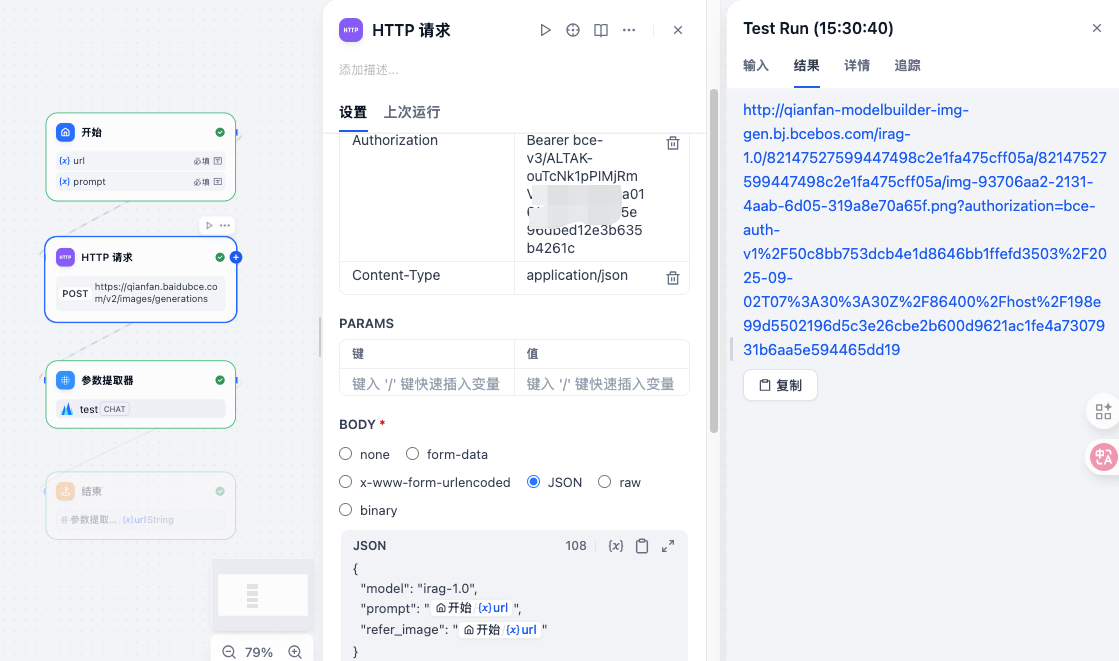
 变成了
变成了
然后,就可以集合起来,搞一个red Book仿写了: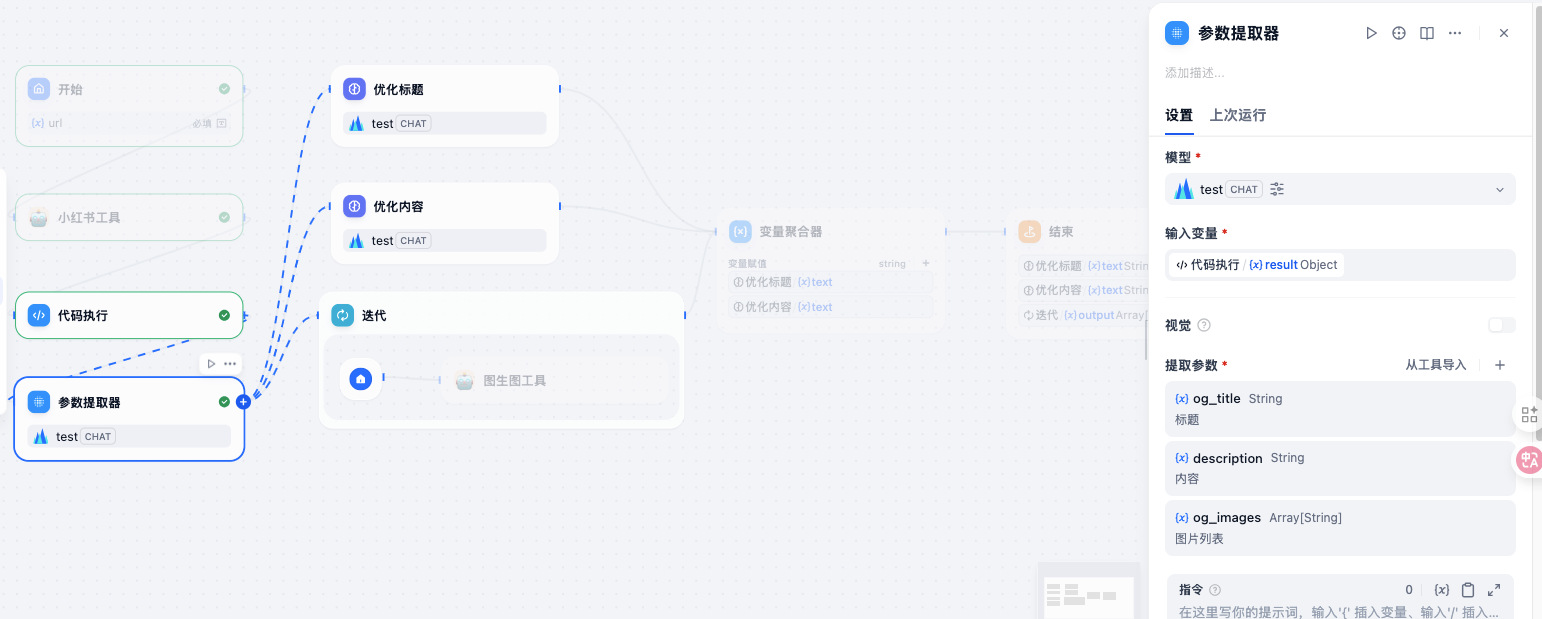
应该是对的,但是报错,报错:
8 100.00% 429 rpm_rate_limit_exceeded Rate limit reached for RPM
说我调用的太频繁了。。。明天再试试
14. 一键获取热榜文章及内容
这节课需要几个新东西:
抓取热门文章列表,可以试试这个
抓取到文章列表后,循环遍历url,获取到url的内容,推荐使用:jina.ai/
其他倒没啥了
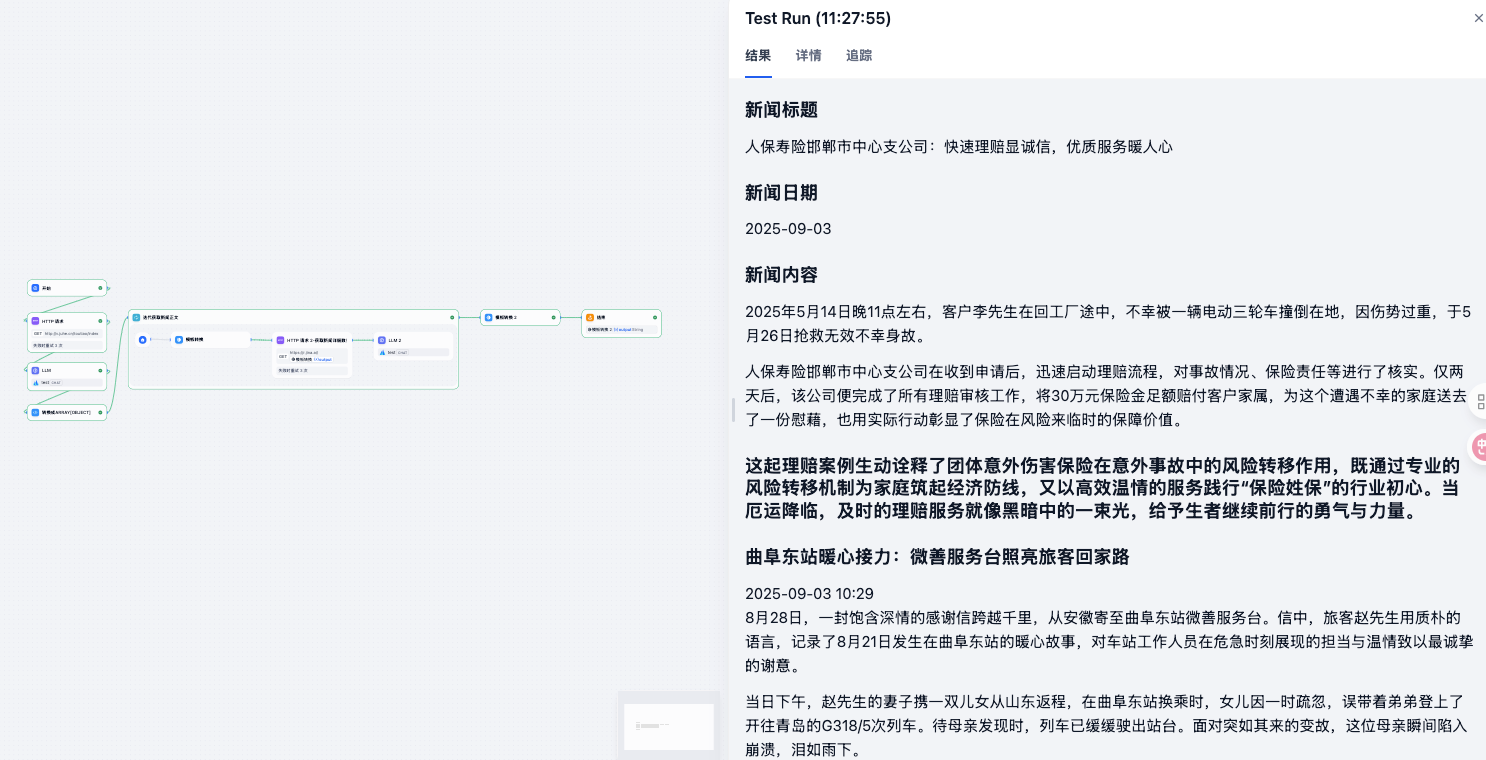
15. 简历优化
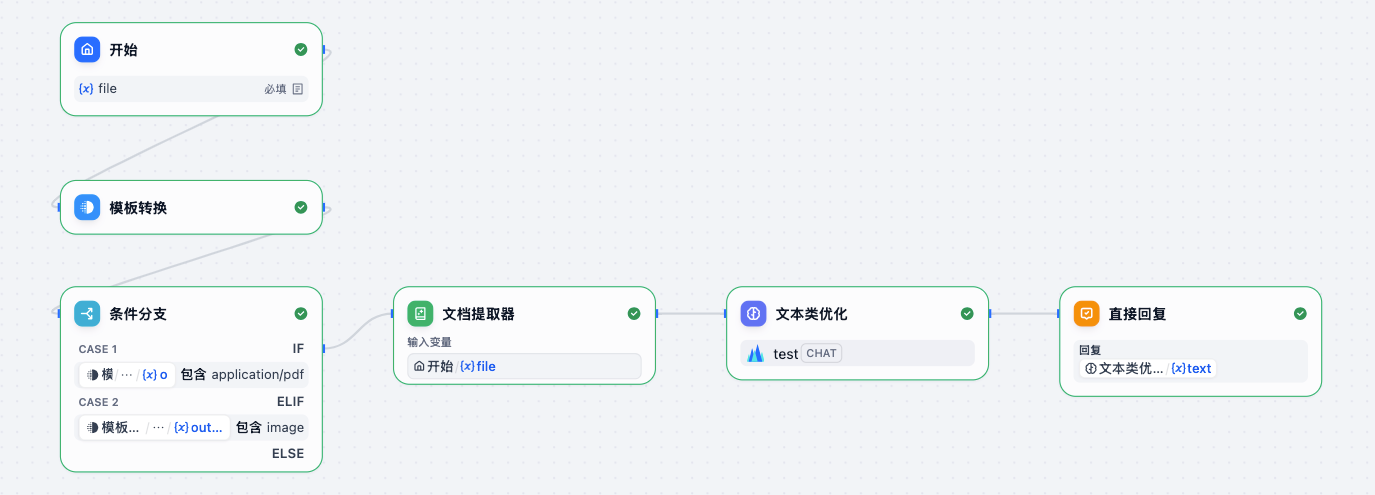
18. 文字转语音
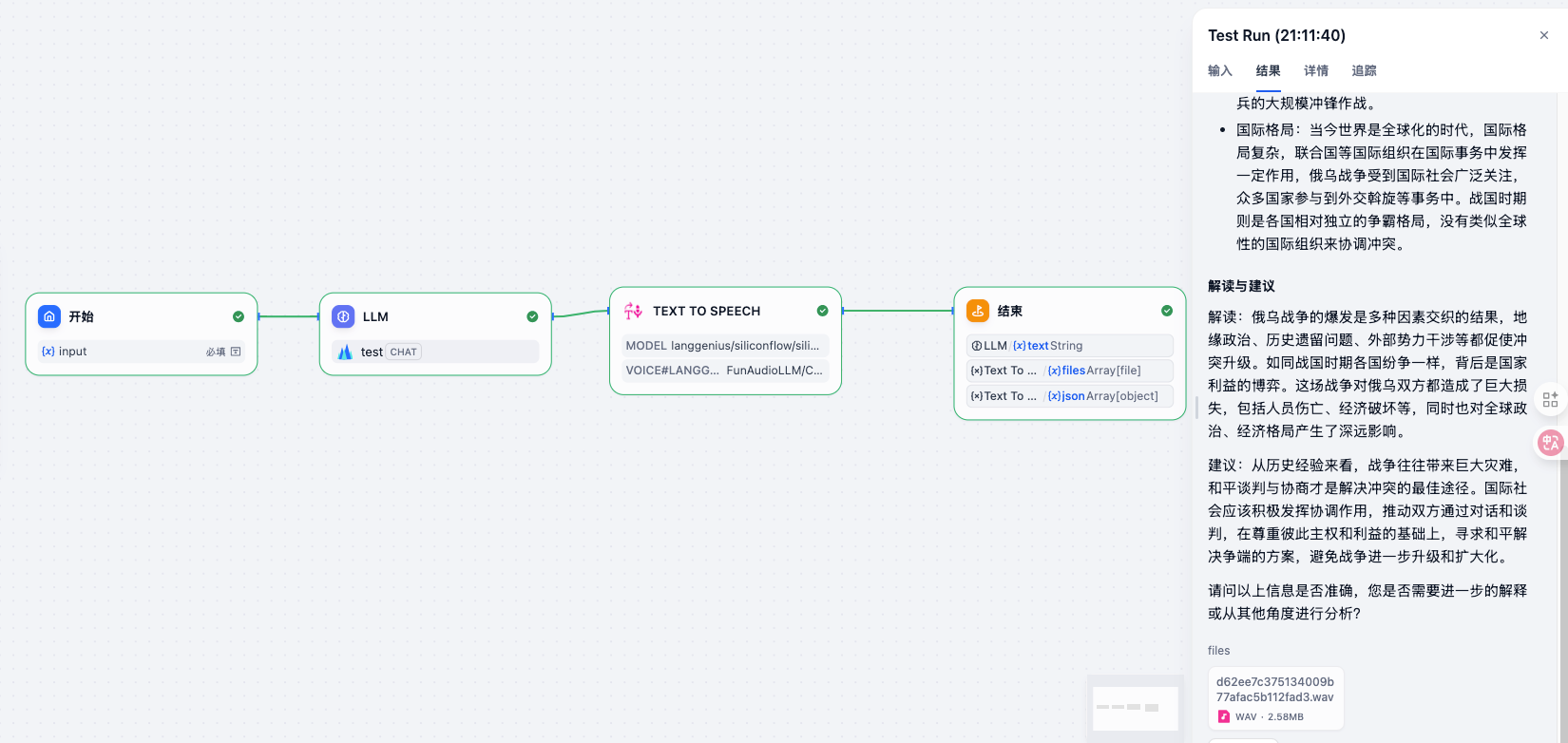
当然,也可以获取到video,然后转成文字,再修改后转成video,相当于copy音频

可以在设置这里,设置默认选中的模型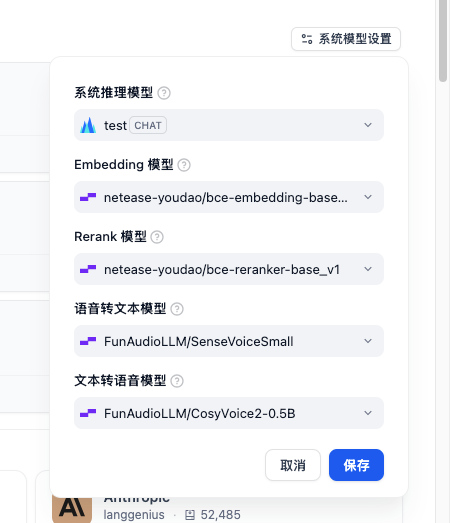
21. Echarts
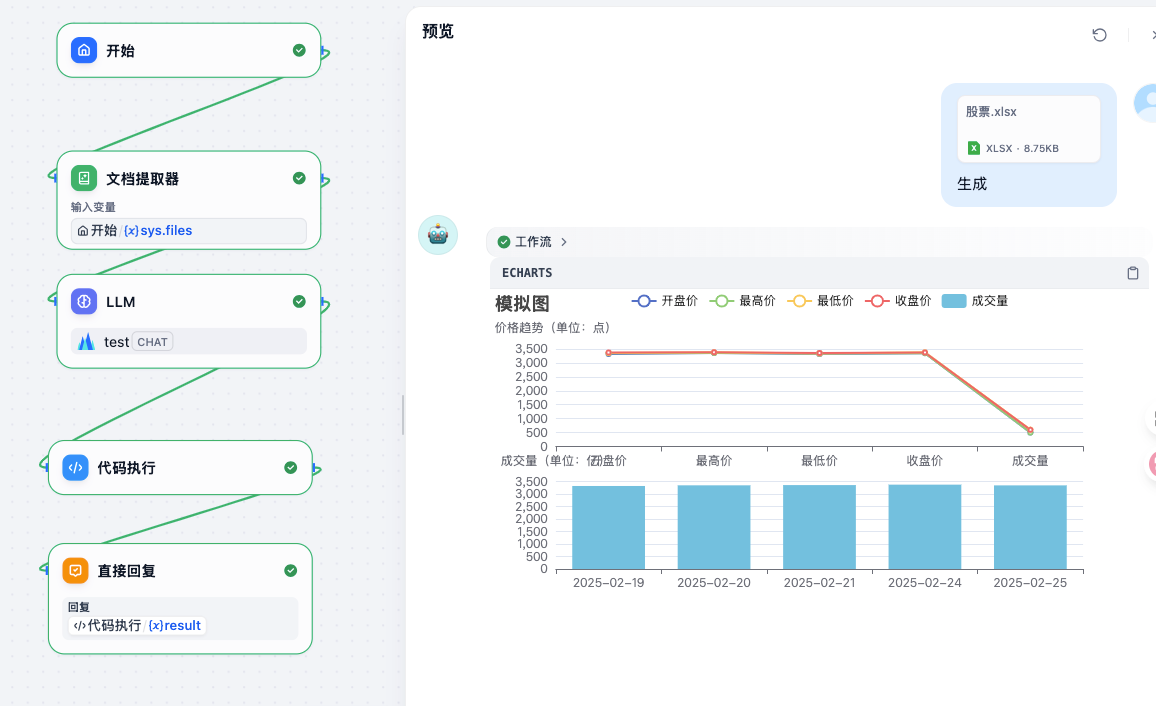
老师那个代码有问题,已经修改过了:
import json
import os
import re
def main(json_str: str) -> dict:
try:
# 预处理:清理非 JSON 部分
json_match = re.search(r'\{.*\}', json_str, re.DOTALL)
if not json_match:
return {"result": "Error: Invalid JSON format"}
# 提取合法的 JSON 部分
cleaned_json_str = json_match.group(0)
# 解析JSON数据
data = json.loads(cleaned_json_str)
filename = data.get("filename", "stock_chart.html")
stock_data = data.get("上证指数日线行情", [])
# 准备数据格式
dates = [item['date'].split(' ')[0] for item in stock_data] # 提取日期部分(去掉时间)
open_prices = [item['open'] for item in stock_data]
close_prices = [item['close'] for item in stock_data]
low_prices = [item['low'] for item in stock_data]
high_prices = [item['high'] for item in stock_data]
volumes = [item['volume'] / 1e8 for item in stock_data] # 转换为亿单位
# 构建ECharts配置
echarts_config = {
"title": {
"text": "模拟图"
},
"legend": {
"data": ["开盘价", "最高价", "最低价", "收盘价", "成交量"]
},
"tooltip": {},
"dataset": {
"source": [
["日期", "开盘价", "最高价", "最低价", "收盘价", "成交量"],
*[[dates[i], open_prices[i], high_prices[i], low_prices[i], close_prices[i], volumes[i]]
for i in range(len(dates))]
]
},
"xAxis": [
{"type": "category", "gridIndex": 0},
{"type": "category", "gridIndex": 1}
],
"yAxis": [
{
"gridIndex": 0,
"name": "价格趋势(单位:点)"
},
{
"gridIndex": 1,
"name": "成交量(单位:亿)"
}
],
"grid": [
{"bottom": "55%"},
{"top": "55%"}
],
"series": [
# 第一个网格中的折线图系列
{"type": "line", "seriesLayoutBy": "row", "name": "开盘价"},
{"type": "line", "seriesLayoutBy": "row", "name": "最高价"},
{"type": "line", "seriesLayoutBy": "row", "name": "最低价"},
{"type": "line", "seriesLayoutBy": "row", "name": "收盘价"},
# 第二个网格中的柱状图系列
{"type": "bar", "xAxisIndex": 1, "yAxisIndex": 1, "name": "成交量"}
]
}
# 生成输出文件
# output = "echarts\n" + json.dumps(echarts_config, indent=2, ensure_ascii=False) + "\n"
output = f'```echarts\n{json.dumps(echarts_config, indent=2, ensure_ascii=False)}\n```'
# 返回结果
return {
"result": output
}
except Exception as e:
return {
"result": f"Error: {str(e)}"
}

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 5
5 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)