IJCAI2025 | FreEformer:频域建模 + 增强注意力,多变量时序预测18个数据集碾压 SOTA!
来自IJCAI2025,最新前沿时序技术,针对多变量时间序列预测,提出了FreEformer模型,利用频域全局特性和增强注意力机制,实现更鲁棒的多变量时间序列预测。
本篇论文来自IJCAI2025,最新前沿时序技术,针对多变量时间序列预测,提出了FreEformer模型,利用频域全局特性和增强注意力机制,实现更鲁棒的多变量时间序列预测。
了解顶会最新技术,紧跟科研潮流,研究与写作才能保持在时代一线,全部49篇IJCAI2025前沿时序合集小时已经整理好了,在功🀄浩“时序大模型”发送“资料”扫码回复“IJCAI2025时序合集”即可自取~其他顶会时序合集也可以回复相关顶会名称自取哈~(AAAI25,ICLR25,ICML25等)
文章信息
论文名称:FreEformer: Frequency Enhanced Transformer for Multivariate Time Series Forecasting
论文作者:Wenzhen Yue、Yong Liu、Xianghua Ying、Bowei Xing、Ruohao Guo、Ji Shi

研究背景
多变量时间序列预测在天气、能源、交通、金融等实际领域意义重大。近年来,RNN、CNN、Transformer 等深度学习模型虽展现出潜力,但仍存在不足:
-
时域模型局限:传统时域 Transformer 类模型(如 Autoformer、Informer)难以捕捉全局频率特征,且普通注意力机制因频率域稀疏性和 Softmax 函数的强值聚焦特性,易导致注意力矩阵低秩,限制表征多样性。
-
频域模型缺陷:现有频域模型多依赖线性层学习频域表征,性能存在差距;部分频域 Transformer 模型(如 Fredformer)采用分块技术,引入额外超参数且破坏频域建模的全局视角。
为处理上述问题,文章提出了FreEformer模型,能利用频域全局特性和增强注意力机制,实现更鲁棒的多变量时间序列预测。
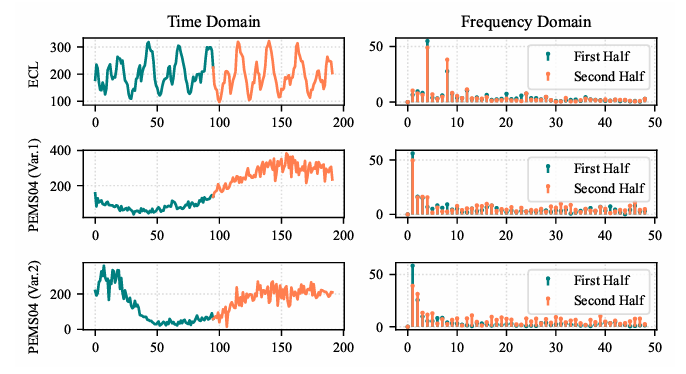
模型框架
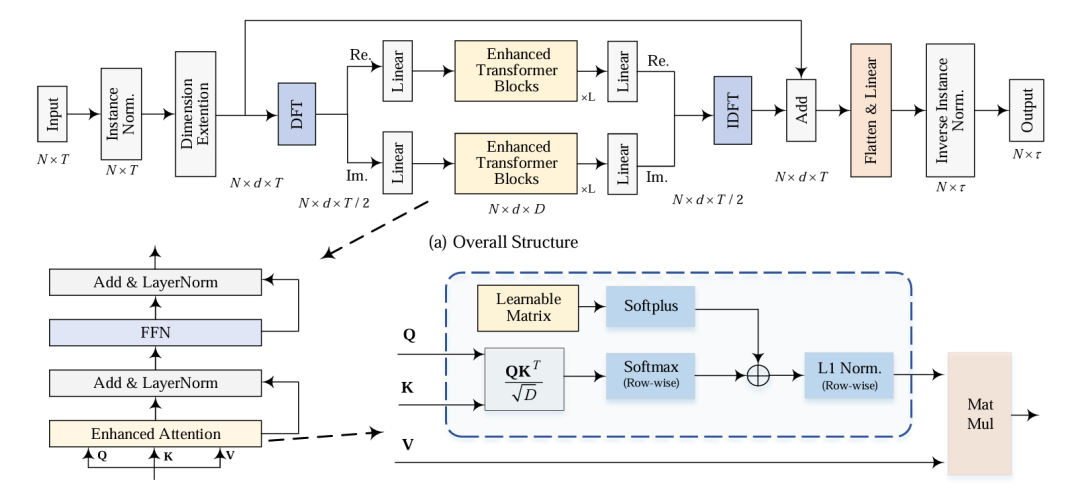
FreEformer是采用 “频域转换 - 增强 Transformer 建模 - 时域恢复” 的核心流程。
具体步骤
数据预处理:使用 RevIN(可逆实例归一化)处理输入数据,消除非平稳性,同时将频域零频点(对应常数均值分量)置零;通过可学习权重向量扩展输入维度,得到高维序列。
频域转换与处理:沿时间维度应用离散傅里叶变换,得到复频域谱,利用实值信号频域的共轭对称性,仅保留实部和虚部的前部分元素。
增强 Transformer 建模:将实部和虚部分别展平并投影到隐藏维度,构建频域变量令牌,输入堆叠的增强 Transformer 块捕捉多变量间依赖;Transformer 块中,先通过增强注意力捕捉交叉变量依赖,再用 LayerNorm 和 FFN 更新频率表征。
时域恢复与预测:将 Transformer 输出投影回原始回溯长度,重组实部和虚部重建频域谱,通过逆 DFT(IDFT)恢复时域信号,引入残差连接,经展平、线性层和反归一化得到最终预测结果。
增强注意力机制(关键创新点)
针对普通注意力矩阵低秩问题,论文提出增强注意力机制。
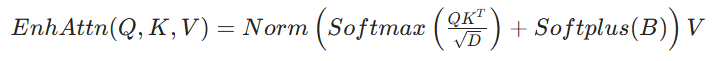
核心改进:在普通 Softmax 注意力矩阵基础上,添加可学习矩阵B(经 Softplus 确保非负性),再进行行级 L1 归一化。
频域 - 时域等价性(定理 1):频域线性投影等价于时域中序列及其调制版本的循环卷积之和,证明频域操作在计算复杂时域变换时更简洁高效。
矩阵秩边界(定理 2):对于同尺寸矩阵A和B,满足

为增强注意力提升矩阵秩提供理论依据。
梯度特性:普通注意力梯度易因 Softmax 概率乘积过小导致梯度消失,而增强注意力通过可学习矩阵B和缩放因子,缓解梯度消失问题,提升训练稳定性。

理论优势:
-
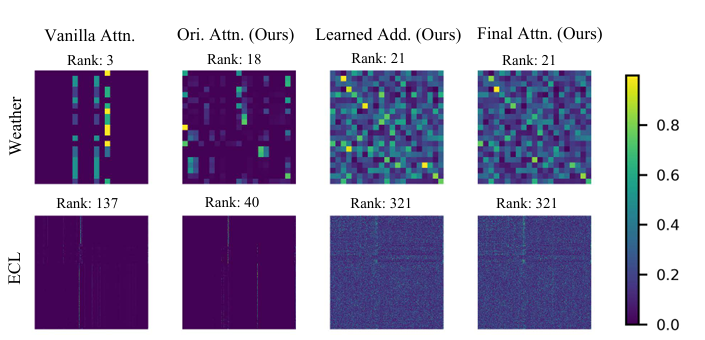
提升特征多样性:根据定理 2(矩阵和的秩边界),低秩的普通注意力矩阵与近满秩的学习矩阵相加后,秩显著提升,增强表征多样性。
-
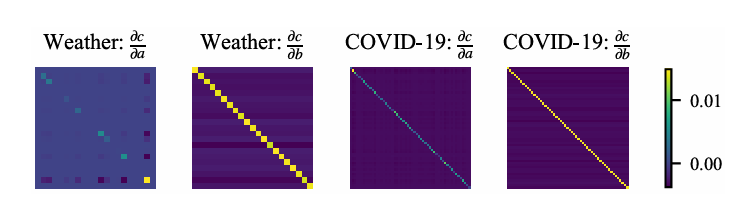
优化梯度流动:增强注意力的 Jacobian 矩阵保留普通注意力结构,同时通过可学习因子灵活缩放梯度,且对角线更突出,说明b对注意力权重的调制作用更强,提升梯度控制灵活性。
实验数据
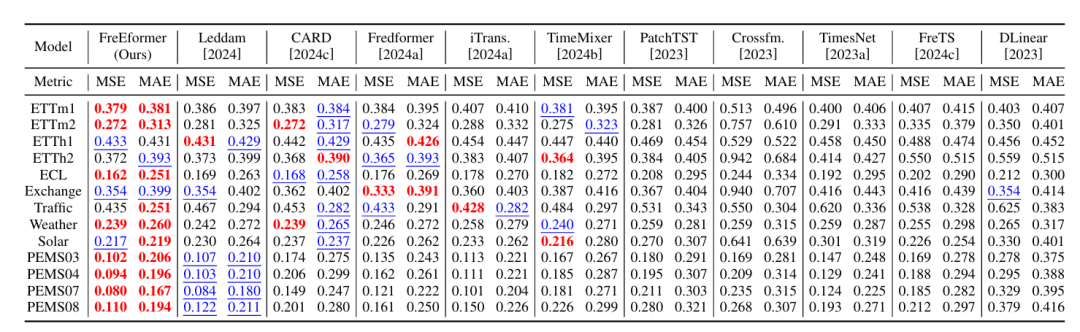
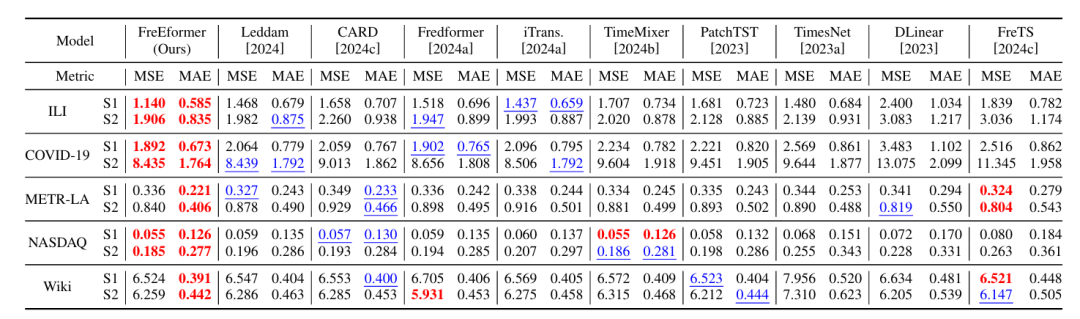
数据集:覆盖 18 个真实数据集,涵盖电力(ETT、ECL)、交通(PEMS、Traffic、METR-LA)、天气(Weather)、医疗(COVID-19、ILI、ECG)、金融(NASDAQ、Exchange)等领域。
基线模型:包括 10 种主流模型,如 Transformer 类(Leddam、CARD、Fredformer、iTransformer)、线性类(TimeMixer、FreTS、DLinear)、TCN 类(TimesNet)。
评价指标:主要采用 MSE(均方误差)和 MAE(平均绝对误差),辅助使用Pearson 等相关系数、MASE(平均绝对标度误差)。
关键实验结果:
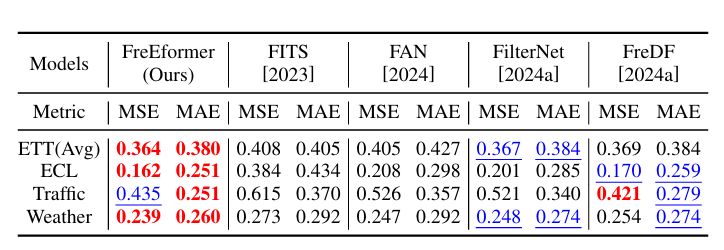
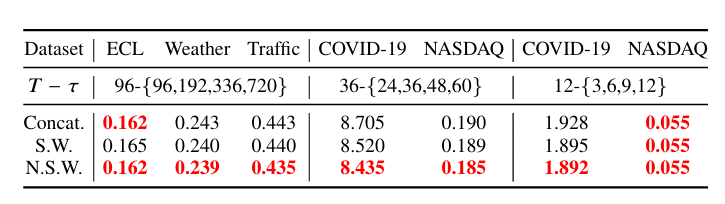
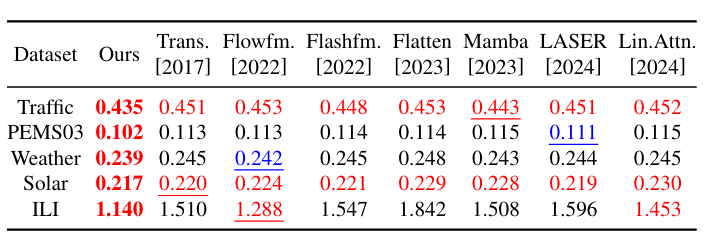
预测性能领先:在长短期预测任务中,FreEformer 均优于基线模型,如长期预测中,ETTm1 数据集 MSE 为 0.379(基线模型 Leddam 为 0.386、CARD 为 0.383);短期预测(Input-12-Predict-{3,6,9,12})中,COVID-19 数据集 MSE 为 1.892(基线模型 Leddam 为 2.064、Fredformer 为 1.902)。
增强注意力通用性:将增强注意力作为插件模块集成到 iTransformer、PatchTST、Leddam、Fredformer 中,平均 MSE 分别提升 5.9%、9.9%、1.4%、3.8%,证明其可迁移性。
频域优势验证:对比频域与时域版本 FreEformer,频域版本在增强注意力和普通注意力设置下,MSE 分别平均降低 8.4% 和 10.7%,且傅里叶基优于小波基(Haar、离散 Meyer)和多项式基(Legendre、Chebyshev、Laguerre)。
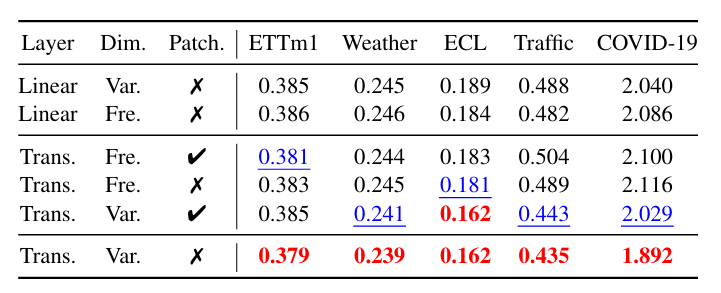
架构消融:增强 Transformer 块优于线性层;多变量依赖学习(Var 维度)优于频率间依赖学习(Fre 维度);频域分块无增益,反而破坏全局信息。
鲁棒性:7 次不同随机种子实验中,FreEformer 性能标准差小(如 ECL 数据集 96 步预测 MSE 标准差 ±0.001);在训练数据量仅 5% 时,仍优于多数基线模型;且与预训练模型(如 Timer)相比,在部分数据集(Traffic、Weather、PEMS03)上性能更优,仅用 20% 训练数据即可在 ETTm1、ECL 上超越预训练模型。
效率:在 “Input-96-Predict-96” 设置下,FreEformer 训练时间(如 ETTh1 数据集 23.33ms/iter)和内存占用(0.26GB)低于多数基线模型(如 TimesNet 训练时间 501.98ms/iter,内存 5.80GB),实现性能与效率的平衡。

小小总结
FreEformer模型,通过频域全局建模和增强注意力,实现多变量时间序列预测性能突破,架构简洁且易实现。增强注意力机制可有效提升注意力矩阵秩和梯度灵活性,作为通用插件模块,能持续改进现有 Transformer 类预测模型性能。
2025顶会前沿时序合集,攻🀄豪关注“时序大模型”,回复“资料”即可自取~

关注小时,持续学习前沿时序技术!

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 33
33 0
0- 0



 已为社区贡献13条内容
已为社区贡献13条内容

所有评论(0)