如何判定AI给出的模型是否正确?
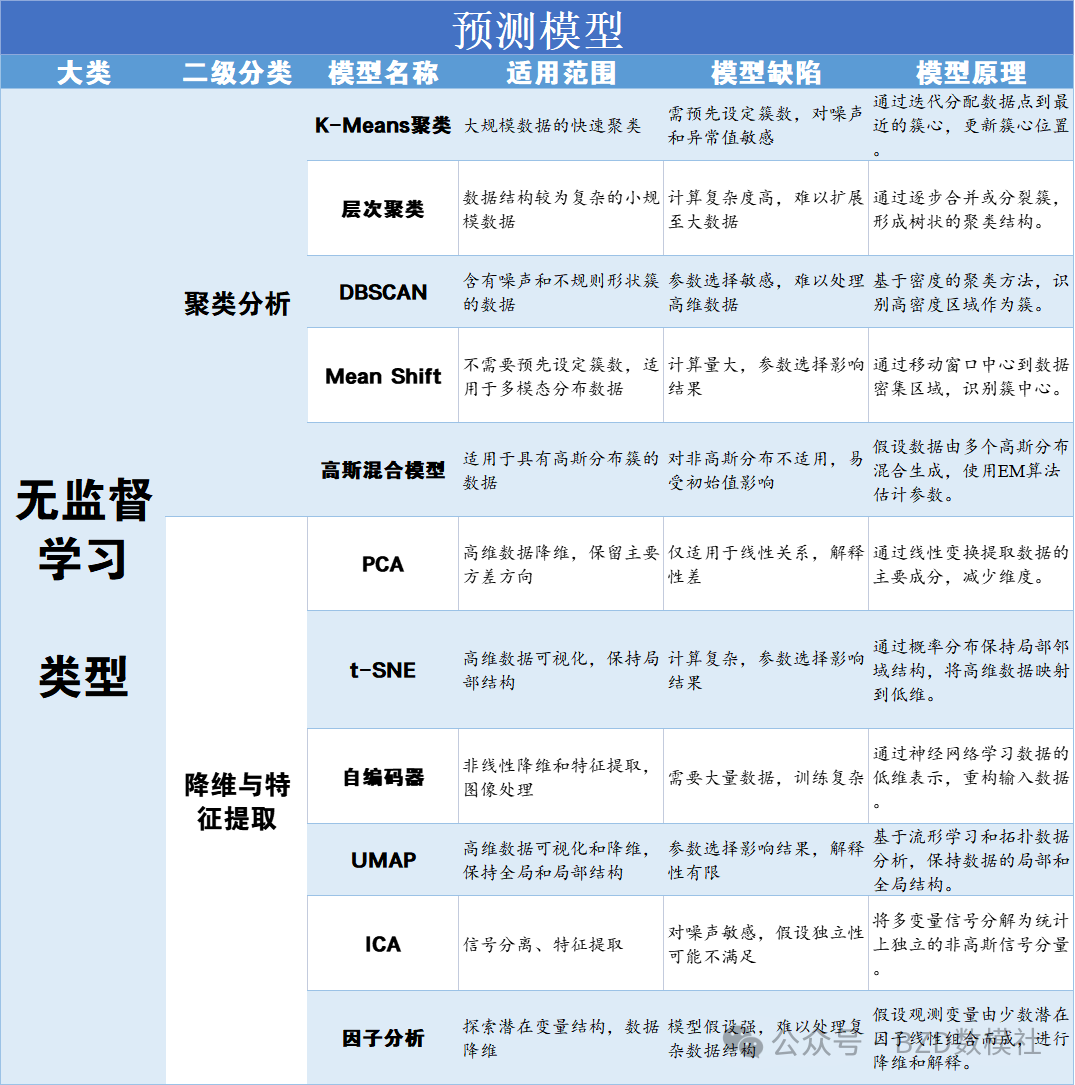
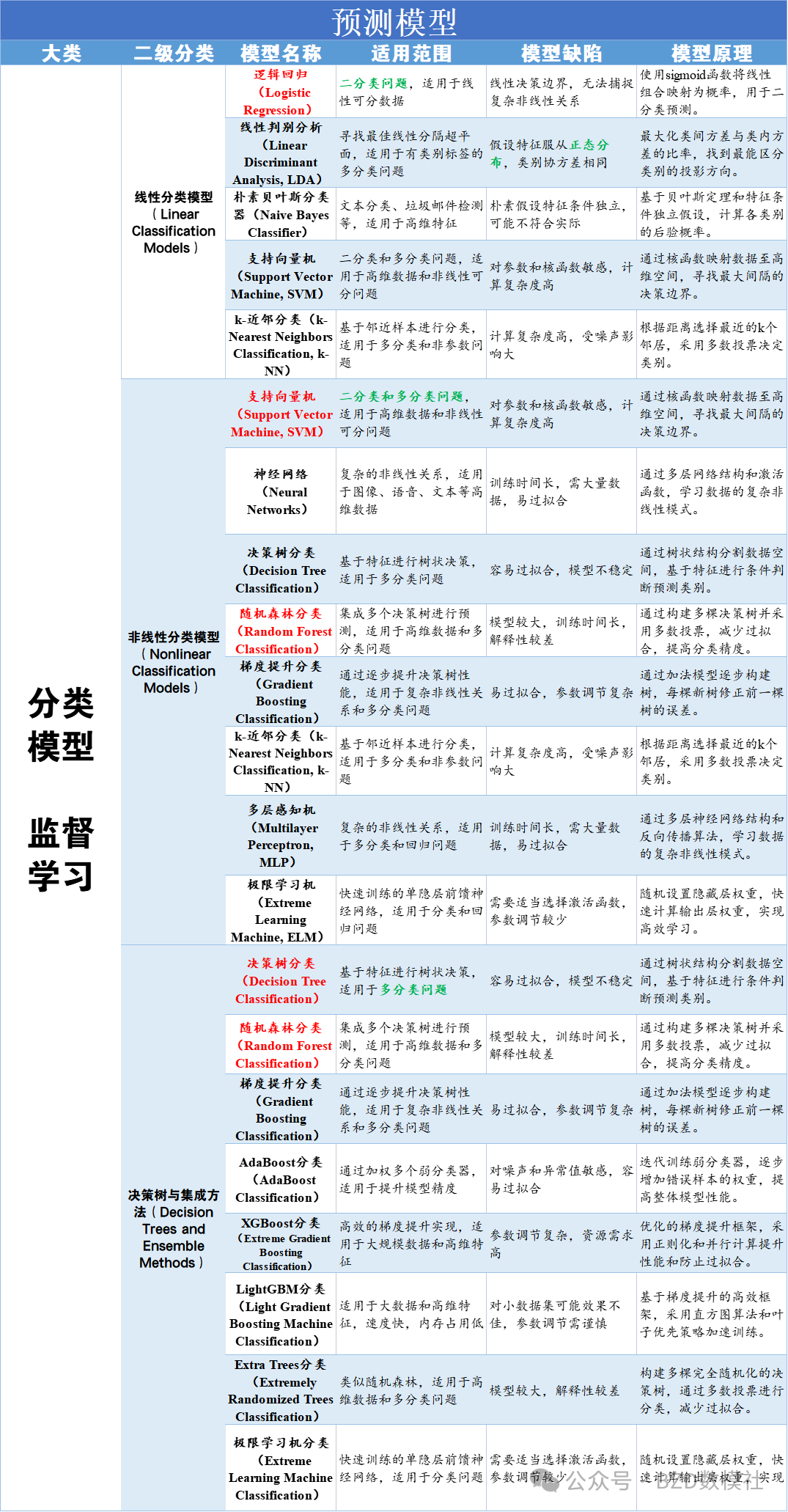
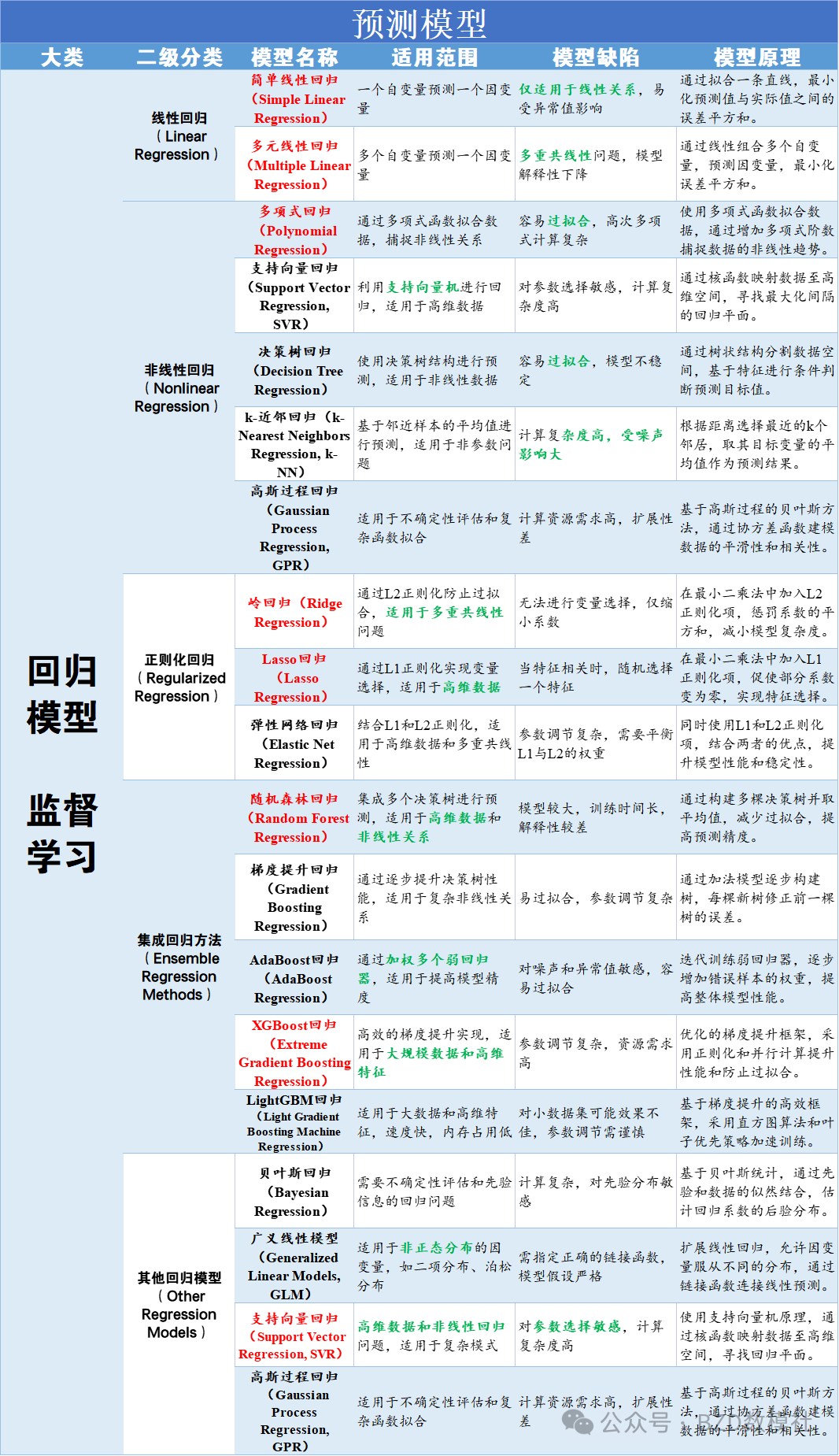
针对赛中,无指导老师、无丰富的参赛经验、无模型基础的情况,其实我们需要做的就是判定模型是否适合于该题目、使用的模型是否完备。因此,我们赛中可以通过网上资料或者AI学习设计的三四个模型的适用范围、模型缺陷、模型原理即可。尤其是对于参赛学生而言,更是无法直接判定输出模型的正确性,比较建议可以同时尝试多个AI输出模型,选择公认可以使用的模型;具体的,我将常见模型分为数据预处理、时序预测、分类、评价、优化
AI在数模竞赛中存在三大痛点:无专门的AI+数模培训课程导致零基础人群无法入门;AI生成内容同质化严重影响论文创新;AI生成内容正确性无法确保,存在模型适用性风险。本文将为大家解决如何识别AI生成内容正确性。
国赛在七八月份开了很多的研讨会,对于该问题的主要答复为建议进行多AI辅助。具体来讲,以chatGPT为例,其本身作为一个chat模型,真正用于科研输出结果的真实性我们是无法直接判断的。尤其是对于参赛学生而言,更是无法直接判定输出模型的正确性,比较建议可以同时尝试多个AI输出模型,选择公认可以使用的模型;也可以将A AI模型的输出结果交给B AI模型进行判定使用是否合适。
针对赛中,无指导老师、无丰富的参赛经验、无模型基础的情况,其实我们需要做的就是判定模型是否适合于该题目、使用的模型是否完备。对于数学建模竞赛真正解题过程,其中所涉及的模型一共只有三四个。我们只需要判定三四个模型是否适用于该题目解题即可。因此,我们需要了解这三四个模型的适用范围、模型缺陷、模型原理(稍微了解)。因此,我们赛中可以通过网上资料或者AI学习设计的三四个模型的适用范围、模型缺陷、模型原理即可。
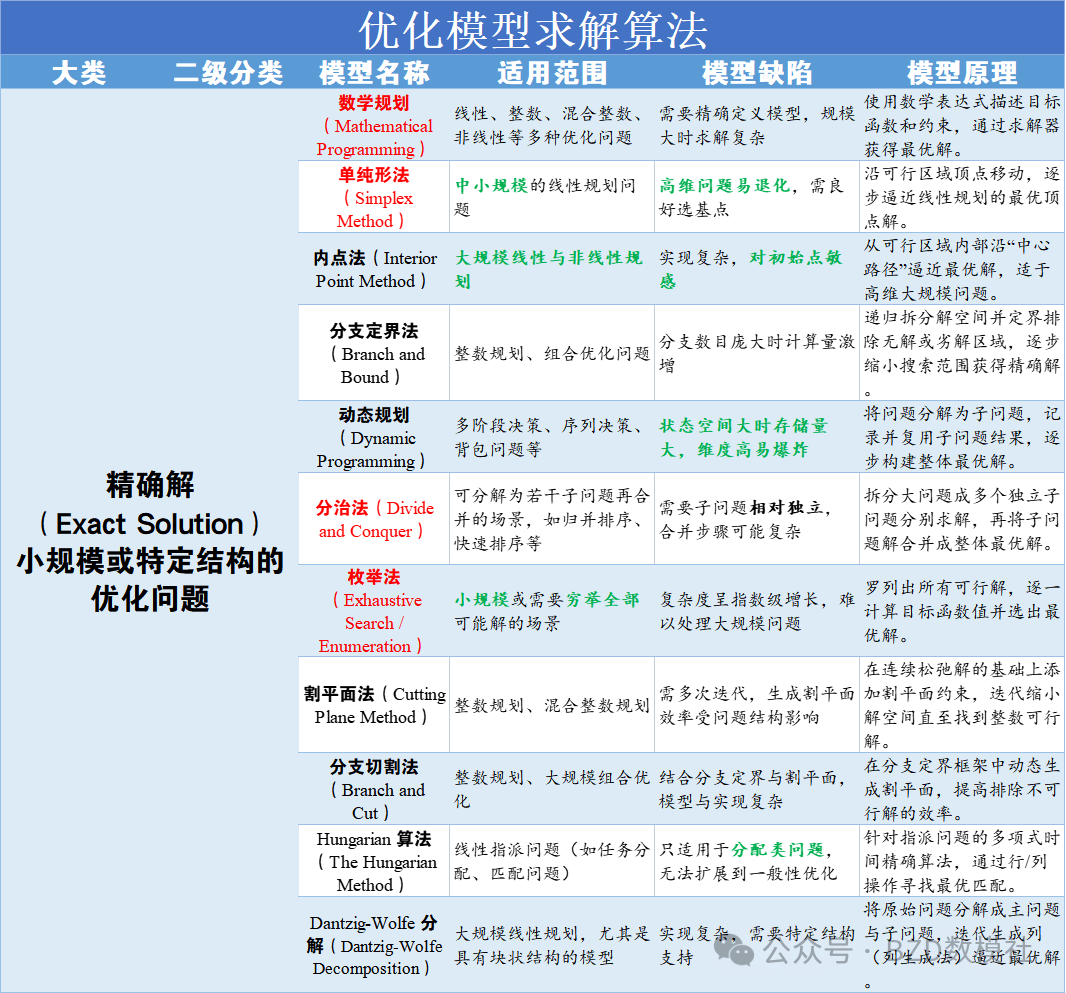
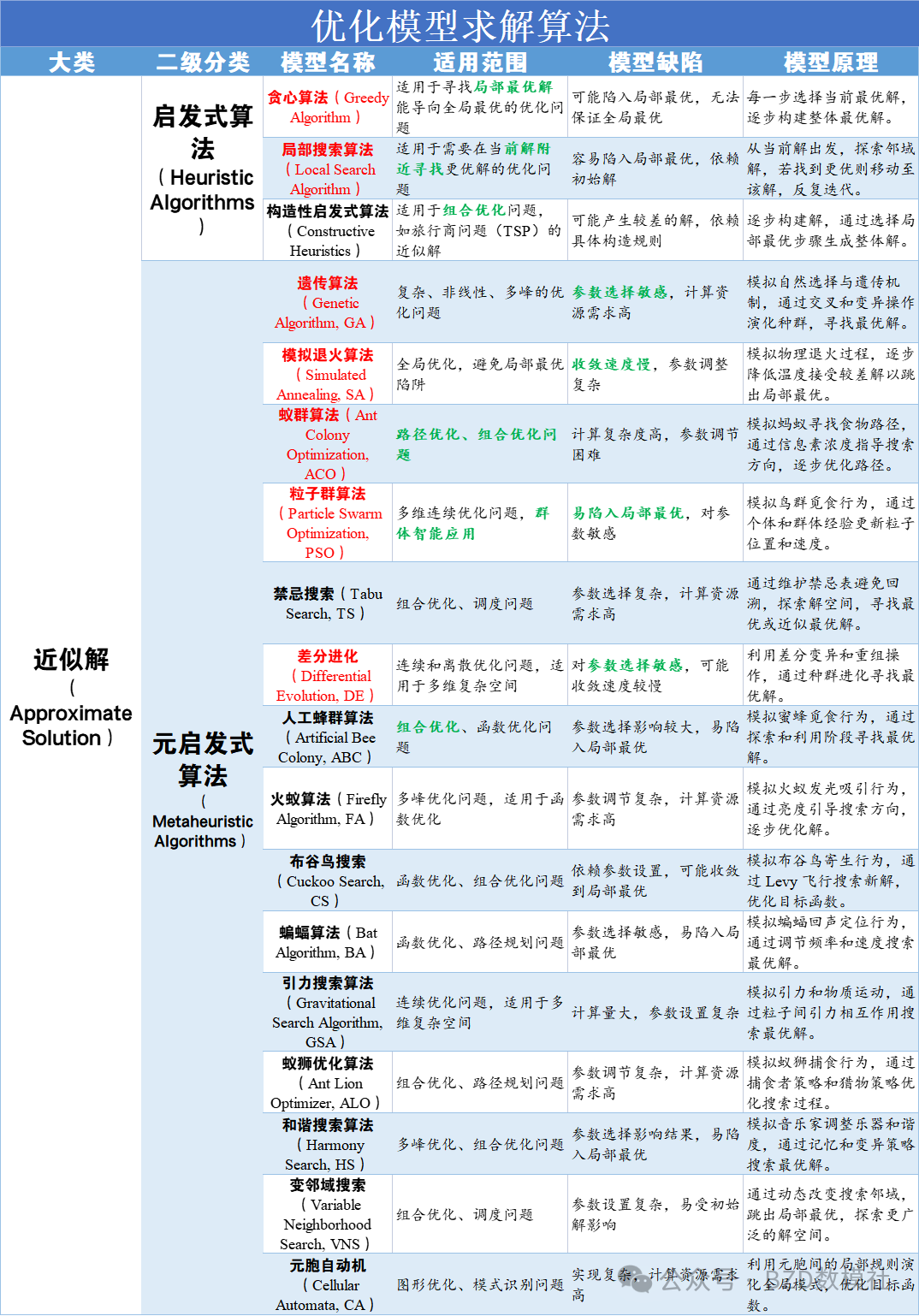
国赛中70%的题目都会涉及优化模型,而优化模型在过去几年出现求解算法乱用、智能算法、张冠李戴的问题。因此,我们必须清楚什么优化问题适用于什么求解算法.具体适用范围可以对照下图下表
|
类别 |
问题类型 |
方法 |
思路/原理简述 |
|
精确解方法 |
线性规划(LP) |
单纯形法 |
遍历可行域多面体的顶点,找到最优解 |
|
内点法 |
沿约束集内部的路径逐步逼近最优解 |
||
|
整数规划(IP) |
分支定界法 |
递归分割解空间(分支),逐步逼近最优解 |
|
|
割平面法 |
添加约束(割平面)裁剪解空间,逼近整数解 |
||
|
非线性规划(NLP) |
牛顿法 |
基于泰勒展开,利用二阶导数更新变量 |
|
|
拟牛顿法 |
近似计算Hessian 矩阵 |
||
|
序列二次规划法 |
将NLP 转化为一系列 QP,逐步逼近最优解 |
||
|
近似解方法 |
线性规划(LP) |
对偶法 |
通过求解对偶问题近似原问题 |
|
整数规划(IP) |
贪心算法 |
每步选局部最优,构建全局近似解 |
|
|
遗传算法 |
模拟选择、交叉、变异的进化过程 |
||
|
模拟退火 |
模拟退火过程,接受较差解避免局部最优 |
||
|
非线性规划(NLP) |
遗传算法 |
模拟自然进化寻找近似解 |
|
|
粒子群优化算法 |
模拟鸟群觅食,多粒子全局搜索 |
||
|
蚁群优化 |
模拟蚂蚁觅食,通过信息素传递找最优解 |
||
|
差分进化 |
全局搜索能力强,适合连续优化 |
||
|
人工鱼群算法 |
模拟鱼群集体行为,避免局部最优 |
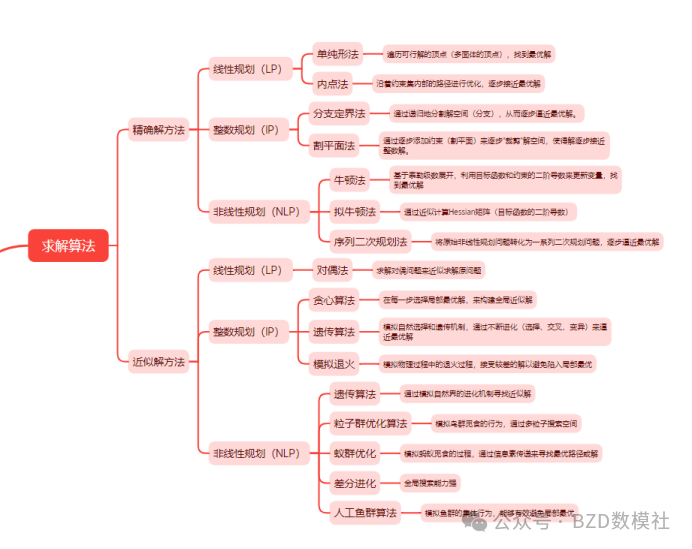
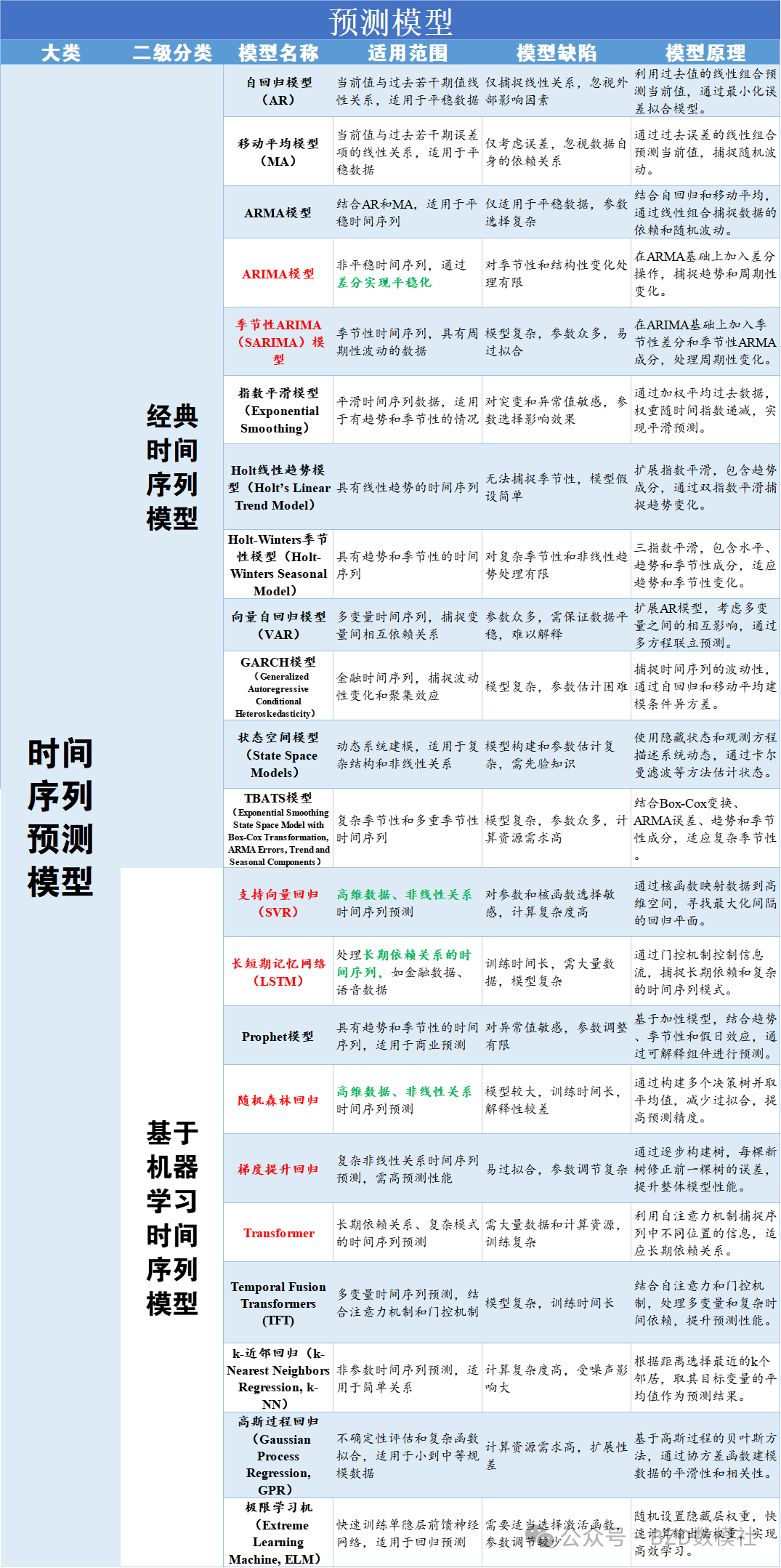
具体的,我将常见模型分为数据预处理、时序预测、分类、评价、优化模型,用表格的形式呈现出每类模型的适用范围、模型缺陷、模型原理以便大家在赛中查阅。
具体可见文末
|
数据清洗-异常值判定 |
||||
|
二级分类 |
模型名称 |
适用范围 |
模型缺陷 |
模型原理 |
|
统计方法 |
Z-Score(标准分数)法 |
适用于正态分布数据的异常值检测 |
对非正态分布敏感,易受极端值影响 |
通过计算数据点与均值的标准差,判断是否偏离正常范围。 |
|
IQR(四分位距)法 |
适用于各种分布的数据,尤其是非正态分布 |
对数据分布形状有一定要求,可能误判边界数据 |
利用数据的上下四分位数范围,识别超出范围的异常值。 |
|
|
Grubbs' 检验 |
适用于检测单个或少数异常值的正态分布数据 |
只能检测单个异常值,假设数据为正态分布 |
基于极端值与整体数据的统计差异,进行异常值的假设检验。 |
|
|
主成分分析(PCA) |
降维和异常检测,适用于多维数据 |
对线性关系敏感,难以捕捉复杂模式 |
通过线性变换提取主要成分,识别在主成分空间中偏离的数据点。 |
|
|
贝叶斯网络(Bayesian Networks) |
适用于有先验知识和概率关系的数据异常检测 |
模型构建复杂,计算开销大 |
基于变量之间的概率依赖关系,计算数据点的概率,低概率点为异常。 |
|
|
可视化方法 |
箱线图 |
可视化各种分布的数据,快速识别异常值 |
仅适用于单变量数据,无法处理多维异常 |
通过绘制数据的四分位数和中位数,展示数据分布及异常值。 |
|
散点图 |
适用于双变量或多变量数据的可视化异常检测 |
视觉上难以识别大量数据中的异常值 |
通过绘制数据点的位置关系,直观展示数据中的异常分布。 |
|
|
直方图(Histogram) |
显示数据分布形态,识别偏离常态的异常值 |
难以处理多维数据,依赖于分箱策略 |
通过分组显示数据频率,观察数据分布中的异常峰或低谷。 |
|
|
QQ图(Quantile-Quantile Plot) |
检验数据分布是否符合特定理论分布,识别偏差异常 |
需要对比理论分布,解释结果需专业知识 |
将数据分位数与理论分位数对比,判断数据分布的一致性。 |
|
|
基于模型的方法 |
K-近邻 |
适用于多维数据,通过邻近关系检测异常 |
计算复杂度高,选择K值敏感 |
基于数据点的邻近数量和距离,判断其是否为异常。 |
|
聚类分析(如DBSCAN) |
适用于发现任意形状的聚类和异常点 |
对参数敏感,难以处理高维数据 |
通过密度聚类方法,识别密集区域及孤立的异常点。 |
|
|
隔离森林(Isolation Forest) |
适用于大规模高维数据的异常检测 |
对参数选择敏感,解释性较差 |
通过随机分割数据,隔离异常点需要较少的分割步骤。 |
|
|
单类支持向量机(One-Class SVM) |
适用于高维数据的异常检测,尤其是复杂边界 |
计算复杂度高,参数选择困难 |
学习正常数据的边界,识别落在边界外的异常点。 |
|
|
自编码器(Autoencoder) |
适用于非线性和高维数据的异常检测 |
训练复杂,需要大量数据,解释性较差 |
利用神经网络重构输入数据,重构误差较大的数据点被视为异常。 |
|
|
随机森林(Random Forest) |
通过集成决策树进行异常检测,适用于多维数据 |
模型较大,训练时间长,解释性一般 |
通过构建多个决策树,利用投票机制识别不符合大多数树预测的数据点。 |
|
|
局部离群因子(Local Outlier Factor, LOF) |
基于密度的异常检测,适用于多维数据 |
对参数敏感,难以处理大规模数据 |
通过比较数据点与其邻近点的密度,识别密度显著较低的异常点。 |
|
|
数据清洗-缺失值处理 |
||||
|
常用基础插值模型 |
均值/中位数/众数填补(Mean/Median/Mode Imputation) |
适用于数值型或类别型数据的简单缺失值填补 |
忽视数据的变异性,可能引入偏差 |
使用数据的均值、中位数或众数替代缺失值。 |
|
线性插值(Linear Interpolation) |
适用于时间序列数据的连续缺失值填补 |
仅适用于线性关系,无法处理非线性缺失 |
通过已知数据点之间的直线进行插值,填补缺失位置的数据。 |
|
|
多项式插值(Polynomial Interpolation) |
适用于具有多项式趋势的连续缺失值填补 |
容易过拟合,计算复杂度高 |
使用多项式函数拟合已知数据点,插值缺失值。 |
|
|
样条插值(Spline Interpolation) |
适用于平滑连续的缺失值填补 |
对异常值敏感,选择节点位置影响结果 |
通过分段多项式函数实现数据的平滑插值,适应数据的局部变化。 |
|
|
前向填充/后向填充(Forward/Backward Fill) |
适用于时间序列数据的缺失值填补 |
可能引入重复数据,无法处理非时间序列数据 |
使用前一个或后一个有效数据点的值填补缺失值。 |
|
|
高阶插值模型 |
多重插补(Multiple Imputation) |
适用于多变量数据的缺失值填补 |
计算复杂,需要多次插补结果的合并 |
生成多个插补数据集,综合多次插补结果以减少不确定性。 |
|
K-邻近插补(K-Nearest Neighbors Imputation, KNN) |
适用于多维数据,通过相似样本填补缺失值 |
计算复杂度高,对异常值敏感 |
根据样本间的距离,利用最近邻的已知值进行插补。 |
|
|
模型预测插补(Model-Based Imputation) |
适用于多变量数据,通过建立预测模型填补缺失值 |
模型依赖性强,可能引入模型偏差 |
使用回归、决策树等模型预测缺失值,基于其他变量的信息。 |
|
|
热卡填补(Hot-Deck Imputation) |
适用于调查数据,通过相似样本填补缺失值 |
依赖于样本的相似性,可能引入随机误差 |
从相似的完整样本中随机选取一个值来填补缺失值。 |
|
|
冷卡填补(Cold-Deck Imputation) |
适用于需要一致填补策略的数据集,通过预定义值填补缺失 |
可能不适应所有样本的具体情况,填补效果有限 |
使用预先确定的固定值或规则来填补缺失值。 |
|
|
回归插补(Regression Imputation) |
适用于有明确变量关系的数据,通过回归模型预测缺失值 |
依赖于线性关系假设,可能低估数据的变异性 |
建立回归模型,利用其他变量预测缺失值。 |
|
|
期望最大化(Expectation-Maximization, EM)算法 |
适用于统计模型中缺失数据的估计 |
计算复杂,收敛速度可能慢 |
迭代估计缺失数据的期望值,通过最大化似然函数优化参数。 |
|
|
深度学习插补(Deep Learning Imputation) |
适用于复杂高维数据,通过神经网络填补缺失值 |
训练复杂,需要大量数据,计算资源需求高 |
利用神经网络模型学习数据的潜在结构,预测并填补缺失值。 |
|
|
矩阵分解插补(Matrix Factorization Imputation) |
适用于大规模稀疏数据,通过矩阵分解填补缺失值 |
对噪声敏感,需要选择合适的分解方法 |
分解数据矩阵为低秩矩阵,利用分解结果预测缺失值。 |
|
|
随机森林插补(Random Forest Imputation) |
适用于多变量数据,通过随机森林模型预测缺失值 |
模型复杂,训练时间较长,解释性一般 |
使用随机森林模型,根据其他特征预测并填补缺失值。 |
|
|
贝叶斯插补(Bayesian Imputation) |
适用于具有先验知识的数据,通过贝叶斯方法填补缺失值 |
计算复杂,需要先验分布信息 |
基于贝叶斯统计理论,结合先验信息和数据观测,估计缺失值。 |
|




有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 20
20 0
0- 0



 已为社区贡献41条内容
已为社区贡献41条内容

所有评论(0)