LangGraph:构建AI Agent的利器
传统的LLM应用往往是线性的,即用户输入一个问题,模型生成一个回答。然而,现实世界中的许多任务并非如此简单,它们可能需要模型进行多轮交互、调用外部工具、进行决策甚至自我修正。LangGraph通过引入“图(Graph)”的概念,将这些复杂的交互和决策过程可视化并模块化,从而使得构建复杂的Agent成为可能。简单来说,LangGraph允许定义一个有向图,其中每个“节点(Node)”代表一个操作(例
什么是LangGraph
传统的LLM应用往往是线性的,即用户输入一个问题,模型生成一个回答。然而,现实世界中的许多任务并非如此简单,它们可能需要模型进行多轮交互、调用外部工具、进行决策甚至自我修正。LangGraph通过引入“图(Graph)”的概念,将这些复杂的交互和决策过程可视化并模块化,从而使得构建复杂的Agent成为可能。
简单来说,LangGraph允许定义一个有向图,其中每个“节点(Node)”代表一个操作(例如,调用LLM、执行工具、处理数据),而“边(Edge)”则定义了这些操作之间的流程和条件。这种基于图的结构,使得Agent的行为路径不再是固定的,而是可以根据实时情况动态调整,从而实现更高级的智能和适应性。
LangGraph的核心优势
- 状态管理(State Management):LangGraph内置了强大的状态管理机制,允许Agent在不同节点之间传递和维护信息,从而实现长期的记忆和多轮对话能力。
- 可控的执行流程(Controllable Execution Flow):通过定义节点和边,开发者可以精确控制Agent的执行逻辑,包括条件分支、循环和并行执行等,这对于构建复杂的决策链至关重要。
- 工具集成(Tool Integration):LangGraph能够无缝集成各种外部工具(如搜索引擎、数据库、API等),让Agent能够获取实时信息、执行特定操作,极大地扩展了LLM的能力边界。
- 可观测性与调试(Observability & Debugging):图结构使得Agent的运行路径清晰可见,便于开发者理解Agent的决策过程,并在出现问题时进行快速定位和调试。
- 模块化与可复用性(Modularity & Reusability):每个节点都可以是一个独立的、可复用的组件,这有助于构建可维护性高、易于扩展的Agent系统。
LangGraph核心概念
1. 状态(State)
在LangGraph中,State是Agent在整个执行过程中共享和更新的数据。它通常是一个字典或自定义的TypedDict,包含了Agent当前所需的所有信息,例如用户查询、历史对话、检索到的文档、工具执行结果等。每个节点都可以读取和修改这个共享状态,从而实现信息的传递和记忆。
2. 节点(Nodes)
节点是图中的基本操作单元,每个节点都执行一个特定的任务。一个节点可以是一个LLM调用、一个工具函数、一个数据处理逻辑,甚至是另一个LangGraph子图。节点的设计应该尽可能地原子化和单一职责,以便于管理和复用。
3. 边(Edges)
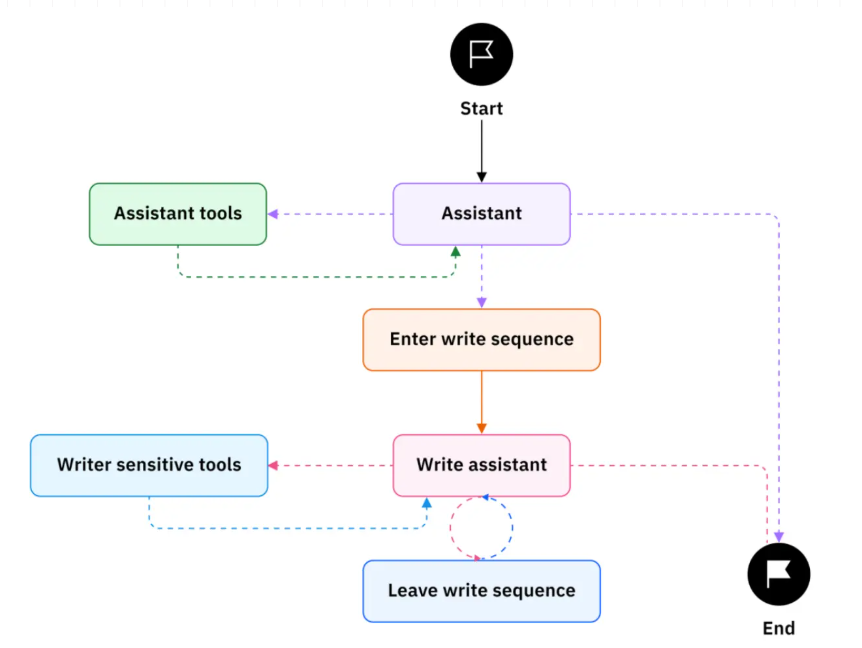
边连接了图中的节点,定义了执行流程的方向。LangGraph支持两种类型的边:
- 普通边(Normal Edges):从一个节点直接连接到另一个节点,表示无条件地从前一个节点跳转到后一个节点。
- 条件边(Conditional Edges):从一个节点连接到多个可能的后续节点,根据某个条件(例如,LLM的输出、工具执行结果)动态选择下一个执行的节点。这是LangGraph实现复杂决策逻辑的关键。
4. 入口点与出口点(Entry Point & End Point)
- 入口点(Entry Point):定义了图的起始执行节点。当Agent开始运行时,它会从入口点开始执行。
- 出口点(End Point):定义了图的结束执行节点。当Agent达到出口点时,表示当前任务完成,图的执行结束。
5. 检查点(Checkpoints)
检查点是LangGraph的一个高级特性,它允许Agent在执行过程中保存当前的状态。这对于实现Agent的记忆功能、支持长时间运行的任务以及从中断中恢复非常有用。通过检查点,Agent可以记住之前的对话历史和执行路径,从而在后续交互中保持上下文连贯性。
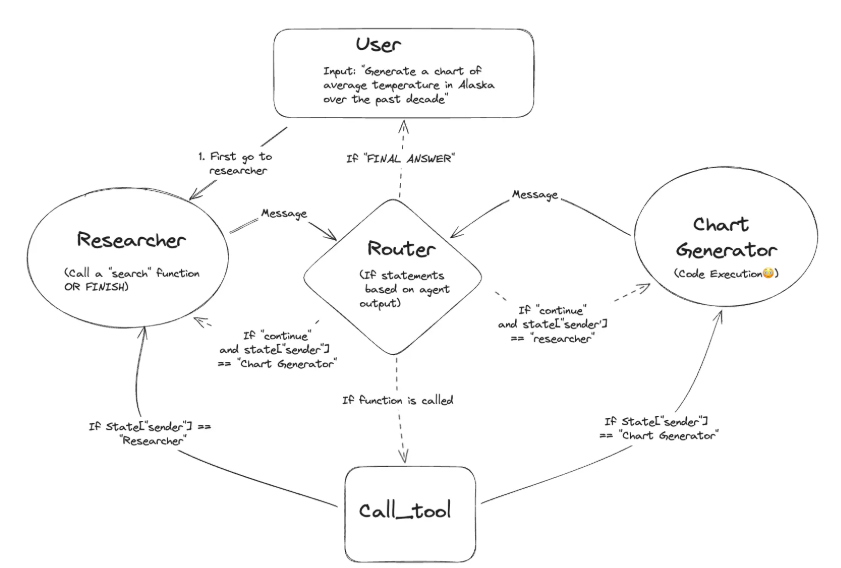
构建智能研究Agent
为了更好地理解LangGraph的实际应用,我们将从零开始构建一个智能研究Agent。这个Agent能够接收用户查询,分解为子任务,执行搜索,并最终生成研究报告。
1. Agent状态定义
我们需要定义Agent的状态,在LangGraph中,状态是Agent在不同节点之间共享和传递的数据。对于研究Agent,它需要跟踪用户查询、生成的子任务、搜索结果以及最终的报告。定义一个ResearchState类来表示这些信息:
from typing import List, Dict, Any, Optional, TypedDict
class ResearchState(TypedDict):
user_query: str
subtasks: List[Dict[str, Any]]
search_results: Dict[str, Any]
report: str
messages: List[Any] # 用于跟踪对话历史
ResearchState包含了以下关键信息:
user_query: 用户的原始查询。subtasks: 规划代理生成的子任务列表,每个子任务包含ID、查询、来源类型、时间范围等。search_results: 存储每个子任务的搜索结果。report: 最终生成的研究报告。messages: 用于跟踪Agent与用户之间的对话历史,这对于多轮交互和调试非常有用。
2. 节点功能实现
接下来实现构成研究Agent工作流的各个节点。每个节点都负责一个特定的任务:
2.1 规划研究节点 (_plan_research_node)
这个节点负责接收用户的原始查询,并将其分解为结构化的子任务。它会利用LLM的能力,根据预设的提示模板,生成包含详细搜索指令(如查询内容、来源类型、时间范围、优先级等)的子任务列表。这一步是“上下文工程”的体现,通过精确的提示和结构化输出要求,确保LLM能够生成高质量、可执行的计划。
# 简化示例代码,实际实现会更复杂,包含LLM调用和JSON解析
def _plan_research_node(self, state: ResearchState) -> ResearchState:
user_query = state["user_query"]
# 调用LLM生成研究计划和子任务
# ...
subtasks = [...] # 假设LLM生成了子任务列表
state["subtasks"] = subtasks
state["messages"].append(HumanMessage(content=user_query))
return state
2.2 执行搜索节点 (_execute_searches_node)
该节点遍历规划阶段生成的每个子任务,并根据子任务的详细信息(如查询、时间范围)调用外部搜索工具(例如DuckDuckGo Search)。搜索结果会被收集并存储在search_results中,以便后续的RAG(检索增强生成)步骤使用。
# 简化示例代码
def _execute_searches_node(self, state: ResearchState) -> ResearchState:
subtasks = state["subtasks"]
search_results = {}
for subtask in subtasks:
query = subtask["query"]
# 调用搜索工具执行搜索
# ...
search_results[subtask["id"]] = {"original_subtask": subtask, "results": "..."}
state["search_results"] = search_results
return state
2.3 构建RAG节点 (_build_rag_node)
此节点负责将搜索结果整合到RAG流程中。它会将检索到的文档进行分块、生成向量嵌入,并构建一个向量存储(如FAISS),以便进行语义相似性搜索。这一步为LLM提供了丰富的、与查询相关的上下文信息,从而提高生成报告的准确性和相关性。
# 简化示例代码
def _build_rag_node(self, state: ResearchState) -> ResearchState:
search_results = state["search_results"]
# 整合搜索结果,分块,生成嵌入,构建向量存储
# ...
# 假设构建了可用于RAG的文档集合
state["documents_for_rag"] = "..."
return state
2.4 生成报告节点 (_generate_report_node)
最后一个节点利用RAG节点提供的上下文信息,结合LLM(如Kimi K2),生成最终的综合研究报告。LLM会根据所有检索到的信息进行总结、提炼和组织,形成一篇结构完整、内容详实的报告
# 简化示例代码
def _generate_report_node(self, state: ResearchState) -> ResearchState:
documents_for_rag = state["documents_for_rag"]
user_query = state["user_query"]
# 调用LLM生成报告,结合RAG文档
# ...
report = "最终的研究报告内容"
state["report"] = report
state["messages"].append(AIMessage(content=report))
return state
3. 构建LangGraph工作流
有了各个节点的功能实现,我们就可以使用StateGraph来构建整个Agent的工作流。我们将定义节点的连接顺序,以及入口点和出口点。
from langgraph.graph import StateGraph, END
from langgraph.checkpoint.memory import MemorySaver
# 假设 ResearchState, _plan_research_node, _execute_searches_node, _build_rag_node, _generate_report_node 已定义
workflow = StateGraph(ResearchState)
# 添加节点
workflow.add_node("plan_research", self._plan_research_node)
workflow.add_node("execute_searches", self._execute_searches_node)
workflow.add_node("build_rag", self._build_rag_node)
workflow.add_node("generate_report", self._generate_report_node)
# 设置入口点
workflow.set_entry_point("plan_research")
# 添加边,定义执行顺序
workflow.add_edge("plan_research", "execute_searches")
workflow.add_edge("execute_searches", "build_rag")
workflow.add_edge("build_rag", "generate_report")
# 设置出口点
workflow.add_edge("generate_report", END)
# 编译工作流,可选地添加检查点以实现记忆功能
memory = MemorySaver()
graph = workflow.compile(checkpointer=memory)
这个工作流清晰地展示了研究Agent的执行流程:从规划研究开始,接着执行搜索,然后构建RAG,最后生成报告。通过MemorySaver,Agent可以在多次调用中保持状态,实现记忆功能。
4. 运行Agent
工作流构建完成并编译,我们就可以像调用普通函数一样调用Agent,并传入用户查询:
from langchain_core.messages import HumanMessage
# 假设 graph 已经编译完成
inputs = {"user_query": "最新的AI医疗技术有哪些?", "messages": []}
# 运行Agent
for state in graph.stream(inputs):
# 可以在这里打印每个节点的状态变化,以便调试和观察
print(state)
# 最终报告将存储在 state["report"] 中
通过以上步骤,我们成功地使用LangGraph构建了一个能够自主规划、执行搜索并生成报告的智能Agent。这个Agent的强大之处在于其模块化的设计和灵活的执行流程,使其能够适应各种复杂的任务需求。
RAG高级使用
作为工具调用RAG
在某些场景下,我们可能不希望RAG流程是Agent工作流中固定的一步,而是希望Agent能够根据实际情况“决定”是否需要进行RAG。这时,我们可以将RAG封装成一个工具,让LLM在需要时调用它。这种模式的优势在于:
- 决策灵活性:Agent可以根据用户问题的类型(例如,是否需要外部知识)智能地选择是否调用RAG工具,避免不必要的检索。
- 模块化:RAG功能被封装成独立的工具,提高了代码的模块化和可复用性。
实现工具调用RAG的关键在于定义一个工具函数,并将其绑定到LLM上,让LLM能够感知并调用这个工具。例如,创建一个retriever_tool和一个off_topic工具,Agent会根据问题是否与特定主题相关来决定调用哪个工具。
from langchain.tools.retriever import create_retriever_tool
from langchain_core.tools import tool
# 假设 retriever 已定义
retriever_tool = create_retriever_tool(
retriever,
"retriever_tool",
"Information related to pricing, hours, or founder of Cafe Lumiere."
)
@tool
def off_topic():
"""For unrelated questions."""
return "Forbidden - do not respond."
# Agent会根据LLM的判断来决定调用 retriever_tool 还是 off_topic
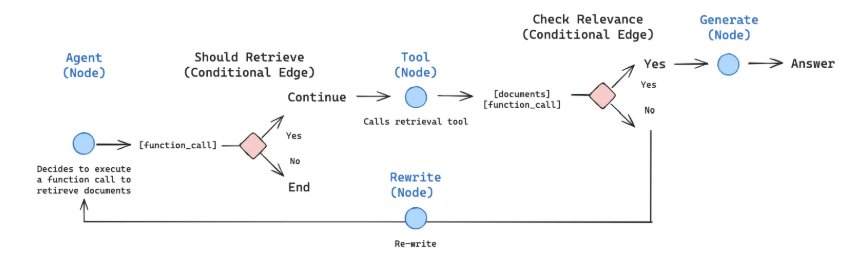
在LangGraph中,通过条件边和ToolNode来实现这种基于工具的决策流程。Agent首先通过LLM判断是否需要工具调用,如果需要,则进入ToolNode执行相应的工具,然后将工具的输出返回给Agent进行下一步处理。
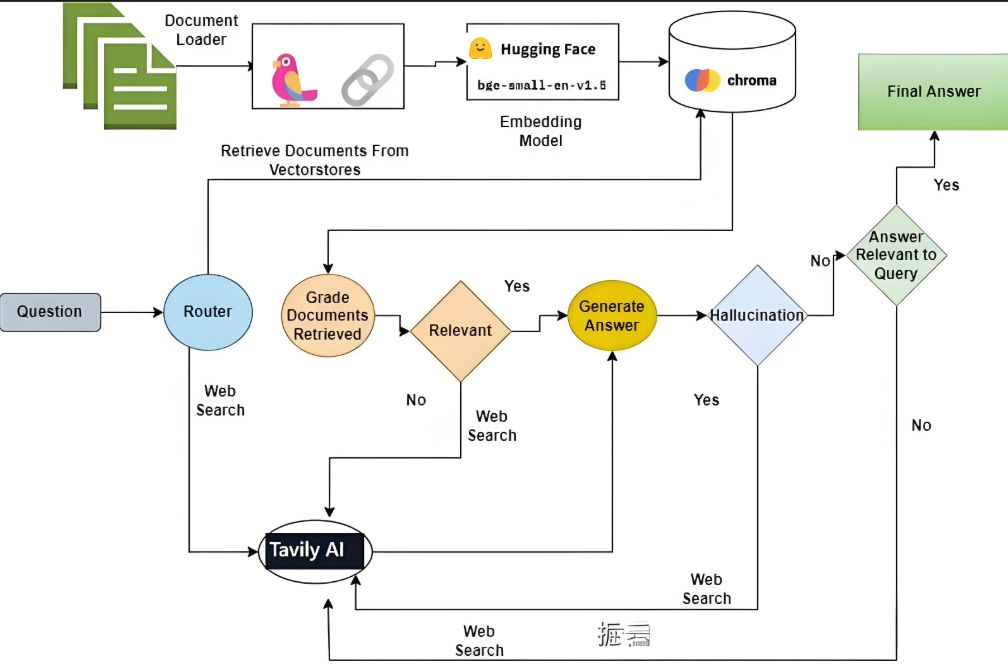
自适应RAG(Adaptive RAG)
自适应RAG是RAG策略的进一步演进,它能够根据查询的复杂性和上下文动态调整检索和生成策略。这意味着Agent不再是简单地执行RAG,而是能够智能地判断:
- 是否需要检索:对于简单问题,直接由LLM回答,无需检索。
- 检索的复杂性:对于复杂问题,可能需要多跳检索或网络搜索。
- 多阶段质量保证:在检索和生成过程中进行多重评估,例如文档相关性评估、幻觉检测和答案质量评估,以确保最终回答的准确性。
构建自适应RAG系统通常涉及以下关键组件:
- 查询路由与分类器:一个训练有素的分类器,用于分析传入查询的复杂性,并决定最佳的知识获取策略(例如,基于索引的检索、网络搜索或无需检索)。
- 动态知识获取策略:根据分类器的判断,系统智能地在不同信息源之间进行路由,例如本地向量数据库或实时网络搜索。
- 多阶段质量保证:在整个流程中嵌入多个评估点,确保检索到的文档相关、生成的答案准确且没有幻觉。
LangGraph的图结构非常适合实现自适应RAG。通过定义不同的节点(如查询分类器、本地检索器、网络搜索器、答案生成器、评估器)和条件边,构建一个高度灵活和智能的工作流,使其能够根据查询的特性动态地调整其行为,从而在各种场景下提供最优的RAG体验。
结语
LangGraph为构建复杂的、具有Agent能力的LLM应用提供了强大的框架。通过其图结构、状态管理、工具集成和灵活的执行流程,开发者可以摆脱传统线性链的限制,构建出能够自主思考、决策和行动的智能Agent。从简单的研究Agent到高级的自适应RAG系统,LangGraph都展现了其卓越的适应性和扩展性。
随着AI技术的不断发展,Agent将成为未来LLM应用的核心。掌握LangGraph,意味着拥有构建下一代智能应用的关键能力,让我们在实践中探索LangGraph的更多可能性,共同推动AI技术的发展。
-
学习资源推荐
如果你想更深入地学习大模型,以下是一些非常有价值的学习资源,这些资源将帮助你从不同角度学习大模型,提升你的实践能力。
一、全套AGI大模型学习路线
AI大模型时代的学习之旅:从基础到前沿,掌握人工智能的核心技能!

因篇幅有限,仅展示部分资料,需要点击文章最下方名片即可前往获取
二、640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示

因篇幅有限,仅展示部分资料,需要点击文章最下方名片即可前往获取
三、AI大模型经典PDF籍
随着人工智能技术的飞速发展,AI大模型已经成为了当今科技领域的一大热点。这些大型预训练模型,如GPT-3、BERT、XLNet等,以其强大的语言理解和生成能力,正在改变我们对人工智能的认识。 那以下这些PDF籍就是非常不错的学习资源。
因篇幅有限,仅展示部分资料,需要点击文章最下方名片即可前往获取
四、AI大模型商业化落地方案

因篇幅有限,仅展示部分资料,需要点击文章最下方名片即可前往获取
作为普通人,入局大模型时代需要持续学习和实践,不断提高自己的技能和认知水平,同时也需要有责任感和伦理意识,为人工智能的健康发展贡献力量。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 9
9 0
0- 0



 已为社区贡献90条内容
已为社区贡献90条内容

所有评论(0)