什么是 RAG?RAG 的主要流程是什么?
是一种结合信息检索和生成式模型的技术方案。即我们在本地到相关的内容,把它到提示词里,然后再去做结果。简单来说就是利用外部知识动态补充模型生成能力,既能保证回答的准确性,又能在知识库更新时及时反映最新信息(还有一点就是部分业务是内部文档,网上没有,因此可以本地提供知识库来增强 AI 的知识)。
RAG(Retrieval Augmented Generation,检索增强生成)是一种结合信息检索和生成式模型的技术方案。其主要流程包括两个核心环节:
- 检索(Retrieval): 基于用户的输入,从外部知识库中检索与查询相关的文本片段,通常使用向量化表示和向量数据库进行语义匹配。
- 生成(Generation): 将用户查询与检索到的内容作为上下文输入给生成模型(如 GPT等),由模型输出最终回答。
即我们在本地检索到相关的内容,把它增强到提示词里,然后再去做结果生成。
简单来说就是利用外部知识动态补充模型生成能力,既能保证回答的准确性,又能在知识库更新时及时反映最新信息(还有一点就是部分业务是内部文档,网上没有,因此可以本地提供知识库来增强 AI 的知识)。
扩展知识
为什么会有 RAG ?
因为,随着自然语言处理技术的发展,纯生成模型虽然可以生成流畅的文本,但有时知识会滞后或不够精准。
通过引入检索模块,RAG 模型能够从外部知识库中提取实时且丰富的信息,再经过生成模型综合处理,提升回答的准确率和覆盖面,而无需重新训练模型。
RAG 的详细工作流程
可以看下这个流程图:
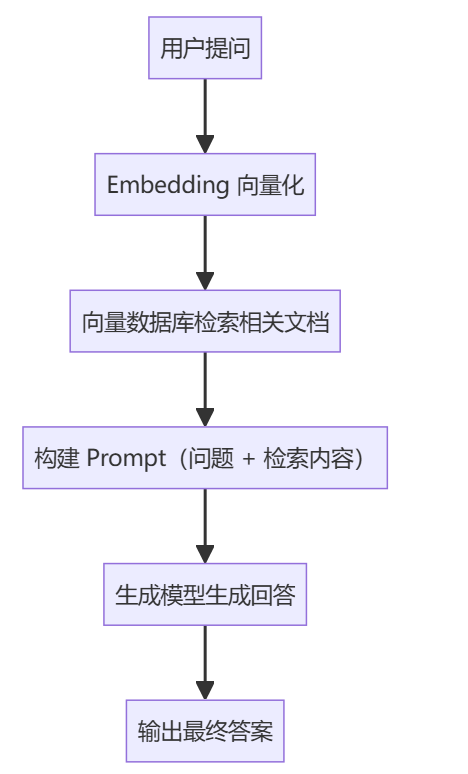
用户提问
Embedding 向量化
向量数据库检索相关文档
构建 Prompt(问题 + 检索内容)
生成模型生成回答
输出最终答案
1、文本向量化(Embedding)
使用语义模型(如 OpenAI 的 text-embedding-ada-002,或者 Sentence-BERT 等)将文档和问题转为高维向量表示。
2、向量数据库检索
使用如 Faiss、Milvus等向量数据库存储所有文档向量。
用户提问后,对问题进行向量化,并在数据库中执行最近邻搜索,找出语义最相近的 N 条内容。
3、构建 Prompt 将用户原始问题和检索到的内容拼接成上下文输入,传入生成模型。
4、生成回答
由大语言模型(如 GPT、LLaMA 等)综合已有上下文生成最终输出。
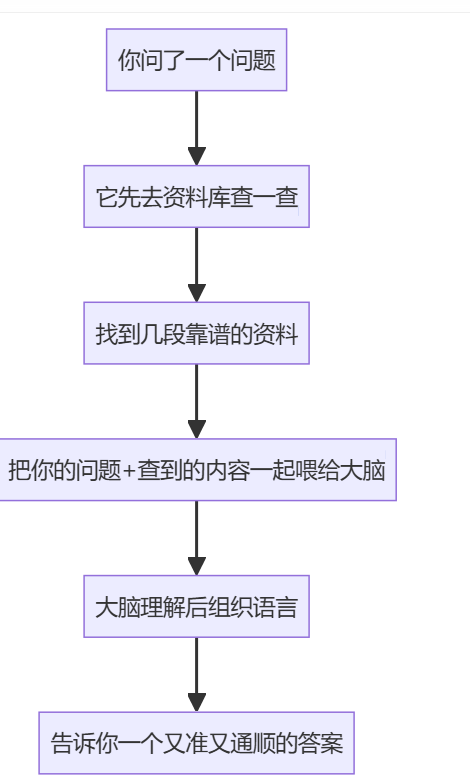
通俗理解
我们可以把 RAG 想象成是一个“聪明的问答助手”,它不仅会说话(生成能力),还会查资料(检索能力),就像你去问一个特别靠谱的朋友:
你问了一个问题
它先去资料库查一查
找到几段靠谱的资料
把你的问题+查到的内容一起喂给大脑
大脑理解后组织语言
告诉你一个又准又通顺的答案

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐



 5
5 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)