π0应用到自己的 aubo机械臂上
修改src/openpi/policies/aloha_policy为src/openpi/policies/aubo_policy.py。2数据集变化:增添examples/hhy_test/convert_aubo_data_to_lerobot.py。根据examples/inference.ipynb提供的方式我建立了一个eval.py。在路径:src/openpi/training/co
π0现已开源,配置和环境安装请参考:
GitHub - c237814486/OA-Stereo
Model 复现系列(三)π0 -- Physical Intelligence Pi-zero(Pi0)_pi0复现-CSDN博客
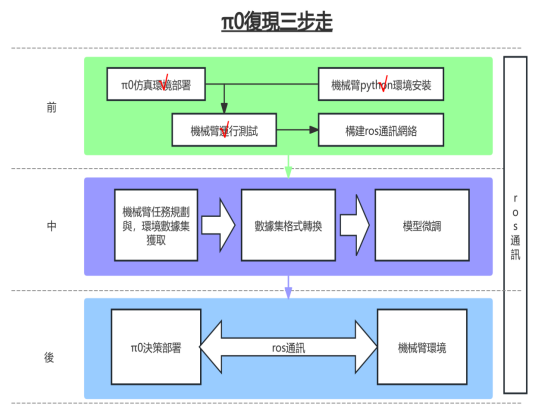
本文章主要简单描述本人是如何将π0部署的。
1.首先我们需要配置训练信息:
在路径:src/openpi/training/config.py中增加
TrainConfig(
name="pi0_your_custom_task1",
#model=pi0.Pi0Config(),
model=pi0.Pi0Config(paligemma_variant="gemma_2b_lora", action_expert_variant="gemma_300m_lora"),
#LeRobotLiberoDataConfig
data=LeRobotAuboDataConfig(
repo_id="your-org/your-dataset-name",#
assets=AssetsConfig(
#assets_dir = "/home/taizun/hhy_ws/openpi/openpi/assets/pi0_your_custom_task/physical-intelligence",
asset_id="your-org/your-dataset-name",
),
default_prompt="Pick the purple mangosteen and place it into the green pot.",
repack_transforms=_transforms.Group(
inputs=[
_transforms.RepackTransform(
{
"images": {
"top": "observation.images.top",
"wrist": "observation.images.wrist"
},
"state": "observation.state",
"actions": "action",
}
)
]
),
),
batch_size=1,
weight_loader=weight_loaders.CheckpointWeightLoader("gs://openpi-assets/checkpoints/pi0_base/params"),
num_train_steps=20_000,
freeze_filter=pi0.Pi0Config(
paligemma_variant="gemma_2b_lora", action_expert_variant="gemma_300m_lora"
).get_freeze_filter(),
ema_decay=None,
),可以根据自己的情况进行更改,以上配置设置了仅微调动作解释部分。
2数据集变化:增添examples/hhy_test/convert_aubo_data_to_lerobot.py
"""
Script to convert Aloha hdf5 data to the LeRobot dataset v2.0 format.
Example usage: uv run examples/aloha_real/convert_aloha_data_to_lerobot.py --raw-dir /path/to/raw/data --repo-id <org>/<dataset-name>
"""
import dataclasses
from pathlib import Path
import shutil
from typing import Literal
import h5py
from lerobot.common.datasets.lerobot_dataset import LEROBOT_HOME
from lerobot.common.datasets.lerobot_dataset import LeRobotDataset
#from lerobot.common.datasets.push_dataset_to_hub._download_raw import download_raw
import numpy as np
import torch
import tqdm
import tyro
@dataclasses.dataclass(frozen=True)
class DatasetConfig:
use_videos: bool = True
tolerance_s: float = 0.0001
image_writer_processes: int = 10
image_writer_threads: int = 5
video_backend: str | None = None
DEFAULT_DATASET_CONFIG = DatasetConfig()
def create_empty_dataset(
repo_id: str,
robot_type: str,
mode: Literal["video", "image"] = "video",
*,
has_velocity: bool = False,
has_effort: bool = False,
dataset_config: DatasetConfig = DEFAULT_DATASET_CONFIG,
) -> LeRobotDataset:
motors = [
"right_waist",
"right_shoulder",
"right_elbow",
"right_forearm_roll",
"right_wrist_angle",
"right_wrist_rotate",
"right_gripper"
]
cameras = [
"top",
"wrist"
]
features = {
"observation.state": {
"dtype": "float32",
"shape": (len(motors),),
"names": [
motors,
],
},
"action": {
"dtype": "float32",
"shape": (len(motors),),
"names": [
motors,
],
},
}
if has_velocity:
features["observation.velocity"] = {
"dtype": "float32",
"shape": (len(motors),),
"names": [
motors,
],
}
if has_effort:
features["observation.effort"] = {
"dtype": "float32",
"shape": (len(motors),),
"names": [
motors,
],
}
for cam in cameras:
features[f"observation.images.{cam}"] = {
"dtype": mode,
"shape": (3, 480, 640),
"names": [
"channels",
"height",
"width",
],
}
if Path(LEROBOT_HOME / repo_id).exists():
shutil.rmtree(LEROBOT_HOME / repo_id)
return LeRobotDataset.create(
repo_id=repo_id,
fps=50,
robot_type=robot_type,
features=features,
use_videos=dataset_config.use_videos,
tolerance_s=dataset_config.tolerance_s,
image_writer_processes=dataset_config.image_writer_processes,
image_writer_threads=dataset_config.image_writer_threads,
video_backend=dataset_config.video_backend,
)
def get_cameras(hdf5_files: list[Path]) -> list[str]:
with h5py.File(hdf5_files[0], "r") as ep:
# ignore depth channel, not currently handled
return [key for key in ep["/observations/images"].keys() if "depth" not in key] # noqa: SIM118
def has_velocity(hdf5_files: list[Path]) -> bool:
with h5py.File(hdf5_files[0], "r") as ep:
return "/observations/qvel" in ep
def has_effort(hdf5_files: list[Path]) -> bool:
with h5py.File(hdf5_files[0], "r") as ep:
return "/observations/effort" in ep
def load_raw_images_per_camera(ep: h5py.File, cameras: list[str]) -> dict[str, np.ndarray]:
imgs_per_cam = {}
for camera in cameras:
uncompressed = ep[f"/observations/images/{camera}"].ndim == 4
if uncompressed:
# load all images in RAM
imgs_array = ep[f"/observations/images/{camera}"][:]
else:
import cv2
# load one compressed image after the other in RAM and uncompress
imgs_array = []
for data in ep[f"/observations/images/{camera}"]:
imgs_array.append(cv2.cvtColor(cv2.imdecode(data, 1), cv2.COLOR_BGR2RGB))
imgs_array = np.array(imgs_array)
imgs_per_cam[camera] = imgs_array
return imgs_per_cam
def load_raw_episode_data(
ep_path: Path,
) -> tuple[dict[str, np.ndarray], torch.Tensor, torch.Tensor, torch.Tensor | None, torch.Tensor | None]:
with h5py.File(ep_path, "r") as ep:
state = torch.from_numpy(ep["/observations/qpos"][:])
action = torch.from_numpy(ep["/action"][:])
velocity = None
if "/observations/qvel" in ep:
velocity = torch.from_numpy(ep["/observations/qvel"][:])
effort = None
if "/observations/effort" in ep:
effort = torch.from_numpy(ep["/observations/effort"][:])
imgs_per_cam = load_raw_images_per_camera(
ep,
[
"top",
"wrist"
],
)
return imgs_per_cam, state, action, velocity, effort
def populate_dataset(
dataset: LeRobotDataset,
hdf5_files: list[Path],
task: str,
episodes: list[int] | None = None,
) -> LeRobotDataset:
if episodes is None:
episodes = range(len(hdf5_files))
for ep_idx in tqdm.tqdm(episodes):
ep_path = hdf5_files[ep_idx]
imgs_per_cam, state, action, velocity, effort = load_raw_episode_data(ep_path)
num_frames = state.shape[0]
for i in range(num_frames):
frame = {
"observation.state": state[i],
"action": action[i],
"task": task,
}
for camera, img_array in imgs_per_cam.items():
frame[f"observation.images.{camera}"] = img_array[i]
if velocity is not None:
frame["observation.velocity"] = velocity[i]
if effort is not None:
frame["observation.effort"] = effort[i]
dataset.add_frame(frame)
dataset.save_episode()
return dataset
def port_aloha(
raw_dir: Path,
repo_id: str,
raw_repo_id: str | None = None,
task: str = "DEBUG",
*,
episodes: list[int] | None = None,
push_to_hub: bool = True,
is_mobile: bool = False,
mode: Literal["video", "image"] = "image",
dataset_config: DatasetConfig = DEFAULT_DATASET_CONFIG,
):
if (LEROBOT_HOME / repo_id).exists():
shutil.rmtree(LEROBOT_HOME / repo_id)
'''
if not raw_dir.exists():
if raw_repo_id is None:
raise ValueError("raw_repo_id must be provided if raw_dir does not exist")
download_raw(raw_dir, repo_id=raw_repo_id)'''
hdf5_files = sorted(raw_dir.glob("episode_*.hdf5"))
dataset = create_empty_dataset(
repo_id,
robot_type="mobile_aloha" if is_mobile else "aloha",
mode=mode,
has_effort=has_effort(hdf5_files),
has_velocity=has_velocity(hdf5_files),
dataset_config=dataset_config,
)
dataset = populate_dataset(
dataset,
hdf5_files,
task=task,
episodes=episodes,
)
#dataset.consolidate()
'''
if push_to_hub:
dataset.push_to_hub()'''
if __name__ == "__main__":
tyro.cli(port_aloha)
修改src/openpi/policies/aloha_policy为src/openpi/policies/aubo_policy.py
主要替换一下内容
class auboInputs(transforms.DataTransformFn):
"""Inputs for the Aloha policy.
Expected inputs:
- images: dict[name, img] where img is [channel, height, width]. name must be in EXPECTED_CAMERAS.
- state: [14]
- actions: [action_horizon, 14]
"""
# The action dimension of the model. Will be used to pad state and actions.
action_dim: int = 32
# If true, this will convert the joint and gripper values from the standard Aloha space to
# the space used by the pi internal runtime which was used to train the base model.
adapt_to_pi: bool = True
# The expected cameras names. All input cameras must be in this set. Missing cameras will be
# replaced with black images and the corresponding `image_mask` will be set to False.
EXPECTED_CAMERAS: ClassVar[tuple[str, ...]] = ("top")
def __call__(self, data: dict) -> dict:
print("111111111111111\ndata",data["state"].shape)
data = _decode_aloha(data, adapt_to_pi=self.adapt_to_pi)
#self.action_dim = 7
# Get the state. We are padding from 14 to the model action dim.
state = transforms.pad_to_dim(data["state"], self.action_dim)
in_images = data["images"]
# if set(in_images) - set(self.EXPECTED_CAMERAS):
# raise ValueError(f"Expected images to contain {self.EXPECTED_CAMERAS}, got {tuple(in_images)}")
# Assume that base image always exists.
base_image = in_images["top"]
images = {
"base_0_rgb": base_image,
}
image_masks = {
"base_0_rgb": np.True_,
}
# dest = "left_wrist_0_rgb"
# images[dest] = in_images["wrist"]
# image_masks[dest] = np.True_
# Add the extra images.
extra_image_names = {
"left_wrist_0_rgb": "wrist",
# "right_wrist_0_rgb": "cam_right_wrist",
}
for dest, source in extra_image_names.items():
if source in in_images:
images[dest] = in_images[source]
image_masks[dest] = np.True_
else:
images[dest] = np.zeros_like(base_image)
image_masks[dest] = np.False_
inputs = {
"image": images,
"image_mask": image_masks,
"state": state,
}
# Actions are only available during training.
if "actions" in data:
actions = np.asarray(data["actions"])
actions = _encode_actions_inv(actions, adapt_to_pi=self.adapt_to_pi)
inputs["actions"] = transforms.pad_to_dim(actions, self.action_dim)
if "prompt" in data:
inputs["prompt"] = data["prompt"]
return inputs
在src/openpi/models/model.py中需要修改摄像头配置:
# The model always expects these images
IMAGE_KEYS = (
"base_0_rgb",
"left_wrist_0_rgb",
# "right_wrist_0_rgb",
)
验证eval.py:
根据examples/inference.ipynb提供的方式我建立了一个eval.py
import socket
import pickle
import numpy as np
import cv2
import realsense
import hhy_save_urdf
import dataclasses
import pyrealsense2 as rs
# pip_line = realsense.camera_init()
img = np.zeros((200, 500, 3), np.uint8)
cv2.imshow("12", img)
# cv2.waitKey()
# 获取所有连接的设备
ctx = rs.context()
devices = ctx.query_devices()
print(f"找到 {len(devices)} 个设备")
# writs
cfg = rs.config()
cfg.enable_device("008222071923")
# 配置流(可以根据需要为不同设备设置不同参数)
cfg.enable_stream(rs.stream.depth, 640, 480, rs.format.z16, 30)
cfg.enable_stream(rs.stream.color, 640, 480, rs.format.bgr8, 30)
# 创建并启动流水线
pipeline_top = rs.pipeline(ctx)
pipeline_top.start(cfg)
# top
cfg = rs.config()
cfg.enable_device("250122073121")
# 配置流(可以根据需要为不同设备设置不同参数)
cfg.enable_stream(rs.stream.depth, 640, 480, rs.format.z16, 30)
cfg.enable_stream(rs.stream.color, 640, 480, rs.format.bgr8, 30)
# 创建并启动流水线
pipeline_wrist = rs.pipeline(ctx)
pipeline_wrist.start(cfg)
old_action = None
#realsense.get_img(pipeline_top)
import einops
import jax
import numpy as np
from openpi.models import model as _model
from openpi.policies import droid_policy
from openpi.policies import policy_config as _policy_config
from openpi.shared import download
from openpi.training import config as _config
from openpi.training import data_loader as _data_loader
def get_obs(action):
# global old_action
# if old_action is None:
# old_action = action
# observation = {}
# color_image, depth_colormap = realsense.get_img(pip_line)
# observation["top"] = np.array(color_image)
# observation["positions_id1"] = np.array(old_action[:6])
# observation["id1_open"] = np.array(old_action[6])
# observation["action1"] = np.array(action)
# old_action = action
print("获取图像")
color_image_top, depth_colormap = realsense.get_img(pipeline_top)
color_image_wrist, depth_colormap = realsense.get_img(pipeline_wrist)
print("融合图像")
images = np.hstack((color_image_top, color_image_wrist))
try:
print("显示图像")
cv2.imshow('1212', images)
print("wait")
cv2.waitKey(1)
print("显示图像成功")
except cv2.error as e:
print(f"OpenCV GUI error: {e}")
print("Falling back to saving frames to disk.")
cv2.imwrite('realsense_output.jpg', images)
print("Saved frame to 'realsense_output.jpg'. Press Ctrl+C to exit.")
print("color_image",einops.rearrange(color_image_top, "h w c -> c h w").shape)
images = {
"top": einops.rearrange(color_image_top, "h w c -> c h w"),#np.random.randint(1, size=(3,640,480), dtype=np.uint8)
"wrist": einops.rearrange(color_image_wrist, "h w c -> c h w")#np.random.randint(1, size=(3,640,480), dtype=np.uint8)
}
observation = {
"images" :images,
"state" : action,#np.random.rand(7),
"prompt": "Pick the purple mangosteen and place it into the green pot.",
}
return observation
get_obs(None)
config = _config.get_config("pi0_your_custom_task1")
print("start download")
checkpoint_dir = download.maybe_download("/home/taizun/hhy_ws/openpi/openpi/checkpoints/pi0_your_custom_task1/your-org/your-dataset-name/19999")
print("finish download")
# Create a trained policy.
policy = _policy_config.create_trained_policy(config, checkpoint_dir)
print("Create a trained Pick the purple mangosteen and place it into the green pot.")
def main():
print("start main")
# 初始值
x, y, z = -0.27, -0.04, 0.45
gripper_open = 1000 # 0:闭合, 1000:打开
step = 0.05
# 创建黑色背景窗口
window_name = "Keyboard Control"
print("测试数据集获取")
action_data = np.array([x, y, z,180, 0, -102,gripper_open])
actions = [action_data,action_data,action_data]
print("初始状态获取")
get_obs(action_data)
cv2.waitKey(1)
episode_idx = 15
print("正在连接服务器")
# 创建客户端
client_socket = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
client_socket.connect(('localhost', 12345))
print("已连接到服务器")
while 1:
x, y, z = -0.27, -0.04, 0.45
gripper_open = 1000 # 0:闭合, 1000:打开
finash_task = False
obs=[]
print("start")
while True: # 持续通信循环
# 生成消息或 NumPy 数组(这里用用户输入示例)
#message = input("输入消息 (或 'array' 发送 NumPy 数组, 'exit' 退出): ")
#action_data = np.array([x, y, z,180, 0, -102,gripper_open]) # 生成 NumPy 数组
#print(action_data)
for action_data in actions[:2]:
# 发送数据
client_socket.send(pickle.dumps(action_data))
# 接收响应
response = pickle.loads(client_socket.recv(4096))
#先获取数据再执行action
observation= get_obs(action_data)
# obs.append(observation)
result = policy.infer(observation)
actions = result["actions"]
print(actions[:2,:])
key = cv2.waitKey()
# 处理按键
if key == 27: # ESC键退出
break
# if isinstance(response, np.ndarray):
# print(f"服务器响应 NumPy 数组:\n{response}")
# else:
# print(f"服务器响应: {response}")
# hhy_save_urdf.getobs_and_save_hdf5(obs,episode_idx)
# print("success in save hdf5 idx:",episode_idx)
# episode_idx+=1
if key == 27: # ESC键退出
break
client_socket.close()
pipeline_top.stop()
pipeline_wrist.stop()
try:
cv2.destroyAllWindows()
except cv2.error as e:
print(f"Error closing windows: {e}")
print("连接已断开")
if __name__ == "__main__":
main()运行流程:
1
uv run examples/hhy_test/convert_aubo_data_to_lerobot.py --raw-dir /home/taizun/hhy_ws/openpi/openpi/data/fix --repo-id your-org/your-dataset-name
2
uv run scripts/compute_norm_stats.py --config-name pi0_your_custom_task1
3
# 使用你的自定义配置名称
XLA_PYTHON_CLIENT_MEM_FRACTION=0.99 uv run scripts/train.py pi0_your_custom_task1 --exp_name your-org/your-dataset-name --overwrite
4
python eval.py

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 4
4 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)