中科院重磅:语义查询+实例查询,DocSAM让文档AI脱胎换骨!
【论文摘要】DocSAM提出了一种统一文档图像分割框架,通过查询分解和异构混合学习解决现有方法泛化性差的问题。该模型采用实例查询和语义查询的双路径设计,在混合查询解码器中进行交互:首先通过自注意力交换信息,再分别与图像特征进行交叉注意力计算,最后通过开放集分类机制实现多任务统一处理。核心创新包括:1)将不同分割任务统一为实例/语义分割组合;2)利用Sentence-BERT生成语义查询;3)通过点
·
CoMBO
论文《DOCSAM: UNIFIED DOCUMENT IMAGE SEGMENTATION VIA QUERY DECOMPOSITION AND HETEROGENEOUS MIXED LEARNING》
论文地址: https://arxiv.org/abs/2504.04156
深度交流Q裙:1051849847
全网同名 【大嘴带你水论文】 B站定时发布详细讲解视频
详细代码见文章最后

1、作用
DocSAM旨在解决文档图像分割(DIS)领域中存在的问题,即现有方法通常针对特定任务(如文档布局分析、多粒度文本分割、表格结构识别)设计专门模型,导致泛化能力差和资源浪费。DocSAM提供了一个统一的框架,能够同时处理多种DIS任务,从而提高效率、鲁棒性和泛化能力,适用于广泛的文档图像理解应用。
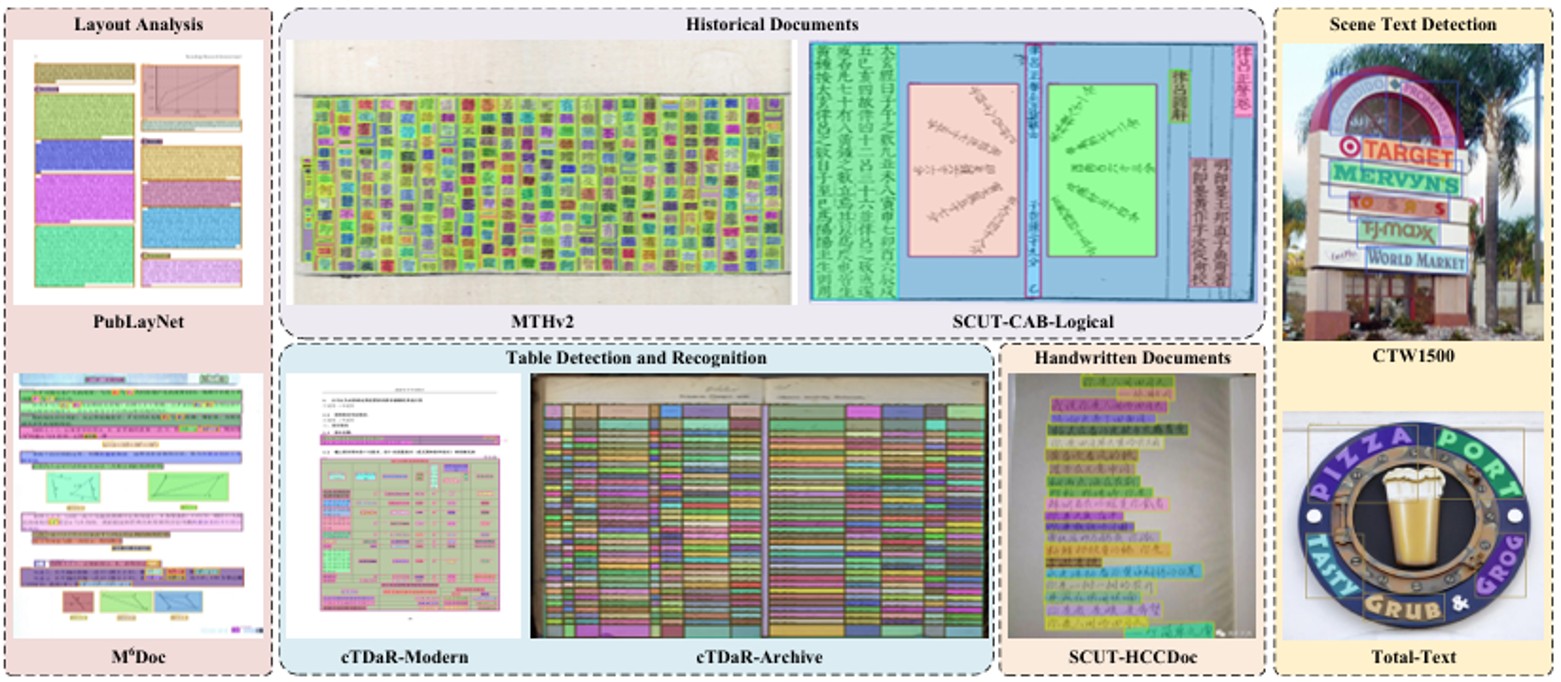
2、机制
- 统一任务范式:DocSAM将各种文档图像分割任务(如布局分析、文本分割、表格识别)统一为实例分割和语义分割的组合。这种方法允许模型在不同的数据集和任务上进行联合训练。
- 查询分解与交互:模型采用两种类型的查询:可学习的实例查询(Instance Queries)和从类别名称生成的语义查询(Semantic Queries)。语义查询是通过Sentence-BERT将类别名称(如“表格”、“图片”)嵌入到与实例查询相同维度的向量中而得到的。
- 混合查询解码器(Hybrid Query Decoder, HQD):实例查询和语义查询在HQD中进行交互。它们首先通过自注意力机制进行信息交换,然后分别与图像特征进行交叉注意力计算,最后再次交互。这种设计使得模型能够同时利用通用的对象检测能力(来自实例查询)和特定于类别的语义信息(来自语义查询)。
- 开放集分类:实例的类别是通过计算实例查询和语义查询之间的点积来预测的,这实质上是将分类问题转化为一个相似度匹配问题。这种设计使得模型能够轻松适应新的类别,而无需重新训练分类头,从而实现了开放集(open-set)分类。
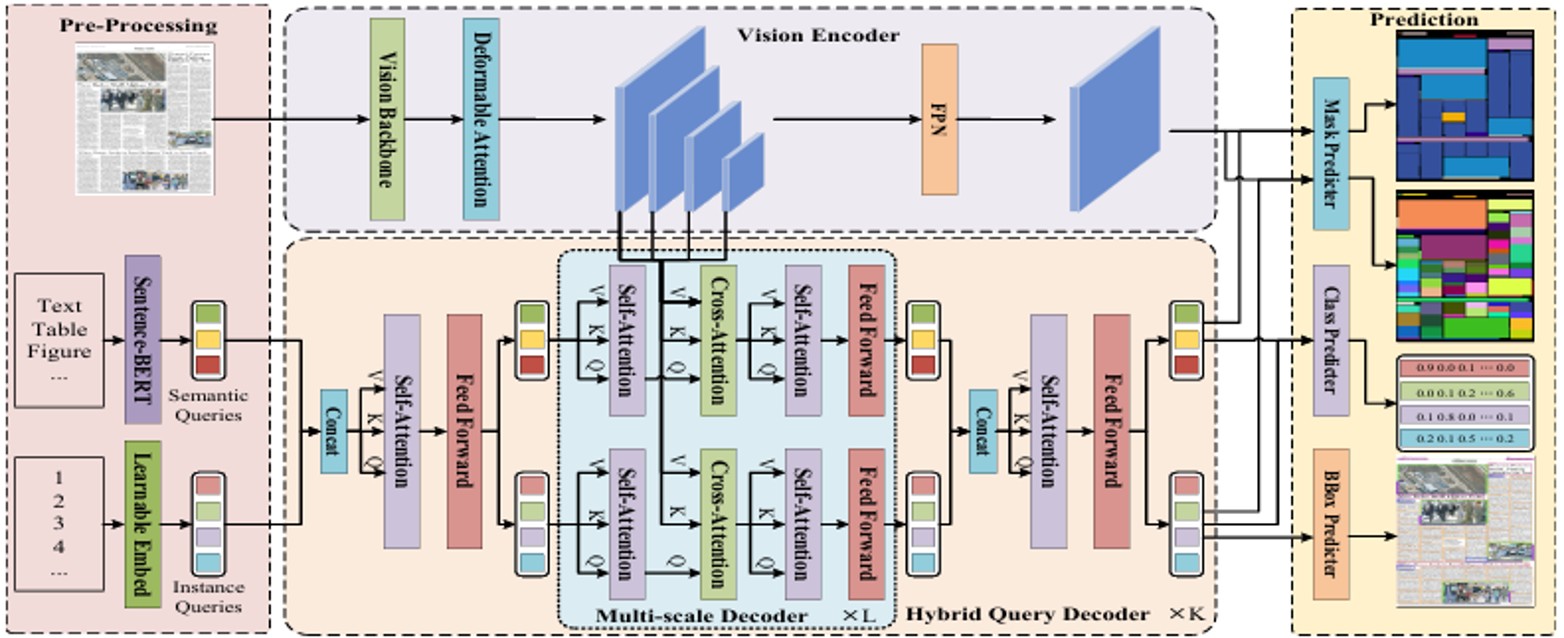
3、代码实现
import torch
import torch.nn as nn
import torch.nn.functional as F
import numpy as np
class MockVisionBackbone(nn.Module):
def __init__(self, embed_dim=256):
super().__init__()
# 使用简单的卷积层模拟特征提取
self.conv = nn.Conv2d(3, embed_dim, kernel_size=3, stride=1, padding=1)
def forward(self, images):
# 假设输出一个特征图,实际中应为多尺度特征
return self.conv(images)
class MockDeformableEncoder(nn.Module):
"""
模拟的可变形编码器
"""
def __init__(self, embed_dim=256):
super().__init__()
# 使用恒等映射作为占位符,不改变输入特征
self.identity = nn.Identity()
def forward(self, features):
return self.identity(features)
class MockSentenceBERT(nn.Module):
def __init__(self, embed_dim=256):
super().__init__()
self.embed_dim = embed_dim
def encode(self, class_names, convert_to_tensor=True):
# 为每个类名生成一个随机向量作为其嵌入
embeddings = [torch.randn(self.embed_dim) for _ in class_names]
if convert_to_tensor:
return torch.stack(embeddings)
return embeddings
# =====================================================================================
# DocSAM 核心实现 (Core Implementation)
# =====================================================================================
class HybridQueryDecoderLayer(nn.Module):
def __init__(self, embed_dim, num_heads):
super().__init__()
# 1. 查询间的自注意力:允许实例查询和语义查询交换信息
self.self_attn = nn.MultiheadAttention(embed_dim, num_heads, batch_first=True)
# 2. 实例查询与图像特征的交叉注意力
self.cross_attn_instance = nn.MultiheadAttention(embed_dim, num_heads, batch_first=True)
# 3. 语义查询与图像特征的交叉注意力
self.cross_attn_semantic = nn.MultiheadAttention(embed_dim, num_heads, batch_first=True)
# 归一化层
self.norm1 = nn.LayerNorm(embed_dim)
self.norm2 = nn.LayerNorm(embed_dim)
self.norm3 = nn.LayerNorm(embed_dim)
self.norm_ffn_instance = nn.LayerNorm(embed_dim)
self.norm_ffn_semantic = nn.LayerNorm(embed_dim)
# 前馈网络 (FFN)
self.ffn_instance = nn.Sequential(
nn.Linear(embed_dim, embed_dim * 4), nn.ReLU(), nn.Linear(embed_dim * 4, embed_dim)
)
self.ffn_semantic = nn.Sequential(
nn.Linear(embed_dim, embed_dim * 4), nn.ReLU(), nn.Linear(embed_dim * 4, embed_dim)
)
def forward(self, instance_queries, semantic_queries, image_features_flat):
# 展平图像特征以用于注意力机制 (B, C, H, W) -> (B, H*W, C)
B, C, H, W = image_features_flat.shape
image_features = image_features_flat.flatten(2).transpose(1, 2)
# 1. 混合查询间的自注意力
queries = torch.cat([instance_queries, semantic_queries], dim=1)
q_attn = self.self_attn(queries, queries, queries)[0]
queries = self.norm1(queries + q_attn)
instance_queries, semantic_queries = torch.split(queries, [instance_queries.size(1), semantic_queries.size(1)], dim=1)
# 2. 实例查询与图像特征的交叉注意力
instance_out = self.cross_attn_instance(instance_queries, image_features, image_features)[0]
instance_queries = self.norm2(instance_queries + instance_out)
# 3. 语义查询与图像特征的交叉注意力
semantic_out = self.cross_attn_semantic(semantic_queries, image_features, image_features)[0]
semantic_queries = self.norm3(semantic_queries + semantic_out)
# 4. 前馈网络
instance_queries = self.norm_ffn_instance(instance_queries + self.ffn_instance(instance_queries))
semantic_queries = self.norm_ffn_semantic(semantic_queries + self.ffn_semantic(semantic_queries))
return instance_queries, semantic_queries
class HybridQueryDecoder(nn.Module):
def __init__(self, embed_dim=256, num_heads=8, num_layers=6):
super().__init__()
self.layers = nn.ModuleList([
HybridQueryDecoderLayer(embed_dim, num_heads) for _ in range(num_layers)
])
def forward(self, instance_queries, semantic_queries, image_features):
for layer in self.layers:
instance_queries, semantic_queries = layer(instance_queries, semantic_queries, image_features)
return instance_queries, semantic_queries
class DocSAM(nn.Module):
"""
DocSAM 模型
"""
def __init__(self, num_instance_queries=100, num_classes=10, embed_dim=256):
super().__init__()
# 1. 视觉和文本编码模块 (使用模拟版本)
self.vision_backbone = MockVisionBackbone(embed_dim)
self.deformable_encoder = MockDeformableEncoder(embed_dim)
self.sentence_bert = MockSentenceBERT(embed_dim)
# 2. 可学习的实例查询
self.instance_queries = nn.Parameter(torch.randn(num_instance_queries, embed_dim))
# 3. 混合查询解码器
self.hqd = HybridQueryDecoder(embed_dim=embed_dim)
# 4. 预测头
# 掩码预测头
self.mask_predictor = nn.Sequential(
nn.Conv2d(embed_dim, embed_dim, kernel_size=3, padding=1),
nn.ReLU(),
nn.Conv2d(embed_dim, embed_dim, kernel_size=3, padding=1)
)
# 边界框预测头
self.bbox_predictor = nn.Sequential(
nn.Linear(embed_dim, embed_dim), nn.ReLU(), nn.Linear(embed_dim, 4)
)
print("DocSAM 模型初始化完成。")
def forward(self, images, class_names):
"""
模型的前向传播。
"""
# 1. 提取图像特征
image_features = self.vision_backbone(images)
refined_features = self.deformable_encoder(image_features) # (B, C, H, W)
# 2. 生成语义查询
# 在此模拟实现中,我们为每个批次项重新计算,实际中可优化
semantic_queries = self.sentence_bert.encode(class_names).to(images.device)
semantic_queries = semantic_queries.unsqueeze(0).repeat(images.size(0), 1, 1) # (B, num_classes, C)
# 3. 混合查询解码器处理
instance_queries = self.instance_queries.unsqueeze(0).repeat(images.size(0), 1, 1)
instance_queries_out, semantic_queries_out = self.hqd(
instance_queries,
semantic_queries,
refined_features
)
# 4. 生成预测结果
# 掩码预测
mask_embed = self.mask_predictor(refined_features)
pred_masks = torch.einsum("bqc,bchw->bqhw", instance_queries_out, mask_embed)
# 类别预测 (通过计算与语义查询的相似度)
pred_logits = torch.einsum("bqc,bkc->bqk", instance_queries_out, semantic_queries_out)
# 边界框预测
pred_boxes = self.bbox_predictor(instance_queries_out).sigmoid()
print("--- DocSAM 前向传播完成 ---
")
return {
"pred_masks": pred_masks,
"pred_logits": pred_logits,
"pred_boxes": pred_boxes
}
if __name__ == '__main__':
# --- 1. 定义超参数 ---
BATCH_SIZE = 2
IMG_HEIGHT = 256
IMG_WIDTH = 256
EMBED_DIM = 256
NUM_INSTANCE_QUERIES = 100
CLASS_NAMES = ["表格", "图片", "段落", "标题", "页眉", "页脚"]
NUM_CLASSES = len(CLASS_NAMES)
# --- 2. 初始化模型 ---
model = DocSAM(
num_instance_queries=NUM_INSTANCE_QUERIES,
num_classes=NUM_CLASSES,
embed_dim=EMBED_DIM
)
# --- 3. 准备模拟输入数据 ---
# 创建随机图像数据
dummy_images = torch.rand(BATCH_SIZE, 3, IMG_HEIGHT, IMG_WIDTH)
print(f"创建了形状为 {dummy_images.shape} 的模拟图像张量。")
# --- 4. 执行模型前向传播 ---
# 将模型置于评估模式
model.eval()
with torch.no_grad():
outputs = model(dummy_images, CLASS_NAMES)
# --- 5. 检查输出结果 ---
print(f"预测掩码 (pred_masks) 的形状: {outputs['pred_masks'].shape}")
print(f"预测类别 (pred_logits) 的形状: {outputs['pred_logits'].shape}")
print(f"预测边界框 (pred_boxes) 的形状: {outputs['pred_boxes'].shape}")
详细代码 gitcode地址:https://gitcode.com/2301_80107842/research

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 3
3 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)