【Agent】Chain-of-Agents: End-to-End Agent Foundation Models via Multi-Agent Distillation and Agentic
对多工具多场景下使用一个Agent模型去解决当前需要多Agent解决的问题进行探索。分别在Web Agent场景和Code Agent场景下进行了尝试,通过使用MAS来生成采样轨迹,将数据轨迹转化为设计的标签进行包裹,之后分别使用SFT和DAPO进行训练,构建成一个端到端的Agent模型。实验结果发现,整体性能均优于现有方法。
论文:Chain-of-Agents: End-to-End Agent Foundation Models via Multi-Agent Distillation and Agentic
代码:https://github.com/OPPO-PersonalAI/Agent_Foundation_Models
Project: Agent Foundation Model
简介:对多工具多场景下使用一个Agent模型去解决当前需要多Agent解决的问题进行探索。分别在Web Agent场景和Code Agent场景下进行了尝试,通过使用MAS来生成采样轨迹,将数据轨迹转化为设计的标签进行包裹,之后分别使用SFT和DAPO进行训练,构建成一个端到端的Agent模型。实验结果发现,整体性能均优于现有方法。其中,还发现在只有Code Agent场景下(只有代码数据)训练过的模型,也具备Web Agent场景下的能力,表现出了通过训练Code场景下工具调用的轨迹数据,在其他场景下也具备良好的泛化能力。反之,在只有Web Agent场景下(只有Web Search数据)训练过的模型,在Code场景下会出现一些格式出错的方面的问题,泛化性能不好。
训练设计
数据生产
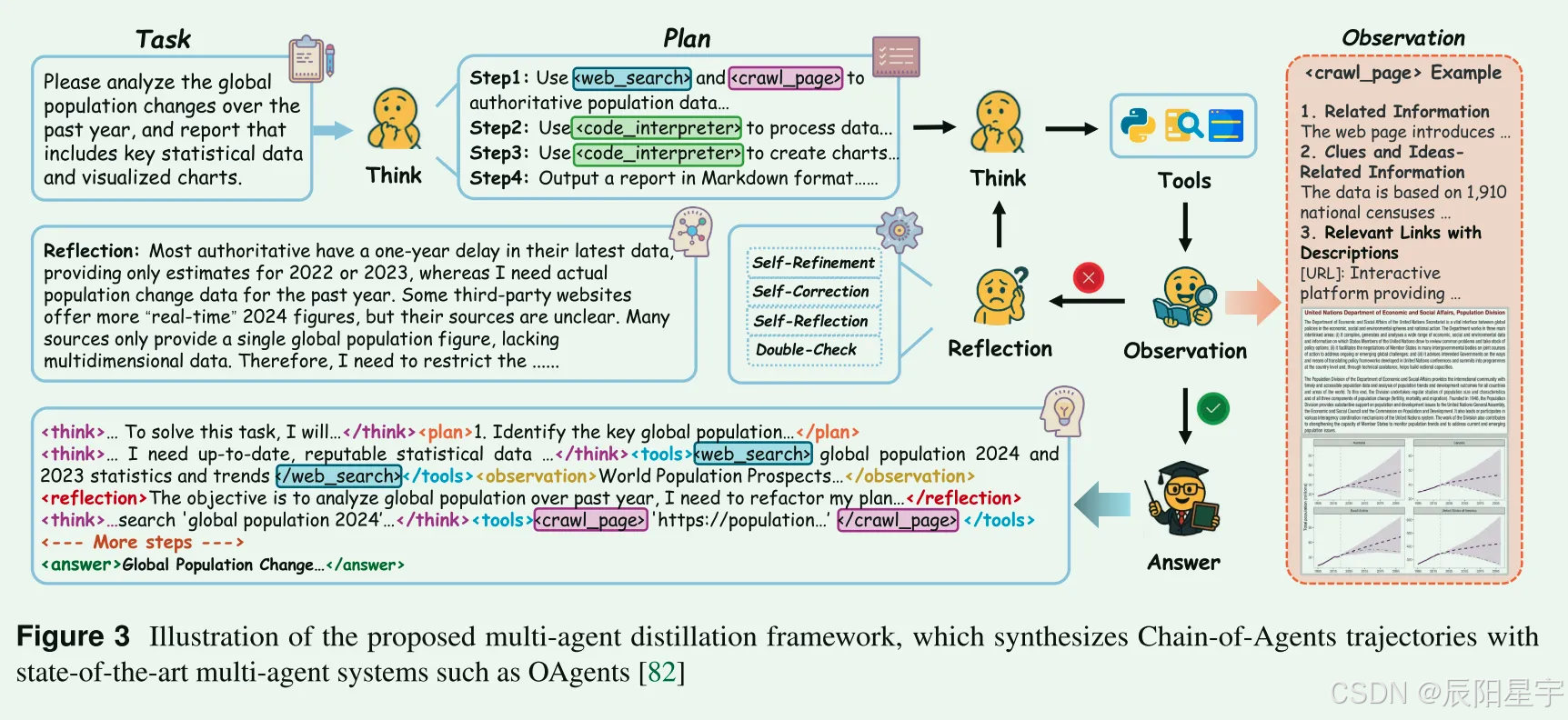
SFT数据筛选
- 数据过滤标准
- 复杂度过滤:排除工具交互总数小于5的轨迹,消除简单任务。
- 质量过滤:删除“脏数据”,包括不正确答案的,冗余工具输入,未能严格遵循说明的实例。
- QA / 搜索任务:采用大模型评估正确性。
- 代码任务:实例执行是否通过测试用例。
- 数学任务:比较生成的答案和预定义的正确答案。
- 丰富反思:缺乏反思轨迹的数据被拒采样,优先考虑有反思的推理轨迹。对于数学和代码任务,没有拒采样没有反思的轨迹。
- 错误轨迹上采样:对于搜索或QA任务,通过GRM可信度指标评估<double_check> Agent最初产生低可信度分数,但最终通过迭代所产生新的推理获取正确答案的轨迹被上采样。优先考虑能够识别并且纠错正确的样本,来对增强数据集的鲁棒性纠错能力。
- 生成语料库的三个关键特征
- 所有的轨迹都需要多工具协作协调,体现复杂的功能相互依赖,需要先进的计划和执行能力
- 推理轨迹5-20跳,远超标准的2-3跳
- 丰富了高质量的反射轨迹,尤其是迭代误差校正轨迹
- SFT训练格式
- C_{cot}</think><tools>a_m(a_p)</tools><observation>O_t</observation><reflection>F_t</reflection>…<answer>A_t</answer>
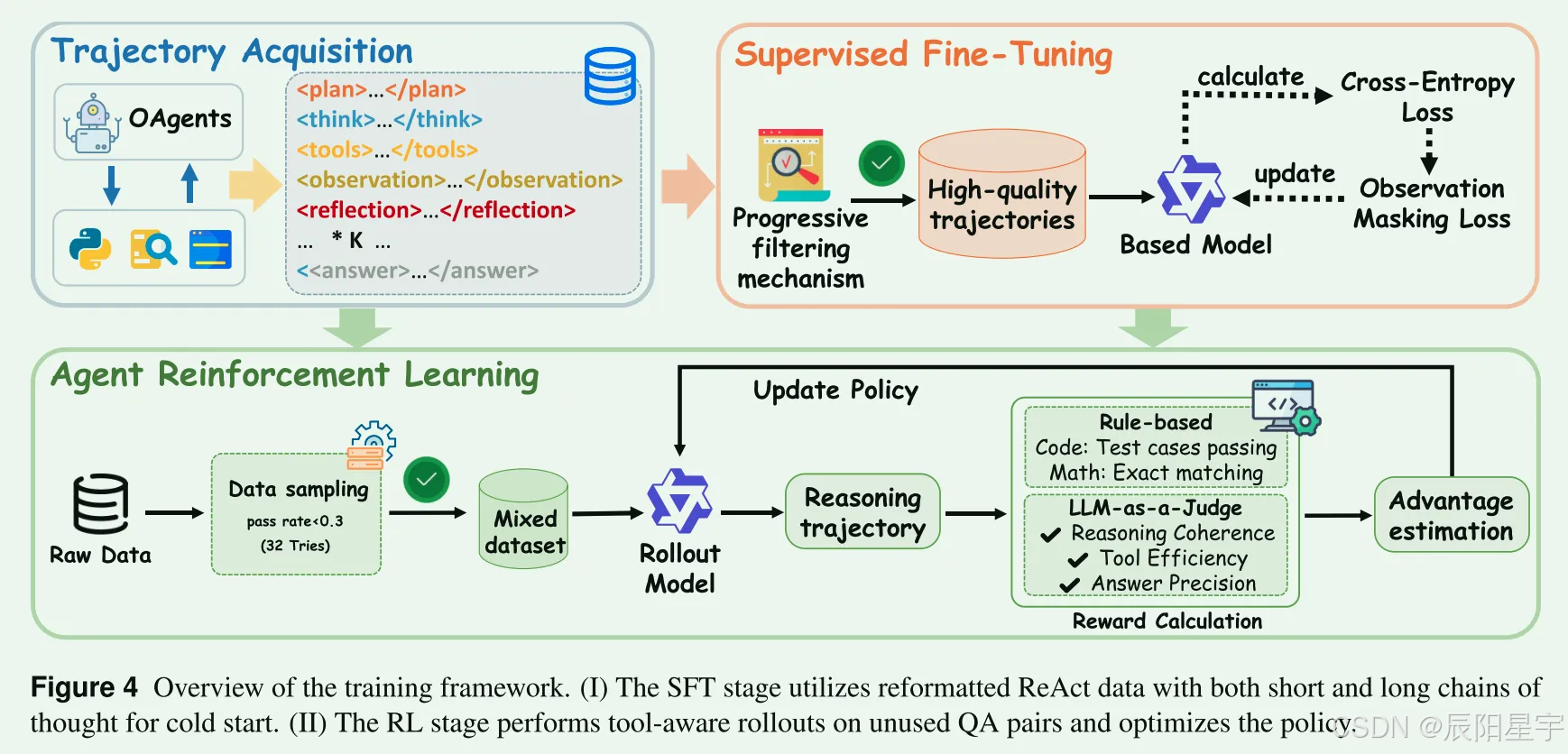
RL数据筛选
- Web Agent数据质量过滤
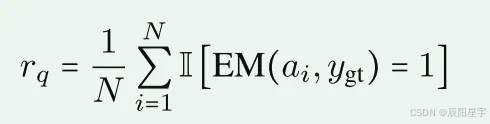
N=32,a_i:第i次预测,y_gt:真实值。EM(·):计算两个输入之间的精确匹配分数。将r_q>0.3的查询排除在外,这类查询:1)不需要使用工具即可解决简单的案例。2)易受参数找回影响污染的样本。阈值确保真正的工具参与。
- 采样策略
采用随机选择策略从剩余的具有挑战性的查询(rq≤0.3)中抽样,这些查询最终用于强化学习训练。从SFT数据集中排除的采样子集形成最终的RL数据集,保证两个阶段的数据之间不重叠。 - Code Agent数据质量过滤
使用了一个经过微调的7B AFM模型对每个查询进行8次采样。在所有8次试验中都正确解决的任何查询都被认为没有足够的挑战性的被丢弃。
奖励函数设计
针对RL阶段的奖励函数设计 - Web Agent奖励函数:
- 大模型打分,打出0或者1。传统的F1, ME作者认为不能很好的捕获内在语义特征。
- Code Agent奖励函数:
- 答案正确性×格式正确性,分值选取都是0或者1。采用Math-Verify对答案进行评估。
训练及评测
Web Agent
-
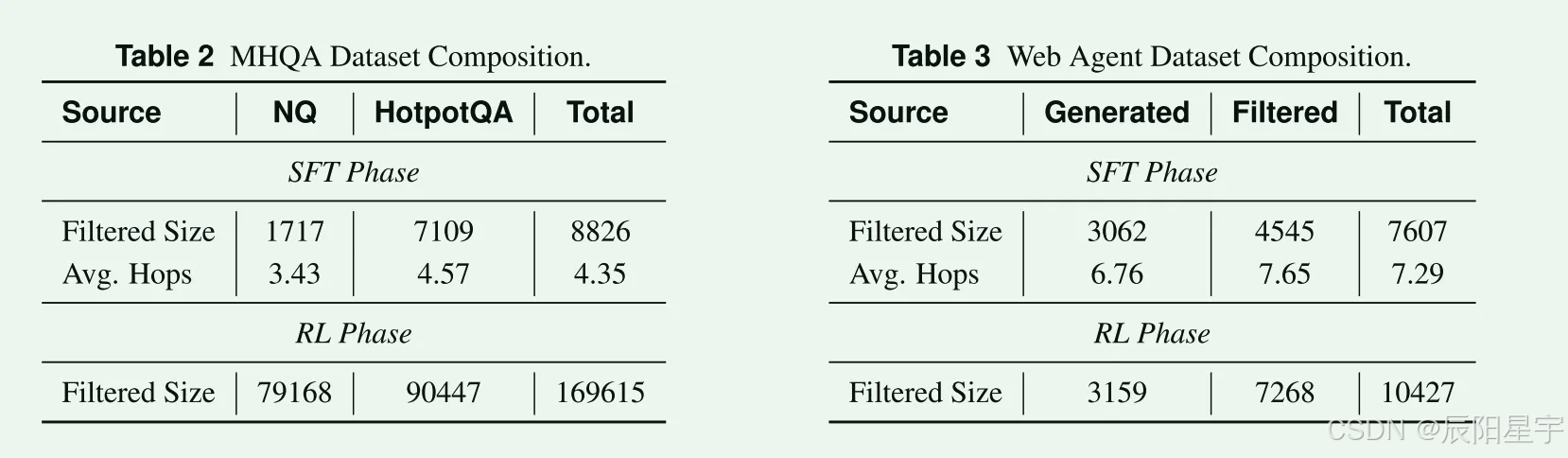
训练数据
SFT16433条(MHQA: 8826, WebAgent: 7607)、RL 180042(MHQA: 169615, WebAgent: 10427)- SFT:数据集采用NQ和HotpotQA数据集中抽取一组QA
- RL:采用与Search-R1相同的数据集设置,使用完整的NQ和HotpotQA数据集
- 数据扩展:1)基于深度扩展:构建需要连续执行工具的多步骤任务;2)基于宽度的扩展:生成分解为并行子任务,每个任务都需要独立的工具共同解决原始问题。
-
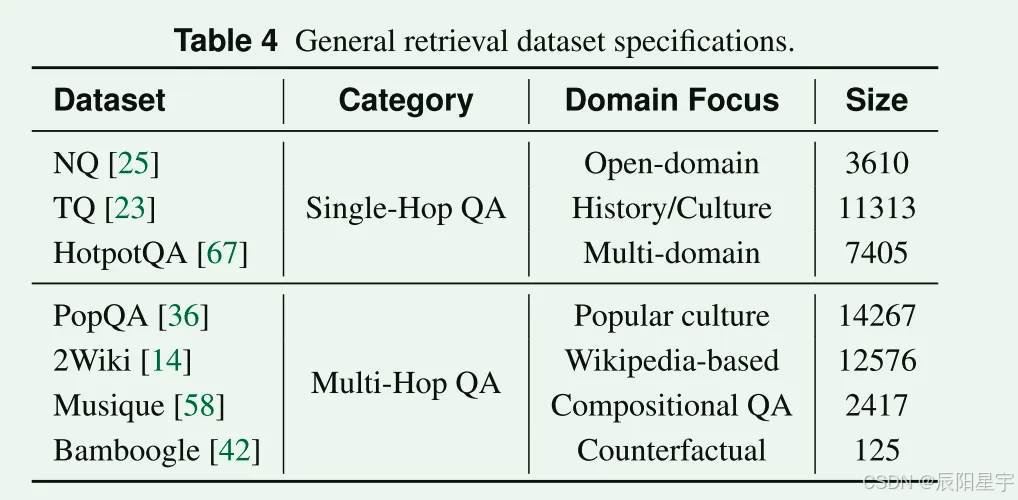
评估数据
- 单跳:NQ + TQ + HotpotQA: 22328
- 多跳:TriviaQA + 2Wiki + MuSiQue + Bamboogle + PopQA:29385
- 复杂信息检索能力:GAIA(103纯文本) 、BrowseComp、HLE
-
评估指标
大模型打分,判断是否正确。 -
训练细节
- 模型:Qwen-2.5-3B-Instruct, 7B-Instruct, 32B-Instruct
- 模型参数:token length: 32768, temperature=1.0, top-p=0.9, top-k=20
- SFT: bach_size=256, epochs=2.5, learning rate=1.4e-5, AdamW
- RL: DAPO, rollouts_n=8, bach_size=64, max_steps=24, max_tokens=32k
-
效果评测
- 结果
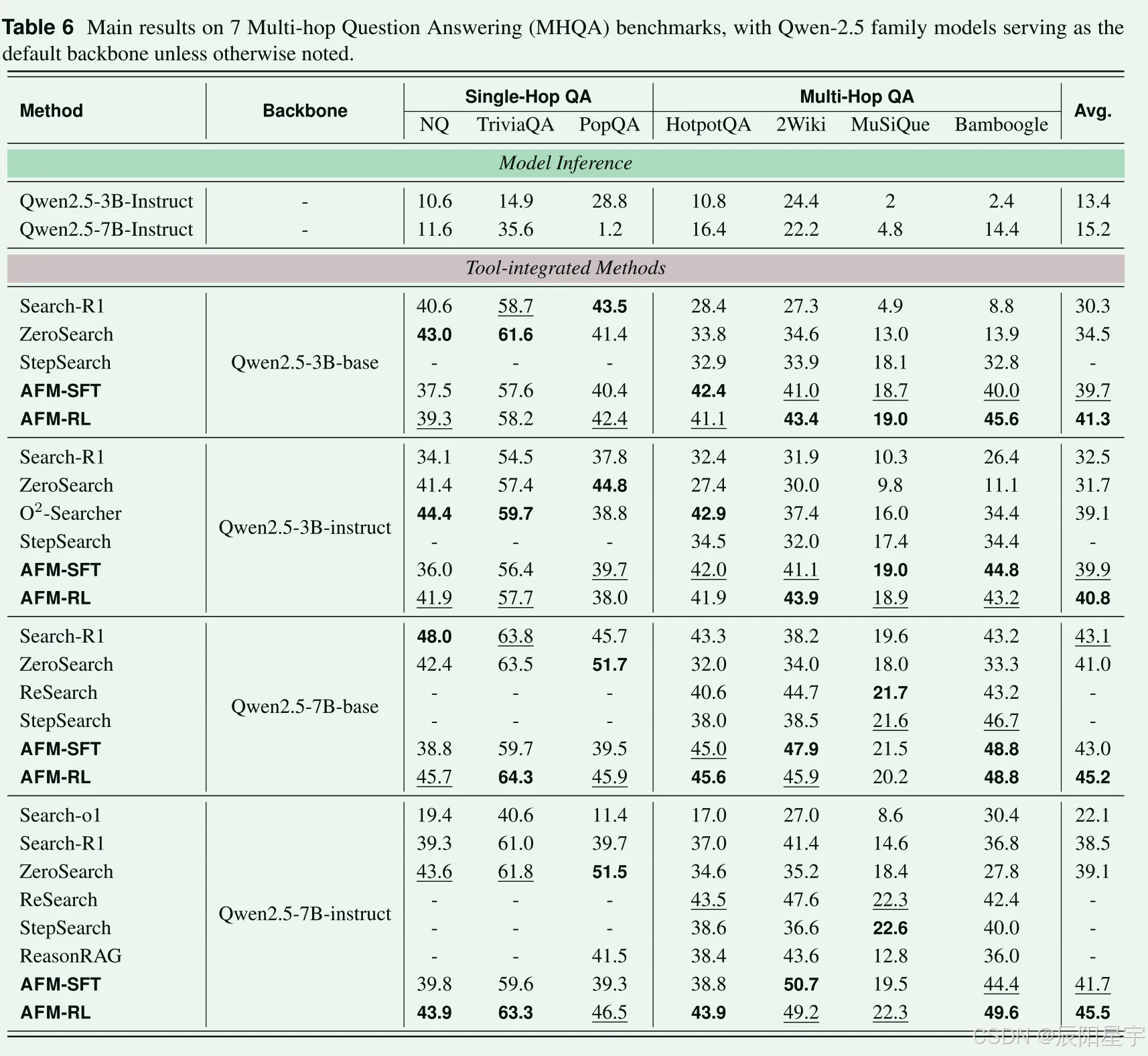
- 结果
在单挑任务上效果表现不佳,考虑是由于数据中简单的单挑轨迹数据被删除的原因,让模型过拟合了更多的多跳任务解决能力。在多跳任务上,更大的模型收益会更大。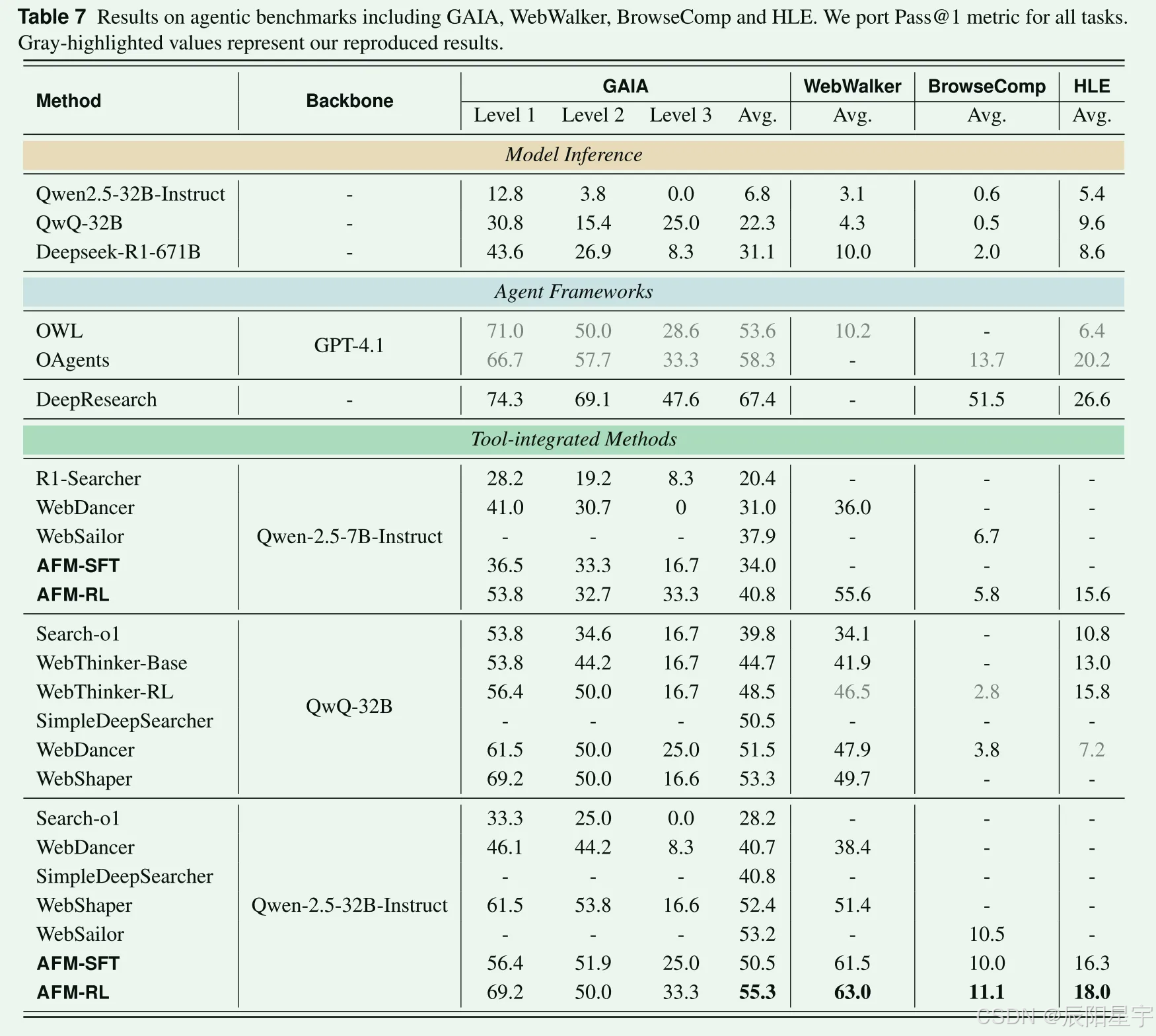
- 性能
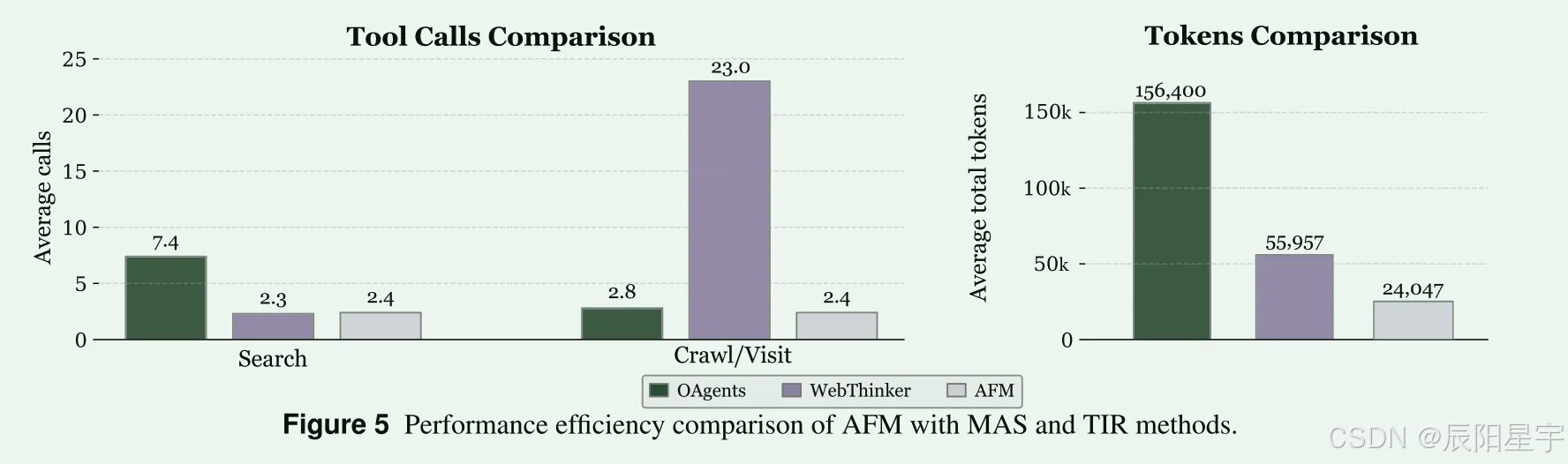
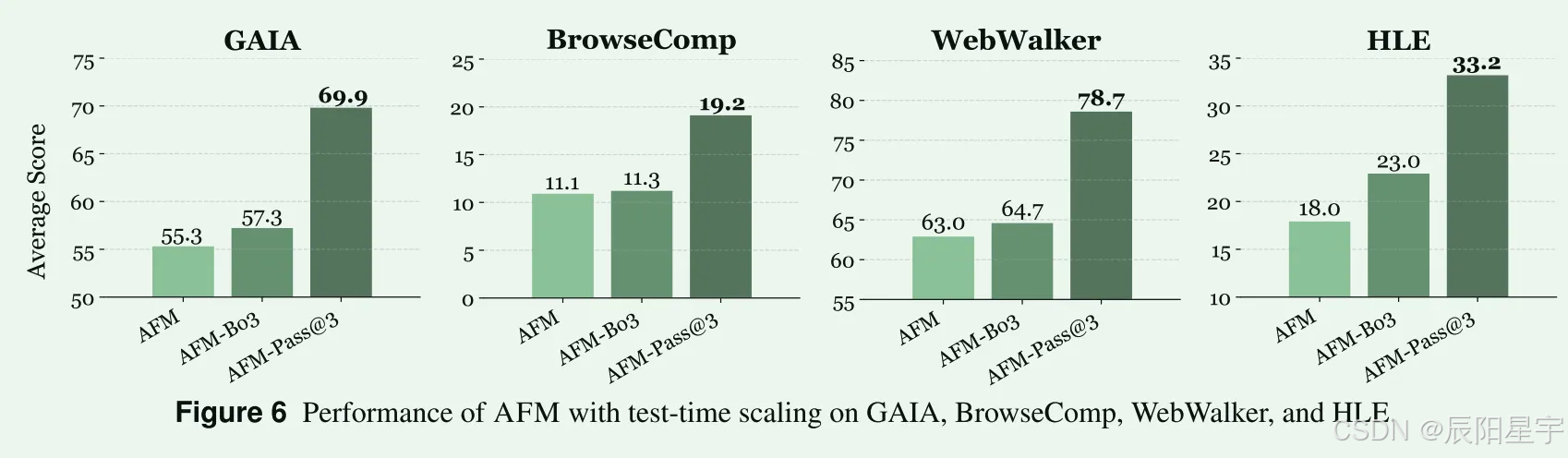
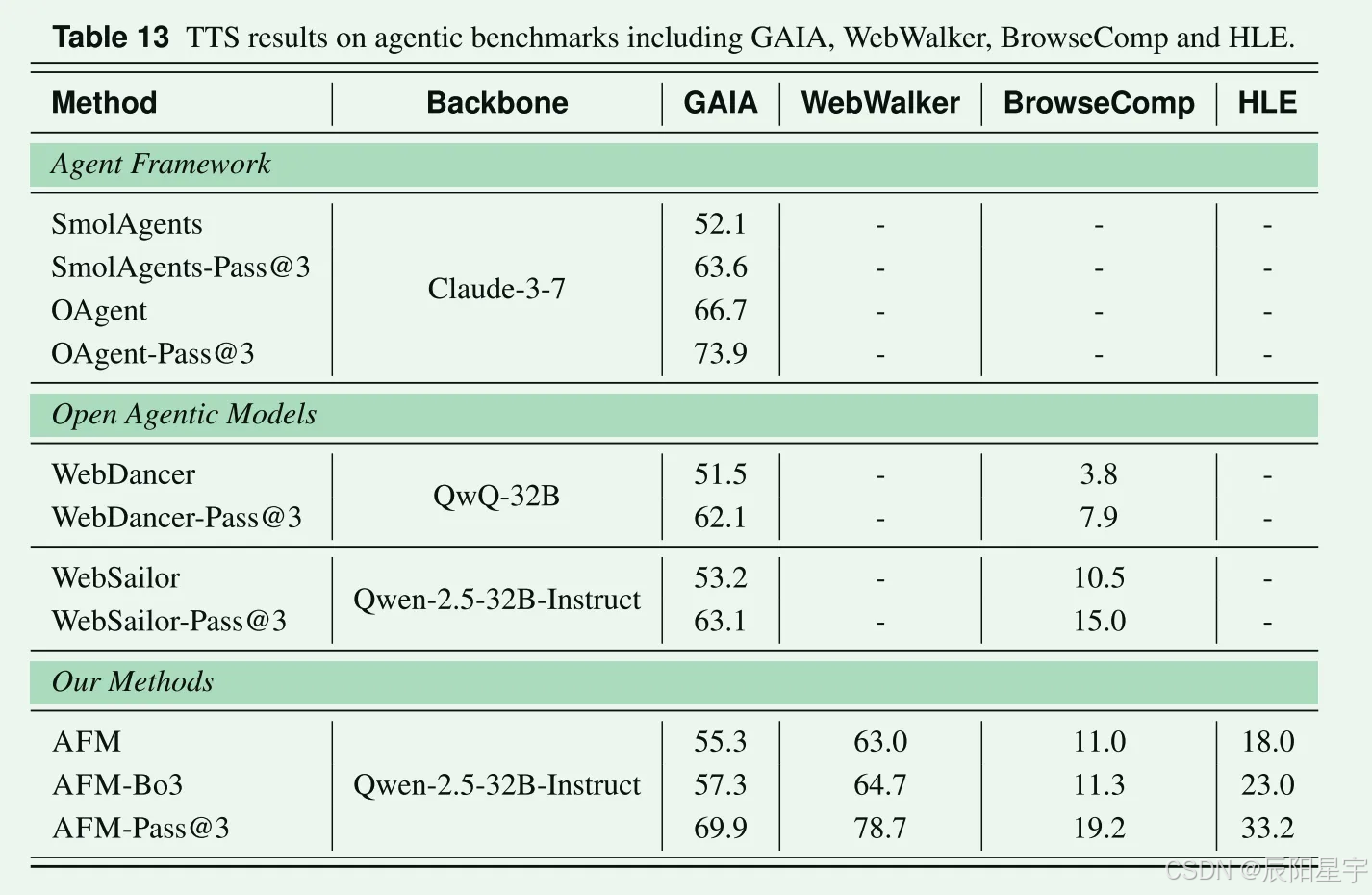
在GAIA数据集上随机采用10个实例进行评测,发现AFM以更少的工具调用次数,更少的token开销完成任务。
Code Agent
-
训练数据
- 由数学和代码类型的数据组成(特点:每个代码问题平均携带大于50个测试用例,证明类数学题被丢弃,具有普通到竞赛难度的多样化的题)
- 纯代码任务:LiveCodeBench v1-v3, CodeForces
- 纯数学任务:Retool-SFT, DAPO-Math
- 混合代码和数学任务:Skywork-OR1-RL-Data
- SFT:使用LiveCodeBench v1-v3, Retool-SFT, Skywork-RL-Data的完成拆分和CodeForces的可验证提示拆分,共保留47k个推理轨迹。
- RL:使用LiveCodeBench v1-v3, Skywork-OR1-RL-Data和DAPO-Math。Skywork-OR1-RL-Data包含超过100万个数学问题,远超代码生成数据集的大小,因此只选取了35k个数学问题数据集Skywork-OR1-RL-Data。然后,再进行质量过滤。这里面不会将SFT重叠数据删除,在RL期间依靠DAPO算法的隐式基于难度的过滤来防止对已经掌握的任务进行过度训练。
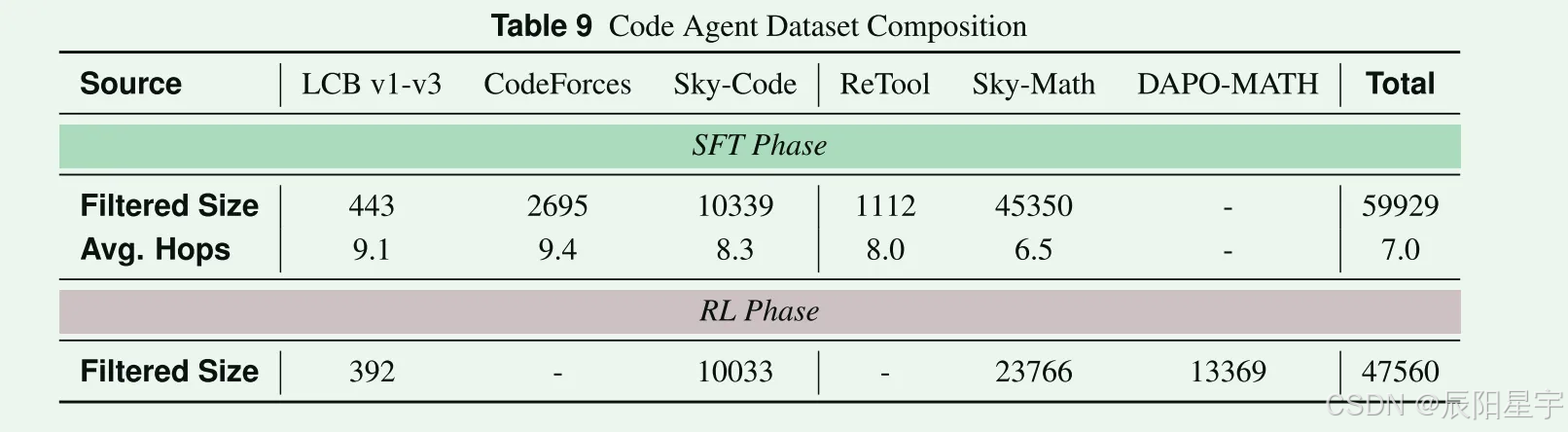
- 由数学和代码类型的数据组成(特点:每个代码问题平均携带大于50个测试用例,证明类数学题被丢弃,具有普通到竞赛难度的多样化的题)
-
评估数据
- 竞赛题:AIME24和AIME25
- MATH500:从OpenAI的PRM800K语料库中抽取500个问题,跨越广泛的数学领域和难度层。
- ACM23:中等难度非常规高中竞赛题。
- OlympiadBench:顶级高中数学和物理奥林匹克竞赛题,保留英文纯文本数学子集。
- LiveCodeBench:专门用于评估编码能力。
- CodeContents:在线公开竞赛,难度从初级到高级。
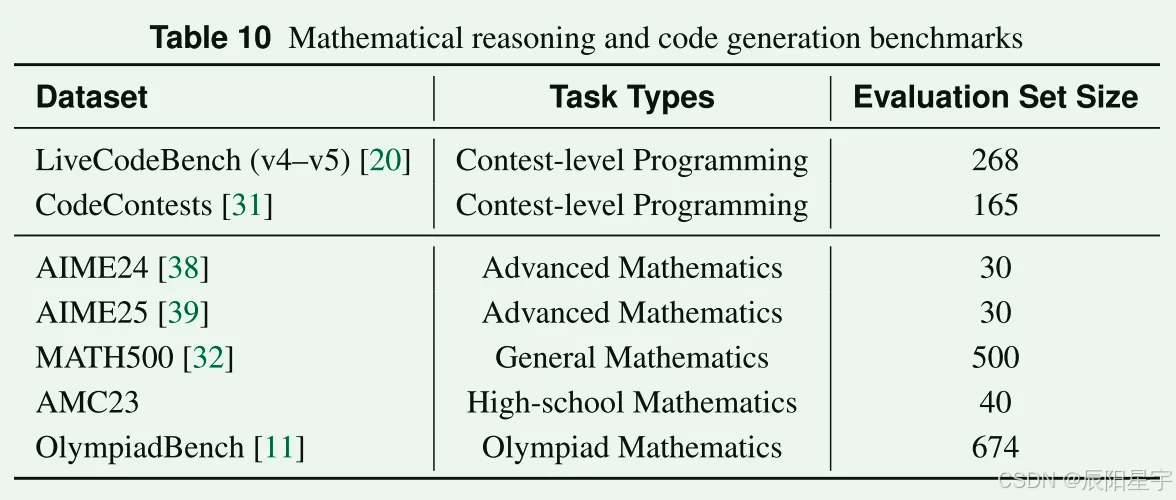
-
评估指标
代码任务,判断pass@1。数学任务,采用Math-Verify判断是否正确。
其中,由于AMC23、AIME24和AIME25样本量优先,pass@1表现出的方差高。为了减弱随机性,采用16个独立性样本的pass@1的平均值作为数据集指标。 -
训练细节
- 模型:Qwen2.5-Coder-7B-Instruct, Qwen-2.5-Coder-32B-Instruct
- SFT:epochs=2, bach_size_7B=32, bach_size_32B=64, AdamW, learning_rate=1.4e-5, warmup_rate=0.1, 余弦衰减。
- RL:DAPO, rollouts_n=8, overlong_Buffer=1/8, max_tools_call=8, bach_size=256, min_bach_size=32, max_tokens_7B=32k。max_tokens_32B_early_40_steps=16K, max_tokens_32B_last_40_steps=32K, global_steps_7B=150, global_steps_32B=120, warmup_steps=10。
-
效果评测
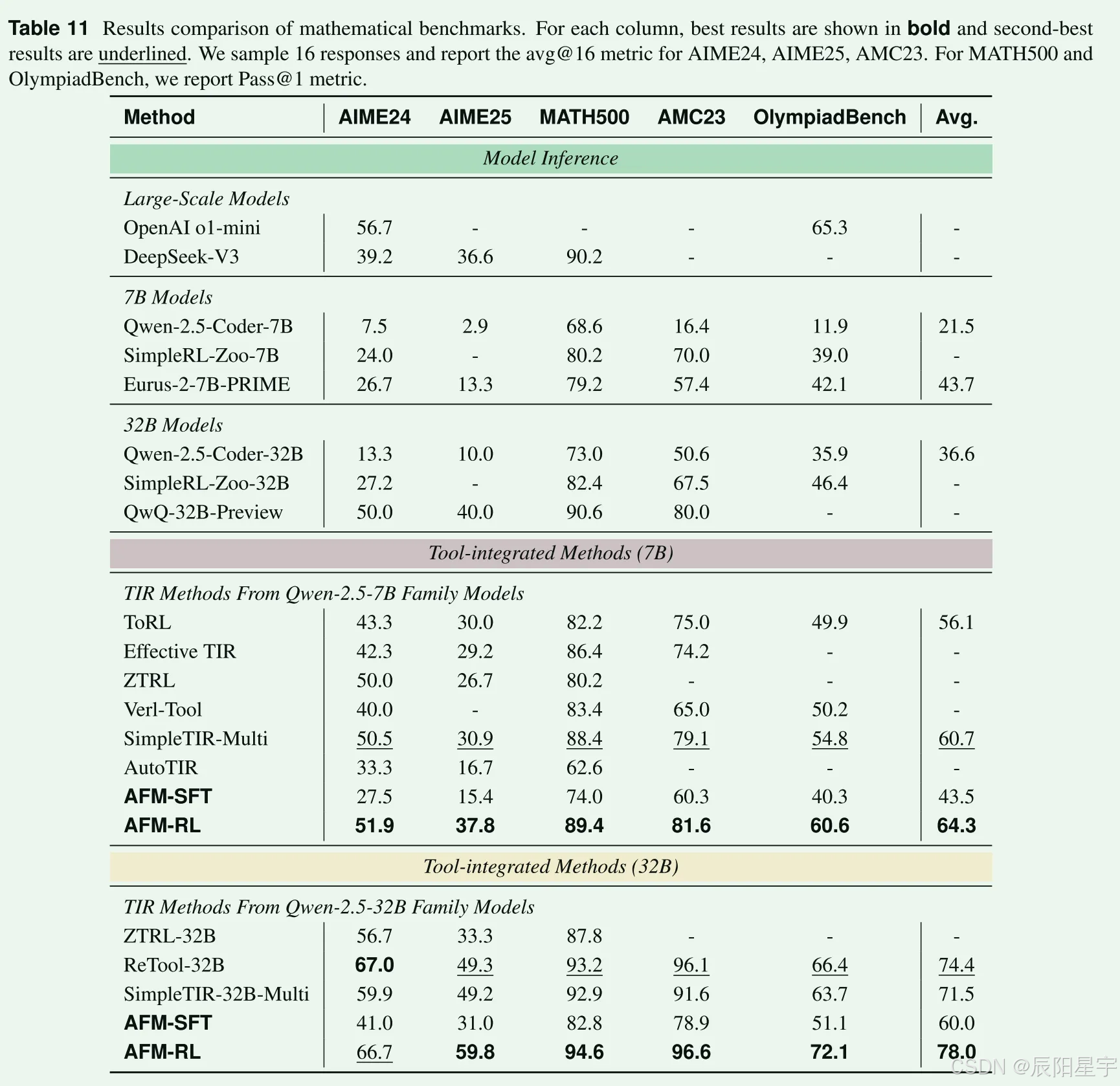
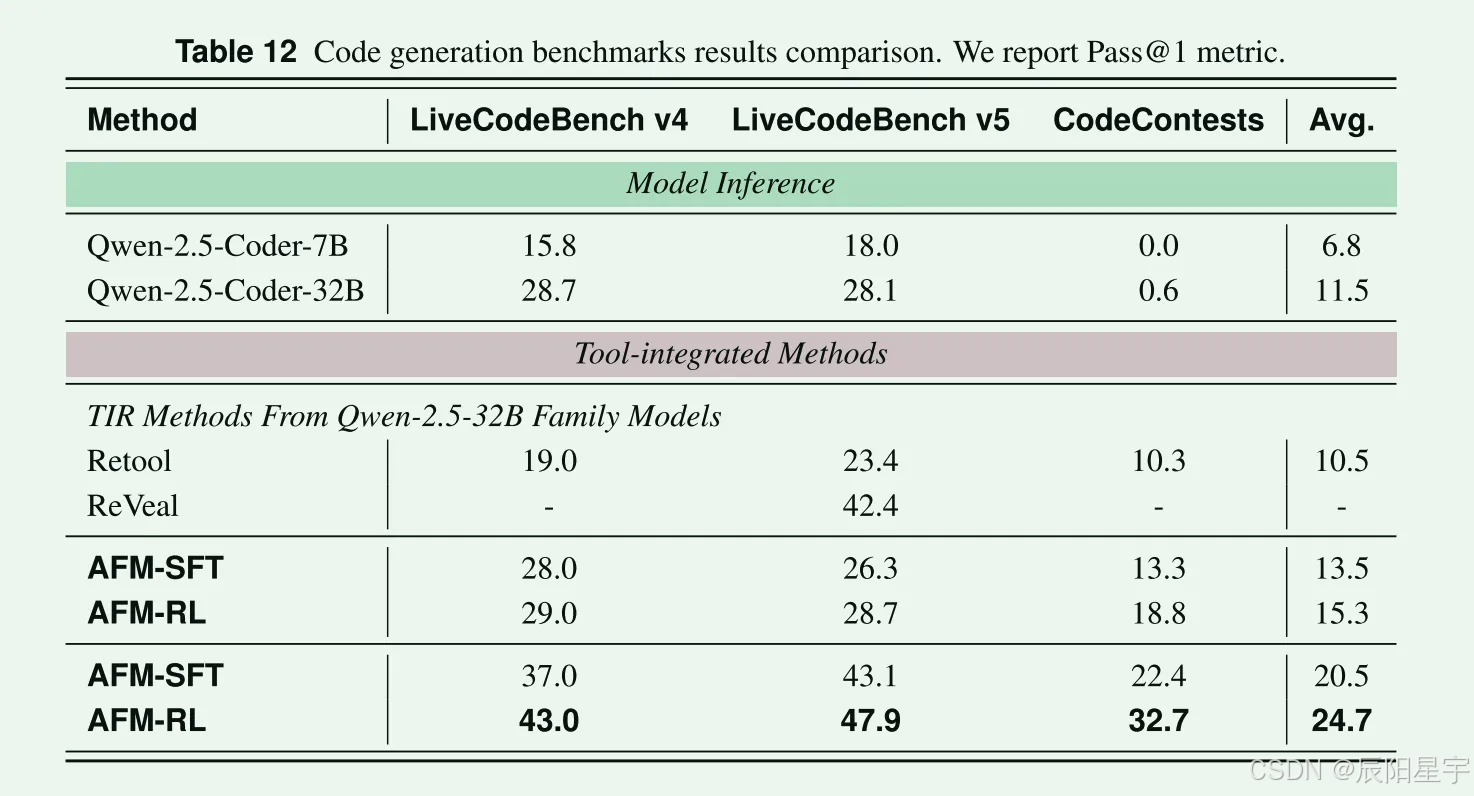
AFM-7B: temperature=0.8, max_tokens=32k, top=p=1.0, max_tools_call=12
AFM-32B: temperature=0.6, max_tokens=32k, top=p=1.0, max_tools_call=12
泛化能力
- Code Agent模型:在GAIA数据集进行了评测,发现Code Agent模型在只有Python代码任务和数学任务数据集训练的情况下,可以严格遵循未见过工具描述要求,并且在工具选择时正确先选择了训练集中未出现过的工具。
- Web Agent模型:以相同的测试,Web Agent仅能在适当的情况调用未见过的工具(例如,Python执行器),但是在遵循格式要求时候(例如:JSON字符串中包含完整字段)却出现错误,不能正确生成内容被解析。
- 进一步发现:对于报告生成等传统任务,模型都可以表现出很高的泛化性,但是对于工具使用要求字符级的精度的时候,Web Agent模型性能显著下降。相比之下,严格的代码格式约束情况下训练的Code Agent模型依然保持很强的鲁棒性。
Test-Time Scaling

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 24
24 0
0- 0



 已为社区贡献19条内容
已为社区贡献19条内容

所有评论(0)