面向RAG与LLM的分块策略权威指南:从基础原理到高级实践
LangGraph为构建复杂的、具有Agent能力的LLM应用提供了强大的框架。通过其图结构、状态管理、工具集成和灵活的执行流程,开发者可以摆脱传统线性链的限制,构建出能够自主思考、决策和行动的智能Agent。从简单的研究Agent到高级的自适应RAG系统,LangGraph都展现了其卓越的适应性和扩展性。随着AI技术的不断发展,Agent将成为未来LLM应用的核心。掌握LangGraph,意味着
在现代人工智能系统架构中,当大型语言模型(LLMs)和向量数据库吸引着大部分目光时,一个更为基础的处理过程正在幕后默默工作——它最终决定了系统输出的质量、可靠性和相关性。这个过程就是分块(Chunking):在信息到达模型之前对其进行策略性分割的关键步骤。作为RAG(检索增强生成)系统的"隐藏架构",分块技术的优劣直接影响着LLM的理解、推理和回答能力,堪称AI应用的"智能基石"。
分块的核心价值与三元挑战
分块的本质是将大型文档分解为更小、更易管理的"块",再将其嵌入向量数据库。这就像给模型提供易于消化的故事片段,而非一次性灌输完整手稿。这些块经过嵌入、存储后,可基于语义相关性进行检索。优质的分块能让AI响应更精准,而拙劣的分块则会导致幻觉、片面回答或无关结果。
分块过程面临着三个相互竞争的核心目标,构成了独特的"三元挑战":
- 块大小:较大的块提供更丰富的上下文,但难以精确检索;较小的块更适合查询,但可能缺乏完整性
- 上下文丰富度:每个块需要包含足够的周边信息,使LLM能够清晰推理
- 检索精度:块必须在语义上紧凑,以确保向量搜索时的正确匹配
这种"精度-丰富度-大小"的三角平衡,使分块既是科学也是艺术。从自然语言处理的发展历程看,分块技术已从 rigid 的固定长度分割,发展到递归分块器,再到如今模仿人类认知策略的语义和智能体感知方法。
基础分块策略:从简单到智能的演进
固定大小分块:入门级解决方案
固定大小分块如同工具箱中的锤子,不考虑文本内容或结构,仅基于字符或token计数定期分割文档。例如将文档按每500个token或1000个字符进行等长划分,具有一致性、可预测性和高速处理的优点。
但其简单性也是最大缺点:由于不关注句子或段落边界,常导致思想被截断、语法破碎和尴尬的块过渡,增加检索器和LLM的处理难度。关键参数包括:
- chunk_size:每个块的最大字符或token数,用于平衡上下文与精度
- chunk_overlap:设置块之间的重叠部分(通常为块大小的10-20%),如滑动窗口般平滑过渡并防止重要思想被分割
使用LangChain的CharacterTextSplitter实现固定大小分块:
from langchain.text_splitter import CharacterTextSplitter
text_splitter = CharacterTextSplitter(
separator=" ",
chunk_size=200,
chunk_overlap=20
)
chunks = text_splitter.split_text(sample_text)递归字符分割:更智能的基线方法
递归字符分割超越了机械分割,尝试在最有意义的边界处拆分文档——先按段落,再按句子,然后按单词,最后才是任意字符断点。这种策略基于分隔符的层次结构,例如LangChain的RecursiveCharacterTextSplitter常用的分隔符列表为["\n\n", "\n", " ", ""],处理流程如下:
- 首先尝试使用列表中的第一个分隔符(双换行符\n\n,通常对应段落分隔)分割整个文档
- 检查生成的块是否仍大于指定的chunk_size
- 对超大块,递归使用下一个分隔符(单换行符\n)继续分割
- 沿分隔符层次结构持续处理,直到所有块小于chunk_size或分隔符用尽
递归分块确保首先尊重段落边界,然后是行分隔等,生成语义更清晰、LLM更易理解的块:
from langchain.text_splitter import RecursiveCharacterTextSplitter
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=150,
separators=["\n\n", "\n", " ", ""]
)
chunks = text_splitter.create_documents([sample_text])内容感知分块:利用文档固有结构
当文档已具有清晰结构(如Markdown标题、HTML标签或代码块)时,内容感知分块直接利用这些结构标记进行分割。这种策略特别适用于:
- Markdown文档:使用LangChain的MarkdownHeaderTextSplitter按#、##、###等标题级别分块,保留文件的逻辑层次
- HTML/XML内容:以<div>、<section>等标签作为分割点
- 源代码:尊重函数或类边界,确保每个块在语法上有效且有意义
以Markdown分块为例:
from langchain.text_splitter import MarkdownHeaderTextSplitter
headers = [("#", "Header 1"), ("##", "Header 2"), ("###", "Header 3")]
markdown_splitter = MarkdownHeaderTextSplitter(headers_to_split_notallow=headers)
chunks = markdown_splitter.split_text(md_content)每个块不仅保留章节内容,还携带元数据(如{'Header 1': 'Introduction'}),便于检索时的过滤或重排序。
策略选择指南:
- 高度结构化数据(Markdown/HTML)→ 内容感知分块
- 干净的散文(博客/文章)→ 递归分割
- 杂乱的非结构化文本(原始日志/粘贴内容)→ 固定大小分块
语义连贯的高级分块策略
语义分块:基于意义而非标点的分组
传统分块方法不关注内容含义,而语义分块通过分析连续句子的相似度来识别主题变化点。其核心流程为:
- 句子分割:将文档拆分为句子
- 嵌入生成:使用文本嵌入模型(如text-embedding-3-small或SentenceTransformers)将每个句子转换为向量
- 相似度评分:计算每对相邻句子向量的余弦相似度
- 断点检测:当相似度低于定义阈值(如所有降幅的第5百分位)时引入分割
这种方法能检测真实的主题转换点,生成语义内聚的块,显著提升复杂查询的检索相关性。但需注意其计算成本较高,且需要对阈值、缓冲区大小和嵌入模型进行调优。
LangChain的SemanticChunker实现:
from langchain_experimental.text_splitter import SemanticChunker
from langchain.embeddings import OpenAIEmbeddings
text_splitter = SemanticChunker(
OpenAIEmbeddings(),
breakpoint_threshold_type="percentile"
)
docs = text_splitter.create_documents([sample_text])层次与关系分块:"从小到大"的范式
RAG系统中存在一个根本矛盾:小块检索更精准,但大块生成效果更佳。层次分块通过LangChain的ParentDocumentRetriever解决这一问题,创建文档的多级表示:
- 子块:针对检索优化的小而精的块,存入向量存储
- 父块:针对生成优化的大上下文块,存入单独的文档存储
检索时先对小子块进行相似度搜索,再获取包含这些子块的父文档,实现"精确检索+广泛生成"的平衡:
from langchain.retrievers import ParentDocumentRetriever
child_splitter = RecursiveCharacterTextSplitter(chunk_size=400)
parent_splitter = RecursiveCharacterTextSplitter(chunk_size=2000)
vectorstore = Chroma(embedding_functinotallow=OpenAIEmbeddings())
store = InMemoryStore()
retriever = ParentDocumentRetriever(
vectorstore=vectorstore,
docstore=store,
child_splitter=child_splitter,
parent_splitter=parent_splitter,
)
retriever.add_documents(docs)层次分块超越了线性分块,构建了文档内部的结构关系(段落属于章节,章节属于文档),为更高级的知识图谱(如GraphRAG)奠定基础。
分块策略的评估艺术
四步评估框架
由于没有放之四海而皆准的分块策略,科学评估至关重要:
- 创建黄金数据集:基于文档构建或生成具有代表性的问答对,可由领域专家手动制作或使用LLM合成
- 隔离变量:仅改变分块策略,保持嵌入模型、检索器设置、生成LLM等其他因素不变
- 运行基准测试:在黄金数据集上运行不同分块策略的RAG管道,记录检索上下文和生成答案
- 测量与比较:使用RAGAS等框架评分,获取具体指标
关键评估指标
检索质量
- 上下文精度:检索到的块中真正相关的比例
- 上下文召回:可用相关块中被找到的比例
生成质量
- 忠实度:答案是否基于检索上下文,而非LLM虚构
- 回答相关性:答案是否真正有用且切题
使用RAGAS进行评估的示例:
from ragas import evaluate
from ragas.metrics import context_precision, context_recall, faithfulness, answer_relevancy
results_data = {
'question': [...],
'answer': [...],
'contexts': [[...], ...],
'ground_truth': [...]
}
dataset = Dataset.from_dict(results_data)
result = evaluate(
dataset=dataset,
metrics=[context_precision, context_recall, faithfulness, answer_relevancy],
)精度-召回-忠实度的权衡
选择大块(如2048 tokens)可能提高召回率(捕获所有相关信息),但会引入大量无关内容,导致LLM产生幻觉或离题回答(忠实度降低)。理想的分块应实现平衡的上下文:足够丰富以覆盖需求,同时足够专注以保持模型的准确性。
分块作为智能的隐藏架构
从固定大小分块的简单性,到语义分块的细微差别,再到层次结构的系统性,分块技术塑造了知识呈现给模型的方式。选择的策略将决定系统是精确检索还是泛泛而谈,是生成有根有据的见解还是自信的幻觉。
在构建RAG系统时,分块不应被视为低级预处理步骤,而应作为智能架构的核心。通过理解数据特性、任务需求和评估反馈,精心设计的分块策略能为LLM提供优质的"思考材料",释放AI系统的真正潜力。随着技术发展,分块将与知识图谱、动态检索策略进一步融合,推动AI从信息处理向真正的认知智能演进。
在LangGraph中,通过条件边和ToolNode来实现这种基于工具的决策流程。Agent首先通过LLM判断是否需要工具调用,如果需要,则进入ToolNode执行相应的工具,然后将工具的输出返回给Agent进行下一步处理。
自适应RAG(Adaptive RAG)
自适应RAG是RAG策略的进一步演进,它能够根据查询的复杂性和上下文动态调整检索和生成策略。这意味着Agent不再是简单地执行RAG,而是能够智能地判断:
- 是否需要检索:对于简单问题,直接由LLM回答,无需检索。
- 检索的复杂性:对于复杂问题,可能需要多跳检索或网络搜索。
- 多阶段质量保证:在检索和生成过程中进行多重评估,例如文档相关性评估、幻觉检测和答案质量评估,以确保最终回答的准确性。
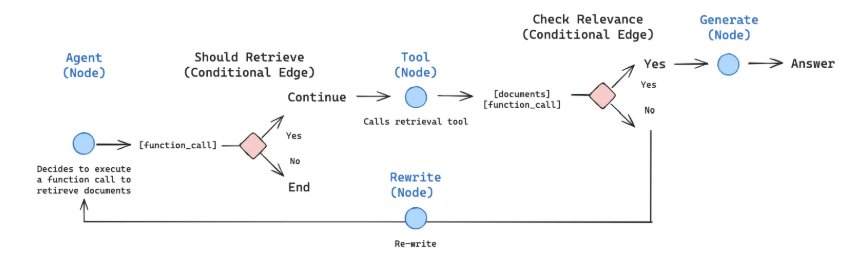
构建自适应RAG系统通常涉及以下关键组件:
- 查询路由与分类器:一个训练有素的分类器,用于分析传入查询的复杂性,并决定最佳的知识获取策略(例如,基于索引的检索、网络搜索或无需检索)。
- 动态知识获取策略:根据分类器的判断,系统智能地在不同信息源之间进行路由,例如本地向量数据库或实时网络搜索。
- 多阶段质量保证:在整个流程中嵌入多个评估点,确保检索到的文档相关、生成的答案准确且没有幻觉。
LangGraph的图结构非常适合实现自适应RAG。通过定义不同的节点(如查询分类器、本地检索器、网络搜索器、答案生成器、评估器)和条件边,构建一个高度灵活和智能的工作流,使其能够根据查询的特性动态地调整其行为,从而在各种场景下提供最优的RAG体验。
结语
LangGraph为构建复杂的、具有Agent能力的LLM应用提供了强大的框架。通过其图结构、状态管理、工具集成和灵活的执行流程,开发者可以摆脱传统线性链的限制,构建出能够自主思考、决策和行动的智能Agent。从简单的研究Agent到高级的自适应RAG系统,LangGraph都展现了其卓越的适应性和扩展性。
随着AI技术的不断发展,Agent将成为未来LLM应用的核心。掌握LangGraph,意味着拥有构建下一代智能应用的关键能力,让我们在实践中探索LangGraph的更多可能性,共同推动AI技术的发展。
-
学习资源推荐
如果你想更深入地学习大模型,以下是一些非常有价值的学习资源,这些资源将帮助你从不同角度学习大模型,提升你的实践能力。
一、全套AGI大模型学习路线
AI大模型时代的学习之旅:从基础到前沿,掌握人工智能的核心技能!

因篇幅有限,仅展示部分资料,需要点击文章最下方名片即可前往获取
二、640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示

因篇幅有限,仅展示部分资料,需要点击文章最下方名片即可前往获取
三、AI大模型经典PDF籍
随着人工智能技术的飞速发展,AI大模型已经成为了当今科技领域的一大热点。这些大型预训练模型,如GPT-3、BERT、XLNet等,以其强大的语言理解和生成能力,正在改变我们对人工智能的认识。 那以下这些PDF籍就是非常不错的学习资源。
因篇幅有限,仅展示部分资料,需要点击文章最下方名片即可前往获取
四、AI大模型商业化落地方案

因篇幅有限,仅展示部分资料,需要点击文章最下方名片即可前往获取
作为普通人,入局大模型时代需要持续学习和实践,不断提高自己的技能和认知水平,同时也需要有责任感和伦理意识,为人工智能的健康发展贡献力量。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 15
15 0
0- 0



 已为社区贡献94条内容
已为社区贡献94条内容

所有评论(0)