AI笔记:大白话说什么是模型?什么是神经网络?
摘要 本文用通俗易懂的语言解释了模型、大模型和神经网络的基本概念。模型由架构(公式/结构)和参数组成,通过数据训练后可用于预测或分类任务。大模型(如大语言模型LLM)具有海量数据、庞大参数和强大算力的特点。神经网络作为一种模型架构,通过输入层、隐藏层和输出层处理复杂问题,其中隐藏层特征提取过程具有"黑盒"特性。文章还以MNIST手写数字识别为例,展示了神经网络的实际应用。最后,
目录
什么是模型?
什么是大模型?
什么是神经网络?
什么是模型?
大白话结论:
模型=架构(公式/结构) + 参数。
架构(公式/结构)定义了模型的计算逻辑和整体框架。这是一个复杂的、预先设计好的“计算流程图”或者“数学公式的骨架”。 它规定了计算的步骤和类型,但里面的具体“参数”还没有确定。
参数是模型架构中需要从数据中学习的具体数值。它们是模型“知识”和“能力”的载体。
举个例子
y=ax+b,这个公式就是一个架构,a和b就是两个参数。若经过训练后,a=2,b=3,则y=2x+3可以理解为就是一个模型。
实际案例
现在有一组数据样本,分别是鳄鱼和蛇的身长和体重,数据如下:
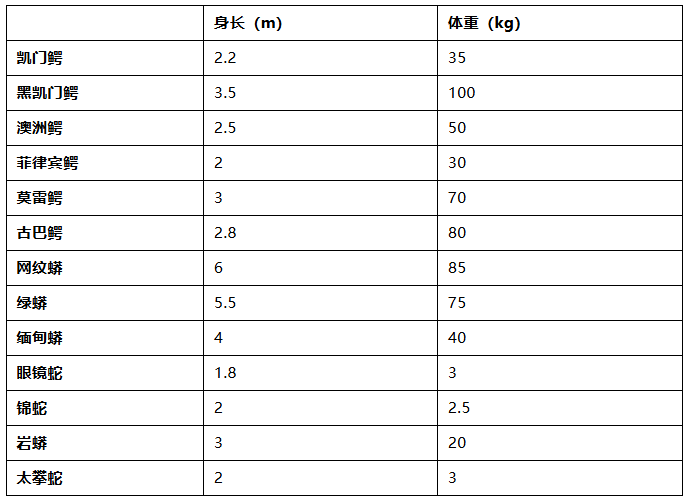

任务:做一个二分类任务,通过(身长、体重)作为输入,设计或者训练一个模型输出蛇和鳄鱼的概率。
我们将这些数据放到二维坐标上,如下图
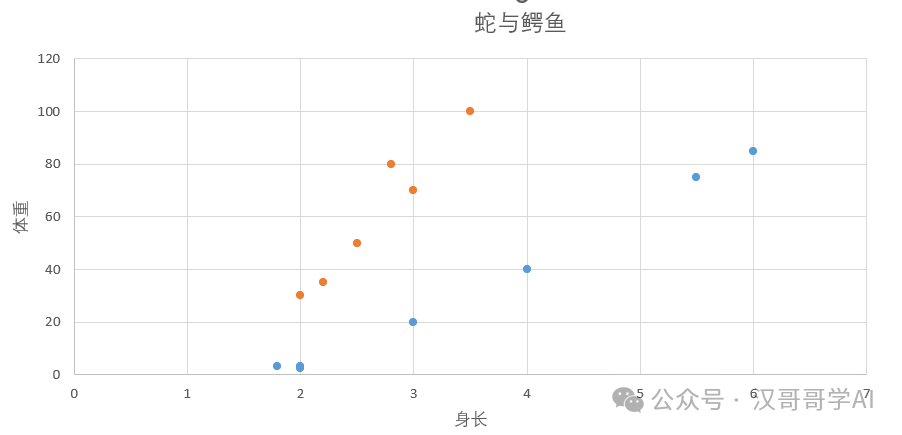
其中橙色点为鳄鱼,蓝色点为蛇,从图表可以看出,数据中存在一定的线性规律。
假如设计一个架构和公式为:y=ax+b,其中a=24,b=-24,即y=24x-24代入到图表中,可得出一条分界线(决策边界)见下图
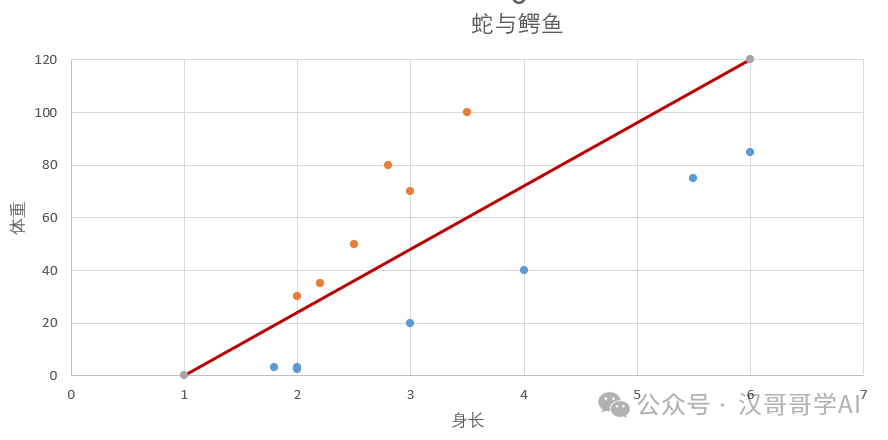
假定y=24x-24是最终所得的公式且可用,我们将公式变换为24x-24-y=0,再找来一批(x,y)数据,代入到公式中,我们可以得出以下规律及结论:
若24x-24-y=0,点将落在红线上,输出鳄鱼和蛇的概率都为50%;
若24x-24-y<0,点将落在红线上方,输出为鳄鱼概率较高,输出蛇的概率较低;
若24x-24-y>0,点将落在红线下方,输出为蛇概率较高,输出鳄鱼的概率较低;
那设计y=ax+b,求出a=24,b=-24,且通过输入(x,y)输出鳄鱼和蛇的概率的这个过程,就是模型设计及训练过程,y=24x-24就是我们所得出来的模型,可以用来解决未来的预测或规律等问题。
什么是大模型?
我们理解了什么是模型,那延展一下什么是大模型?
大模型全称是大语言模型(Large Language Model, LLM),那大模型跟上面所说的模型一样,架构+参数,且特指语言方面模型,大模型有几个“大”的特征:
1、大数据,海量的预料数据进行学习
2、大参数,参数量基本在上亿,上十上百亿
3、大算力,这么多的参数量,需要复杂的底层基础措施才能把这些参数跑起来,参数量计算及硬件评估会在以后文章进行介绍。
小模型?
偶尔看到一些文章说到的小模型又是什么?其实还是架构+参数,广义理解为参数量相对比较小的模型,狭义要结合文章语境,可能指的是小规模参数的大语言模型,比如3B(Billions)大小的大模型;可能指视觉方面(CV)的模型,比如YOLO、U-net家族,参数量在2到100M(Millions);可能指通过结构化数据总结规律的模型,比如上面的y=ax+b,像金融行业里客户的资质评分模型。
什么是神经网络?
现实中简单的问题,我们可以由算法工程师设计框架和公式,比如y=ax+b的。那复杂的真实问题怎么解决呢?—我们有神经网络。
复杂真实问题难以通过人类设计公式解决,神经网络作为万金油公式应运而生。
神经网络是一个模型结构,由输入层、隐藏层、输出层组成。下面是个示意图
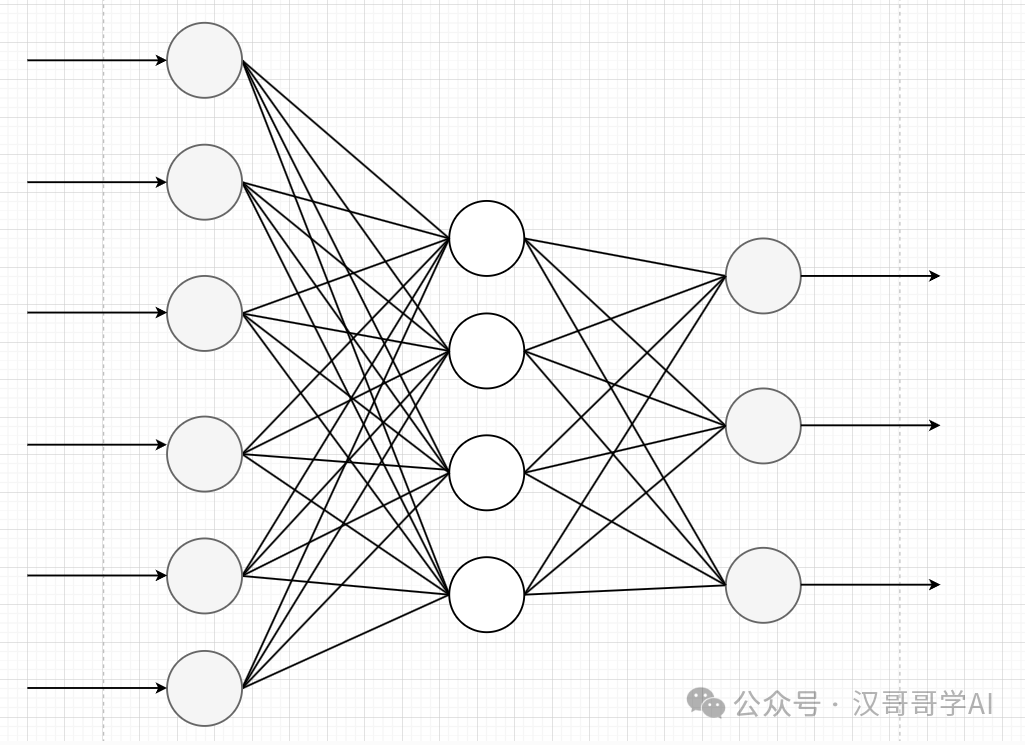
每个圆点是一个神经元,是每一层神经网络的输入或者输出。
每条连线是权重,可以理解为参数。
输入层:输入层的神经元数量必须与单个输入样本的特征数量严格相等。比如上面蛇和鳄鱼的例子,身长和体重就是样本特征,可以认为为两个输入。
输出层:根据我们要做任务来定义,比如上面蛇和鳄鱼的例子,我们要输出蛇和鳄鱼的概率,那就是有两个输出。如果是要输出20个概率,那就是有20个输出。
隐藏层:介于输入层和输出层中间的结构,如果这中间有很多层,比如超过10层,那可以把这个神经网络结构叫做深度神经网络。**隐藏层的每一层输出就是为了提取特征,**这个提取过程对于用户来说是一个“黑盒”,每一层提取了什么,缺乏可解释性。当然,科研人员还是有办法去定性及理解。
举个例子
这里说一个经典神经网络例子,MNIST(Mixed National Institue of Stands and Technology database)图片数据集,这个数据集包含了70000张手写的图像,每一张图像都是28*28像素的灰度图像,其中60000张用于训练,10000张用于测试,每张图像的内容只包含一个手写数字,从0到9的其中一个数字。见下图(图片来自网络)

那我们的任务:
给定一张28*28像素的灰度图像,经过一系列的计算,输出10个概率,分别为0到9的概率。
那就是做一个能做10分类任务的模型,我们还是围绕这个公式:模型=架构(公式/结构)+参数,我们先定义好这模型的输入、输出、结构。
输入
28*28个像素,即784像素输入。我们将这个784输入,设置为784维向量。
什么是向量?
向量就是一个有顺序的数字列表
-
一个购物清单:
[苹果, 香蕉, 牛奶]。如果我们用数字表示数量,比如[3, 5, 2],这个列表就是一个向量。它表示“买3个苹果,5根香蕉,2瓶牛奶”,这是一个三维向量。 -
一个人的特征:我们可以用
[身高(cm), 体重(kg), 年龄(岁)]来描述一个人,例如[175, 70, 28]。这也是一个3维向量。 -
上面蛇和鳄鱼的例子:我们可以用
[身长(m), 体重(kg)]来作为输入,例如[3.5,100]。这是一个2维向量。
784维向量:就是把所有像素按顺序平铺,784维向量看起来类似下面这个样子
[0, 0, 12, 150, 245, 0, 0, 78, … 0, 214, 87, 0, 0],里面一共有784个数字,每一个数字代表每一个像素。
输出
10个,因为需要输出10个概率,分别0到9的概率
结构
使用神经网络,假定隐藏层只有一层,x向量为输入,y向量为输出,z向量为隐藏层,见下图。
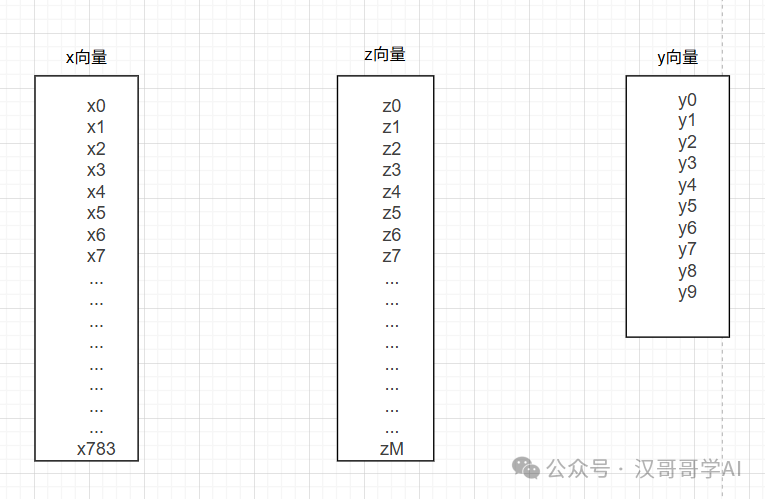
那怎么得出z向量呢?
一个简单的公式:z=w*x+b,计算步骤如下:
1、z0=w0x0+w1x1+w2x2+w3x3+w4x4+…+w783x783+b0,这是一个线性计算,其中w0、w1、w2…w783、b0就是我们上述所说模型的参数,也是模型训练待确认的参数,这些参数的设定将由机器来决定。
2、这个z0再进行激活函数计算(非线性变换),这个激活函数通常都是人类来设定。激活函数是用来帮助获取到数据特征的,比如MNIST中,可以帮助获取数字的轮廓、边框等特征。
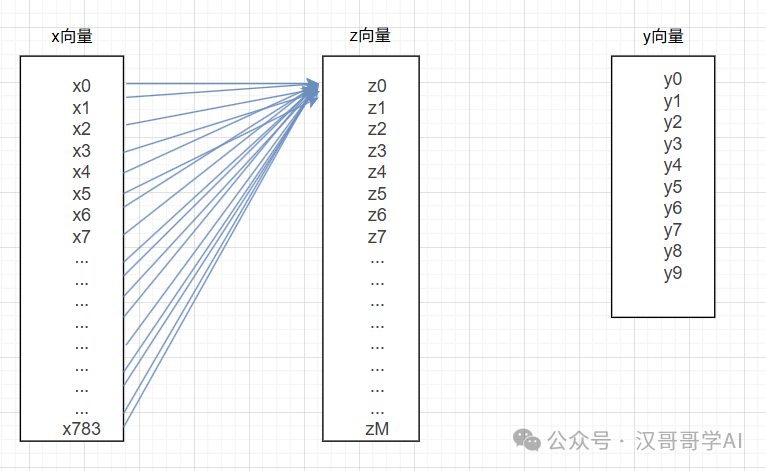
同理,z1=w0x0+w1x1+w2x2+w3x3+w4x4+…+w783x783+b1,其中这里z1的w0和z0的w0是完全不同的参数。
最后通过每一层的线性计算和非线性转换,最后得出y向量。
思考
为什么参数是由机器决定的呢?
总结
1、大白话结论:模型=架构+参数。
2、大模型是大语言模型,也是架构+参数。
3、神经网络是一种模型架构,含有公式和架构,能解决复杂的问题,其中激活函数等是人类设计的,参数则由机器进行学习决定。
最后
选择AI大模型就是选择未来!最近两年,大家都可以看到AI的发展有多快,我国超10亿参数的大模型,在短短一年之内,已经超过了100个,现在还在不断的发掘中,时代在瞬息万变,我们又为何不给自己多一个选择,多一个出路,多一个可能呢?
与其在传统行业里停滞不前,不如尝试一下新兴行业,而AI大模型恰恰是这两年的大风口,整体AI领域2025年预计缺口1000万人,人才需求急为紧迫!
由于文章篇幅有限,在这里我就不一一向大家展示了,学习AI大模型是一项系统工程,需要时间和持续的努力。但随着技术的发展和在线资源的丰富,零基础的小白也有很好的机会逐步学习和掌握。
【2025最新】AI大模型全套学习籽料(可白嫖):LLM面试题+AI大模型学习路线+大模型PDF书籍+640套AI大模型报告等等,从入门到进阶再到精通,超全面存下吧!
获取方式:有需要的小伙伴,可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】
包括:AI大模型学习路线、LLM面试宝典、0基础教学视频、大模型PDF书籍/笔记、大模型实战案例合集、AI产品经理合集等等
大模型学习之路,道阻且长,但只要你坚持下去,一定会有收获。本学习路线图为你提供了学习大模型的全面指南,从入门到进阶,涵盖理论到应用。
L1阶段:启航篇|大语言模型的基础认知与核心原理
L2阶段:攻坚篇|高频场景:RAG认知与项目实践
L3阶段:跃迀篇|Agent智能体架构设计
L4阶段:精进篇|模型微调与私有化部署
L5阶段:专题篇|特训集:A2A与MCP综合应用 追踪行业热点(全新升级板块)





AI大模型全套学习资料【获取方式】

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 24
24 0
0- 0



 已为社区贡献50条内容
已为社区贡献50条内容

所有评论(0)