计组(3)函数调用
把这个程序编译之后,objdump 出来。在main函数中,与不调用函数相比,区别主要是把指令换成了函数调用的指令。call 指令后面跟着的,仍然是跳转后的程序地址。在add函数中,add 函数编译之后,代码先执行了一条 push 指令和一条 mov 指令;在函数执行结束的时候,又执行了一条 pop 和一条 ret 指令。这四条指令的执行,其实就是在进行压栈和出栈操作。
一、程序栈
1、从一个例子开始
下面是一段简单的函数调用程序示例:
// function_example.c
#include <stdio.h>
int static add(int a, int b)
{
return a+b;
}
int main()
{
int x = 5;
int y = 10;
int u = add(x, y);
}把这个程序编译之后,objdump 出来。来看一看对应的汇编代码:
int static add(int a, int b)
{
0: 55 push rbp
1: 48 89 e5 mov rbp,rsp
4: 89 7d fc mov DWORD PTR [rbp-0x4],edi
7: 89 75 f8 mov DWORD PTR [rbp-0x8],esi
return a+b;
a: 8b 55 fc mov edx,DWORD PTR [rbp-0x4]
d: 8b 45 f8 mov eax,DWORD PTR [rbp-0x8]
10: 01 d0 add eax,edx
}
12: 5d pop rbp
13: c3 ret
0000000000000014 <main>:
int main()
{
14: 55 push rbp
15: 48 89 e5 mov rbp,rsp
18: 48 83 ec 10 sub rsp,0x10
int x = 5;
1c: c7 45 fc 05 00 00 00 mov DWORD PTR [rbp-0x4],0x5
int y = 10;
23: c7 45 f8 0a 00 00 00 mov DWORD PTR [rbp-0x8],0xa
int u = add(x, y);
2a: 8b 55 f8 mov edx,DWORD PTR [rbp-0x8]
2d: 8b 45 fc mov eax,DWORD PTR [rbp-0x4]
30: 89 d6 mov esi,edx
32: 89 c7 mov edi,eax
34: e8 c7 ff ff ff call 0 <add>
39: 89 45 f4 mov DWORD PTR [rbp-0xc],eax
3c: b8 00 00 00 00 mov eax,0x0
}
41: c9 leave
42: c3 ret 在main函数中,与不调用函数相比,区别主要是把 jump 指令换成了函数调用的 call 指令。call 指令后面跟着的,仍然是跳转后的程序地址。
在add函数中,add 函数编译之后,代码先执行了一条 push 指令和一条 mov 指令;在函数执行结束的时候,又执行了一条 pop 和一条 ret 指令。这四条指令的执行,其实就是在进行压栈和出栈操作。
2、函数调用与条件指令跳转的区别
函数调用和之前所说的条件跳转指令有些相似,它们两个都是在原来顺序执行的指令过程里,执行了一个内存地址的跳转指令,让指令从原来顺序执行的过程里跳开,从新的跳转后的位置开始执行。
但是,这两个跳转有个区别,if…else 和 for/while 的跳转,是跳转走了就不再回来了,就在跳转后的新地址开始顺序地执行指令。而函数调用的跳转,在对应函数的指令执行完了之后,还要再回到函数调用的地方,继续执行 call 之后的指令。
3、如何实现函数调用
①内联函数
有没有一个可以不跳转回到原来开始的地方,来实现函数的调用呢?好像可以把调用的函数指令,直接插入在调用函数的地方,替换掉对应的 call 指令,然后在编译器编译代码的时候,直接就把函数调用变成对应的指令替换掉。但这个方法有些问题。如果函数 A 调用了函数 B,然后函数 B 再调用函数 A,我们就得面临在 A 里面插入 B 的指令,然后在 B 里面插入 A 的指令,这样就会产生无穷无尽地替换。
注意:这里直接插入在调用函数的地方,替换掉对应的 call 指令,然后在编译器编译代码的时候,直接就把函数调用变成对应的指令替换掉——这个方法其实叫函数内联,在对非递归函数、小函数内联其实可以减少跳转、提升性能,使CPU指令流水线更顺畅。但这无法成为正常标准函数调用的方式。
②寄存器记录回来的地址
能不能把后面要跳回来执行的指令地址给记录下来呢?就像前面讲 PC 寄存器一样,我们可以专门设立一个“程序调用寄存器”,来存储接下来要跳转回来执行的指令地址。等到函数调用结束,从这个寄存器里取出地址,再跳转到这个记录的地址,继续执行就好了。
但是在多层函数调用里,简单只记录一个地址也是不够的。我们在调用函数 A 之后,A 还可以调用函数 B,B 还能调用函数 C。这一层又一层的调用并没有数量上的限制。在所有函数调用返回之前,每一次调用的返回地址都要记录下来,但是我们 CPU 里的寄存器数量并不多。像我们一般使用的 Intel i7 CPU 只有 16 个 64 位寄存器,调用的层数一多就存不下了。
③最终方案:程序栈
我们在内存里面开辟一段空间,用栈这个后进先出的数据结构。栈就像一个乒乓球桶,每次程序调用函数之前,我们都把调用返回后的地址写在一个乒乓球上,然后塞进这个球桶。这个操作其实就是我们常说的压栈。如果函数执行完了,我们就从球桶里取出最上面的那个乒乓球,很显然,这就是出栈。
拿到出栈的乒乓球,找到上面的地址,把程序跳转过去,就返回到了函数调用后的下一条指令了。如果函数 A 在执行完成之前又调用了函数 B,那么在取出乒乓球之前,我们需要往球桶里塞一个乒乓球。而我们从球桶最上面拿乒乓球的时候,拿的也一定是最近一次的,也就是最下面一层的函数调用完成后的地址。乒乓球桶的底部,就是栈底,最上面的乒乓球所在的位置,就是栈顶。
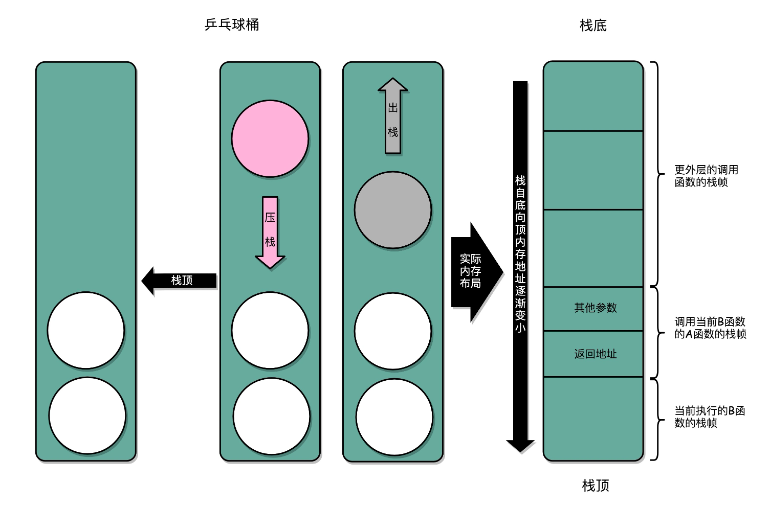
在真实的程序里,压栈的不只有函数调用完成后的返回地址。比如函数 A 在调用 B 的时候,需要传输一些参数数据,这些参数数据在寄存器不够用的时候也会被压入栈中。整个函数 A 所占用的所有内存空间,就是函数 A 的栈帧。
而实际的程序栈布局,顶和底与我们的乒乓球桶相比是倒过来的。底在最上面,顶在最下面,这样的布局是因为栈底的内存地址是在一开始就固定的。而一层层压栈之后,栈顶的内存地址是在逐渐变小而不是变大。
4、函数调用的整个过程
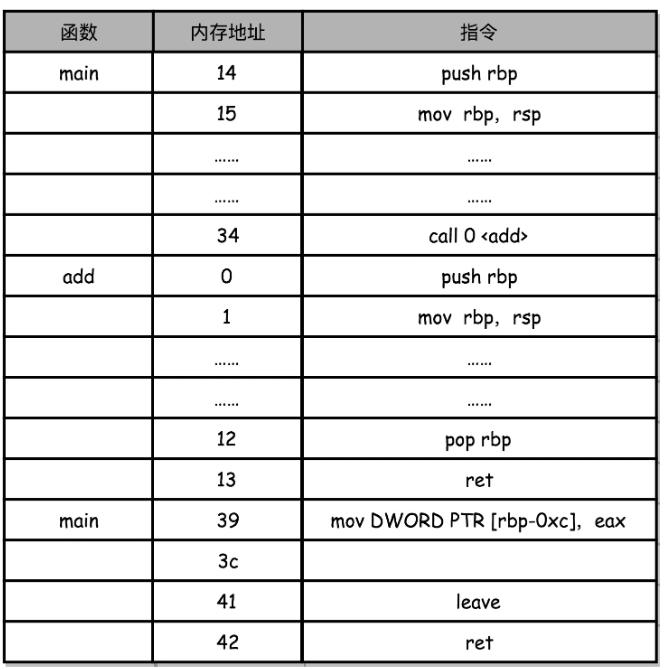
图中,rbp 是 register base pointer 栈基址寄存器(栈帧指针),指向当前栈帧的栈底地址。rsp 是 register stack pointer 栈顶寄存器(栈指针),指向栈顶元素。
对应上面函数 add 的汇编代码,main 函数调用 add 函数时,add 函数入口在内存地址的 0~1 行,add 函数结束之后在 12~13 行。
在调用第 34 行的 call 指令时,会把当前的 PC 寄存器里的下一条指令的地址压栈,保留函数调用结束后要执行的指令地址。而 add 函数的第 0 行,push rbp 这个指令,就是在进行压栈。这里的 rbp 又叫栈帧指针,是一个存放了当前栈帧位置的寄存器。push rbp 就把之前调用函数,也就是 main 函数的栈帧的栈底地址,压到栈顶。
接着,第 1 行的一条命令 mov rbp, rsp 里,则是把 rsp 这个栈指针(Stack Pointer)的值复制到 rbp 里,而 rsp 始终会指向栈顶。这个命令意味着,rbp 这个栈帧指针指向的地址,变成当前最新的栈顶,也就是 add 函数的栈帧的栈底地址了。
而在函数 add 执行完成之后,又会分别调用第 12 行的 pop rbp 来将当前的栈顶出栈,这部分操作维护好了我们整个栈帧。然后,我们可以调用第 13 行的 ret 指令,这时候同时要把 call 调用的时候压入的 PC 寄存器里的下一条指令出栈,更新到 PC 寄存器中,将程序的控制权返回到出栈后的栈顶。
二、stack overflow
通过引入栈,我们可以看到,无论有多少层的函数调用,或者在函数 A 里调用函数 B,再在函数 B 里调用 A,这样的递归调用,我们都只需要通过维持 rbp 和 rsp,这两个维护栈顶所在地址的寄存器,就能管理好不同函数之间的跳转。不过,栈的大小也是有限的。如果函数调用层数太多,我们往栈里压入它存不下的内容,程序在执行的过程中就会遇到栈溢出的错误,这就是大名鼎鼎的“stack overflow”。
我们要构造一个stack overflow的错误很简单,例如无限递归而没有出口:
int a()
{
return a();
}
int main()
{
a();
return 0;
}除了无限递归,递归层数过深,在栈空间里面创建非常占内存的变量(比如一个巨大的数组),这些情况都很可能给你带来 stack overflow。
拓展:内存的栈区
这里程序栈所放的内存中的栈区, 是程序运行时 每个线程/函数调用的临时工作区,除了存放栈帧之外,也会存放:
(1)函数调用相关的数据
当函数被调用时,栈上会生成 栈帧,包含:
①返回地址(Return Address)
-
当函数执行完毕,需要返回调用点时用的地址
-
由
call指令自动压入栈(在 x86 是ret弹出)
②上一层栈帧指针(Saved Frame Pointer)
-
保存调用函数的基址(比如
ebp/rbp) -
方便函数内部访问参数和局部变量
(2)函数参数
有些参数先放在寄存器,超过寄存器数量的参数或者栈调用约定要求的参数,会压入栈
(3)局部变量
函数内部定义的 局部变量(局部数组、整型、结构体等),栈上分配 → 函数结束后自动释放
(4)临时数据 / 保存寄存器
一些计算中间结果(临时寄存器值),调用函数前需要保存的一些寄存器值,以便返回后恢复
(5)栈对齐和填充
为了满足 CPU 的对齐要求(比如 16 字节对齐),编译器可能在栈上添加一些 填充字节 (padding)
(6)特殊场景
异常处理或信号处理时,栈也可能保存 异常信息、返回上下文;
多线程时,每个线程会有自己的栈空间
三、内联函数细节
把一个实际调用的函数产生的指令,直接插入到的位置,来替换对应的函数调用指令。尽管这样的方案在函数递归调用中不可用,但在其他情况下还是可以用的,并且性能还会优化。
事实上,这就是一个常见的编译器进行自动优化的场景,我们通常叫函数内联(Inline)。我们只要在 GCC 编译的时候,加上对应的一个让编译器自动优化的参数 -O,编译器就会在可行的情况下,进行这样的指令替换。
除了依靠编译器的自动优化,还可以在定义函数的地方,加上 inline 的关键字,来提示编译器对函数进行内联。
内联带来的优化是,CPU 需要执行的指令数变少了,根据地址跳转的过程不需要了,压栈和出栈的过程也不用了。不过内联并不是没有代价,内联意味着,我们把可以复用的程序指令在调用它的地方完全展开了。如果一个函数在很多地方都被调用了,那么就会展开很多次,整个程序占用的空间就会变大了。
四、函数调用整个过程(更详细版本)
用下面这个例子来查看函数调用过程中栈帧、参数、临时变量、返回结果等的变化情况。
#include <stdio.h>
int sum(int a, int b) {
int c = a + b;
return c;
}
int main() {
int x = 3, y = 5;
int z = sum(x, y);
printf("%d\n", z);
return 0;
}
编译之后:
Disassembly of section .text:
0000000000000000 <sum>:
#include <stdio.h>
int sum(int a, int b) {
0: 55 push rbp
1: 48 89 e5 mov rbp,rsp
4: 89 7d ec mov DWORD PTR [rbp-0x14],edi
7: 89 75 e8 mov DWORD PTR [rbp-0x18],esi
int c = a + b;
a: 8b 55 ec mov edx,DWORD PTR [rbp-0x14]
d: 8b 45 e8 mov eax,DWORD PTR [rbp-0x18]
10: 01 d0 add eax,edx
12: 89 45 fc mov DWORD PTR [rbp-0x4],eax
return c;
15: 8b 45 fc mov eax,DWORD PTR [rbp-0x4]
}
18: 5d pop rbp
19: c3 ret
000000000000001a <main>:
int main() {
1a: 55 push rbp
1b: 48 89 e5 mov rbp,rsp
1e: 48 83 ec 10 sub rsp,0x10 ;分配16字节局部变量空间
int x = 3, y = 5;
22: c7 45 f4 03 00 00 00 mov DWORD PTR [rbp-0xc],0x3
29: c7 45 f8 05 00 00 00 mov DWORD PTR [rbp-0x8],0x5
int z = sum(x, y);
30: 8b 55 f8 mov edx,DWORD PTR [rbp-0x8]
33: 8b 45 f4 mov eax,DWORD PTR [rbp-0xc]
36: 89 d6 mov esi,edx
38: 89 c7 mov edi,eax
3a: e8 00 00 00 00 call 3f <main+0x25>
3f: 89 45 fc mov DWORD PTR [rbp-0x4],eax
printf("%d\n", z);
42: 8b 45 fc mov eax,DWORD PTR [rbp-0x4]
45: 89 c6 mov esi,eax
47: 48 8d 3d 00 00 00 00 lea rdi,[rip+0x0] # 4e <main+0x34>
4e: b8 00 00 00 00 mov eax,0x0
53: e8 00 00 00 00 call 58 <main+0x3e>
return 0;
58: b8 00 00 00 00 mov eax,0x0
}
5d: c9 leave
5e: c3 ret
其中栈的变化是:
(1)main刚进入时

(2)main 建立栈帧并分配局部变量

(3)调用call sum
call sum做两件事:
①压栈返回地址(main中 call 之后的下一条指令地址)
②跳转到 sum

(4)sum 建立自己的栈帧
执行 push rbp; mov rbp, rsp

注意:返回地址上面是main的栈帧,下面是sum的栈帧;其本身不属于任何栈帧内部。
(5)sum执行完毕,返回

(6)回到main
返回值存放在 eax,写入 z。
最终 main 结束,leave; ret,整个栈帧销毁。
注意:


有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 7
7 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)