一文搞懂 LoRA 如何高效微调大模型
随着大规模预训练模型不断增大,模型微调的资源需求和部署复杂度也急剧提升。LoRA(Low-Rank Adaptation)作为近年来高效微调的代表方案,因其在显存占用、训练效率和部署便捷性之间取得了平衡,迅速成为大模型微调的首选。
一文搞懂 LoRA 如何高效微调大模型
📚 微调系列文章
随着大规模预训练模型不断增大,模型微调的资源需求和部署复杂度也急剧提升。
LoRA(Low-Rank Adaptation)作为近年来高效微调的代表方案,因其在显存占用、训练效率和部署便捷性之间取得了平衡,迅速成为大模型微调的首选。
在深入理解 LoRA 之前,我们可以带着这三个问题来阅读本文:
- 为什么 LoRA 能在众多微调方案中脱颖而出?
- LoRA 的核心技术原理是什么,它是如何节省计算和显存资源的?
- 实际应用中,使用 LoRA 需要关注哪些关键细节?
所有相关源码示例、流程图、模型配置与知识库构建技巧,我也将持续更新在Github:LLMHub,欢迎关注收藏!
一、背景与挑战
在 LoRA 出现之前,微调大模型通常依赖全参数微调或 Adapter 方案。
- 全参数微调虽然效果最佳,但显存需求极高,训练门槛较高;
- Adapter 微调减少了训练参数,但会带来推理延迟和部署复杂度。
因此,研究者亟需一种既节省资源又能保证性能,且方便推理部署的微调方法。
LoRA 正是在这样的背景下诞生,目标明确:
- 显著降低训练时的显存与计算成本;
- 保持接近全参数微调的性能水平;
- 实现推理时无额外计算负担,方便快速部署。
二、LoRA 的技术原理
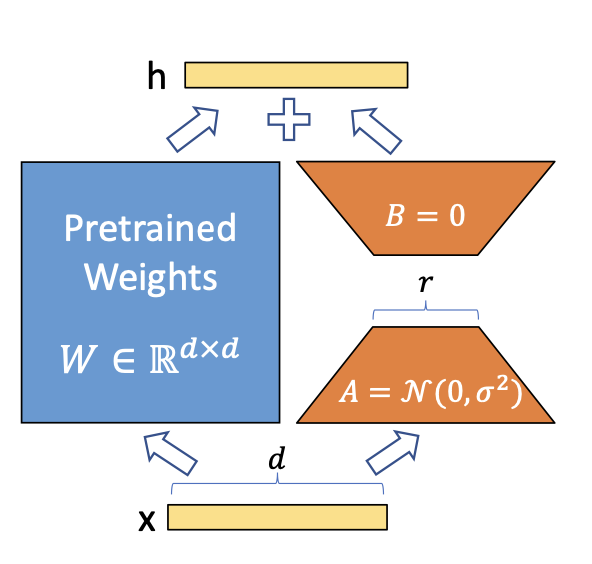
2.1 核心思想
Transformer 模型中,绝大部分计算来自于大规模权重矩阵与输入的乘法运算。直接微调这些庞大矩阵参数,意味着巨大的计算和显存开销。
LoRA 通过对权重更新做低秩分解,实现参数的高效表达。
具体而言,假设原权重矩阵为 W W W,LoRA 并不直接更新 W W W,而是引入两个小矩阵 A A A 和 B B B,使得权重的增量更新满足:
Δ W = A × B \Delta W = A \times B ΔW=A×B
其中, A ∈ R d × r A \in \mathbb{R}^{d \times r} A∈Rd×r, B ∈ R r × k B \in \mathbb{R}^{r \times k} B∈Rr×k,且秩 r ≪ d , k r \ll d, k r≪d,k。
训练过程中,仅优化这两个低秩矩阵参数,保持 W W W 不变,从而大幅减少可训练参数数量和计算资源。
2.2 实现细节
● 低秩大小 r r r 选择
r r r 通常在 4 到 64 之间,根据任务复杂度与资源限制调整。秩越小,资源消耗越少,但性能可能略降。
● 更新部位
LoRA 通常作用于 Transformer 中关键线性层(如自注意力的 Query、Key、Value 投影矩阵),保证微调效果最大化。
● 训练策略
初始化时,矩阵 B B B 通常初始化为零,保证初始模型表现不变; A A A 初始化为小随机值。
训练时仅更新 A A A、 B B B,其他参数冻结。
● 推理阶段
微调后,可以将 A B A B AB 直接合并进 W W W,推理时无额外计算开销,实现高效部署。
三、发展与变体
自 2021 年 LoRA 提出后,技术不断演进,形成多种变体:
- QLoRA
结合 4-bit 量化,极大压缩模型大小与显存需求,实现大模型微调的低资源化; - AdaLoRA
动态调整不同层的低秩大小,提高训练灵活性和性能; - PEFT 框架
在 Hugging Face PEFT 中标准化接口,实现 LoRA 快速集成和使用。
四、特点与适用场景
LoRA 的优势主要体现在:
- 显存占用低,适合单卡训练甚至低配设备;
- 训练高效,降低成本;
- 权重更新可合并,推理零额外负担;
- 良好兼容量化等压缩技术。
但也存在一定限制:
- 某些任务下性能略低于全参数微调;
- 低秩大小需精细调优。
适合应用于:
- 垂直领域问答与对话系统定制;
- 个性化生成任务;
- 资源有限环境下的大模型快速适配。
最后,我们来回答一下文章开头提出的三个问题:
- LoRA 为什么受欢迎?
它在性能与资源消耗间取得理想平衡,降低大模型微调门槛。 - 核心技术原理是什么?
通过低秩矩阵分解,只训练权重增量的低秩部分,显著减少显存和计算开销。 - 应用时需关注哪些?
需要合理设置低秩大小,权衡性能与资源;结合量化可进一步降低成本,但注意潜在精度损失。
关于深度学习和大模型相关的知识和前沿技术更新,请关注公众号coting!

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 36
36 0
0- 0



 已为社区贡献19条内容
已为社区贡献19条内容

所有评论(0)