高性能分布式文件系统PoleFS是如何工作的
PoleFS是公司自主研发的一款面向云原生设计的高性能分布式文件系统。提供完全兼容POSIX标准的接口,通过自主研发的分布式缓存架构,深度融合NVMe高速存储介质,实现微秒级I/O延迟与百万级IOPS并发处理能力。同时引入低成本S3协议对象存储作为全域数据持久化载体,形成“热数据NVMe加速+冷数据S3沉降”的分层存储体系,实现性能与容量的双重弹性扩展。目前主要业务场景有AI 训练、大模型、容器平
PoleFS是公司自主研发的一款面向云原生设计的高性能分布式文件系统。提供完全兼容POSIX标准的接口,通过自主研发的分布式缓存架构,深度融合NVMe高速存储介质,实现微秒级I/O延迟与百万级IOPS并发处理能力。同时引入低成本S3协议对象存储作为全域数据持久化载体,形成“热数据NVMe加速+冷数据S3沉降”的分层存储体系,实现性能与容量的双重弹性扩展。目前主要业务场景有AI 训练、大模型、容器平台等。
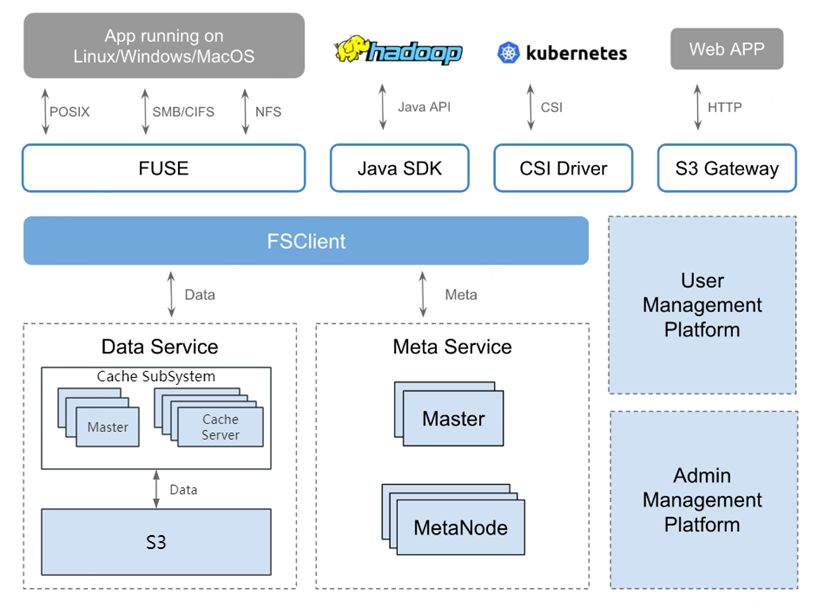
高性能分布式文件系统主要包括元数据服务、缓存数据服务、数据存储服务、FUSE client、Java SDK、CSI Driver几个部分。元数据服务由Master和MetaNode节点组成,Master将负责卷和缓存信息的管理,包括创建、更新、查询、删除卷和缓存操作,MetaNode负责文件的元数据,每个独立的卷包含若干元数据的分区用来存储inode和Dentry信息,这些分区以分布式的形式尽量均衡地存储于元数据集群,元数据具备极易扩展,可支持超大目录的能力。数据服务由分布式缓存与支持S3协议的对象存储共同构建,其中对象存储提供低成本、高容量的数据持久化能力;缓存层采用独立的分布式架构,通过一致性哈希算法动态选取高性能节点,实现写入时的三副本缓存冗余与读取时的单副本高效访问机制。客户端提供多种接入方式,为上层业务提供不同的访问协议,最大限度满足用户的多样化需求。统一缓存文件系统具备以下能力:
(1) 统一存储底座:基于S3协议的对象存储系统,通过统一缓存文件系统实现数据持久化,充分发挥对象存储海量扩展与低成本优势。分布式缓存最终将数据安全可靠地沉降至S3协议存储层,实现性能与成本的弹性平衡。
(2) 高性能缓存功能:基于一致性哈希算法的高性能弹性分布式缓存组件,向上层应用提供超低时延、高吞吐的读写能力;向下依托统一存储底座实现数据持久化,通过分级存储架构兼顾性能弹性与成本效率。
(3) 多种数据操作接口:实现POSIX、SMB/CIFS、NFS、Java API、HTTP等多种访问方式,支持AI训练、大数据、日志、备份等场景。
(4) 超大目录:支持文件系统单个目录存储超十亿个文件。
(5) 千亿级文件数量:支持超大规模的文件数量,能够满足用户未来数据爆发式增长。
(6) 低时延:能够提供20毫秒以内的访问响应速度。
(7) 回收站:支持数据删除后,通过回收站将删除数据进行恢复,能够减少用户误删带来的数据丢失风险。
元数据
具备高性能可扩展的元数据服务,传统的文件系统主要以静态子树和动态子树来管理文件空间,或存在元数据规模瓶颈,或存在平衡、运维管理复杂的问题,统一缓存文件系统对元数据进行分片管理,以层级的、分布式的、自动平衡的方式进行组织和管理,避免单机容量瓶颈,支持海量文件数据。参考市面元数据组织方式,多款分布式文件系统为了聚焦数据处理能力和模块化把元数据存入独立的kv系统中,性能和可扩展性等特点没办法保证。Polefs自研高可用全内存的元数据集群,将元数据信息inode和dentry按卷的粒度,partition为实体以分布式的方式在集群中进行存储及管理。并对posix语义操作做单独优化,使元数据访问在性能、可扩展、可运维等多个方面达到一个很好的效果。
文件的分布与Juicefs相同,按照 Chunk、Slice、Block 的规则进行数据块管理。每个 Chunk 的大小固定为 64M,主要用于优化数据的查找和定位。实际的文件写入操作则在 Slice 上执行,每个 Slice 代表一次连续的写入过程,属于特定的 Chunk,并且不会跨越 Chunk 的边界,因此长度不超过 64M。Chunk 和 Slice 主要是逻辑上的划分,而 Block(默认大小为 4M)则是物理存储的基本单位,用于在对象存储和磁盘缓存中实现数据的最终存储。
分布式缓存
分布式缓存层的特性,首先,在高性能硬件上建立分布式缓存,并以低廉的对象存储作为存储底座,实现高性能低成本的文件系统特性。其次,业务可以自主选择数据存储实体,实现数据在公有云私有云的快速流转,统一的存储上层可接入大数据引擎、高性能计算引擎等应用框架,实现数据分析、数据挖掘、数据高性能计算等一数多用。
分布式缓存层采用写三读一的设计方式,在保证数据可靠性的同时可以降低数据占用的存储空间;读写缓存空间可根据用户需求动态调整;缓存层支持限流,可以控制不同用户卷的流量压力,避免单用户把集群带宽打满;写缓存的数据会异步下刷到底层存储,下刷后的数据会移动到读缓存,以提高读缓存命中率;读缓存在LRU策略的基础上同时考虑了容量、文件数、过期时间等维度对数据进行淘汰,避免单一维度的局限性。业界文件系统对实现高性能和低成本的思路主流做法是分层拷贝迁移的方式,时效性差、复杂度高、计算成本高、组件间融合性差、数据调动冷热调整复杂、对文件系统部分有较高的数据可靠性要求。Polefs改变思路将高性能文件系统部分调整为分布式缓存,并以主流缓存方案的一致性哈希思想为基础,合理设计和底层数据存储组件交互的模块及策略,解决传统数据分层方式的弱点,实现更强的数据交换能力,提供更多的例如数据预加载等能力。
客户端多级缓存模式
客户端侧可配置本地缓存模式,可利用操作系统缓存、进程管理内存和本地磁盘构建三级缓存,来缓存数据和元数据,客户端侧也可以动态调整分布式缓存大小,整体上给业务提供极致的性能体验。
在文件系统发展的洪流中,适应数据规模增大、架构可扩展等需求,文件系统逐步发展为模块化、分布式的形式。客户对文件进行访问需要通过网络请求访问专门的元数据模块和专门的数据模块,可能产生多次网络IO增加访问的时延。分析多款分布式文件系统,面对解决性能问题主流的解决思路有两类,一类是缩短链路,以缓存方式提高性能,一类是加速访问,以硬件优化技术优化并行增高等方式加速访问效率。Polefs在缓存策略上集各家所长并做适当的融合及优化,根据访问情况及特点自动调整元数据在客户端的缓存,以更高的缓存命中率提高元数据命中缩短元数据访问的链路,以多客户端修改通知机制来实现数据更新即时可见能力。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 25
25 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)