老码农和你一起学AI系列:机器学习实战- SVM 与核方法
本文介绍了支持向量机(SVM)的基本原理及其应用。SVM通过最大化间隔来寻找最优分类超平面,具有优秀的泛化能力。文章详细讲解了硬间隔SVM、Hinge Loss优化方法,以及Scikit-learn中SVC类的核心参数设置。通过月亮数据集的分类实验,对比了不同核函数(线性核、多项式核和RBF核)的效果,展示了SVM处理非线性问题的能力。最后指出,在实际应用中需要根据数据特点选择合适的核函数,并利用
在人工智能的算法宝库中,支持向量机(SVM)以其优雅的数学原理和强大的分类能力占据着重要地位。无论是处理简单的线性可分问题,还是应对复杂的非线性场景,SVM 都能凭借 “边界” 的艺术找到最优解。本文将从基础原理出发,逐步揭开 SVM 与核方法的神秘面纱,让专业与非专业人士都能领略其 “魔法” 所在。
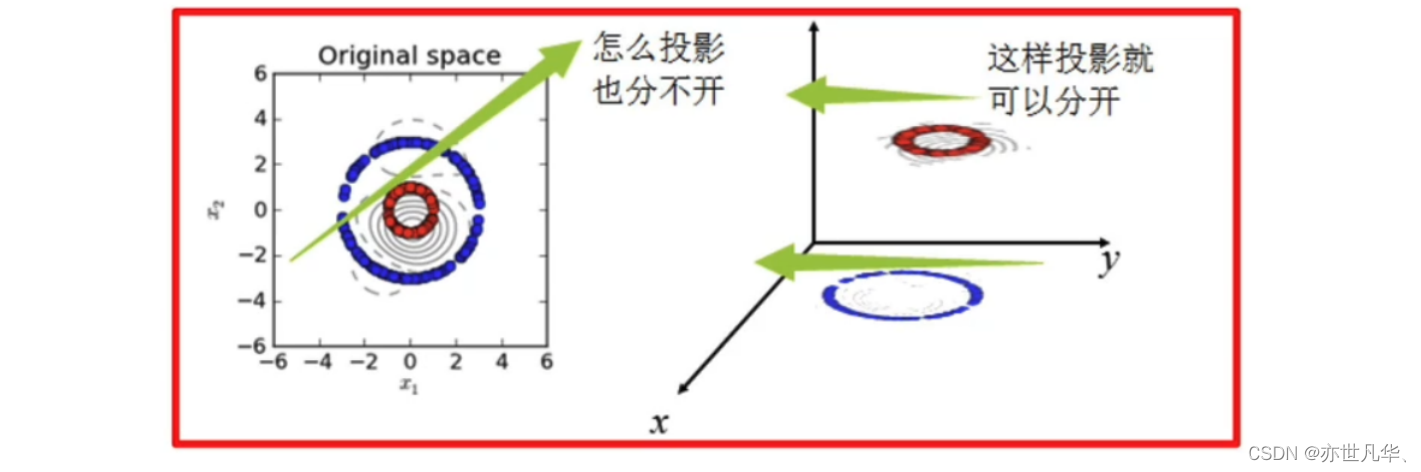
一、寻找最优边界
1、感知机的局限与 SVM 的诞生
在机器学习的入门阶段,感知机是我们接触到的第一个线性分类模型。它通过寻找一个超平面将不同类别的数据分隔开,其数学表达为:
其中,w 是权重向量,b 是偏置项,sign是符号函数。当样本点被正确分类时,;反之则为错误分类。感知机的目标是最小化误分类点的数量,通过梯度下降不断调整 \(w\) 和 \(b\) 来优化模型。
然而,感知机存在一个明显的缺陷:它找到的分隔超平面往往不是唯一的,而且对噪声敏感。在实际应用中,我们需要的是一个鲁棒性更强、泛化能力更好的超平面。这就是支持向量机(SVM)诞生的背景。
2、硬间隔 SVM
SVM 的核心思想是 “最大化间隔”。所谓间隔,是指分隔超平面到最近的样本点(即支持向量)的距离。硬间隔 SVM 假设数据是线性可分的,它的目标是找到一个能将两类数据完美分开,且间隔最大的超平面。
从数学角度看,间隔的计算公式为:
其中,\(\|w\|\) 是权重向量 \(w\) 的 L2 范数。要最大化间隔,就需要最小化 \(\|w\|\)。同时,为了保证所有样本都被正确分类,需要满足约束条件:
因此,硬间隔 SVM 的优化问题可以表示为:
这是一个带约束的凸优化问题,可以通过拉格朗日乘子法求解。求解后得到的超平面只由少数几个支持向量决定,这也是 SVM 具有良好泛化能力的原因之一。
3、用梯度下降优化 Hinge Loss
在实际应用中,我们更多地使用损失函数来描述优化目标。对于 SVM,常用的损失函数是 Hinge Loss( hinge 损失),其表达式为:
Hinge Loss 的特点是:当样本被正确分类且间隔大于 1 时,损失为 0;当样本被错误分类或间隔小于 1 时,损失随间隔的减小而增大。
我们可以使用梯度下降法来最小化 Hinge Loss。为了防止过拟合,通常会在损失函数中加入正则化项,得到:
其中,\(C\) 是惩罚系数,用于平衡间隔大小和分类错误。\(C\) 越大,对错误分类的惩罚越重,模型可能会过拟合;\(C\) 越小,模型更注重间隔最大化,可能会欠拟合。
梯度下降的更新公式为:
其中,是学习率。通过不断迭代更新 w 和 b,我们可以得到最优的模型参数。
二、Scikit-learn 中的 SVM
1、SVC 的核心参数
Scikit-learn 是 Python 中常用的机器学习库,其中的SVC类实现了支持向量分类器。要熟练使用SVC,需要掌握以下核心参数:
C(惩罚系数):如前所述,C 用于平衡间隔大小和分类错误。在实际应用中,我们可以通过交叉验证来选择合适的C值。
kernel(核函数):核函数是 SVM 处理非线性问题的关键。SVC提供了多种核函数选择:
- linear(线性核):适用于线性可分的数据,计算速度快。
- poly(多项式核):通过多项式变换将数据映射到高维空间,适用于中等复杂度的非线性问题。
- rbf(径向基函数核):也称为高斯核,是最常用的核函数之一,适用于各种复杂的非线性问题。
- degree:当kernel='poly'时,degree表示多项式的阶数。阶数越高,模型越复杂,可能会过拟合。
- gamma:当kernel='rbf'或kernel='poly'时,gamma是核函数的参数。gamma越大,核函数的影响范围越小,模型可能会过拟合;gamma越小,核函数的影响范围越大,模型可能会欠拟合。
2、超参数自动优化
为了找到最优的超参数组合,我们可以使用 Scikit-learn 中的GridSearchCV或RandomizedSearchCV。GridSearchCV通过穷举所有可能的超参数组合来寻找最优解,其优点是结果可靠,缺点是计算量较大。例如,我们可以为C和gamma设置一系列候选值,然后通过GridSearchCV来找到最优组合:
from sklearn.model_selection import GridSearchCV
from sklearn.svm import SVC
param_grid = {'C': [0.1, 1, 10, 100], 'gamma': [0.001, 0.01, 0.1, 1]}
grid_search = GridSearchCV(SVC(kernel='rbf'), param_grid, cv=5)
grid_search.fit(X_train, y_train)
print("最优参数:", grid_search.best_params_)
print("最优得分:", grid_search.best_score_)RandomizedSearchCV则是通过随机采样的方式选择超参数组合,其优点是计算量小,适用于超参数较多的情况。
三、月亮数据集分类
为了直观地感受不同核函数的效果,我们使用 Scikit-learn 中的月亮数据集进行分类实验。月亮数据集是一个常用的非线性数据集,由两个半月形的样本组成。
数据准备
首先,我们生成月亮数据集并进行可视化:
import numpy as np
import matplotlib.pyplot as plt
from sklearn.datasets import make_moons
from sklearn.model_selection import train_test_split
# 生成月亮数据集
X, y = make_moons(n_samples=100, noise=0.1, random_state=42)
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
# 可视化数据集
plt.scatter(X[y==0, 0], X[y==0, 1], c='red', marker='o', label='类别0')
plt.scatter(X[y==1, 0], X[y==1, 1], c='blue', marker='s', label='类别1')
plt.xlabel('特征1')
plt.ylabel('特征2')
plt.legend()
plt.show()模型训练与评估
接下来,我们分别使用线性核、多项式核和 RBF 核对数据进行分类,并评估模型的性能:
from sklearn.svm import SVC
from sklearn.metrics import accuracy_score
# 线性核SVM
svm_linear = SVC(kernel='linear', C=1)
svm_linear.fit(X_train, y_train)
y_pred_linear = svm_linear.predict(X_test)
accuracy_linear = accuracy_score(y_test, y_pred_linear)
print("线性核SVM的准确率:", accuracy_linear)
# 多项式核SVM
svm_poly = SVC(kernel='poly', degree=3, C=1)
svm_poly.fit(X_train, y_train)
y_pred_poly = svm_poly.predict(X_test)
accuracy_poly = accuracy_score(y_test, y_pred_poly)
print("多项式核SVM的准确率:", accuracy_poly)
# RBF核SVM
svm_rbf = SVC(kernel='rbf', gamma=1, C=1)
svm_rbf.fit(X_train, y_train)
y_pred_rbf = svm_rbf.predict(X_test)
accuracy_rbf = accuracy_score(y_test, y_pred_rbf)
print("RBF核SVM的准确率:", accuracy_rbf)结果可视化
最后,我们可视化不同核函数的分类边界:
# 绘制分类边界
def plot_decision_boundary(model, X, y):
h = 0.02
x_min, x_max = X[:, 0].min() - 0.5, X[:, 0].max() + 0.5
y_min, y_max = X[:, 1].min() - 0.5, X[:, 1].max() + 0.5
xx, yy = np.meshgrid(np.arange(x_min, x_max, h), np.arange(y_min, y_max, h))
Z = model.predict(np.c_[xx.ravel(), yy.ravel()])
Z = Z.reshape(xx.shape)
plt.contourf(xx, yy, Z, alpha=0.4)
plt.scatter(X[:, 0], X[:, 1], c=y, alpha=0.8)
plt.figure(figsize=(15, 5))
plt.subplot(131)
plot_decision_boundary(svm_linear, X, y)
plt.title('线性核SVM')
plt.subplot(132)
plot_decision_boundary(svm_poly, X, y)
plt.title('多项式核SVM')
plt.subplot(133)
plot_decision_boundary(svm_rbf, X, y)
plt.title('RBF核SVM')
plt.show()从实验结果可以看出,线性核对月亮数据集的分类效果较差,因为数据是非线性的;多项式核和 RBF 核都能较好地拟合数据,其中 RBF 核的效果通常更优。这说明核函数能够将低维空间中的非线性问题转化为高维空间中的线性问题,从而使 SVM 能够处理复杂的分类任务。
最后总结
支持向量机(SVM)是一种强大的机器学习算法,它通过最大化间隔来寻找最优的分隔超平面,具有良好的泛化能力。核方法的引入使得 SVM 能够处理非线性问题,其中 RBF 核是最常用的核函数之一。在实际应用中,我们需要根据数据的特点选择合适的核函数和超参数。Scikit-learn 中的SVC类为我们提供了便捷的实现,而GridSearchCV和RandomizedSearchCV则可以帮助我们自动优化超参数。通过本文的介绍,相信无论是 AI 专业人士还是非专业人士,都对 SVM 与核方法有了更深入的理解。在未来的学习和实践中,我们可以进一步探索 SVM 的更多特性和应用场景,充分发挥其 “边界的魔法”。未完待续.......

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 36
36 0
0- 0



 已为社区贡献42条内容
已为社区贡献42条内容

所有评论(0)