Transformer实时检测首次全面超越YOLO:百度LW-DETR轻量高效,精度速度双突破
百度团队已经开源了LW-DETR的代码和预训练模型,这将极大促进实时目标检测领域的发展。研究人员和开发者可以在此基础上进一步探索Transformer在实时视觉任务中的应用潜力。LW-DETR的出现标志着实时目标检测领域迎来了一个新时代,Transformer架构不仅在大模型上表现出色,在轻量级实时模型上也同样具有压倒性优势。
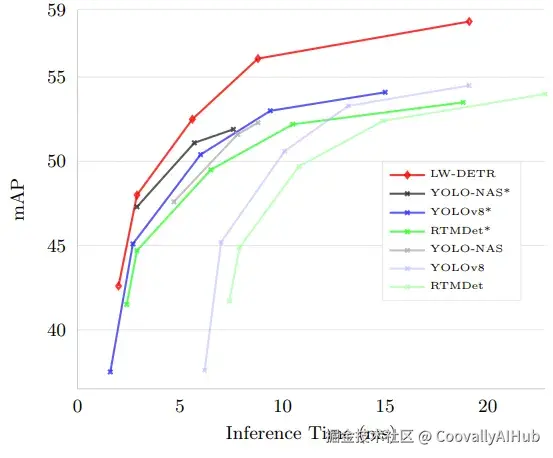
YOLO系列长期统治着实时目标检测,但Transformer能否取而代之一直是悬而未决的问题。百度最新提出的LW-DETR(Light-Weight DETR)给出了答案:它在保持轻量高效的同时,精度全面超越YOLO,速度也实现突破,真正将Transformer带入实时检测新时代。
在目标检测领域,YOLO系列一直被视为实时检测的黄金标准。从YOLOv1到YOLOv10,从YOLOX到YOLO-NAS,卷积神经网络(CNN)架构始终占据着主导地位。
近年来,Transformer架构在检测任务中展现出强大性能,DETR系列模型不断刷新COCO榜单纪录。但一个根本问题始终悬而未决:基于Transformer的检测器能否在实时场景下超越YOLO?
现在,百度研究团队给出了肯定答案!他们提出的LW-DETR(Light-Weight DETR)不仅在精度上全面超越YOLO系列,在速度上也实现了显著提升,成为实时目标检测的新标杆。
架构设计:三大创新打造高效Transformer
LW-DETR的架构设计体现了"简洁而不简单"的哲学思想,通过三大创新实现了计算效率的质的飞跃。
- 多级特征聚合机制

传统ViT编码器通常只使用最后一层的特征,而LW-DETR创新性地聚合了中间层和最终层的特征图,形成了更丰富的特征表示。具体来说:
- 在tiny模型(6层编码器)中,使用第0、2、4层的特征
- 在small/medium/large/xlarge模型(10层编码器)中,使用第2、4、5、9层的特征
- 通过特征融合,获得了0.7mAP的性能提升
这种方法既保留了浅层的细节信息,又融合了深层的语义信息,为检测任务提供了更优质的特征基础。
- 交替注意力机制
LW-DETR采用了窗口注意力和全局注意力交替使用的策略,大幅降低了计算复杂度:
# 6层编码器的注意力模式(W:窗口注意力,G:全局注意力)层数: 0 1 2 3 4 5模式: W G W G W G # tiny模型# 10层编码器的注意力模式层数: 0 1 2 3 4 5 6 7 8 9 模式: W W G W W G W W G W # 其他模型
这种设计将计算复杂度从O(n²)降低到O(n√n),其中n是序列长度。实验表明,这一改变将FLOPs从23.0G降低到16.6G,减少了28%的计算量。
- 窗口优先特征组织
这是LW-DETR在工程实现上的重要创新。传统ViTDet实现使用行优先(row-major)特征组织方式,需要在窗口注意力和全局注意力之间进行昂贵的内存重排操作。
LW-DETR采用窗口优先(window-major)组织方式,彻底避免了这一开销。以一个4×4特征图为例:
行优先组织:

窗口优先组织(2×2窗口)
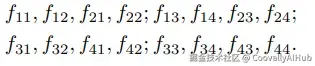
这一优化带来了显著的延迟降低:从3.9ms降至2.9ms,减少了25.6%的推理时间。
训练策略:两大创新加速收敛提升性能
LW-DETR在训练策略上进行了精心设计,通过两大创新技术解决了DETR系列训练收敛慢的问题。
这一优化带来了显著的延迟降低:从3.9ms降至2.9ms,减少了25.6%的推理时间。
训练策略:两大创新加速收敛提升性能
LW-DETR在训练策略上进行了精心设计,通过两大创新技术解决了DETR系列训练收敛慢的问题。

- 两阶段预训练策略
LW-DETR采用了精心设计的两阶段预训练策略:
第一阶段:自监督预训练
- 使用CAEv2(Context Autoencoder v2)方法在Objects365数据集上进行掩码图像建模
- 学习丰富的视觉表示,为下游检测任务奠定基础
第二阶段:有监督预训练
- 在Objects365上以有监督方式训练编码器-解码器结构
- 使模型适应目标检测任务的特点和要求
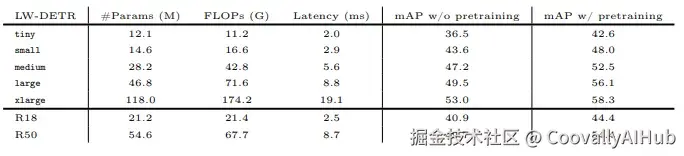
这一预训练策略带来了显著的性能提升,平均提高5.5mAP,其中tiny模型提升6.1mAP,xlarge模型提升5.3mAP。
- Group DETR多组监督
LW-DETR引入了Group DETR训练策略,使用13个并行且权重共享的解码器进行训练:
- 每个解码器从投影器输出特征中生成各自的对象查询
- 推理时仅使用主解码器,不增加计算开销
- 通过一对多匹配提供更丰富的监督信号
这一技术将mAP从35.4提升到38.4,提高了3.0个点,极大地加速了训练收敛过程。
- 损失函数优化
LW-DETR采用了IoU感知的分类损失(IA-BCE损失),其数学表达为:
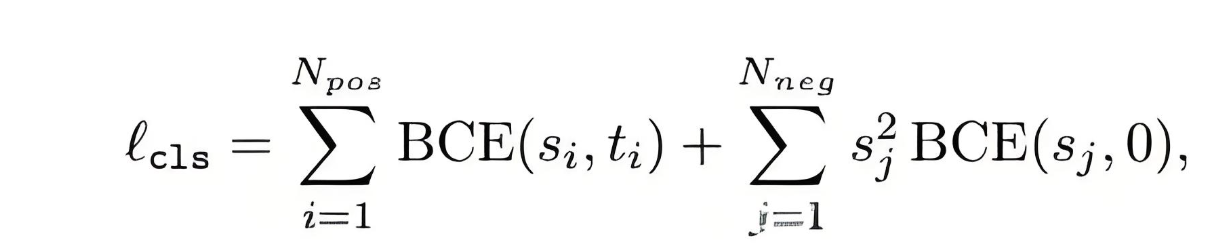
其中目标分数t吸收了IoU信息:t = s^α u^{1-α}(α=0.25),使分类得分与定位质量保持一致。
对于希望复现或进一步探索此类模型的研究者,可以借助如Coovally这样的高效AI开发平台,Coovally不仅提供了丰富的开源数据资源和算法组件,更在开发体验和训练效率上进行了全面优化。 研究者可以在平台上使用自己熟悉的开发工具(如 VS Code、Cursor 等),通过 SSH 协议直连云端算力,享受如同本地一样的实时开发与调试体验,同时调用高性能 GPU 环境,极大地加速了实验迭代与模型训练进程。
实验结果:全面领先的性能表现
LW-DETR在多个数据集和评测基准上展现了令人瞩目的性能优势。
- COCO数据集上的绝对领先
下表展示了LW-DETR与主流实时检测器在COCO val2017上的对比结果:

从结果可以看出,LW-DETR在各个规模模型上都实现了精度和速度的双重优势。
- 跨域泛化能力卓越
LW-DETR在UVO和Roboflow 100等跨域数据集上表现出了卓越的泛化能力:
UVO开放世界检测结果:
- RTMDet-s: 29.7 mAP
- YOLOv8-s: 29.1 mAP
- YOLO-NAS-s: 31.0 mAP
- LW-DETR-small: 32.3 mAP(领先1.3mAP)

Roboflow 100多域检测结果:
LW-DETR在7个不同领域(航空、游戏、显微、水下、文档、电磁、真实世界)上都取得了最优性能,平均mAP达到82.5,显著优于YOLOv8-s(80.1)和RTMDet-s(79.2)。

- 无需NMS的端到端优势
与传统检测器相比,LW-DETR无需NMS后处理,这一优势在小模型上尤为明显:
- YOLOv8n的NMS耗时4.7ms,占总推理时间的76%
- RTMDet-tiny的NMS耗时5.3ms,占总推理时间的72%
- LW-DETR-tiny完全避免NMS开销,实现真正端到端检测
即使对传统方法调优NMS得分阈值,LW-DETR仍保持明显优势,证明了其设计的前瞻性和实用性。
Coovally平台还可以直接查看“实验日志” 。在每一个实验详情页中,用户都可以实时查看训练日志、输出信息或报错内容,无需额外配置、无缝集成于工作流中!
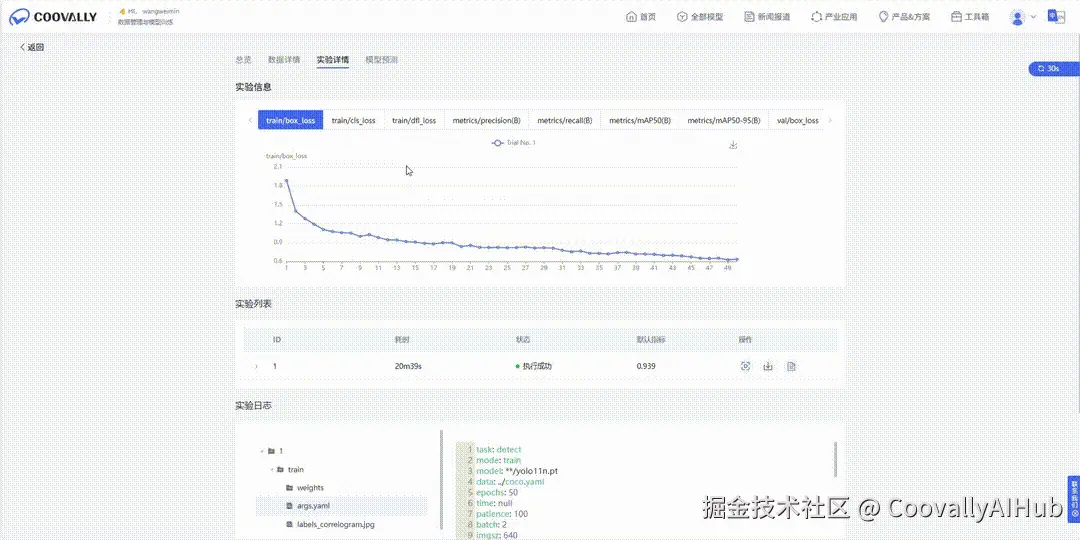
不论是模型调参、错误排查,还是过程复现,这项新功能都将大幅提升你的实验效率。
未来展望:Transformer的时代来临
LW-DETR的成功证明了Transformer架构在实时视觉任务中的巨大潜力。研究人员表示,未来将继续探索:
- 开放世界目标检测应用
- 多人姿态估计任务
- 多视角3D目标检测
- 神经网络架构搜索技术结合
结语:开源贡献,推动行业发展
百度团队已经开源了LW-DETR的代码和预训练模型,这将极大促进实时目标检测领域的发展。研究人员和开发者可以在此基础上进一步探索Transformer在实时视觉任务中的应用潜力。
LW-DETR的出现标志着实时目标检测领域迎来了一个新时代,Transformer架构不仅在大模型上表现出色,在轻量级实时模型上也同样具有压倒性优势。
-
学习资源推荐
如果你想更深入地学习大模型,以下是一些非常有价值的学习资源,这些资源将帮助你从不同角度学习大模型,提升你的实践能力。
一、全套AGI大模型学习路线
AI大模型时代的学习之旅:从基础到前沿,掌握人工智能的核心技能!

因篇幅有限,仅展示部分资料,需要点击文章最下方名片即可前往获取
二、640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示

因篇幅有限,仅展示部分资料,需要点击文章最下方名片即可前往获取
三、AI大模型经典PDF籍
随着人工智能技术的飞速发展,AI大模型已经成为了当今科技领域的一大热点。这些大型预训练模型,如GPT-3、BERT、XLNet等,以其强大的语言理解和生成能力,正在改变我们对人工智能的认识。 那以下这些PDF籍就是非常不错的学习资源。
因篇幅有限,仅展示部分资料,需要点击文章最下方名片即可前往获取
四、AI大模型商业化落地方案

因篇幅有限,仅展示部分资料,需要点击文章最下方名片即可前往获取
作为普通人,入局大模型时代需要持续学习和实践,不断提高自己的技能和认知水平,同时也需要有责任感和伦理意识,为人工智能的健康发展贡献力量。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 13
13 0
0- 0



 已为社区贡献94条内容
已为社区贡献94条内容

所有评论(0)